目录
[1. 透视](#1. 透视)
[1.1 pivot](#1.1 pivot)
[1.2 pivot_table](#1.2 pivot_table)
1. 透视
透视是长表变宽表。
pivot() 和 pivot_table()两个函数都可以做到,后者可以聚合前者不行。
| 特性 | df.pivot() |
df.pivot_table() |
|---|---|---|
| 重复值处理 | 要求索引和列的组合唯一,否则报错 ValueError |
允许重复值,通过聚合函数(如均值、求和等)处理 |
| 聚合功能 | 不支持聚合,仅用于数据重组 | 支持聚合(默认 aggfunc='mean') |
| 多值列处理 | 无法处理多值列(需唯一索引-列组合) | 自动聚合多值(如求和、均值等) |
| 灵活性 | 简单场景适用(无重复值) | 复杂场景适用(支持重复值和自定义聚合) |
示例数据:
python
import pandas as pd
data = {
'Year': [2020, 2020, 2021, 2021, 2020, 2020],
'Product': ['A', 'A', 'A', 'B', 'B', 'B'],
'Region': ['East', 'West', 'East', 'West', 'East', 'West'],
'Sales': [100, 150, 200, 50, 120, 90]
}
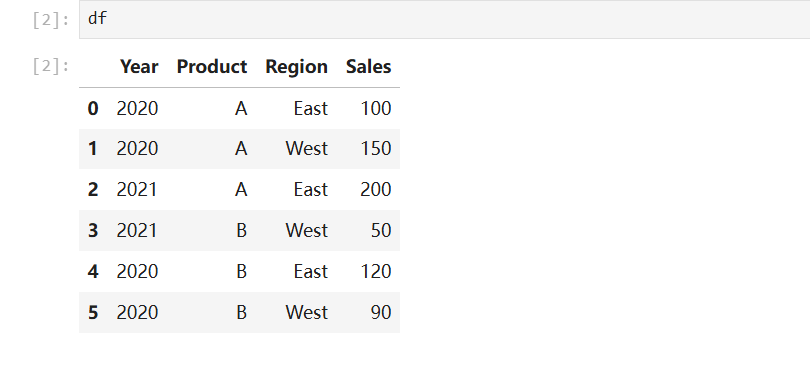
df = pd.DataFrame(data)原表:
1.1 pivot
| 参数 | 说明 | 默认值 | 示例 |
|---|---|---|---|
index |
作为行索引的列名(可以是单个列名或列表) | None |
