目录
[2.1 Q-learning强化学习原理](#2.1 Q-learning强化学习原理)
[2.2 基于Q-learning的电梯群控系统建模](#2.2 基于Q-learning的电梯群控系统建模)
1.算法仿真效果
matlab2022a仿真结果如下**(完整代码运行后无水印)**:
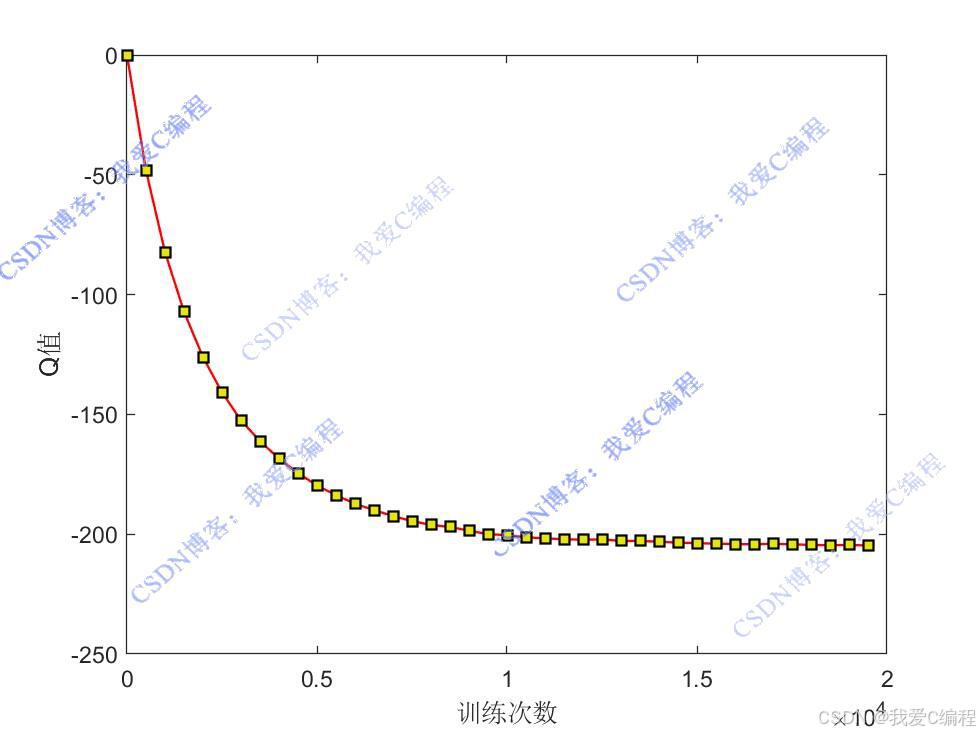
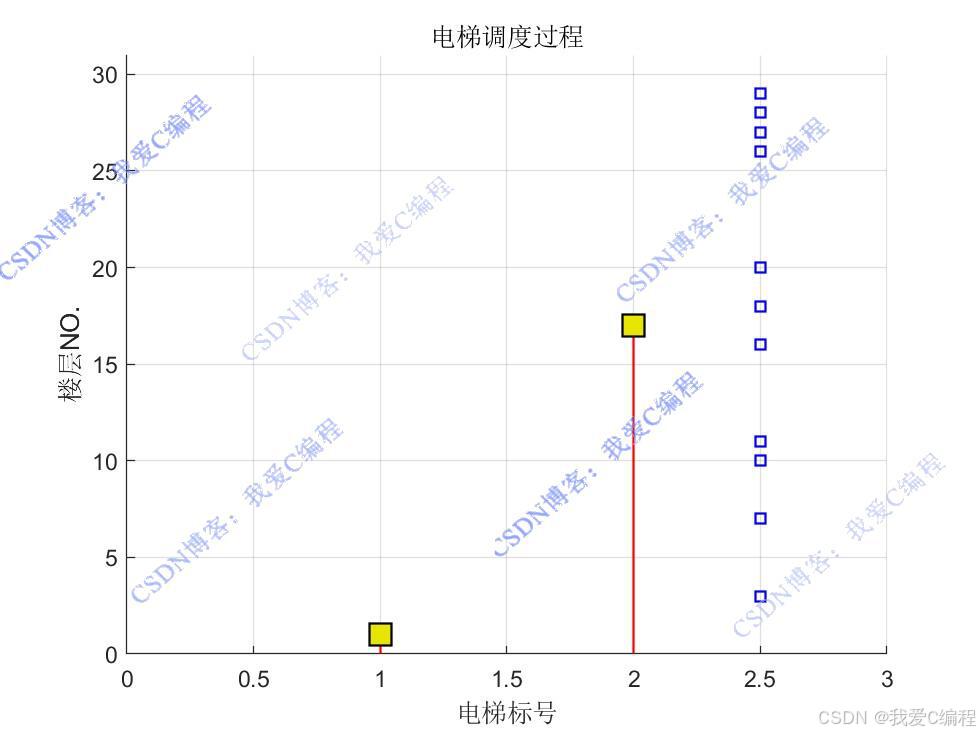
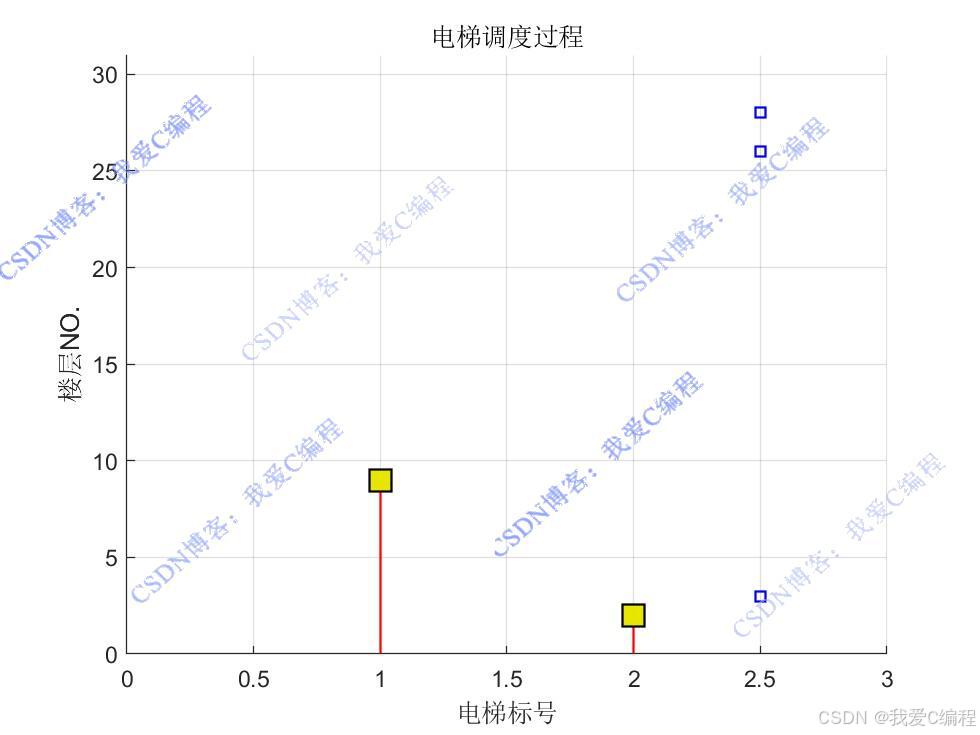
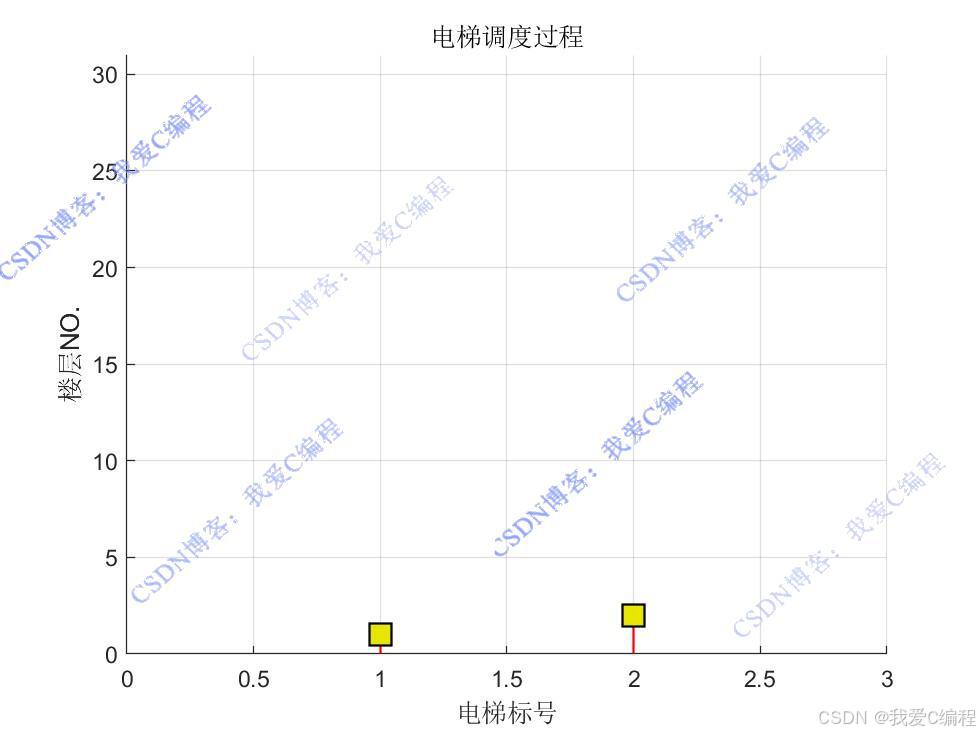
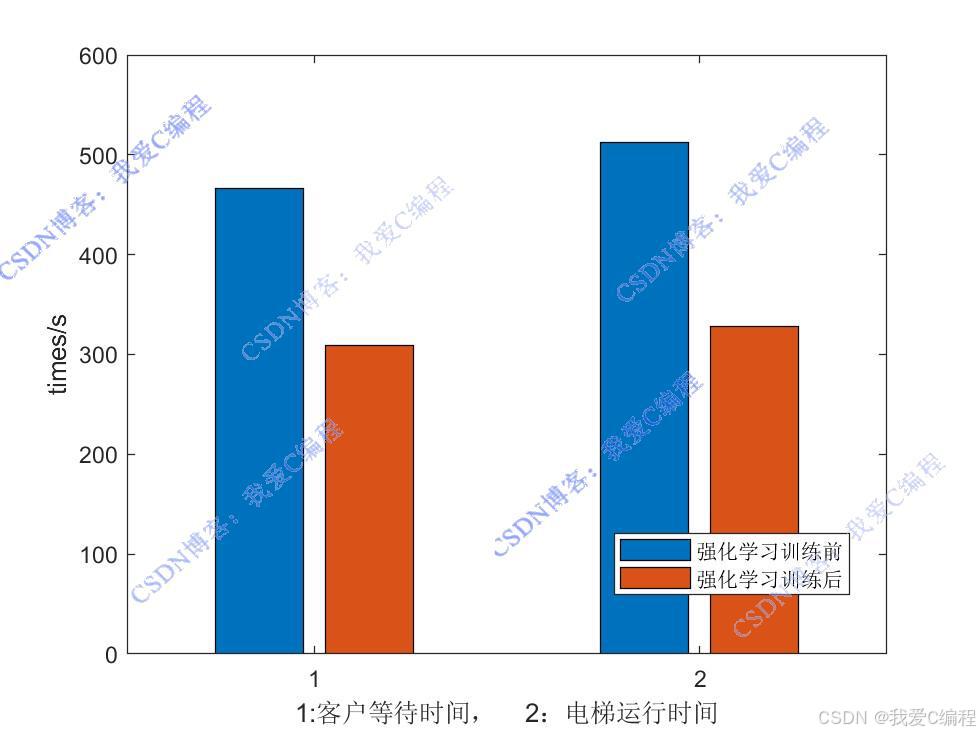
仿真操作步骤可参考程序配套的操作视频。
2.算法涉及理论知识概要
随着高层建筑的不断增多,电梯成为人们日常生活中不可或缺的垂直交通工具。电梯群控系统(Elevator Group Control System,EGCS)旨在对多台电梯进行统一调度,以提高电梯的运行效率,减少乘客的等待时间和乘梯时间,提升服务质量。传统的电梯群控算法往往基于固定的规则和经验,难以适应复杂多变的交通流量模式。而强化学习作为一种能够通过智能体与环境交互来学习最优策略的方法,为电梯群控系统的优化提供了新的思路。Q - learning 是一种经典的无模型强化学习算法,它通过不断更新 Q 表来学习最优动作价值函数,从而实现对环境的最优控制。
电梯群控系统的主要调度目标包括:
