深度学习之LSTM时序预测入门指南:从原理到实战

一、LSTM核心原理:让机器学会"选择性记忆"
1. 为什么LSTM适合时序预测?
传统神经网络(如全连接层)无法捕捉时间序列的先后依赖,而LSTM作为循环神经网络(RNN)的改进版,通过门控机制解决了梯度消失问题,能有效记忆长期依赖。
- 场景举例:预测明日股价时,LSTM可选择性记住"30天前的大涨",忽略"昨日的小幅波动"。
2. 三个"门"掌控信息流动
LSTM通过三个"门"实现对信息的筛选与控制:
- 遗忘门(Forget Gate):决定丢弃哪些旧信息(如短期噪声)。
- 输入门(Input Gate):选择接纳哪些新信息(如突破关键均线的信号)。
- 输出门(Output Gate):控制输出用于预测的信息(如收益率的非线性组合)。
二、数据预处理:构建LSTM可识别的"时光窗口"
1. 三维数据结构(核心输入格式)
LSTM要求输入数据为 [样本数, 时间步长, 特征数] 的三维张量:
- 示例 :用过去60天数据预测第61天股价,时间步长=60,特征包含收盘价、5日均线、10日均线、波动率(共4个特征),则单个样本形状为
(60, 4)。 - 意义:时间步长决定模型"记忆力",需平衡短期波动与长期趋势(如60天适合捕捉中短期模式)。
2. 滚动窗口标准化(避免未来信息泄漏)
- 传统陷阱:全局标准化(用全部数据算均值/标准差)会"偷看"未来数据,导致回测结果虚高。
- 正确方法 :用过去N天数据 (如60天)动态计算当前标准化值,模拟实时数据流:
z t = x t − μ t − 60 : t σ t − 60 : t z_t = \frac{x_t - \mu_{t-60:t}}{\sigma_{t-60:t}} zt=σt−60:txt−μt−60:t
其中, μ \mu μ 为窗口均值, σ \sigma σ 为窗口标准差,确保每个时间点的预处理仅依赖历史数据。
三、LSTM单元结构详解:从数学公式到代码实现
1. 门控机制的数学表达
LSTM的核心是通过 三个门控单元 控制信息流动,其内部计算过程可用以下公式严格描述:
i t = σ ( W i ⋅ h t − 1 , x t + b i ) (输入门) f t = σ ( W f ⋅ h t − 1 , x t + b f ) (遗忘门) g t = tanh ( W g ⋅ h t − 1 , x t + b g ) (候选记忆) o t = σ ( W o ⋅ h t − 1 , x t + b o ) (输出门) c t = f t ⊙ c t − 1 + i t ⊙ g t (细胞状态更新) h t = o t ⊙ tanh ( c t ) (隐藏状态输出) \begin{aligned} i_t &= \sigma(W_i \cdot h_{t-1}, x_t + b_i) \quad \text{(输入门)} \\ f_t &= \sigma(W_f \cdot h_{t-1}, x_t + b_f) \quad \text{(遗忘门)} \\ g_t &= \tanh(W_g \cdot h_{t-1}, x_t + b_g) \quad \text{(候选记忆)} \\ o_t &= \sigma(W_o \cdot h_{t-1}, x_t + b_o) \quad \text{(输出门)} \\ c_t &= f_t \odot c_{t-1} + i_t \odot g_t \quad \text{(细胞状态更新)} \\ h_t &= o_t \odot \tanh(c_t) \quad \text{(隐藏状态输出)} \end{aligned} itftgtotctht=σ(Wi⋅ht−1,xt+bi)(输入门)=σ(Wf⋅ht−1,xt+bf)(遗忘门)=tanh(Wg⋅ht−1,xt+bg)(候选记忆)=σ(Wo⋅ht−1,xt+bo)(输出门)=ft⊙ct−1+it⊙gt(细胞状态更新)=ot⊙tanh(ct)(隐藏状态输出)
