NBM的原理及应用
贝叶斯决策及相关
贝叶斯决策
- 对于给定数据集 X = X 1 , X 2 , ⋯ , X d T X=X_1,X_2,\\cdots,X_d^T X=X1,X2,⋯,XdT
- K个类 C i , i = 1 , ⋯ , K C_i,i=1,\cdots,K Ci,i=1,⋯,K, 满足 P ( C i ) > = 0 a n d ∑ P ( C i ) = 1 P(C_i)>=0\ and\ \sum P(C_i)=1 P(Ci)>=0 and ∑P(Ci)=1
- 对于数据样本 x x x的类别判断为:
c h o o s e C i i f P ( C i ∣ x ) = m a x P ( C k ∣ x ) choose\ C_i\ if P(C_i|x)=maxP(C_k|x) choose Ci ifP(Ci∣x)=maxP(Ck∣x)
后验概率的计算
-
贝叶斯定理公式为
P ( C i ∣ x ) = p ( x ∣ C i ) P ( C i ) p ( x ) P(C_i|x)=\frac{p(x|C_i)P(C_i)}{p(x)} P(Ci∣x)=p(x)p(x∣Ci)P(Ci)
其中, p ( x ) , p ( x ∣ C i ) p(x),p(x|C_i) p(x),p(x∣Ci)可以从训练样本中估算。
理解后验概率
后验概率是一种条件概率,代表随机事件存在关联。
理解贝叶斯决策
总是选择错误风险最小的结果。
一元统计分析及参数估计
-
常规做法:根据给定的数据集估算这些概率。
-
存在问题:如果数据集太小,那么从数据集里计算出来的概率偏差将非常严重。
例:观察一个质地均匀的骰子投掷6次的结果:
1,3,1,5,3,3
质地均匀的骰子每个点出现的概率应该是1/6
如果根据观察到的数据集去计算每个点的概率,和真实的概率差别会非常大。
即:如果数据集太小,那么从数据集里计算出来的概率偏差将非常严重。
-
解决方法:
- 不完全依赖给定的数据,结合概率分布模型计算概率。
概率分布模型
- 概率密度函数(PDF)
- 描述连续随机事件(变量)可能性的函数。
- 概率质量函数(PMF)
- 描述离散随机事件(变量)可能性的函数。
处理连续随机变量和离散随机变量需要采用不同的概率分布模型
- 伯努利分布(二值分布)
- 二项式分布
- 多值分布
- 多项式分布
- 高斯分布
一维数据的情况
数据仅含一个特征,可能是连续/随机的随机变量。
伯努利分布
伯努利分布是二值分布,用0/1表示。
- 伯努利分布概率质量函数:
P ( X = x ) = { p x = 1 1 − p x = 0 P(X=x)=\left\{ \begin{matrix} p\qquad &x=1\\ 1-p\qquad &x=0 \end{matrix} \right. P(X=x)={p1−px=1x=0
- 二项式分布:
P k = C N k p k ( 1 − p ) N − k P_k=C_N^kp^k(1-p)^{N-k} Pk=CNkpk(1−p)N−k
做了N次伯努利试验,结果1出现k次的概率。多值分布
∑ j = 1 M p j = 1 f ( x 1 , x 2 , ⋯ , x m ∣ p ) = ∏ j = 1 M p j x j \begin{align} \sum_{j=1}^{M}p_j=&1\\ f(x_1,x_2,\cdots,x_m|p)=&\prod_{j=1}^{M}p_j^{x_j} \end{align} j=1∑Mpj=f(x1,x2,⋯,xm∣p)=1j=1∏Mpjxj
M M M是特征取值的状态数, x j x_j xj当且仅当类别x状态j时,取值为1,其余情况取值为0。
-
多项式分布:满足多值分布的实验,连续做 n 次后,每种类别出现的特定次数组合的概率。
多项式分布的PMF:
f ( X , n , P ) = n ! ∏ j = 1 M x j ! ∏ j = 1 M p j x j \begin{align} f(X,n,P)=\frac{n!}{\prod_{j=1}^{M}x_j!}\prod_{j=1}^Mp_j^{x_j} \end{align} f(X,n,P)=∏j=1Mxj!n!j=1∏Mpjxj
高斯分布
连续随机变量的概率分布,即正态分布
公式包含 μ , σ \mu,\sigma μ,σ两个参数:
