博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。
技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。
主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。
🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
++感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人++
目录
[2.1 python编程](#2.1 python编程)
[2.2 爬虫技术](#2.2 爬虫技术)
[2.3 Echarts数据可视化技术](#2.3 Echarts数据可视化技术)
[2.4 MySQL数据库](#2.4 MySQL数据库)
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!

2.1 python编程
Python作为一种简洁、易学的编程语言,已成为数据分析和机器学习领域的主流工具之一。在本课题中,主要使用Python编程语言来处理二手车数据,进行数据分析、价格预测及可视化展示10。其中,Pandas 库作为Python中广泛使用的数据分析工具,在数据处理和分析中起着至关重要的作用。Pandas提供了高效且灵活的数据结构和函数,能够方便地处理一维、二维以及多维数据,极大简化了数据清洗、预处理和分析的过程。通过Pandas,用户可以轻松读取和写入各种数据格式,CSV文件、Excel文件,并且能够将数据高效存储到MySQL等数据库中。
在数据采集阶段,通过爬虫技术抓取二手车的销售数据,并利用Pandas库对数据进行清洗和处理。数据从爬取的网页中提取出来后,经过格式化和清洗,利用Pandas的DataFrame结构进行存储,确保数据的整洁与一致性。Pandas还提供了强大的数据分析功能,能够快速进行数据汇总、筛选、分组和统计分析,为后续的价格预测和市场分析提供准确的数据支持。
除了数据清洗和预处理,Pandas在数据可视化方面也有很好的支持。通过与Matplotlib或Seaborn等可视化库的结合11,Pandas能够将数据以各种形式进行展示,如折线图、柱状图、散点图等,帮助用户直观地分析二手车市场的趋势和特征。Pandas作为开源免费工具,不仅灵活高效,还能够处理大量数据,因而成为数据分析领域的主流库之一,广泛应用于各类数据处理任务,尤其适用于二手车数据的处理和分析。
2.2 爬虫技术
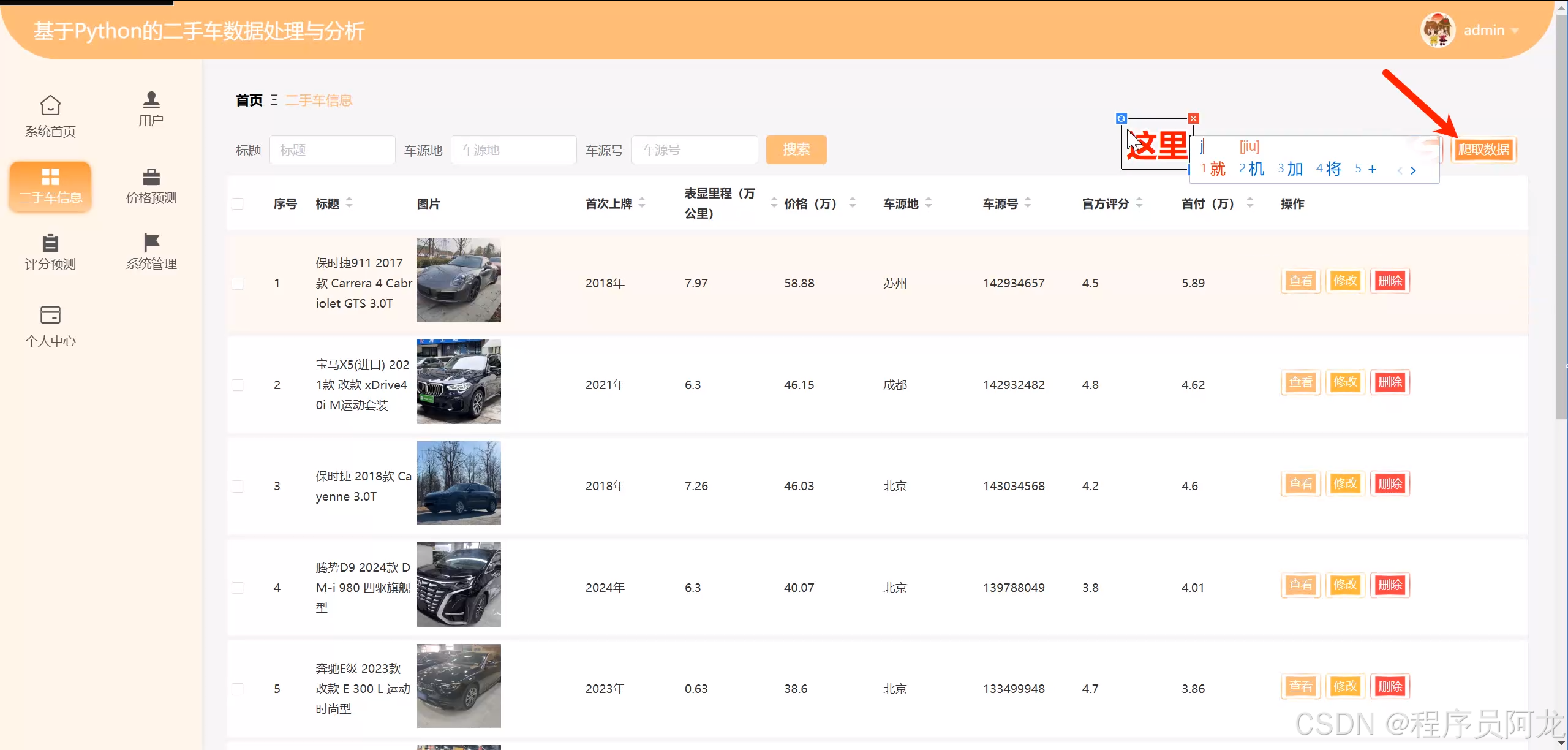
在本项目中,使用了Scrapy 框架(简称SC)来实现二手车数据的爬取。Scrapy是一个高效、灵活的Python爬虫框架,广泛应用于数据抓取和网页爬取任务。Scrapy的最大特点是其高性能和易用性12,它能够在较短时间内从多个网站抓取大量数据,并将数据以结构化格式存储。通过Scrapy框架,能够方便地获取二手车市场的相关数据,包括车辆品牌、价格、车龄、里程数等重要信息。
Scrapy框架基于异步处理和事件驱动模型,使得爬虫在抓取数据时具有很高的效率。Scrapy提供了强大的请求处理能力和数据解析功能,能够轻松处理HTML网页的解析,抓取到需要的数据后,通过内置的Pipeline组件将数据存储到不同的数据库或文件中。为了高效地存储和管理二手车数据,选择将爬取到的信息通过Pandas库导入到MySQL数据库中,确保数据的持久化存储和后续的高效查询。
Scrapy框架还支持高度的定制化,允许开发者根据具体需求自定义爬虫策略和数据存储方式。Scrapy具有强大的并发控制能力13,能够高效地抓取大量页面而不会造成网站服务器过载,这对于抓取大规模二手车数据至关重要。得益于其良好的扩展性,Scrapy可以轻松与其他库如BeautifulSoup、Lxml等结合,进一步提高数据提取的精度和效率。
2.3 Echarts数据可视化技术
Echarts是一款强大的开源数据可视化库,广泛应用于生成生动、直观、且符合交互要求的图表。由百度团队于2018年开源,并赠送给Apache基金会,成为ASF孵化级项目。Echarts具有高性能和灵活性,支持丰富的图表类型,折线图、柱状图、饼图、散点图等,并提供了强大的自定义和交互功能14,广泛应用于数据展示和分析。