公式拆解(以遗忘门为例):
- 输入 :当前时刻输入 x t x_t xt 和上一时刻隐藏状态 h t − 1 h_{t-1} ht−1 拼接成向量 h t − 1 , x t h_{t-1}, x_t ht−1,xt。
- 线性变换 :通过权重矩阵 W f W_f Wf 和偏置 b f b_f bf 进行线性变换( W f ⋅ h t − 1 , x t + b f W_f \cdot h_{t-1}, x_t + b_f Wf⋅ht−1,xt+bf)。
- 激活函数 :Sigmoid函数将结果映射到 0 , 1 0, 1 0,1,表示"遗忘概率"(0=完全遗忘,1=完全保留)。
2. 变量说明(类比现实场景理解)
| 符号 | 名称 | 作用描述 | 类比举例 |
|---|---|---|---|
| i t i_t it | 输入门 | 决定"接纳多少新信息",输出0-1之间的概率,控制候选记忆 g t g_t gt 的流入量。 | 海关安检:筛选允许进入仓库的货物。 |
| f t f_t ft | 遗忘门 | 决定"丢弃多少旧信息",输出0-1之间的概率,控制旧细胞状态 c t − 1 c_{t-1} ct−1 的保留量。 | 仓库管理员:定期清理过时货物。 |
| g t g_t gt | 候选记忆 | 临时存储当前时刻提取的新特征(经tanh激活),等待输入门筛选。 | 待入库的新货物清单。 |
| o t o_t ot | 输出门 | 决定"输出多少信息",控制隐藏状态 h t h_t ht 的生成,仅输出部分关键信息。 | 快递分拣:按目的地筛选待发货货物。 |
| c t c_t ct | 细胞状态 | 长期记忆存储单元,整合遗忘门和输入门的决策,保存历史关键信息。 | 仓库库存:记录所有入库/出库后的剩余货物。 |
| h t h_t ht | 隐藏状态 | 短期记忆输出,包含当前时刻用于预测的关键信息(如股价趋势)。 | 快递单据:包含本次运输的关键信息。 |
| σ \sigma σ | Sigmoid函数 | 将数值映射到0-1,用于生成概率值(如遗忘概率、输入概率)。 | 概率开关:0-1之间的调节旋钮。 |
| ⊙ \odot ⊙ | 逐元素相乘 | 按元素位置相乘(如遗忘门输出与旧细胞状态相乘,仅保留对应位置的信息)。 | 货物筛选:按清单逐项核对保留货物。 |
3. 简化版Python代码实现(单细胞计算)
python
import numpy as np
# 假设已定义好权重和偏置(实际训练中由模型自动学习)
W_i = np.random.randn(128, 128 + 4) # 输入门权重(隐藏状态128维 + 特征4维)
b_i = np.random.randn(128) # 输入门偏置
W_f = np.random.randn(128, 128 + 4) # 遗忘门权重
b_f = np.random.randn(128)
W_g = np.random.randn(128, 128 + 4) # 候选记忆权重