1.减少乘客等待时间:使乘客从发出请求到进入电梯的时间尽可能短。
2.减少乘客乘梯时间:使乘客在电梯内的旅行时间尽可能短。
2.1 Q-learning强化学习原理
强化学习是一种通过智能体(Agent)与环境(Environment)进行交互来学习最优策略的机器学习方法。智能体在环境中执行动作(Action),环境根据智能体的动作给出奖励(Reward)和下一个状态(State)。智能体的目标是通过不断地与环境交互,学习到一种最优策略,使得累积奖励最大化。
Q-learning 是一种无模型的强化学习算法,它通过学习动作价值函数Q(s, a) 来确定最优策略。动作价值函数Q(s, a)表示在状态s下执行动作a后,能够获得的累积奖励的期望值。
Q-learning 算法的核心思想是使用一个Q表来存储每个状态 - 动作对的Q值。在每个时间步,智能体根据当前状态s选择一个动作a,执行该动作后,环境返回下一个状态s'和奖励r。然后,智能体使用以下公式更新Q表中的Q值:

2.2 基于Q-learning的电梯群控系统建模
状态定义
在电梯群控系统中,状态 s 可以由多个因素组成,例如:
1.电梯位置:每台电梯当前所在的楼层。
2.电梯运行方向:每台电梯的运行方向(上行、下行或静止)。
3.请求队列:当前所有未处理的乘客请求,包括请求的起始楼层和目标楼层。
动作定义
动作a表示为哪个电梯去响应当前的一个请求。假设系统中有n台电梯,则动作空间A={1,2,⋯,n},其中动作i表示选择第i台电梯去响应请求。
奖励定义
奖励r是环境对智能体执行动作的反馈,用于引导智能体学习最优策略。在电梯群控系统中,奖励可以根据以下因素进行设计:
