论文链接: Language Models are Few-Shot Learners
点评: GPT3把参数规模扩大到1750亿,且在少样本场景下性能优异。对于所有任务,GPT-3均未进行任何梯度更新或微调,仅通过纯文本交互形式接收任务描述和少量示例。然而,我们也发现部分数据集上GPT-3的少样本学习能力仍有局限,以及一些因依赖大规模网络语料训练引发的潜在方法学问题。
GPT系列:
|------|---------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------|
| GPT1 | | 预训练+微调, 创新点在于Task-specific input transformations。 | |
| GPT2 | 15亿参数 | 预训练+Prompt+Predict, 创新点在于Zero-shot | Zero-shot新颖度拉满,但模型性能拉胯 |
| GPT3 | 1750亿参数 | 预训练+Prompt+Predict, 创新点在于in-context learning | 开创性提出in-context learning概念,是Prompting祖师爷(ICL)是Prompting范式发展的第一阶段。 |
GPT模型指出,如果用Transformer的解码器和大量的无标签样本去预训练一个语言模型,然后在子任务上提供少量的标注样本做微调,就可以很大的提高模型的性能。GPT2则是更往前走了一步,说在子任务上不去提供任何相关的训练样本,而是直接用足够大的预训练模型去理解自然语言表达的要求,并基于此做预测。但是,GPT2的性能太差,有效性低。
GPT3其实就是来解决有效性低的问题。Zero-shot的概念很诱人,但是别说人工智能了,哪怕是我们人,去学习一个任务也是需要样本的,只不过人看两三个例子就可以学会一件事了,而机器却往往需要大量的标注样本去fine-tune。那有没有可能:给预训练好的语言模型一点样本。用这有限的样本,语言模型就可以迅速学会下游的任务?
**Note: GPT3中的few-shot learning,只是在预测是时候给几个例子,并不微调网络。**GPT-2用zero-shot去讲了multitask Learning的故事,GPT-3使用meta-learning和in-context learning去讲故事。
网络结构 Model Construction

GPT-3沿用了GPT-2的结构,但是在网络容量上做了很大的提升,并且使用了一个Sparse Transformer的架构,具体如下:
1.GPT-3采用了96层的多头transformer,头的个数为 96;
2.词向量的长度是12,888;
3.上下文划窗的窗口大小提升至2,048个token;
4.使用了alternating dense和locally banded sparse attention
Sparse Transformer:
Sparse Transformer是一种旨在处理高维、稀疏和长序列数据的Transformer拓展版,相比于传统的Transformer架构,Sparse Transformer通过在自注意力机制中引入稀疏性,减少了网络中计算的数量 ,从而可以处理更长的序列数据 。具体的:在处理高维、稀疏数据时,Sparse Transformer可以避免对所有输入的位置进行计算,只计算与当前位置相关的位置 ,从而提高了计算效率。
GPT3的batch size达到320万,为什么用这么大的?