b_g = np.random.randn(128)
W_o = np.random.randn(128, 128 + 4) # 输出门权重
b_o = np.random.randn(128)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def lstm_cell(input, hidden_state, cell_state):
# 拼接上一时刻隐藏状态和当前输入(形状:[隐藏状态维度 + 特征维度])
concat = np.concatenate([hidden_state, input], axis=-1)
# 输入门:计算接纳新信息的概率
i = sigmoid(W_i @ concat + b_i) # 输出形状与隐藏状态一致(128维)
# 遗忘门:计算丢弃旧信息的概率
f = sigmoid(W_f @ concat + b_f)
# 候选记忆:生成待筛选的新信息(-1到1之间)
g = np.tanh(W_g @ concat + b_g)
# 更新细胞状态:遗忘旧信息 + 接纳新信息
new_cell = f * cell_state + i * g # 逐元素相乘(形状不变)
# 输出门:计算输出信息的概率
o = sigmoid(W_o @ concat + b_o)
# 新隐藏状态:仅输出细胞状态中被选中的部分
new_hidden = o * np.tanh(new_cell)
return new_hidden, new_cell4. 公式与代码的对应关系
| 数学公式 | 代码实现 | 核心作用 |
|---|---|---|
| h t − 1 , x t h_{t-1}, x_t ht−1,xt | np.concatenate([hidden_state, input], ...) |
拼接历史信息与当前输入 |
| σ ( ⋅ ) \sigma(\cdot) σ(⋅) | sigmoid(x) |
生成0-1之间的概率值 |
| tanh ( ⋅ ) \tanh(\cdot) tanh(⋅) | np.tanh(x) |
生成-1到1之间的候选特征 |
| f t ⊙ c t − 1 f_t \odot c_{t-1} ft⊙ct−1 | f * cell_state |
按概率遗忘旧细胞状态 |
| i t ⊙ g t i_t \odot g_t it⊙gt | i * g |
按概率接纳新候选记忆 |
| o t ⊙ tanh ( c t ) o_t \odot \tanh(c_t) ot⊙tanh(ct) | o * np.tanh(new_cell) |
按概率输出最终隐藏状态 |
四、模型搭建:从数据到预测的核心架构
1. LSTM层:提取时序特征的"时光机"
python
model = Sequential([
LSTM(units=128, # 神经元数量,控制模型复杂度
activation='tanh', # 内部激活函数,输出候选记忆
input_shape=(60, 4), # 输入形状:[时间步长, 特征数]
return_sequences=False # 仅输出最后一个时间步的隐藏状态
),
Dropout(0.3), # 随机丢弃30%神经元,防止过拟合
Dense(64, activation='relu'), # 全连接层,提取高层特征
Dense(1) # 输出单个预测值(如股价涨幅)
])2. Huber Loss:平衡异常值的损失函数
- 公式 :