index='Region' |
columns |
作为列名的列名(可以是单个列名或列表) | None |
columns='Year' |
values |
作为填充值的列名(可以是单个列名或列表,选填) | None |
values='Sales' |
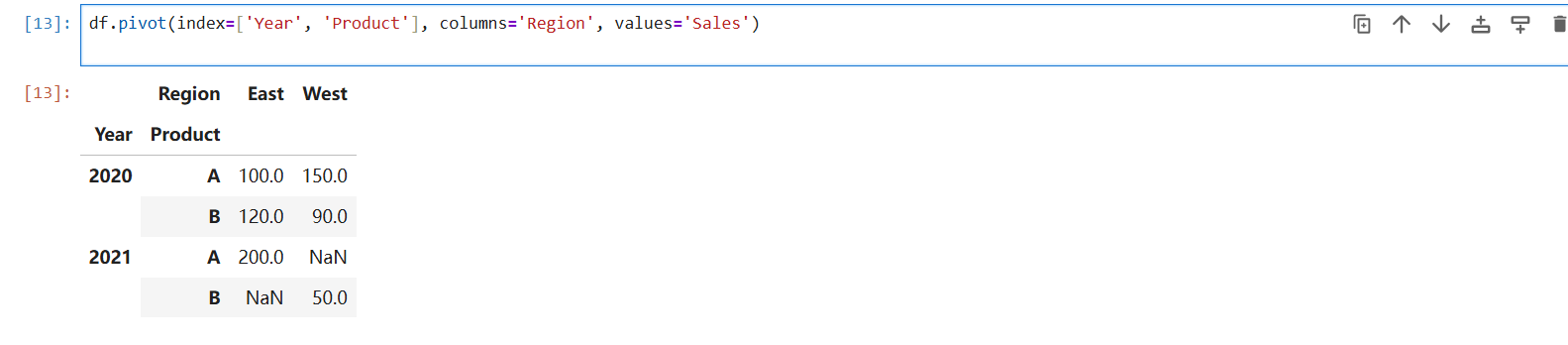
指定index是转换后的索引,不能重复,如果单独是Year 则会报错:
ValueError: Index contains duplicate entries, cannot reshape
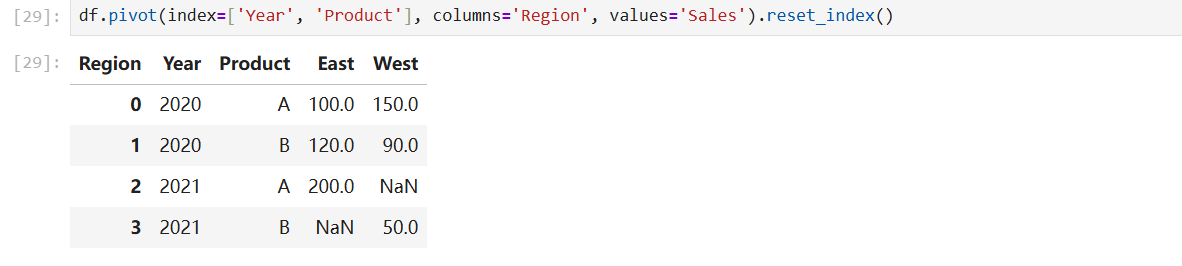
 重置一下行索引:
重置一下行索引:
1.2 pivot_table
| 参数 | 说明 | 默认值 | 示例 |
|---|---|---|---|
index |
作为行索引的列名(可以是单个列名或列表) | None |
index='Region' |
columns |
作为列名的列名(可以是单个列名或列表) | None |
columns='Year' |
values |
作为填充值的列名(可以是单个列名或列表,选填) | None |
values='Sales' |
aggfunc |
聚合函数(如 'sum', 'mean', 'count' 或自定义函数) |
'mean' |
aggfunc='sum' |
fill_value |
填充缺失值的值 | None |
fill_value=0 |
margins |
是否添加总计行/列(True/False) |
False |
margins=True |
margins_name |
总计行/列的标签名 | 'All' |
margins_name='Total' |