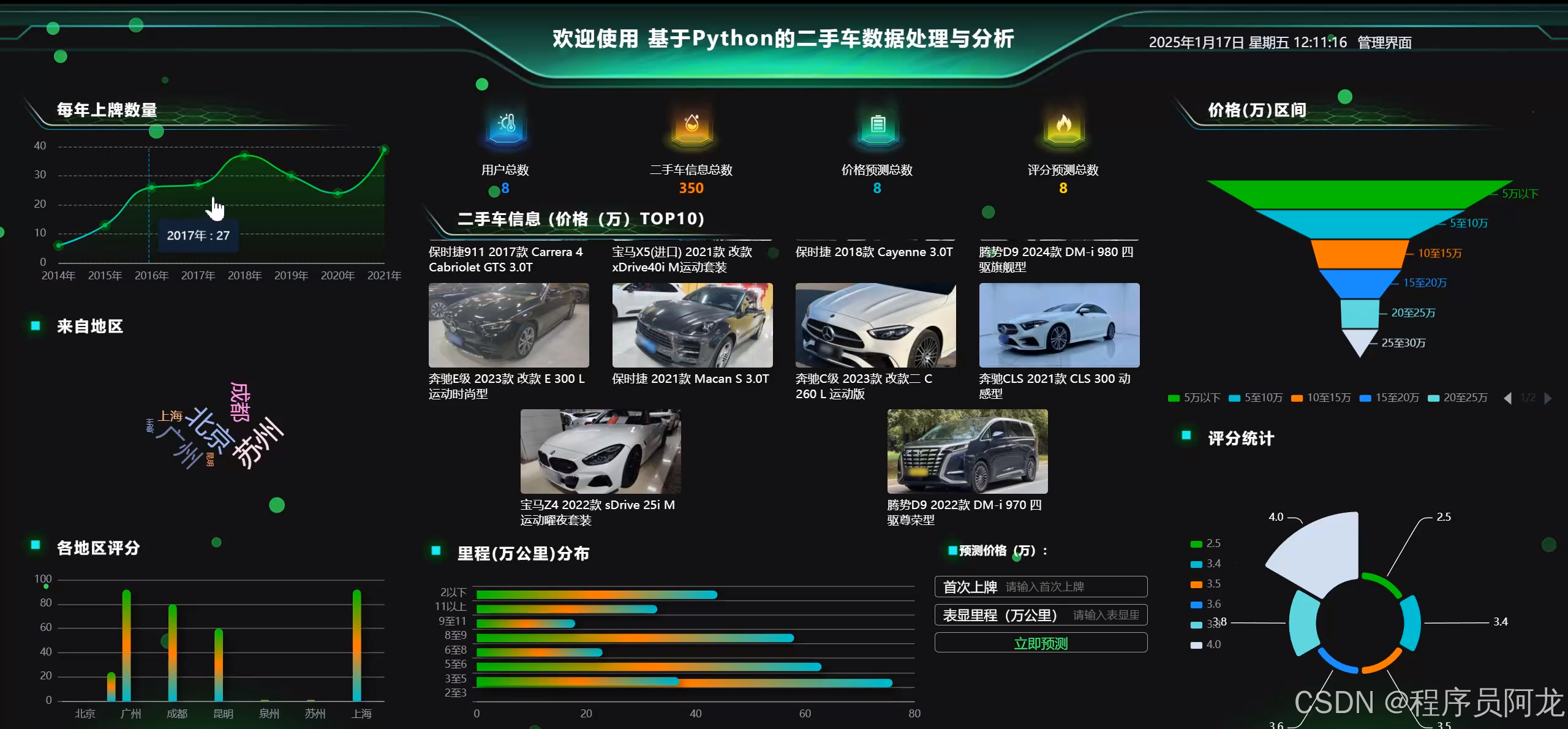
在本项目中,Echarts被用来展示二手车市场的分析结果,能够将复杂的二手车数据通过图形化的方式直观展示给用户,帮助用户更好地理解市场趋势、价格波动以及各类车型的分布情况。通过与Python结合,Echarts可以轻松地处理数据并生成动态交互式图表,使得数据分析结果不仅具有美观的展示效果,还能提供便捷的交互体验。
在具体实现中,Echarts与Python的结合充分发挥了Python在数据处理和分析中的优势。通过Python处理和清洗二手车数据后,使用Echarts将分析结果以图表的形式展示。无论是展示市场价格趋势、车型分布、各地区销售数据,还是显示车辆价格与车龄、里程的关系,Echarts都能够以清晰的图形方式呈现,提升数据展示的效果和用户体验。
Echarts支持响应式设计,能够根据不同的设备和屏幕大小自动调整图表展示,确保无论在PC端还是移动端,用户都能获得一致的交互体验。因此,Echarts成为该项目中数据可视化展示的重要工具,有助于实现二手车市场数据的深度挖掘和可视化分析。
2.4 MySQL数据库
MySQL是一种广泛使用的关系型数据库管理系统,因其高效性、简便性和开源特性,在各类数据存储和管理应用中得到广泛应用。在本项目中,MySQL被用作存储和管理二手车数据的核心数据库系统。MySQL的配置非常简单,占用的存储空间相对较小,几乎可以在普通的计算机环境下进行部署,且随着数据量的增长,能够高效地管理海量数据,确保系统的稳定性和高性能。
MySQL在本项目中扮演了至关重要的角色,负责存储和管理通过爬虫技术抓取的二手车市场数据。包括车品牌、车龄、里程、价格等各类信息。这些数据会通过爬虫工具(如Scrapy)进行采集,并通过Python中的Pandas库进行处理后,存储到MySQL数据库中。MySQL能够提供高效的查询能力,确保在大数据量的情况下,依然能保持快速的数据访问和检索。