L δ ( y , y ^ ) = { 1 2 ( y − y ^ ) 2 ∣ y − y ^ ∣ ≤ δ δ ∣ y − y ^ ∣ − 1 2 δ 2 其他 L_\delta(y, \hat{y}) = \begin{cases} \frac{1}{2}(y-\hat{y})^2 & |y-\hat{y}| \leq \delta \\ \delta|y-\hat{y}| - \frac{1}{2}\delta^2 & \text{其他} \end{cases} Lδ(y,y^)={21(y−y^)2δ∣y−y^∣−21δ2∣y−y^∣≤δ其他 - 优势 :当误差较小时( ∣ y − y ^ ∣ ≤ 1 |y-\hat{y}| \leq 1 ∣y−y^∣≤1)采用均方误差(MSE),误差较大时转为平均绝对误差(MAE),对异常值(如股价暴跌)更鲁棒。
好的!以下是在博文中新增 "LSTM单元结构详解" 章节的完整内容,包含公式、变量说明和代码示例,已融入原文逻辑:
五、实战关键步骤:从代码到落地
1. 数据生成与加载(模拟/真实数据通用)
模拟数据(快速验证)
python
def generate_data(num_days=1000):
np.random.seed(42)
dates = pd.date_range(start='2020-01-01', periods=num_days, freq='D')
close = 100 + np.cumsum(np.random.randn(num_days)) # 模拟收盘价(随机游走)
ma5 = pd.Series(close).rolling(5).mean().fillna(close[0]) # 5日均线
return pd.DataFrame({'date': dates, 'close': close, 'ma5': ma5})真实数据(以股票为例)
-
从Yahoo Finance下载CSV,包含
Date(日期)、Close(收盘价)等列。 -
加载并预处理:
pythondef load_real_data(file_path): data = pd.read_csv(file_path, parse_dates=['Date']) data = data.rename(columns={'Date': 'date', 'Close': 'close'}).sort_values('date') data['ma5'] = data['close'].rolling(5).mean().fillna(data['close'].iloc[0]) # 计算5日均线 return data.dropna() # 移除缺失值
2. 序列数据构造(将数据转换为三维张量)
python
def create_sequences(features, time_steps=60):
X, y = [], []
for i in range(time_steps, len(features)):
X.append(features[i-time_steps:i, :]) # 前60天特征(输入)
y.append(features[i, 0]) # 第61天的目标值(如ma5,索引0)
return np.array(X), np.array(y) # 输出形状:(样本数, 60, 4), (样本数,)3. 训练与早停法(防止过拟合)
python
early_stopping = EarlyStopping(