dropna |
是否删除全为 NaN 的列(True/False) |
True |
dropna=False |
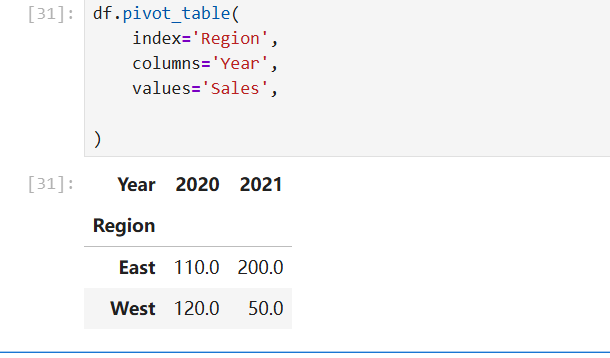
index指定的索引值可以重复,相当于根据该值进行分组,自动进行聚合(默认聚合函数median)例子以地区为索引,以Year为列,求每年的Sales的均值
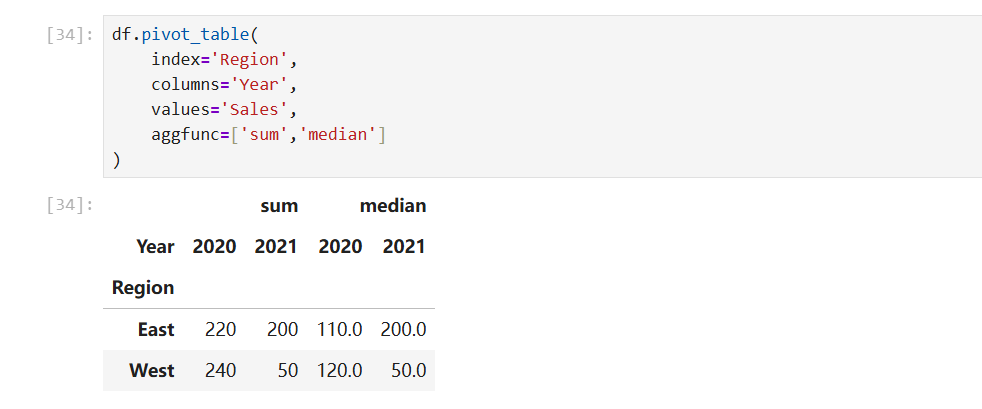
- 自定义聚合函数
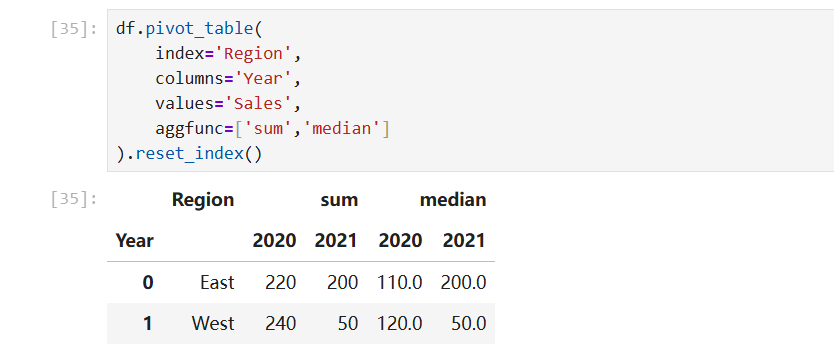
同样重置索引:
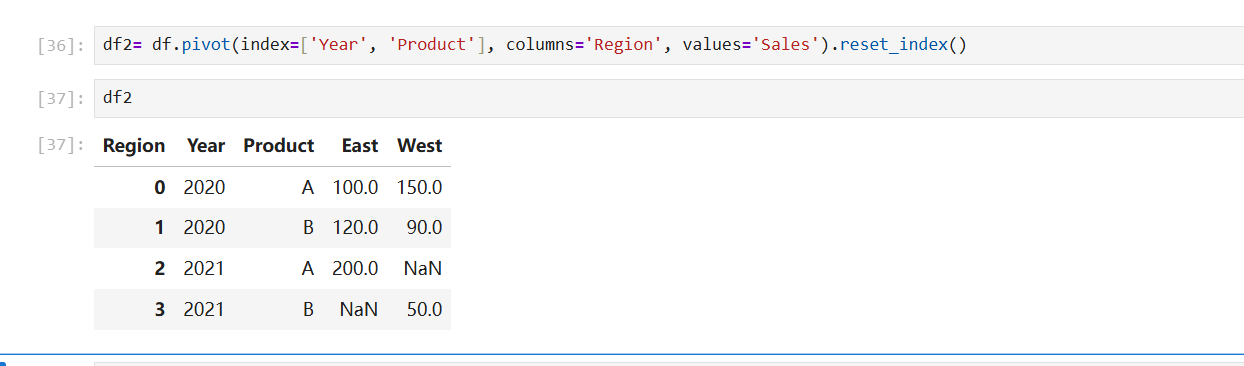
2.逆透视
melt()函数,指定宽表变长表
| 参数 | 说明 | 默认值 | 示例 |
|---|---|---|---|
id_vars |
保留的标识列(不参与转换,可以是单个列名或列表) | None |
id_vars=['Year', 'Product'] |
value_vars |
需要转换的列(可以是单个列名或列表,默认转换所有非 id_vars 列) |
None |
value_vars=['Sales'] |
var_name |
存储原列名的列名(新生成的"变量列") | 'variable' |
var_name='Category' |
value_name |
存储原列值的列名(新生成的"值列") | 'value' |
value_name='Revenue' |
col_level |
多层列索引时指定要转换的层级(用于 MultiIndex 列) |
None |
col_level=0 |
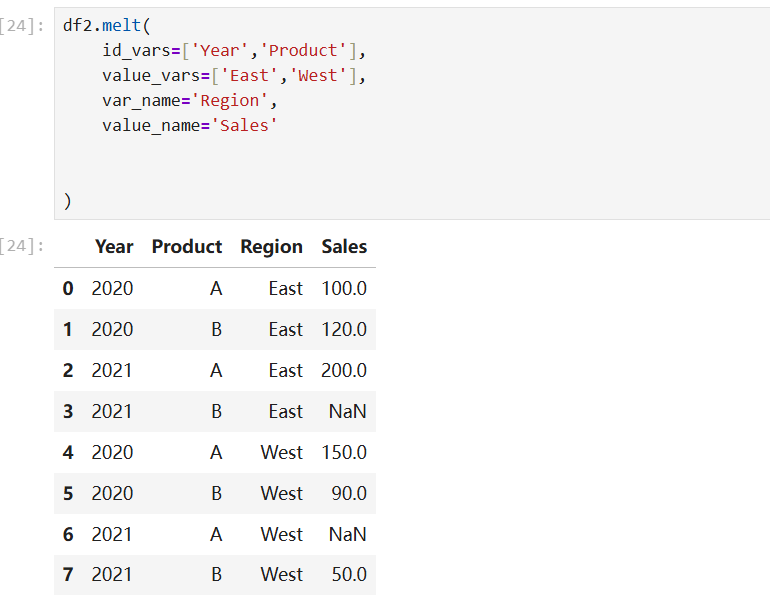
以上面透视的结果为例:
逆透视: