一.RabbitMQ简单介绍
消息队列作为分布式系统中不可或缺的组件,承担着解耦系统组件、保障数据可靠传输、提高系统吞吐量等重要职责。在众多消息队列产品中,RabbitMQ 凭借其可靠性和丰富的特性,在企业级应用中获得了广泛应用。
二.RabbitMQ 核心组件与工作原理
RabbitMQ 作为一个基于 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)标准的开源消息系统,其设计理念源于"生产者-消费者"模式,旨在实现系统组件间的异步通信和解耦。在深入探讨 RabbitMQ 的应用之前,我们首先需要理解其核心组件及其工作原理。
Broker:消息中枢
Broker 是 RabbitMQ 的核心组件,扮演着消息中转站的角色。它接收来自生产者的消息,并根据预设的路由规则将消息转发给相应的消费者。在 RabbitMQ 的架构中,Broker 是消息流通的枢纽,负责消息的存储、转发和管理。当消息被生产者发送到 Broker 时,Broker 会根据消息的路由键(Routing Key)和交换机(Exchange)类型,将消息路由到相应的消息队列(Queue)。Broker 的存在使得生产者和消费者无需直接通信,从而实现了系统的解耦。此外,Broker 还负责管理消息的持久化、过期时间以及消息的确认机制等,确保消息的可靠传输。在高可用性场景下,RabbitMQ 支持集群部署,多个 Broker 可以协同工作,提供故障转移和负载均衡能力,进一步提高系统的稳定性和性能。
Producer:消息生产者
Producer 是消息的源头,负责生成并发送消息到 Broker。在 RabbitMQ 中,生产者通过定义消息的路由键(route key)和交换机(exchanger)类型,指定消息的流向。生产者可以是任何能够连接到 RabbitMQ 服务的应用程序或服务。当生产者发送消息时,它需要指定消息的内容、路由键以及交换机类型。交换机类型决定了消息如何被路由到队列。RabbitMQ 支持多种交换机类型,如直连交换机(Direct Exchange)、主题交换机(Topic Exchange)、扇出交换机(Fanout Exchange)和头交换机(Headers Exchange)等。每种交换机类型都有其特定的路由规则,允许生产者灵活控制消息的分发方式。例如,直连交换机根据路由键的精确匹配将消息路由到特定的队列,而主题交换机则支持基于通配符(使用 *(匹配一个词)和 #(匹配多个词))的路由键匹配。生产者还可以设置消息的属性,如消息过期时间、优先级等,进一步控制消息的行为。此外,生产者可以通过设置消息的持久化级别,确保消息在 Broker 重启后不会丢失。
Consumer:消息消费者
Consumer 是消息的接收和处理端,从 Broker 获取消息并进行相应的业务逻辑处理。在 RabbitMQ 中,消费者通过订阅特定的消息队列来接收消息。消费者可以是任何能够连接到 RabbitMQ 服务的应用程序或服务。当消费者订阅了一个队列后,它会接收到该队列中的消息,并根据业务逻辑进行处理。RabbitMQ 支持多种消息确认机制,允许消费者在处理消息后向 Broker 发送确认信号,表示消息已成功处理。如果消费者未确认消息,Broker 会认为消息未被成功处理,并会在一定时间后将消息重新发送给其他消费者。这种机制确保了消息的可靠性,即使在消费者出现故障的情况下,消息也不会丢失。此外,消费者还可以设置消息的处理超时时间,防止长时间未处理的消息占用队列资源。
MessageQueue:消息队列
MessageQueue 是消息的存储和中转站,负责暂存消息直到被消费者处理。在 RabbitMQ 中,消息队列是消息存储和管理的基本单位。当生产者发送消息到 Broker 时,Broker 会根据路由规则将消息存储在相应的消息队列中。消费者通过订阅消息队列来接收和处理消息。消息队列可以配置为持久化或非持久化。持久化队列的消息会保存到磁盘上,即使 Broker 重启,消息也不会丢失。而非持久化队列的消息只保存在内存中,Broker 重启后消息会丢失。根据应用场景的需求,我们可以灵活选择消息队列的持久化策略。消息队列还可以设置最大消息数量或最大存储空间,防止队列无限增长导致系统资源耗尽。此外,消息队列还支持消息的 TTL(Time To Live,生存时间)设置,控制消息的有效期,过期的消息会自动从队列中删除。
RabbitMQ 工作原理
RabbitMQ 的工作原理基于生产者-消费者模式,通过消息的异步传输实现系统组件的解耦 。当生产者发送消息时,它将消息发送到 Broker,指定消息的路由键和交换机类型。Broker 根据交换机类型和路由键,将消息路由到相应的消息队列中。消费者通过订阅消息队列,从队列中获取消息并进行处理。这种设计使得生产者和消费者无需直接通信,也无需同时在线,极大地提高了系统的灵活性和可靠性。
RabbitMQ 的消息传输过程可以分为以下几个步骤:
- 生产者发送消息:生产者通过 RabbitMQ 客户端将消息发送到 Broker。消息包含内容和路由信息(如路由键)。
- Broker 接收消息:Broker 接收生产者发送的消息,并根据消息的路由信息和交换机类型,将消息路由到相应的消息队列。
- 消息存储:消息被存储在消息队列中,等待消费者处理。根据队列的配置,消息可以是持久化的(保存到磁盘)或非持久化的(只保存在内存中)。
- 消费者接收消息:消费者从消息队列中获取消息。RabbitMQ 支持多种消息接收方式,如轮询(Polling)和推送(Push)。
- 消息处理:消费者处理获取到的消息,并根据业务逻辑执行相应的操作。
- 消息确认 :消费者处理消息后,向 Broker 发送确认信号,表示消息已成功处理。如果消费者未确认消息,Broker 会认为消息未被成功处理,并会在一定时间后将消息重新发送给其他消费者。
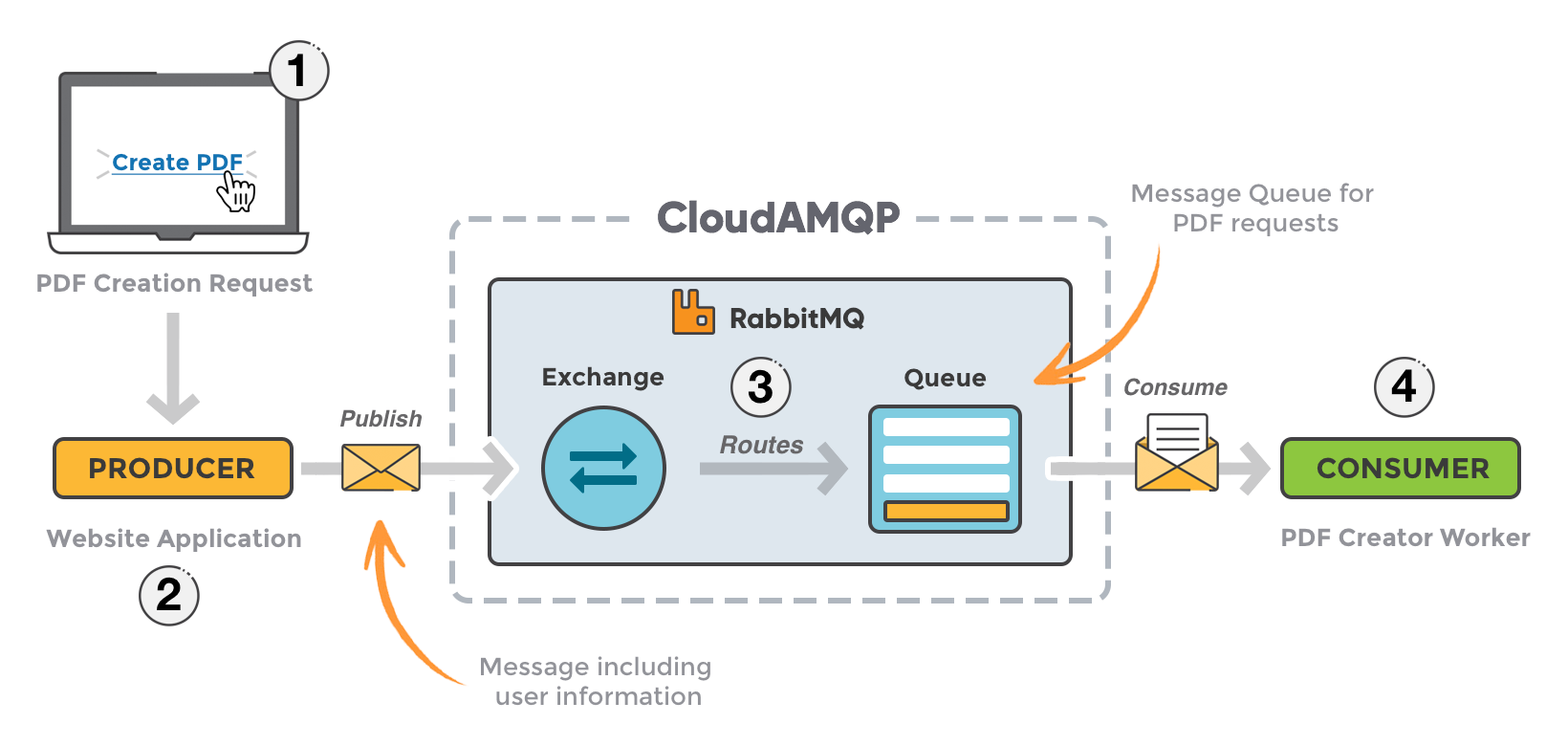