monitor='val_loss', # 监控验证集损失
patience=10, # 连续10轮不改进则停止
restore_best_weights=True # 保留最优权重
)
model.compile(optimizer=Adam(learning_rate=0.001), loss=huber_loss) # 自定义Huber Loss
history = model.fit(X_train, y_train,
epochs=100, batch_size=32,
validation_data=(X_val, y_val),
callbacks=[early_stopping])六、常见问题与解决方案
1. 过拟合:训练好但验证差
- 表现:训练损失持续下降,验证损失上升。
- 对策 :
- 增加
Dropout率(如从0.3调至0.4)。 - 减少LSTM层神经元数量(如从128调至64)。
- 提前停止训练(早停法
patience设为10-20)。
- 增加
2. 未来信息泄漏:致命错误
- 原因:标准化或特征计算时使用了未来数据(如用全数据集均值)。
- 检查点 :
- 确保滚动窗口仅包含当前及之前数据(如60天窗口,当前天为第t天,窗口为t-59, t)。
- 划分数据集时按时间顺序(禁止随机划分)。
3. 仓位控制:从预测到交易
- 映射公式 :用双曲正切函数将预测值转为仓位(-1~1):
Position = tanh ( α ⋅ r ^ ) \text{Position} = \tanh(\alpha \cdot \hat{r}) Position=tanh(α⋅r^)
其中, α = 10 \alpha=10 α=10(缩放因子,控制仓位灵敏度),-1为满仓做空,1为满仓做多。
七、策略评估:量化收益与风险
1. 风险调整后收益指标
- 夏普比率(Sharpe Ratio) :衡量单位风险的超额收益:
Sharpe = 策略日均收益 收益标准差 × 252 \text{Sharpe} = \frac{\text{策略日均收益}}{\text{收益标准差}} \times \sqrt{252} Sharpe=收益标准差策略日均收益×252 - Calmar比率 :收益与最大回撤的比值(越高越好):
Calmar = 年化收益 最大回撤 \text{Calmar} = \frac{\text{年化收益}}{\text{最大回撤}} Calmar=最大回撤年化收益
2. 可视化工具
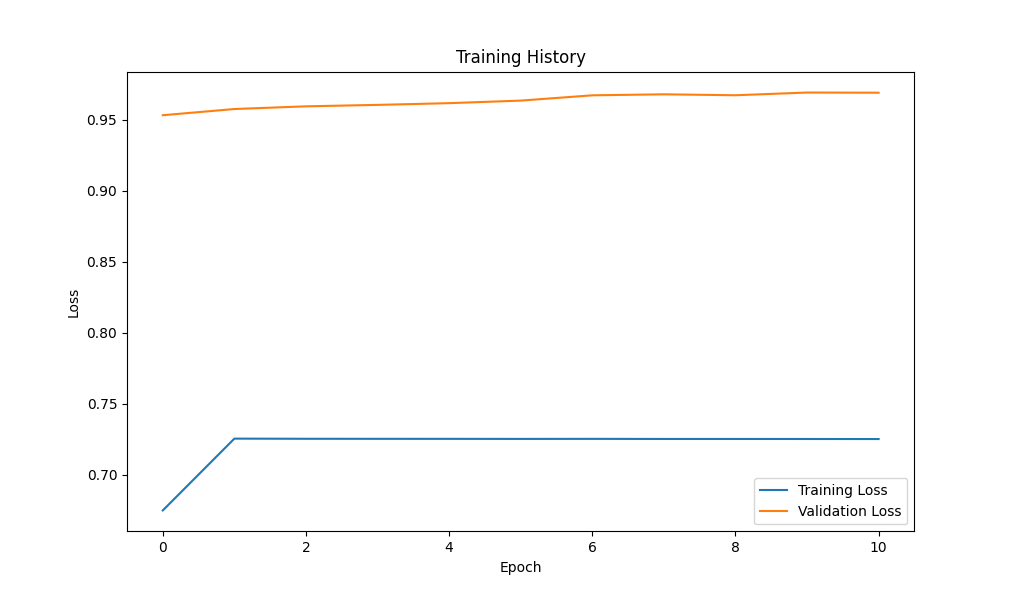
- 损失曲线:对比训练/验证损失,判断过拟合。
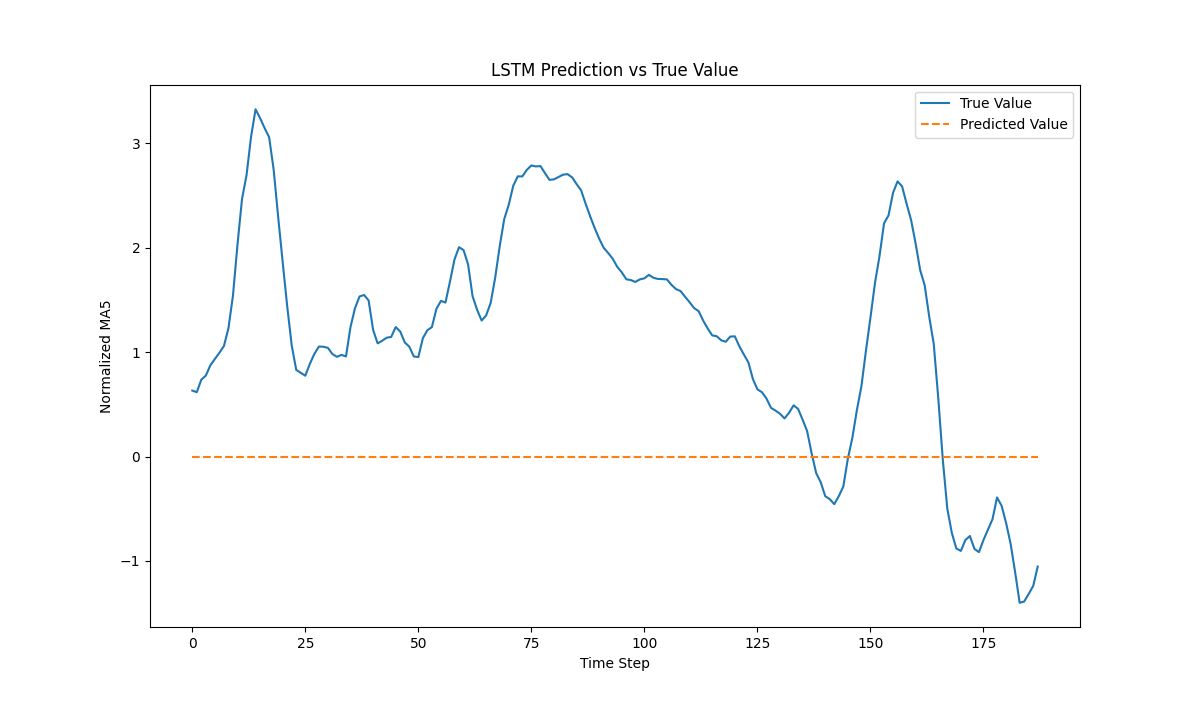
- 预测对比图:直观展示预测值与真实值的趋势一致性。
八、总结:LSTM时序预测的完整闭环
- 数据层:清洗、构造三维数据,滚动窗口标准化防泄漏。
- 模型层:LSTM捕捉时序依赖,Dropout和早停法防过拟合,Huber Loss处理异常值。
- 策略层:预测值映射仓位,结合风险控制(止损、交易成本)形成完整策略。
- 迭代层:定期用新数据 retrain,根据市场变化调整特征(如加入波动率状态)。
LSTM的核心魅力在于"选择性记忆",但实际效果依赖数据质量、特征工程和超参数调优。建议从模拟数据起步,逐步过渡到真实场景,通过反复实验找到最优配置。
通过以上步骤,你将掌握从数据处理到模型部署的全流程,为时序预测(如股价、销量、天气)打下坚实基础。欢迎在评论区分享你的实践经验!