p ( x ) = 1 2 π e x p ( − ( x − μ ) 2 2 σ 2 ) p(x)=\frac{1}{\sqrt{2\pi}}exp(-\frac{(x-\mu)^2}{2\sigma^2}) p(x)=2π 1exp(−2σ2(x−μ)2)
参数估计
含义:确定概率分布模型的参数,概率模型确定后,即可计算 p ( x ) 和 p ( x ∣ C i ) p(x)和p(x|C_i) p(x)和p(x∣Ci)。
方法:最大似然估计
最大似然估计
似然:在参数 θ \theta θ下,数据样本 X = { x 1 , x 2 , ⋯ , x n } X=\{x_1,x_2,\cdots,x_n\} X={x1,x2,⋯,xn}出现的概率
-
样本满足独立同分布
X = { x t } t = 1 N X={\{x^t\}}^N_{t=1} X={xt}t=1N
-
x服从参数为 θ \theta θ的概率分布
x t ∼ p ( x ∣ θ ) x^t\sim p(x|\theta) xt∼p(x∣θ)
-
样本的似然(假设样本相互独立):
l ( X ∣ θ ) = p ( X ∣ θ ) = ∏ t = 1 N p ( x t ∣ θ ) l(X|\theta)=p(X|\theta)=\prod_{t=1}^Np(x^t|\theta) l(X∣θ)=p(X∣θ)=t=1∏Np(xt∣θ)
对数似然:L ( X ∣ θ ) = l o g l ( X ∣ θ ) = ∑ t = 1 N l o g p ( x t ∣ θ ) L(X|\theta)=logl(X|\theta)=\sum_{t=1}^Nlog\ p(x^t|\theta) L(X∣θ)=logl(X∣θ)=t=1∑Nlog p(xt∣θ)
-
通过极值估算概率模型参数 θ \theta θ
-
伯努利分布
下面的公式展示了如何通过最大似然估计(MLE)推导伯努利分布的参数p。
伯努利分布的概率质量函数为:
P ( x t ∣ p ) = p x t ( 1 − p ) 1 − x t \begin{align} P(x^t|p)={p^x}^t(1-p)^{1-x^t} \end{align} P(xt∣p)=pxt(1−p)1−xt
联合似然函数(所有样本的联合概率):
L ( X ∣ p ) = ∏ t = 1 N p x t ( 1 − 0 ) 1 − x t \begin{align} L(X|p)=\prod_{t=1}^N{p^x}^t(1-0)^{1-x^t} \end{align} L(X∣p)=t=1∏Npxt(1−0)1−xt
为了简化计算,取对数,将连乘转为连加:
l o g L ( X ∣ p ) = ∑ t = 1 N x t l o g p + ( 1 − x t ) l o g ( 1 − p ) , 展开得: = ( ∑ t = 1 N x t ) l o g p + ( N − ∑ t = 1 N x t ) l o g ( 1 − p ) 其中, ∑ x t 表示总成功次数, N − ∑ x t 表示失败次数。 \begin{align} log\ L(X|p)=&\sum_{t=1}^Nx\^tlog\\ p+(1-x^t)log(1-p),展开得:\\ =&(\sum_{t=1}^Nx^t)log\ p+(N-\sum_{t=1}^Nx^t)log(1-p) \end{align}\\ 其中,\sum x^t表示总成功次数,N-\sum x^t表示失败次数。 log L(X∣p)==t=1∑Nxtlog p+(1−xt)log(1−p),展开得:(t=1∑Nxt)log p+(N−t=1∑Nxt)log(1−p)其中,∑xt表示总成功次数,N−∑xt表示失败次数。
对p求导,并令导数为0:
d d p l o g L ( X ∣ p ) = x t p − N − ∑ x t 1 − p = 0 \begin{align} \frac{d}{dp}log\ L(X|p)=\frac{x^t}{p}-\frac{N-\sum x^t}{1-p}=0 \end{align} dpdlog L(X∣p)=pxt−1−pN−∑xt=0
解方程得:
p ^ = x t N \hat{p}=\frac{x^t}{N} p^=Nxt
-
多值分布
-
类条件概率的估计
p ^ ( x ∣ C i ) = ∏ j = 1 M p ^ i j x j \hat p(x|C_i)=\prod_{j=1}^M\hat p_{ij}^{x_j} p^(x∣Ci)=j=1∏Mp^ijxj
- 符号说明 :
- C i C_i Ci表示第i个类别。