这种消息确认机制确保了消息的可靠性,即使在消费者出现故障的情况下,消息也不会丢失。此外,RabbitMQ 还支持多种消息投递策略,如消息的公平分配(Fair Dispatch)、消息的优先级等,进一步提高了系统的灵活性和性能。
三.Java 开发中 RabbitMQ 常见问题及解决方案
在 Java 应用开发中使用 RabbitMQ 时,开发者常常会遇到各种挑战,如消息堆积、消息幂等性判断和消息丢失等问题。这些问题如果处理不当,将直接影响系统的性能和可靠性。本节将深入探讨这些问题的原因、影响以及相应的解决方案。
消息堆积问题
消息堆积是指消息队列中的消息数量迅速增加,导致系统性能下降甚至崩溃。在高并发场景下,消息堆积是一个常见且严重的问题。
消息堆积的原因
消息堆积通常由以下几个因素引起:
-
生产者发送消息的速度快于消费者处理消息的速度:这是消息堆积最直接的原因。当生产者发送消息的速度远快于消费者处理消息的速度时,消息队列中的消息数量会迅速增加,最终导致队列堵塞。
-
消费者处理消息的逻辑复杂,耗时长:如果消费者处理每条消息需要较长时间,而生产者又不断发送新消息,消息队列中的消息数量会不断增加。
-
系统资源不足:如果服务器的 CPU、内存、网络带宽等资源不足,消费者处理消息的速度会受到影响,导致消息堆积。
-
消息队列配置不当 :如果消息队列没有设置合理的参数,如最大消息数量、消息过期时间等,可能会导致消息无限堆积。
消息堆积的解决方案
1.增加消费者数量 :通过增加消费者实例来提高消息处理速度。RabbitMQ 支持负载均衡,多个消费者可以同时处理消息队列中的消息。
代码如下:java@Configuration public class RabbitConfig { @Bean public ConnectionFactory connectionFactory() { CachingConnectionFactory connectionFactory = new CachingConnectionFactory("localhost"); connectionFactory.setPort(5672); return connectionFactory; } @Bean public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) { return new RabbitTemplate(connectionFactory); } @Bean public Queue queue() { return new Queue("my_queue"); } @Bean public SimpleMessageListenerContainer container(ConnectionFactory connectionFactory, MyConsumer myConsumer) { SimpleMessageListenerContainer container = new SimpleMessageListenerContainer(); container.setConnectionFactory(connectionFactory); container.setQueueNames("my_queue"); container.setMessageListener(myConsumer); container.setConcurrentConsumers(5); // 设置并发消费者数量 return container; } }
2 优化消费者代码 :分析消费者处理消息的逻辑,优化代码,减少消息处理时间。例如,避免在消息处理过程中进行耗时的数据库操作或网络调用,可以考虑将这些操作异步化。
在 Java 代码中,可以使用异步数据库访问或消息队列来处理耗时操作:
java
@Component
public class MyConsumer {
@Autowired
private EntityManager entityManager;
@RabbitListener(queues = "my_queue")
public void receiveMessage(String message) {
// 将消息处理逻辑异步化 才想起来之前的并发工具类还没写
CompletableFuture.runAsync(() -> {
try {
// 处理消息
processMessage(message);
// 持久化结果
entityManager.persist(new MessageProcessingResult(message));
} catch (Exception e) {
// 处理异常
handleException(e, message);
}
});
}
private void processMessage(String message) {
// 具体的消息处理逻辑
}
private void handleException(Exception e, String message) {
// 异常处理逻辑
}
}-
设置消息 TTL :为消息设置过期时间(TTL),确保消息不会在队列中无限期地堆积。当消息超过 TTL 时,会被自动删除。(redis策略)
在 RabbitMQ 中,可以通过队列参数设置消息的 TTL:java@Configuration public class RabbitConfig { @Bean public Queue queue() { Map<String, Object> args = new HashMap<>(); args.put("x-message-ttl", 3600000); // 设置消息 TTL 为 1 小时 return new Queue("my_queue", true, false, false, args); } } -
配置队列长度限制 :设置队列的最大消息数量或最大存储空间,防止队列无限增长。当队列达到限制时,新的消息会被拒绝或丢弃。
可以通过队列参数设置最大消息数量:java@Configuration public class RabbitConfig { @Bean public Queue queue() { Map<String, Object> args = new HashMap<>(); args.put("max-length", 10000); // 设置队列最大消息数量为 10000 return new Queue("my_queue", true, false, false, args); } } -
监控和告警 :实施消息队列的监控和告警机制,及时发现消息堆积问题。当队列中的消息数量超过预设阈值时,系统会发出告警,提醒管理员采取措施。
可以使用 RabbitMQ 的管理界面或第三方监控工具来监控队列的状态。
消息幂等性问题
消息幂等性是指同一条消息被多次处理时,结果与一次处理相同。在 RabbitMQ 中,由于消息的可靠传输机制,消息可能会被重复发送,导致重复处理。如果系统的消息处理逻辑不是幂等的,可能会导致数据不一致或重复提交等严重问题。
消息幂等性判断的必要性
-
消息重复投递:在消息传输过程中,由于网络问题或系统故障,消息可能会被重复投递。如果消费者没有幂等性判断机制,可能会多次处理同一条消息,导致业务逻辑执行多次。
-
系统重启恢复:当消费者或整个系统重启后,未确认的消息可能会被重新投递。如果没有幂等性判断,重启后的系统可能会重复处理之前已经处理过的消息。
-
分布式系统中的竞态条件 :在分布式系统中,多个消费者可能同时处理消息,如果没有幂等性判断,可能会导致竞态条件,影响系统的一致性。
消息幂等性判断的方法
1 唯一标识符(tag)检查 :为每条消息生成一个唯一标识符(如 UUID),消费者在处理消息前检查该标识符是否已经处理过。如果已经处理过,则跳过该消息。
代码如下:java@Component public class MyConsumer { @Autowired private RedisTemplate<String, String> redisTemplate; @RabbitListener(queues = "my_queue") public void receiveMessage(String message) { // 生成消息 ID String messageId = UUID.randomUUID().toString(); // 检查消息是否已处理 if (!redisTemplate.hasKey("processed_messages:" + messageId)) { // 处理消息 processMessage(message); // 标记消息为已处理 redisTemplate.opsForValue().set("processed_messages:" + messageId, "processed"); } } private void processMessage(String message) { // 具体的消息处理逻辑 } }
2 数据库唯一约束(unique index):在数据库表中为消息的唯一标识符设置唯一约束。当尝试插入重复的消息时,会抛出唯一性冲突异常,消费者可以捕获该异常并跳过消息处理。
sql
CREATE TABLE processed_messages (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
message_id VARCHAR(100) NOT NULL,
payload TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY uniq_message_id (message_id)
);-
版本号控制 :为消息添加版本号,消费者在处理消息时检查消息的版本号是否是最新的。如果不是最新的版本,跳过处理。可以使用乐观锁来实现版本号控制:
java@Component public class MyConsumer { @Autowired private EntityManager entityManager; @RabbitListener(queues = "my_queue") public void receiveMessage(String message) { // 解析消息 MessageDto messageDto = JsonUtil.fromJson(message, MessageDto.class); // 查询最新的消息版本 Query query = entityManager.createQuery("SELECT m FROM MessageEntity m WHERE m.messageId = :messageId"); query.setParameter("messageId", messageDto.getMessageId()); MessageEntity latestMessage = (MessageEntity) query.getSingleResult(); // 比较版本号 if (latestMessage.getVersion() < messageDto.getVersion()) { // 处理消息 processMessage(messageDto); // 更新消息状态 entityManager.merge(latestMessage); } } private void processMessage(MessageDto messageDto) { // 具体的消息处理逻辑 } } -
时间戳判断 :为消息添加时间戳,消费者在处理消息时检查消息的创建时间。如果消息的创建时间与当前时间相差较大,可能是重复消息,跳过处理。
在 Java 代码中,可以使用消息的时间戳来判断:java@Component public class MyConsumer { @RabbitListener(queues = "my_queue") public void receiveMessage(String message) { // 解析消息 MessageDto messageDto = JsonUtil.fromJson(message, MessageDto.class); // 检查消息是否过时 if (System.currentTimeMillis() - messageDto.getCreateTime() > 3600000) { // 超过 1 小时 // 跳过处理 return; } // 处理消息 processMessage(messageDto); } private void processMessage(MessageDto messageDto) { // 具体的消息处理逻辑 } }
消息丢失问题
消息丢失是指消息从队列中消失,但没有被任何消费者处理。消息丢失会直接导致系统功能异常或数据不一致,是一个严重的可靠性问题。
消息丢失的原因
-
生产者未确认消息发送:在 RabbitMQ 中,生产者将消息发送到 Broker 时,如果不设置消息确认机制,生产者无法知道消息是否成功发送到 Broker。如果网络问题或 Broker 故障导致消息未成功发送,生产者可能已经认为消息已发送,但实际上消息丢失了。
-
Broker 故障:如果 Broker 发生故障(如断电、硬件故障等),且消息未持久化,消息会丢失。即使消息已持久化,如果 Broker 的数据存储介质发生故障,消息也可能丢失。
-
消费者未确认消息接收:在 RabbitMQ 中,消费者接收消息后,如果不发送确认信号,Broker 会认为消息未被成功处理,并会在一定时间后将消息重新发送给其他消费者。如果消费者接收到消息但未处理就崩溃了,且未发送确认信号,Broker 会将消息重新发送给其他消费者,导致消息重复处理。
-
消息队列配置不当 :如果消息队列配置为非持久化,且 Broker 重启,消息会丢失。此外,如果消息队列设置了消息过期时间,过期的消息会自动删除。
消息丢失的解决方案
1 生产者确认消息发送 :在生产者发送消息时,设置消息确认机制,确保消息已成功发送到 Broker。在 RabbitMQ 中,可以通过设置消息的 deliveryMode 为 2(持久化)来确保消息持久化到磁盘。
在 Java 代码中,可以设置消息的持久化:java@Component public class MyProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendMessage(String message) { // 设置消息的 deliveryMode 为 2(持久化) MessageProperties messageProperties = new MessageProperties(); messageProperties.setDeliveryMode(2); // 1 表示非持久化,2 表示持久化 Message rabbitMessage = new Message(message.getBytes(), messageProperties); rabbitTemplate.send("my_exchange", "my_routing_key", rabbitMessage); } }
2.Broker 高可用性配置 :通过配置 RabbitMQ 集群或主从复制,提高 Broker 的可靠性。如果单个 Broker 故障,其他 Broker 可以接管,确保消息不丢失。
在 RabbitMQ 中,可以通过配置镜像队列(Mirrored Queues)或使用 RabbitMQ HA(High Availability)插件来提高消息的可靠性:
java
@Configuration
public class RabbitConfig {
@Bean
public Queue queue() {
Map<String, Object> args = new HashMap<>();
args.put("x-ha-policy", "all"); // 配置镜像队列策略为 all
return new Queue("my_queue", true, false, false, args);
}
}3.消费者确认消息接收 :在消费者接收消息后,及时发送确认信号,确保 Broker 知道消息已被成功处理。在 RabbitMQ 中,消费者可以通过调用 acknowledge() 方法来确认消息。
在 Java 代码中,可以设置消费者自动确认或手动确认:
java
@Component
public class MyConsumer {
@RabbitListener(queues = "my_queue", autoStartup = "false")
public void receiveMessage(String message) {
try {
// 处理消息
processMessage(message);
// 确认消息
getChannel().basicAck(getDeliveryTag(), false);
} catch (Exception e) {
// 处理异常
handleException(e, message);
// 拒绝消息,不重新投递
getChannel().basicReject(getDeliveryTag(), false);
}
}
private void processMessage(String message) {
// 具体的消息处理逻辑
}
private void handleException(Exception e, String message) {
// 异常处理逻辑
}
}-
设置消息过期时间 :为消息设置合理的过期时间,防止消息在队列中无限期地堆积。过期的消息会自动删除,释放队列空间。