1.乘客等待时间:乘客等待时间越短,奖励越高。
2.乘客乘梯时间:乘客乘梯时间越短,奖励越高。
3.电梯运行效率:电梯的空驶时间和不必要的停靠次数越少,奖励越高。
3.MATLAB核心程序
.............................................................
%%
load R2.mat
% 测试调度策略并生成动画
elevator_positions = ones(1, num_elevators);
request_queue = [];
num_requests = randi([Num_people/2, Num_people]);
for i = 1:num_requests
start_floor = randi([1, num_floors]);
end_floor = randi([1, num_floors]);
while end_floor == start_floor
end_floor = randi([1, num_floors]);
end
request_queue = [request_queue; start_floor, end_floor];
end
total_waiting_time = 0;
total_travel_time = 0;
num_requests = size(request_queue, 1);
while ~isempty(request_queue)
% 获取当前状态
state = get_state(elevator_positions, request_queue);
% 选择动作
[~, action] = max(Q(state, :));
% 执行动作
[new_elevator_positions, new_request_queue, reward, waiting_time, travel_time] = take_action(elevator_positions, request_queue, action);
% 更新电梯位置和请求队列
elevator_positions = new_elevator_positions;
request_queue = new_request_queue;
% 累计指标
total_waiting_time = total_waiting_time + waiting_time;
total_travel_time = total_travel_time + travel_time;
end
% 输出最终指标
total_waiting_time2=total_waiting_time;
total_travel_time2=total_travel_time;
figure;
bar([total_waiting_time1,total_waiting_time2;total_travel_time1,total_travel_time2]);
ylabel('times/s');
xlabel('1:客户等待时间, 2:电梯运行时间');
legend('强化学习训练前','强化学习训练后');
0Z_020m4.完整算法代码文件获得
V