附:完整代码
python
# ---------------------- 1. 导入库 ----------------------
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
# ---------------------- 2. 生成/加载数据 ----------------------
# 【可选】如果用真实数据,替换下面的模拟数据生成函数
# 真实数据需为CSV格式,包含日期列和特征列(如收盘价、均线、波动率)
def generate_data(num_days=1000):
np.random.seed(42)
dates = pd.date_range(start="2020-01-01", periods=num_days, freq="D")
close = 100 + np.cumsum(np.random.randn(num_days)) # 模拟收盘价
ma5 = pd.Series(close).rolling(5).mean().fillna(close[0]) # 5日均线
ma10 = pd.Series(close).rolling(10).mean().fillna(close[0]) # 10日均线
volatility = np.abs(np.random.randn(num_days)) * 0.05 # 模拟波动率
data = pd.DataFrame(
{
"date": dates,
"close": close,
"ma5": ma5,
"ma10": ma10,
"volatility": volatility,
}
)
return data
data = generate_data() # 生成模拟数据
# 【真实数据加载示例】
# data = pd.read_csv('your_data.csv', parse_dates=['date']) # 替换为你的CSV路径
# ---------------------- 3. 数据预处理 ----------------------
def rolling_window_normalize(data, window_size=60):
normalized_data = data.copy()
features = data.columns[1:] # 假设第一列为日期,其余为特征列
for col in features:
for i in range(len(data)):
start = max(0, i - window_size + 1)
window = data[col][start : i + 1]
mean = window.mean()
std = window.std() if window.std() != 0 else 1 # 避免除以0
normalized_data.at[i, col] = (data[col][i] - mean) / std
return normalized_data
data_normalized = rolling_window_normalize(data, window_size=60)
features = data_normalized[["ma5", "ma10", "volatility", "close"]].values # 4个特征
# ---------------------- 4. 构造序列数据(三维输入) ----------------------
def create_sequences(features, time_steps=60):
X, y = [], []
for i in range(time_steps, len(features)):
X.append(features[i - time_steps : i, :]) # 前60天的特征
y.append(features[i, 0]) # 目标:第61天的ma5(可改为其他特征,如收盘价索引为3)
return np.array(X), np.array(y)
time_steps = 60
X, y = create_sequences(features, time_steps=time_steps)
# ---------------------- 5. 划分训练集和验证集 ----------------------
split_idx = int(0.8 * len(X))
X_train, X_val = X[:split_idx], X[split_idx:]
y_train, y_val = y[:split_idx], y[split_idx:]
# ---------------------- 6. 搭建LSTM模型 ----------------------
model = Sequential(
[
LSTM(
units=128, # 神经元数量,控制模型复杂度
activation="tanh", # LSTM内部激活函数
input_shape=(time_steps, X.shape[2]), # 输入形状:[时间步长, 特征数]
return_sequences=False, # 仅输出最后一个时间步的结果
),
Dropout(0.3), # 随机丢弃30%神经元,防止过拟合
Dense(64, activation="relu"), # 全连接层,提取高层特征
Dropout(0.2),
Dense(1), # 输出单个预测值(回归问题)
]
)
# 编译模型(使用Huber Loss)
optimizer = Adam(learning_rate=0.001) # 优化器,控制学习速度
model.compile(
optimizer=optimizer,
loss=lambda y_true, y_pred: tf.where(
tf.abs(y_true - y_pred) <= 1, # δ=1(Huber Loss参数)
0.5 * (y_true - y_pred) ** 2, # 误差较小时用MSE
1 * tf.abs(y_true - y_pred) - 0.5, # 误差较大时用MAE
),
)
# ---------------------- 7. 训练模型(含早停法) ----------------------
early_stopping = EarlyStopping(
monitor="val_loss", # 监控验证集损失
patience=10, # 连续10轮不改进则停止训练
restore_best_weights=True, # 保留训练过程中最好的模型权重
)
history = model.fit(
X_train,
y_train,
epochs=100, # 最大训练轮数
batch_size=32, # 每次喂给模型的数据量(内存不足时可减小,如16)
validation_data=(X_val, y_val), # 验证集
callbacks=[early_stopping], # 应用早停法
verbose=1, # 显示训练进度(0=静默,1=进度条,2=每轮一行)
)
# ---------------------- 8. 预测与结果分析 ----------------------
y_pred = model.predict(X_val) # 预测验证集
# 【可选】计算仓位(仅当预测目标为收益率时使用,本例预测ma5,可跳过)
# alpha = 10
# position = np.tanh(alpha * y_pred) # 仓位映射到[-1, 1]
# ---------------------- 9. 可视化损失曲线 ----------------------
plt.figure(figsize=(10, 5))
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Training History")
plt.show()
# ---------------------- 10. 可视化预测效果(仅示例,需根据真实数据调整) ----------------------
plt.figure(figsize=(12, 6))
plt.plot(range(len(y_val)), y_val, label="True Value")
plt.plot(range(len(y_pred)), y_pred.flatten(), label="Predicted Value", linestyle="--")
plt.xlabel("Time Step")
plt.ylabel("Normalized MA5")
plt.legend()
plt.title("LSTM Prediction vs True Value")
plt.show()