引言
随着人工智能和机器学习技术的快速发展,向量数据在许多应用场景中变得越来越重要。从推荐系统到自然语言处理,再到图像搜索,向量搜索技术成为实现高效、精准匹配的核心。Pinecone 作为一个托管的向量数据库,为开发者提供了一种简单而强大的解决方案,能够高效地存储和查询高维向量数据。与此同时,微软的开源项目 Semantic Kernel 将 Pinecone 集成到其生态系统中,进一步增强了开发者构建智能应用的能力。
本文将深入介绍 Pinecone 的背景、特点及其优势,并结合 GitHub 上 Semantic Kernel 的单元测试文件 PineconeMemoryStoreTests.cs,详细讲解 Pinecone 在 Semantic Kernel 中的集成和使用方法。
Pinecone 的背景和特点
什么是 Pinecone?
Pinecone 是一个云原生的托管向量数据库,专为存储和查询高维向量数据而设计。它由 Pinecone 公司开发,旨在解决传统数据库在处理向量数据时的性能瓶颈问题。通过提供高效的相似性搜索功能,Pinecone 被广泛应用于机器学习和人工智能领域,尤其是需要快速匹配和检索的场景。
Pinecone 的核心特点
-
高性能相似性搜索
Pinecone 采用先进的索引技术(如近似最近邻搜索 ANN),能够在海量高维向量数据中快速找到与查询向量最相似的结果。这种能力使其在实时应用中表现出色。
-
托管服务
作为一种完全托管的云服务,Pinecone 负责数据库的维护、扩展和安全性,开发者无需自行管理底层基础设施。这大大降低了开发和运维的复杂性。
-
易用性
Pinecone 提供了直观的 API 和多种语言的 SDK(如 Python、C#、Java),开发者可以通过几行代码完成向量的插入和查询操作。
-
可扩展性
Pinecone 支持水平扩展,能够根据数据量和查询负载动态调整资源,确保在高并发场景下的稳定性和性能。
-
灵活性
Pinecone 支持多种距离度量方式(如余弦相似度、欧几里得距离),并允许附加元数据到向量上,增强了数据管理的灵活性。
Pinecone的核心原理与运行机制
Pinecone 是一个托管的向量数据库,专为高效存储和查询高维向量数据而设计。其核心原理和运行机制主要围绕 向量索引 、相似性搜索 和 云原生架构 展开。
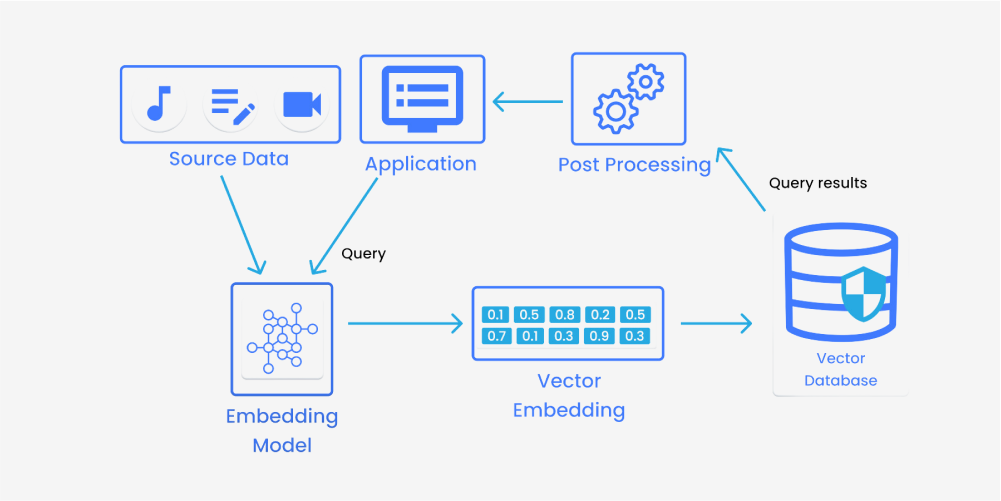
1. 向量索引
Pinecone 的核心在于其 向量索引技术 ,这是一种针对高维向量数据优化的数据结构,能够在海量数据中快速执行相似性搜索。其底层主要基于 近似最近邻(ANN)算法,在保证较高精度的同时显著提升搜索速度。
1.1 近似最近邻(ANN)搜索
- 原理:ANN 算法通过牺牲部分精确度换取更快的搜索速度。在高维空间中,精确的最近邻搜索(KNN)计算量巨大,而 ANN 通过构建特殊索引结构(如树结构、图结构或哈希表),将搜索空间划分为更小的区域,快速定位相似向量。
- 常用技术 :
- 树结构:如 KD 树或 Ball 树,通过递归划分空间。
- 图结构:如 HNSW(层次可导航小世界图),通过多层图实现高效导航。
- 哈希技术:如局部敏感哈希(LSH),将相似向量映射到相同桶中。
1.2 索引构建
- 过程 :
- 数据采样:从数据集中采样,估计数据分布。
- 参数调整:根据分布调整索引参数(如树的深度、图的连接数)。
- 索引训练:利用采样数据训练索引模型。
- 批量插入:将所有向量数据插入索引。
- 自动化:用户只需指定向量维度和距离度量方式(如余弦相似度、欧几里得距离),Pinecone 会自动选择合适的算法和参数。
2. 相似性搜索
相似性搜索 是 Pinecone 的核心功能,用于快速找到与查询向量最相似的向量。
2.1 查询处理
- 步骤 :
- 预处理:对查询向量进行归一化(若使用余弦相似度)。
- 索引搜索:利用索引结构定位候选向量。
- 精排:对候选向量进行精确距离计算,返回 topK 结果。
2.2 距离度量
- 支持类型 :
- 余弦相似度:适用于文本和推荐系统。
- 欧几里得距离:适用于图像和音频特征。
- 点积:某些场景下的相似度度量。
- 选择:用户创建索引时指定度量方式,Pinecone 据此优化索引。
3. 云原生架构
Pinecone 是一个完全托管的云服务,其架构设计注重 可扩展性 、高可用性 和 安全性。
3.1 分布式系统
- 数据分片:将索引数据分布在多个节点上。
- 负载均衡:自动分配查询请求,平衡负载。
- 故障恢复:通过数据冗余和自动 failover 保证高可用性。
3.2 自动扩展
- 水平扩展:增加节点数量提升处理能力。
- 垂直扩展:升级节点配置提高单节点性能。
3.3 安全性
- 数据加密:传输和存储时加密数据。
- 访问控制:通过 API 密钥和 IAM 策略管理权限。
