Nemotron-Research-Tool-N1如何提升大语言模型工具使用能力?
如今,大语言模型(LLMs)发展迅猛,给它配备外部工具成为研究热点。但传统方法存在不少问题。这篇论文提出的Nemotron-Research-Tool-N1系列模型带来新突破,用创新方式训练模型,在多个基准测试中表现超厉害,一起来了解下吧!
论文标题
Nemotron-Research-Tool-N1: Tool-Using Language Models with Reinforced Reasoning
来源
arXiv:2505.00024v1 cs.CL 25 Apr 2025
https://arxiv.org/abs/2505.00024
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
最近这几年,大语言模型(LLMs)越来越火,给它搭配外部工具也成了热门研究方向。当LLMs和搜索引擎一起工作,就能回答各种新知识的问题;和Python解释器合作,复杂数学题也不在话下,这些工具大大拓展了LLMs的能力。不过现在的方法有不少问题。很多研究靠合成工具使用数据然后微调模型,但这些数据里推理步骤不清晰,训练时模型也学不到推理过程。还有人从厉害的模型里提取推理轨迹来训练新模型,可新模型只是模仿表面,没真正学会怎么合理使用工具。这些问题都影响着LLMs更好地利用工具。
研究问题
-
现有提升大语言模型工具调用能力的研究,合成的工具使用轨迹数据常缺少明确推理步骤,训练时往往只监督工具调用步骤,忽略推理过程指导,导致推理在训练阶段被忽视或延迟到推理阶段。
-
从先进模型提取推理轨迹再通过监督微调(SFT)训练student模型的方法,容易让模型产生伪推理,只是模仿表面的模式,没有真正地掌握决策过程。
-
传统基于SFT的方法对大规模高质量数据依赖严重,泛化能力有限。
主要贡献
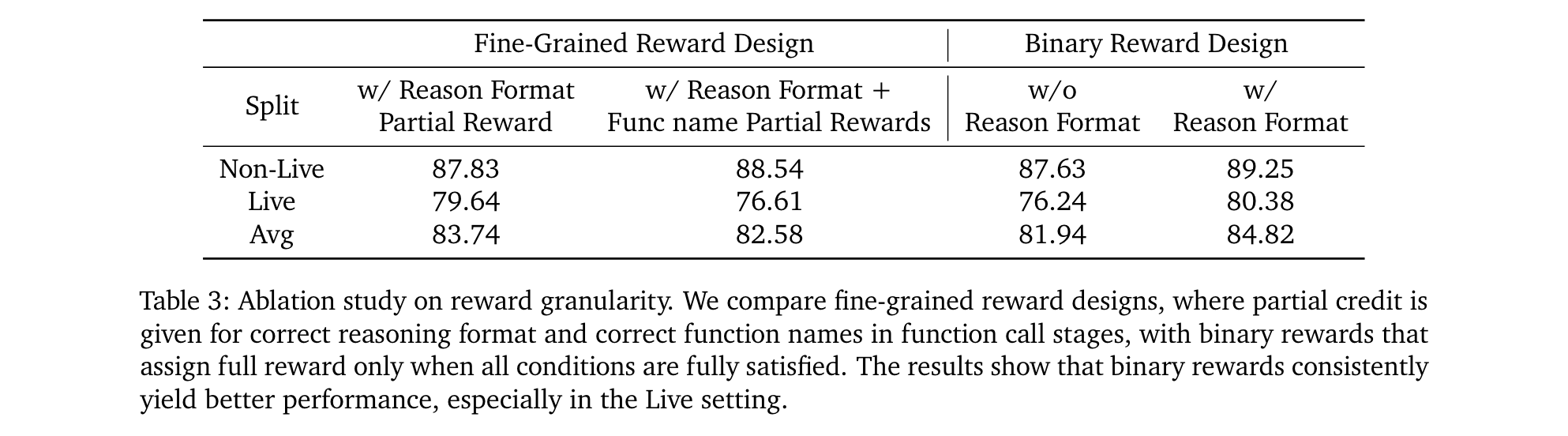
1. 创新训练范式:受DeepSeek-R1启发,采用基于规则的强化学习训练大语言模型,设计简单的结构化推理 - 行动格式,让模型在调用工具前进行明确推理。与以往依赖精确的下一步令牌预测和严格输出匹配的SFT不同,这种方法只评估工具调用的结构有效性和功能正确性,模型能自主内化推理策略,无需标注推理轨迹。
2. 卓越性能表现:在BFCL和API-Bank基准测试中,基于Qwen-2.5-7B/14B-Instruct构建的Nemotron-Research-Tool-N1-7B和Nemotron-Research-Tool-N1-14B模型,全面超越GPT-4o等强大基线模型,证明了该训练范式的有效性。
3. 有效利用数据:统一并预处理来自xLAM和ToolACE的工具调用轨迹数据,将其融入强化学习训练。通过标准化数据格式、过滤无效样本等操作,得到适合训练的数据集,充分利用了现有数据资源。
方法论精要
1. 算法框架:GRPO驱动的智能工具调用