在 Java 代码中,可以设置消息的过期时间:java@Component public class MyProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendMessage(String message) { // 设置消息的过期时间为 1 小时 MessageProperties messageProperties = new MessageProperties(); messageProperties.setExpiration("3600000"); // 3600000 毫秒 = 1 小时 Message rabbitMessage = new Message(message.getBytes(), messageProperties); rabbitTemplate.send("my_exchange", "my_routing_key", rabbitMessage); } }
三.RabbitMQ 特殊消息类型实现
在实际应用中,我们常常需要实现一些特殊类型的消息,如延迟消息、顺序消息和全局顺序消息。这些特殊消息类型可以满足不同的业务需求,提高系统的灵活性和可靠性。
延迟消息实现
延迟消息是指消息在指定时间后才被消费者处理。在某些业务场景中,我们可能需要延迟处理某些消息,如订单超时自动取消、优惠券过期提醒等。
延迟消息的实现方法
在 RabbitMQ 中,实现延迟消息主要有以下几种方法:
-
使用 TTL(Time To Live) :为消息设置过期时间,消息在过期前无法被消费者处理。当消息过期后,会被自动投递给消费者。
在 RabbitMQ 中,可以通过设置消息的 TTL 来实现延迟消息。TTL 是消息的生存时间,超过 TTL 的消息会被视为可消费的。
在 Java 代码中,可以设置消息的 TTL:java@Component public class DelayedMessageProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendDelayedMessage(String message, long delayMs) { // 设置消息的 TTL MessageProperties messageProperties = new MessageProperties(); messageProperties.setExpiration(String.valueOf(delayMs)); Message rabbitMessage = new Message(message.getBytes(), messageProperties); rabbitTemplate.send("delayed_exchange", "delayed_routing_key", rabbitMessage); } }但是,使用 TTL 有一个问题:消息会在 TTL 到期后立即被消费者消费,而不是延迟处理。为了实现真正的延迟消息,我们可以使用 RabbitMQ 的插件或额外的队列设计。
-
使用插件 :RabbitMQ 提供了多个插件可以实现延迟消息,如
rabbitmq_delayed_message插件。
rabbitmq_delayed_message是一个官方插件,允许我们设置消息的延迟时间。使用该插件,我们可以实现精确的延迟消息。
在 Java 代码中,使用插件实现延迟消息:java@Component public class DelayedMessageProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendDelayedMessage(String message, long delayMs) { // 设置消息的延迟时间 Map<String, Object> headers = new HashMap<>(); headers.put("x-delay", delayMs); MessageProperties messageProperties = new MessageProperties(); messageProperties.setHeaders(headers); Message rabbitMessage = new Message(message.getBytes(), messageProperties); rabbitTemplate.send("delayed_exchange", "delayed_routing_key", rabbitMessage); } }需要注意的是,使用插件可能会引入额外的复杂性和性能开销。此外,插件的功能和性能可能会受到 RabbitMQ 版本和配置的影响。
-
使用额外的队列和定时任务 :通过设计额外的队列和定时任务,实现延迟消息。具体来说,可以将消息首先发送到一个临时队列,然后通过定时任务将消息移动到目标队列。
这种方法的优点是不需要依赖插件,完全基于标准的 RabbitMQ 功能实现。缺点是实现较为复杂,需要额外的开发和维护。
在 Java 代码中,可以使用定时任务实现延迟消息:java@Component public class DelayedMessageProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendDelayedMessage(String message, long delayMs) { // 发送消息到临时队列 rabbitTemplate.send("temp_exchange", "temp_routing_key", message); // 设置定时任务,延迟将消息移动到目标队列 Executors.newSingleThreadScheduledExecutor().schedule(() -> { // 从临时队列获取消息 List<Message> messages = rabbitTemplate.receive("temp_queue", 0); // 将消息移动到目标队列 for (Message message : messages) { rabbitTemplate.send("target_exchange", "target_routing_key", message); } }, delayMs, TimeUnit.MILLISECONDS); } }需要注意的是,这种方法可能会引入消息丢失的风险,因为消息在临时队列中可能会被其他消费者处理。此外,定时任务的精度和可靠性也需要考虑。