- 合规性:符合 GDPR、HIPAA 等标准。
Pinecone 在 Semantic Kernel 中的集成
什么是 Semantic Kernel?
Semantic Kernel 是微软推出的一款开源框架,旨在帮助开发者轻松集成大型语言模型(LLM)和其他 AI 技术到应用程序中。它提供了一套工具和 API,支持开发者创建智能代理、处理语义记忆以及实现复杂的功能编排。
在 Semantic Kernel 中,内存存储(Memory Store)是一个关键组件,用于存储和管理语义数据(如文本嵌入向量)。Pinecone 作为一种高效的向量数据库,被集成到 Semantic Kernel 中,通过 PineconeMemoryStore 类实现。
PineconeMemoryStore 的作用
PineconeMemoryStore 是 Semantic Kernel 中的一个具体实现类,遵循 IMemoryStore 接口。它将 Pinecone 的向量存储和查询能力与 Semantic Kernel 的语义记忆功能结合在一起。开发者可以通过这个类将生成的向量嵌入存储到 Pinecone 中,并在需要时执行高效的相似性搜索。
以下是 PineconeMemoryStore 在 Semantic Kernel 中的典型工作流程:
- 向量生成:通过嵌入模型(如 OpenAI 的 embeddings)将文本转换为向量。
- 存储向量 :使用
PineconeMemoryStore将向量上传到 Pinecone 索引。 - 查询向量:根据输入查询,检索与目标向量最相似的记忆。
从单元测试看集成细节
我们可以参考 Semantic Kernel 的 GitHub 仓库中的 PineconeMemoryStoreTests.cs 文件,了解 PineconeMemoryStore 的具体实现和功能。这个单元测试文件包含了多个测试用例,用于验证类的正确性。以下是一个简化的测试用例示例:
using Microsoft.SemanticKernel.Connectors.Pinecone;
using Xunit;
public class PineconeMemoryStoreTests
{
[Fact]
public async Task CanStoreAndRetrieveMemoryAsync()
{
// Arrange
var pineconeClient = new PineconeClient("your-api-key", "your-environment");
var memoryStore = new PineconeMemoryStore(pineconeClient, "test-index");
var collection = "test-collection";
var key = "test-key";
var value = "This is a test memory";
// Act
await memoryStore.SaveAsync(collection, key, value);
var result = await memoryStore.GetAsync(collection, key);
// Assert
Assert.NotNull(result);
Assert.Equal(value, result.Value);
}
}这个测试用例展示了如何使用 PineconeMemoryStore 存储和检索记忆数据。通过分析测试代码,我们可以看到 PineconeMemoryStore 提供了简单的接口,同时依赖底层的 PineconeClient 与 Pinecone 服务交互。
Pinecone 的使用方法
为了让读者更好地掌握 Pinecone 的使用方法,本节将通过详细的代码示例,展示如何在 Semantic Kernel 中操作 Pinecone。以下示例基于 C# 语言和 Semantic Kernel 的集成。
1. 配置 Pinecone 客户端
在使用 Pinecone 之前,需要初始化一个客户端实例,并提供 API 密钥和环境信息。
using Microsoft.SemanticKernel.Connectors.Pinecone;
var pineconeClient = new PineconeClient(
apiKey: "your-api-key",
environment: "your-environment" // 例如 "us-west1-gcp"
);2. 创建索引
索引是 Pinecone 中存储向量的容器。创建索引时,需要指定名称、维度和距离度量方式。
// 创建索引,维度为 1536(常见于 OpenAI 的 embeddings)
await pineconeClient.CreateIndexAsync(
indexName: "my-index",
dimension: 1536,
metric: Metric.Cosine // 使用余弦相似度
);3. 插入向量数据
假设我们有一个文本列表,需要将其转换为向量并存储到 Pinecone 中。
// 定义向量数据
var vectors = new List<Vector>
{
new Vector
{
Id = "doc1",
Values = new float[] { 0.1f, 0.2f, 0.3f /* 1536 个值 */ },
Metadata = new Dictionary<string, object> { { "text", "Hello world" } }
},
new Vector
{
Id = "doc2",
Values = new float[] { 0.4f, 0.5f, 0.6f /* 1536 个值 */ },
Metadata = new Dictionary<string, object> { { "text", "Pinecone test" } }
}
};
// 插入向量
await pineconeClient.UpsertAsync("my-index", vectors);4. 查询相似向量
查询时,需要提供一个查询向量,并指定返回的结果数量(topK)。
// 查询向量
var queryVector = new float[] { 0.1f, 0.2f, 0.3f /* 1536 个值 */ };
var results = await pineconeClient.QueryAsync(
indexName: "my-index",
vector: queryVector,
topK: 5
);
// 输出结果
foreach (var result in results)
{
Console.WriteLine($"ID: {result.Id}, Score: {result.Score}");
}5. 在 Semantic Kernel 中使用 PineconeMemoryStore
以下是一个完整的示例,展示如何将 Pinecone 集成到 Semantic Kernel 中,并执行记忆存储和搜索。
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.Pinecone;
class Program
{
static async Task Main(string[] args)
{
// 初始化 Pinecone 客户端
var pineconeClient = new PineconeClient("your-api-key", "your-environment");
var memoryStore = new PineconeMemoryStore(pineconeClient, "my-index");
// 创建 Semantic Kernel 实例
var kernel = Kernel.CreateBuilder()
.AddMemoryStore(memoryStore)
.Build();
// 保存记忆
await kernel.Memory.SaveAsync(
collection: "my-collection",
key: "doc1",
value: "Hello world",
description: "A simple greeting"
);
// 搜索记忆
var searchResults = await kernel.Memory.SearchAsync(
collection: "my-collection",
query: "Hello",
limit: 5
);
// 输出搜索结果
foreach (var result in searchResults)
{
Console.WriteLine($"Key: {result.Key}, Relevance: {result.Relevance}");
}
}
}在这个示例中,PineconeMemoryStore 作为内存存储后端,Semantic Kernel 会自动将文本转换为向量并存储到 Pinecone 中,搜索时也会利用 Pinecone 的相似性匹配功能。
实际应用场景
Pinecone 和 Semantic Kernel 的结合为多种实际应用提供了强大的支持。以下是一些典型场景:
1. 推荐系统
在推荐系统中,可以将用户行为数据和物品特征转换为向量,存储在 Pinecone 中。通过查询与用户向量最相似的物品向量,实现个性化的推荐。
// 假设用户向量和物品向量已生成
var userVector = new float[] { 0.1f, 0.2f, 0.3f /* 1536 个值 */ };