此外,MySQL的使用界面简洁直观,具备良好的可视化支持,使得用户在进行数据管理和操作时更加便捷。其丰富的SQL语法和功能使得用户能够方便地进行数据的增删改查操作,同时也支持复杂的查询和报表生成,适应了本项目在二手车数据分析中的需求。
MySQL数据库的稳定性和高效性使其成为二手车数据可视化分析平台的首选数据库。随着信息量的增加,MySQL依然能够提供快速的查询和存储效率,并且能够处理复杂的业务逻辑,确保系统在数据量不断扩展的情况下仍能保持优异的性能。正因如此,MySQL被广泛应用于各类数据存储系统中,成为二手车数据分析平台的重要数据存储后端。

系统算法实现:
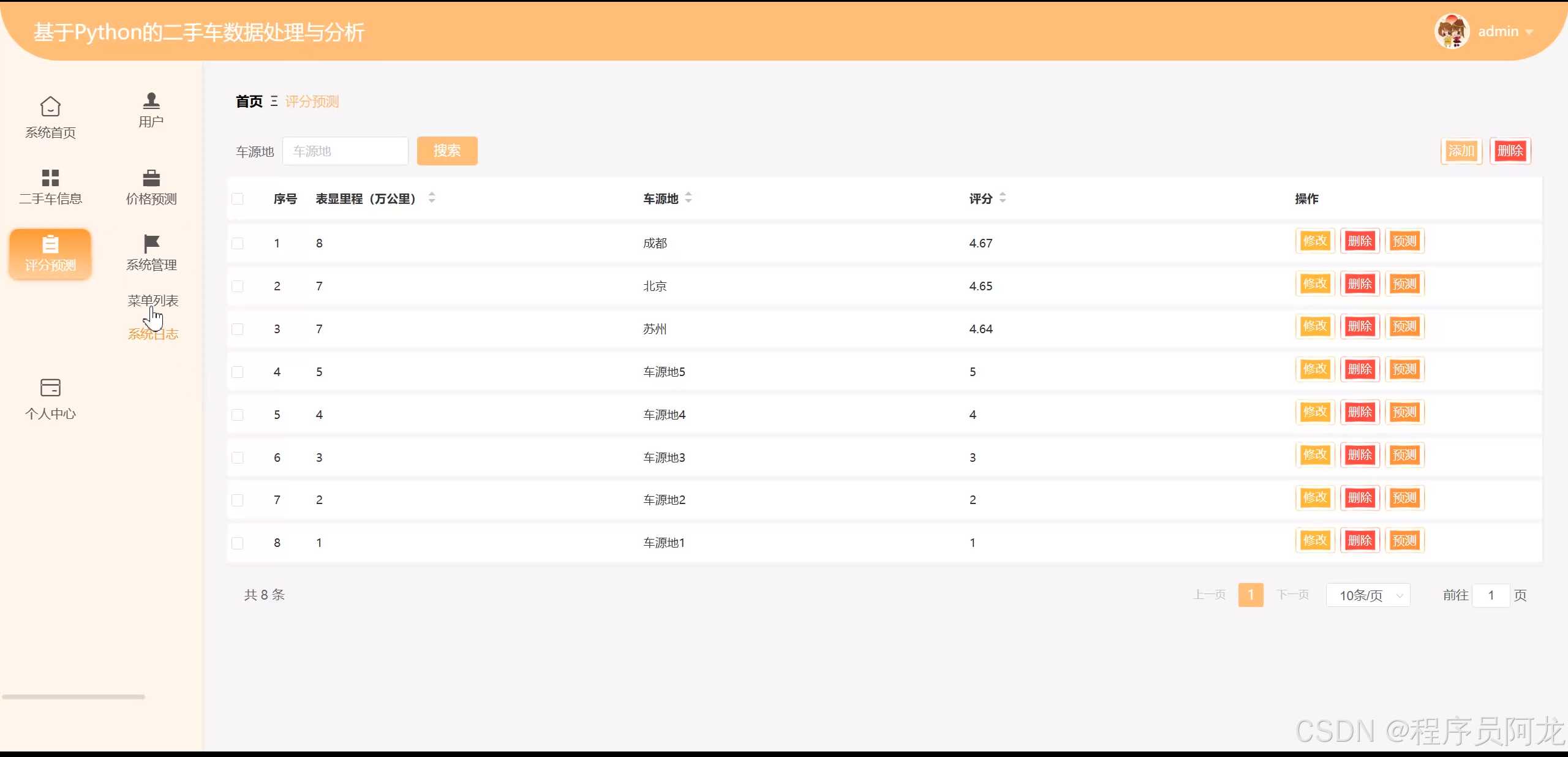

机器学习算法预测实现:
python
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, accuracy_score
# 1. 加载数据集
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target, name='species')
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 3. 训练决策树分类器
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# 4. 在测试集上做预测
y_pred = clf.predict(X_test)
# 5. 模型评估
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# 6. 对单个新样本进行预测示例
new_sample = [[5.1, 3.5, 1.4, 0.2]]
predicted_class = iris.target_names[clf.predict(new_sample)[0]]
print(f"\nNew sample {new_sample} → Predicted as: {predicted_class}")
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