顺序消息实现
顺序消息是指消息按照特定的顺序被处理。在某些业务场景中,消息的处理顺序非常重要,如订单处理、交易记录等。
顺序消息的实现方法
-
单线程消费 :通过设置消费者为单线程,确保消息按顺序处理。每个消费者只能处理一条消息,消息处理完成后再处理下一条消息。
这种方法简单直接,但可能会降低系统的吞吐量,因为消费者不能并行处理消息。
代码如下:java@Configuration public class RabbitConfig { @Bean public SimpleMessageListenerContainer container(ConnectionFactory connectionFactory, MyConsumer myConsumer) { SimpleMessageListenerContainer container = new SimpleMessageListenerContainer(); container.setConnectionFactory(connectionFactory); container.setQueueNames("my_queue"); container.setMessageListener(myConsumer); container.setConcurrentConsumers(1); // 设置并发消费者数量为 1 return container; } } -
消息组 :使用消息组(Message Groups)确保消息按顺序处理。消息组是一个逻辑概念,表示一组消息需要按顺序处理。在 RabbitMQ 中,可以通过设置消息的组 ID 来实现。
可以设置消息的组 ID:java@Component public class OrderedMessageProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendOrderedMessage(String message, String groupId) { // 设置消息的组 ID MessageProperties messageProperties = new MessageProperties(); messageProperties.setGroupId(groupId); Message rabbitMessage = new Message(message.getBytes(), messageProperties); rabbitTemplate.send("ordered_exchange", "ordered_routing_key", rabbitMessage); } } -
队列绑定顺序 :通过设计队列的绑定顺序,确保消息按顺序处理。具体来说,可以将消息先发送到一个预处理队列,处理后再发送到目标队列。
这种方法通过队列的顺序处理来保证消息的顺序性,但可能会增加系统的复杂性和延迟。
在 RabbitMQ 中,可以通过队列的绑定顺序来实现:java@Configuration public class RabbitConfig { @Bean public Queue preProcessQueue() { return new Queue("pre_process_queue"); } @Bean public Queue targetQueue() { return new Queue("target_queue"); } @Bean public Binding binding() { return BindingBuilder.bind(targetQueue()) .to("pre_process_exchange") .with("pre_process_routing_key") .noargs(); } }在 Java 代码中,可以实现消息的顺序处理:
java@Component public class PreProcessConsumer { @RabbitListener(queues = "pre_process_queue") public void receiveMessage(String message) { // 处理消息 processMessage(message); // 发送消息到目标队列 rabbitTemplate.send("target_exchange", "target_routing_key", message); } private void processMessage(String message) { // 具体的预处理逻辑 } }
全局顺序消息实现
全局顺序消息是指所有消息按照全局唯一的顺序被处理。在某些业务场景中,消息的全局顺序非常重要,如金融交易、区块链等。
全局顺序消息的实现方法
-
单线程消费+全局锁 :通过设置系统为单线程消费,并使用全局锁保证消息处理的顺序性。所有消息只能由一个消费者处理,确保全局顺序。
这种方法简单直接,但系统吞吐量会受到严重影响,特别是在高并发场景下。
在 Java 代码中,可以使用分布式锁实现全局顺序消息:java@Component public class GlobalOrderedMessageConsumer { @Autowired private DistributedLock distributedLock; @RabbitListener(queues = "global_ordered_queue") public void receiveMessage(String message) { // 获取全局锁 if (distributedLock.acquire("global_lock", 1000)) { try { // 处理消息 processMessage(message); } finally { // 释放锁 distributedLock.release("global_lock"); } } else { // 处理获取锁失败的情况 handleLockFailure(message); } } private void processMessage(String message) { // 具体的消息处理逻辑 } private void handleLockFailure(String message) { // 处理获取锁失败的情况 } } -
消息分片+顺序处理 :将消息按照一定规则分片,每个分片内部按顺序处理。通过合理设计分片规则,可以在一定程度上保证全局顺序。
这种方法通过分片来平衡系统性能和顺序性,但实现较为复杂,需要仔细设计分片规则。java@Component public class GlobalOrderedMessageProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendGlobalOrderedMessage(String message) { // 计算分片 ID String shardId = calculateShardId(message); // 发送消息到对应分片的队列 rabbitTemplate.send("shard" + shardId + "_exchange", "shard" + shardId + "_routing_key", message); } private String calculateShardId(String message) { // 根据消息内容计算分片 ID return message.hashCode() % 10; // 假设分片数量为 10 } }每个分片的消费者按顺序处理消息:
java@Component public class ShardConsumer { @RabbitListener(queues = "shard${shardId}_queue") public void receiveMessage(String message) { // 处理消息 processMessage(message); } private void processMessage(String message) { // 具体的消息处理逻辑 } } -
外部排序+消息队列 :先将消息存储在外部系统中,按顺序排序后再发送到消息队列。通过外部系统的排序功能,保证消息的全局顺序。
这种方法利用外部系统的排序功能,实现全局顺序消息,但可能会增加系统的复杂性和延迟。java@Component public class GlobalOrderedMessageProducer { @Autowired private ExternalSortingService externalSortingService; public void sendGlobalOrderedMessage(String message) { // 将消息发送到外部排序服务 externalSortingService.sortAndSend(message); } }外部排序服务实现:
java@Component public class ExternalSortingService { @Autowired private RabbitTemplate rabbitTemplate; public void sortAndSend(String message) { // 将消息存储到列表中 List<String> messages = new ArrayList<>(); messages.add(message); // 排序消息 Collections.sort(messages); // 发送排序后的消息到消息队列 for (String sortedMessage : messages) { rabbitTemplate.send("global_ordered_exchange", "global_ordered_routing_key", sortedMessage); } } }
四.RabbitMQ 底层原理
RabbitMQ 的消息读写和负载均衡机制是其核心功能,理解这些底层原理对于优化系统性能和解决实际问题至关重要。
消息读写机制
RabbitMQ 的消息读写机制涉及消息的生产、传输、存储和消费等多个环节,每个环节都有其特定的实现原理和优化策略。
消息生产机制
在 RabbitMQ 中,消息生产主要涉及以下几个步骤:
- 生产者连接 Broker:生产者通过 TCP 连接到 RabbitMQ Broker,建立网络连接。RabbitMQ 支持多种协议,如 AMQP 0-9-1、AMQP 1.0 和 MQTT 等。
- 声明交换机和队列:生产者需要声明消息将要发送的交换机和队列。交换机是消息路由的起点,队列是消息存储的容器。
- 发送消息:生产者将消息内容和路由信息(如路由键)封装成消息包,发送到 Broker。
- 消息确认:如果启用了消息确认机制,Broker 会向生产者发送确认消息,表示消息已成功接收。
java
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMessage(String message) {
rabbitTemplate.send("my_exchange", "my_routing_key", new Message(message.getBytes(), new MessageProperties()));
}消息存储机制
RabbitMQ 的消息存储机制主要涉及以下几个方面:
- 内存存储:RabbitMQ 默认将消息存储在内存中,以提高消息读写的性能。内存存储速度快,但消息在系统重启后会丢失。
- 持久化存储:为了提高消息的可靠性,RabbitMQ 支持将消息持久化到磁盘。持久化消息在系统重启后不会丢失,但写入磁盘的开销较大,影响性能。