var results = await pineconeClient.QueryAsync("items-index", userVector, topK: 10);
Console.WriteLine("推荐的物品:");
foreach (var result in results)
{
Console.WriteLine($"物品 ID: {result.Id}, 相似度: {result.Score}");
}2. 语义搜索
在文档管理系统中,可以将文档内容转换为向量,存储在 Pinecone 中,实现基于语义的搜索。
// 搜索与查询"人工智能"最相关的文档
var queryVector = new float[] { 0.4f, 0.5f, 0.6f /* 1536 个值 */ };
var results = await pineconeClient.QueryAsync("docs-index", queryVector, topK: 5);
foreach (var result in results)
{
Console.WriteLine($"文档 ID: {result.Id}, 相似度: {result.Score}");
}3. 图像搜索
将图像特征提取为向量后,可以利用 Pinecone 实现基于内容的图像搜索。
// 查询与目标图像相似的图像
var imageVector = new float[] { 0.7f, 0.8f, 0.9f /* 特征向量 */ };
var results = await pineconeClient.QueryAsync("images-index", imageVector, topK: 3);
foreach (var result in results)
{
Console.WriteLine($"图像 ID: {result.Id}, 相似度: {result.Score}");
}性能与可扩展性
性能分析
Pinecone 的核心优势之一是其高性能。它通过近似最近邻(ANN)搜索算法,在毫秒级别内完成大规模向量查询。根据官方数据,Pinecone 能够在数十亿向量中实现亚秒级的响应时间,非常适合实时应用。
在 Semantic Kernel 中,PineconeMemoryStore 的实现也充分利用了 Pinecone 的性能优势,确保了高效的记忆存储和检索。
可扩展性设计
Pinecone 的云原生架构支持动态扩展。开发者可以通过控制台或 API 调整索引的容量和计算资源,以满足不断增长的数据和查询需求。这种灵活性使其适用于从小规模原型到企业级应用的各种场景。
最佳实践与注意事项
-
选择合适的距离度量
根据应用需求选择合适的距离度量方式。例如,余弦相似度适用于文本嵌入,欧几里得距离适用于图像特征。
-
批量操作
在插入或查询大量向量时,使用批量操作可以显著提高效率。例如:
var largeVectors = new List<Vector> { /* 数千个向量 */ }; await pineconeClient.UpsertAsync("my-index", largeVectors); -
优化向量维度
高维度向量会增加存储和查询的成本。建议在保证准确性的前提下,使用降维技术(如 PCA)降低维度。
-
安全性
不要在代码中硬编码 API 密钥,建议使用环境变量或密钥管理服务。
-
监控性能
定期检查 Pinecone 的查询延迟和资源使用情况,及时优化配置。
结语
Pinecone 作为一个托管向量数据库,以其高性能、易用性和可扩展性,成为处理高维向量数据的首选工具。通过与 Semantic Kernel 的集成,开发者可以轻松构建智能应用,利用 Pinecone 的向量搜索能力实现语义记忆、推荐系统等功能。本文通过详细的代码示例和应用场景分析,展示了 Pinecone 的强大功能及其在实际项目中的使用方法。
无论是初学者还是经验丰富的开发者,Pinecone 和 Semantic Kernel 的组合都提供了一个高效的平台,帮助他们快速将 AI 技术落地到现实世界中。未来,随着向量搜索技术的进一步发展,Pinecone 无疑将在更多领域发挥重要作用。
参考文献
- Pinecone 官方文档:https://docs.pinecone.io/
- Semantic Kernel GitHub 仓库:https://github.com/microsoft/semantic-kernel
PineconeMemoryStoreTests.cs文件:https://github.com/microsoft/semantic-kernel/blob/main/dotnet/src/Connectors/Connectors.Pinecone.UnitTests/PineconeMemoryStoreTests.cs