这篇论文的核心创新在于采用GRPO(Generalized Reinforcement Policy Optimization)强化学习算法来构建Nemotron-Research-Tool-N1框架。简单来说,模型的工作流程是这样的:首先根据对话历史和可用工具列表生成多个可能的响应选项,然后通过精心设计的奖励函数对这些响应进行评分,最后利用GRPO算法来优化模型策略。特别值得注意的是,整个过程都受到KL散度的约束,确保模型更新不会偏离原始策略太远。
2. 参数设计的巧思
在训练参数设置上,作者团队做了不少精心的考量:
- 采用较大的batch size(1024)来保证训练稳定性
- 设置较低的学习率(1e-6)实现更精细的参数调整
- 固定temperature为0.7,在生成多样性和准确性之间取得平衡
- 将entropy coefficient设为0,避免不必要的探索干扰
- 引入1e-3的KL散度约束,防止策略更新过于激进
这些参数的组合既确保了训练过程的平稳进行,又有效提升了模型使用工具的能力。
3. 创新技术组合
这篇论文的技术创新主要体现在两个方面:
- 采用了轻量化的prompt模板设计,要求模型在特定标签内完成推理和工具调用。这种结构化的处理方式不仅规范了模型的输出格式,更重要的是鼓励模型进行自主推理。
- 创新性地设计了二元奖励机制。这个奖励函数会同时评估:
✓ 推理格式的正确性
✓ 工具调用的准确性(包括工具名称和参数) - 比较人性化的是,这个评估允许参数顺序的变化,更注重语义层面的正确理解,而不是死板的格式匹配。

4. 实验设计
数据集选择:
- ToolACE:覆盖多种工具调用场景
- xLAM:专注单轮函数调用
模型配置:
- 以Qwen2.5-7B/14B-Instruct为主要实验对象
- 同时测试了LLaMA系列等其他模型作为参照
对比基线:
- GPT系列、Gemini2.0等通用大模型
- ToolACE-8B、xLAM-2等专用工具调用模型
评估标准:
- BFCL基准(包含Non-live和Live子集)
- API-Bank基准(专注单轮调用)
- 统一采用准确率作为核心评估指标
实验洞察
1. 性能表现:显著超越GPT-4o
在BFCL基准测试中,Nemotron-Research-Tool-N1-7B 和 -14B 展现出了强大的竞争力,整体表现优于GPT-4o等主流模型。具体来看:
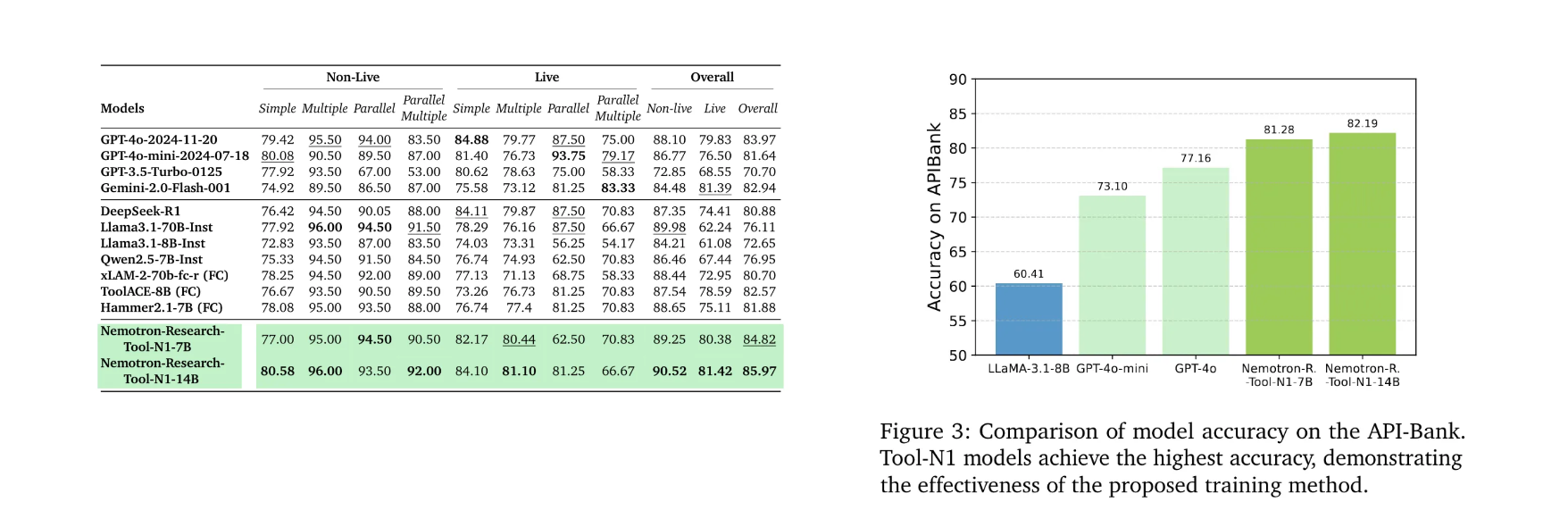
- 在 Non-Live + Live 综合评估 中,Tool-N1-7B的平均准确率达到 84.82%,而更大的14B版本进一步提升至 85.97%。
- 在 API-Bank 测试中,这两个模型同样表现亮眼,分别比GPT-4o高出 4.12% 和 5.03%,显示出明显的优势。
2. 关键消融实验:结构化推理至关重要
论文通过消融实验验证了几个关键设计:
- 奖励机制对比:二元奖励(Binary Reward)比细粒度奖励表现更好,特别是在 Live 子集 上(80.38% vs. 76.61%)。
- 推理格式的影响:如果去掉结构化推理的约束,性能会明显下降(从80.38%→76.24%),证明清晰的推理格式对工具调用的可靠性至关重要。
- 训练数据的影响 :
- R1风格的训练策略 比传统SFT更能提升工具调用能力。
- ToolACE数据 对模型在实时场景(Live)下的表现提升尤为显著。