- 消息索引:RabbitMQ 为消息创建索引,加速消息的查找和检索。索引包括消息的元数据,如消息 ID、队列 ID 等。
- 消息过期 :RabbitMQ 支持设置消息的过期时间,过期的消息会自动删除,释放存储空间。
在 RabbitMQ 的配置中,可以通过设置队列参数来控制消息的存储策略:
java
@Bean
public Queue queue() {
Map<String, Object> args = new HashMap<>();
args.put("durable", true); // 设置队列为持久化
return new Queue("my_queue", true, false, false, args);
}消息消费机制
在 RabbitMQ 中,消息消费主要涉及以下几个步骤:
- 消费者连接 Broker:消费者通过 TCP 连接到 RabbitMQ Broker,建立网络连接。
- 声明队列:消费者需要声明将要消费的消息队列。
- 订阅队列:消费者订阅队列,表示愿意接收该队列中的消息。
- 接收消息:消费者从队列中接收消息。RabbitMQ 支持两种消息接收模式:轮询(Polling)和推送(Push)。
- 消息确认:消费者处理消息后,向 Broker 发送确认信号,表示消息已成功处理。如果消费者未确认消息,Broker 会认为消息未被成功处理,并会在一定时间后将消息重新发送给其他消费者。
java
@Component
public class MyConsumer {
@RabbitListener(queues = "my_queue")
public void receiveMessage(String message) {
// 处理消息
processMessage(message);
// 确认消息
getChannel().basicAck(getDeliveryTag(), false);
}
private void processMessage(String message) {
// 具体的消息处理逻辑
}
}负载均衡机制
负载均衡是 RabbitMQ 重要的特性之一,它允许系统在多个消费者之间分配消息处理任务,提高系统的吞吐量和可靠性。
负载均衡的实现原理
RabbitMQ 的负载均衡主要通过以下几种机制实现:
- 轮询分发(Round Robin):这是 RabbitMQ 的默认负载均衡策略。消息会按照轮询的方式分发给不同的消费者。每个消费者会接收到大致相同数量的消息。
- 消息分片(Sharding):通过将消息按照一定规则分片,每个分片由特定的消费者处理。这种策略可以保证特定类型的消息总是由特定的消费者处理,适用于消息需要按特定属性分组处理的场景。
- 消费者权重(Consumer Weights):允许为不同的消费者设置不同的权重,权重高的消费者会接收到更多的消息。这种策略可以适应不同消费者处理能力的差异。
- 队列亲和性(Queue Affinity) :允许将队列绑定到特定的消费者,确保队列中的消息只由特定的消费者处理。这种策略适用于需要特定消费者处理特定队列消息的场景。
在 RabbitMQ 中,可以通过设置消费者参数来实现不同的负载均衡策略。例如,设置消费者的并发数量:
java
@Bean
public SimpleMessageListenerContainer container(ConnectionFactory connectionFactory, MyConsumer myConsumer) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setQueueNames("my_queue");
container.setMessageListener(myConsumer);
container.setConcurrentConsumers(5); // 设置并发消费者数量
return container;
}负载均衡的配置与优化
- 合理设置消费者数量:根据系统的处理能力和消息流量,合理设置消费者的数量。过多的消费者会增加系统的开销,过少的消费者则无法充分利用系统的处理能力。
- 配置消费者权重:如果不同消费者的处理能力不同,可以为它们设置不同的权重,使系统能够更有效地分配消息处理任务。
- 优化消息分片策略:根据业务需求和消息特性,设计合理的消息分片策略,确保消息能够被正确地分发给适合的消费者。
- 监控和调整 :实施系统的监控机制,实时监控消息队列和消费者的性能,根据监控结果动态调整系统的配置,确保系统的负载均衡和性能最优。
可以设置消费者的权重:
java
@Bean
public SimpleMessageListenerContainer container1(ConnectionFactory connectionFactory, MyConsumer myConsumer1) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setQueueNames("my_queue");
container.setMessageListener(myConsumer1);
container.setConcurrentConsumers(3); // 设置消费者1的并发数量为3
return container;
}
@Bean
public SimpleMessageListenerContainer container2(ConnectionFactory connectionFactory, MyConsumer myConsumer2) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setQueueNames("my_queue");
container.setMessageListener(myConsumer2);
container.setConcurrentConsumers(2); // 设置消费者2的并发数量为2
return container;
}感谢你看到这里,喜欢的可以点点关注哦!