首先,大模型相比于小模型更不容易过拟合,所以更用大的、噪音更少的Batch也不会带来太多负面影响;其次,现在训练一个大模型会用到多台机器做分布式计算,机器与机器之间数据并行。最后,虽然批大小增加会导致梯度计算的时间复杂度增加,但是较大的batch size通常可以提高模型的训练效率和性能。
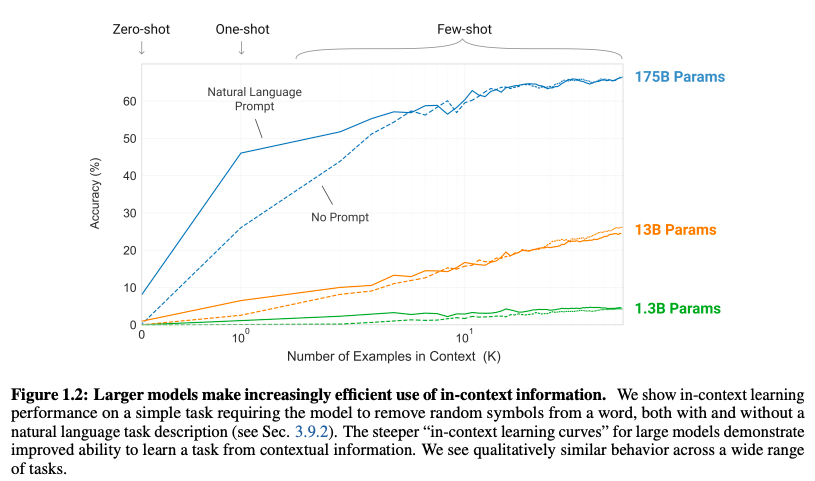
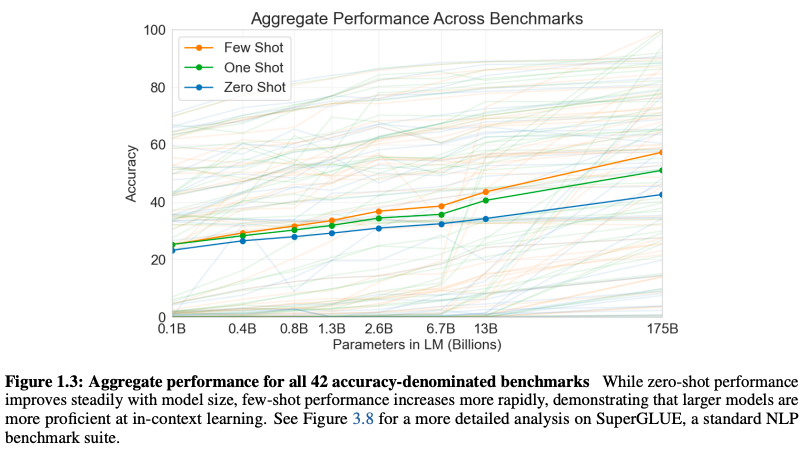
图1.2:更大的模型拥有更强的利用情境信息能力
图1.3: 聚合了模型在42个基准数据集上的性能
- 本文的实现与GPT-2的方法相似,预训练过程的不同只在于采用了参数更多的模型、更丰富的数据集和更长的训练的过程。本文聚焦于系统分析同一下游任务不同设置情况下,模型情境学习能力的差异。下游任务的设置有以下四类:
- Fine-Tunning(FT):FT利用成千上万的下游任务标注数据来更新预训练模型中的权重以获得强大的性能。但是,该方法不仅导致每个新的下游任务都需要大量的标注语料,还导致模型在样本外预测的能力很弱。虽然GPT-3从理论上支持FT,但本文没这么做。
- Few-Shot(FS):模型在推理阶段可以得到少量的下游任务示例作为限制条件,但是不允许更新预训练模型中的权重。FS过程的示例可以看本笔记图2.1点整理的案例。FS的主要优点是并不需要大量的下游任务数据,同时也防止了模型在fine-tune阶段的过拟合。FS的主要缺点是不仅与fine-tune的SOTA模型性能差距较大且仍需要少量的下游任务数据。
- One-Shot(1S):模型在推理阶段仅得到1个下游任务示例。把1S独立于Few-Shot和Zero-Shot讨论是因为这种方式与人类沟通的方式最相似。
- Zero-Shot(0S):模型在推理阶段仅得到一段以自然语言描述的下游任务说明。0S的优点是提供了最大程度的方便性、尽可能大的鲁棒性并尽可能避免了伪相关性。0S的方式是非常具有挑战的,即使是人类有时候也难以仅依赖任务描述而没有示例的情况下理解一个任务。但毫无疑问,0S设置下的性能是最与人类的水平具有可比性的。
评估:
-
单项选择任务:给定K个任务示例和待测样本的上下文信息,计算分别选取每个候选词的整个补全样本(K个任务示例+待测样本上下文+待测样本候选词)的似然,选择能产生最大样本似然的候选词作为预测。
-
二分类任务:将候选词从0和1变为False和True等更具有语义性的文本,然后使用上述单项选择任务的方式计算不同候选项补全的样本似然。
-
无候选词任务:使用和GPT-2完全一样参数设置的beam search方式,选择F1相似度,BLEU和精确匹配等指标作为评价标准。
论文阅读 A Survey of Pre-trained Language Models for Processing Scientific Text