- p ^ i j \hat p_{ij} p^ij表示类别 C i C_i Ci下第j个特征的出现概率(MLE估计值)。
- x j x_j xj是样本的第j个特征值(二值或频数)。
- p ^ i j = N i j N i \hat p_{ij}=\frac{N_{ij}}{N_i} p^ij=NiNij, N i j N_{ij} Nij表示 C i C_i Ci中第 j j j个特征出现的总次数, N i N_i Ni表示 C i C_i Ci的总样本数。
- 符号说明 :
-
先验概率的估计
p ^ ( C i ) = ∑ l r l i N \hat p(C_i)=\frac{\sum_lr_l^i}{N} p^(Ci)=N∑lrli
- 符号说明 :
- r l i r_l^i rli:第 l l l个样本是否属于 C i C_i Ci(1是,0否)。
- N:总样本数。
- 符号说明 :
-
构建判别式函数
g i ( x ) = l o g ( p ^ ( x ∣ C i ) p ^ ( C i ) ) = ∑ j = 1 M x j l o g p ^ i j + l o g p ^ ( C i ) g_i(x)=log(\hat p^(x∣C_i)\hat p^(C_i))=\sum_{j=1}^M x_{j}log\ \hat p_{ij}+log\ \hat p(C_i) gi(x)=log(p^(x∣Ci)p^(Ci))=∑j=1Mxjlog p^ij+log p^(Ci)
-
高斯分布
-
建立似然函数
L ( X ∣ μ , σ ) = − N 2 l o g ( 2 π ) − N l o g σ − ∑ t ( x t − μ ) 2 2 σ 2 L(X|\mu,\sigma)=-\frac{N}{2}log(2\pi)-Nlog\sigma-\frac{\sum_t(x^t-\mu)^2}{2\sigma^2} L(X∣μ,σ)=−2Nlog(2π)−Nlogσ−2σ2∑t(xt−μ)2
-
计算自变量的偏导,令等于0,得最大似然估计结果:
m = ∑ t x t N s 2 = ∑ t ( x t − m ) 2 N m=\frac{\sum_tx^t}{N}\\ s^2=\frac{\sum_t(x^t-m)^2}{N} m=N∑txts2=N∑t(xt−m)2
-
高斯分布用于分类
-
对每个类别 C i C_i Ci,用MLE估计其高斯参数 ( m i , s i 2 ) (m_i,s_i^2) (mi,si2):
p ^ ( x ∣ C i ) = 1 2 π s i e x p ( − ( x − m i ) 2 2 s i 2 ) \hat p(x|C_i)=\frac{1}{\sqrt{2\pi s_i}}exp(-\frac{(x-m_i)^2}{2s_i^2}) p^(x∣Ci)=2πsi 1exp(−2si2(x−mi)2)
-
先验概率估计:
p ^ ( C i ) = 类别 C i 的样本数 N \hat p(C_i)=\frac{类别C_i的样本数}{N} p^(Ci)=N类别Ci的样本数
-
构建判别式
取对数后,判别函数 g i ( x ) g_i(x) gi(x) 为:
g i ( x ) = − 1 2 l o g 2 π − l o g s i − ( x − m i ) 2 2 s i 2 + l o g p ^ ( C i ) g_i(x)=-\frac{1}{2}log2\pi-log\ s_i-\frac{(x-m_i)^2}{2s_i^2}+log\ \hat p(C_i) gi(x)=−21log2π−log si−2si2(x−mi)2+log p^(Ci)
-
-
多元数据的贝叶斯模型
多元数据
-
被观测的样本具有多个特征(维度>1)
样本集可以用矩阵表示。
X = X 1 1 X 2 1 ⋯ X d 1 X 1 2 X 2 2 ⋯ X d 2 . . X 1 N X 2 N ⋯ X d N X=\begin{bmatrix} X_1^1\quad X_2^1\quad \cdots\quad X_d^1\\ X_1^2\quad X_2^2\quad \cdots\quad X_d^2\\ .\\ .\\ X_1^N\quad X_2^N\quad \cdots\quad X_d^N \end{bmatrix} X= X11X21⋯Xd1X12X22⋯Xd2..X1NX2N⋯XdN
多元数据的统计量
-
均值向量
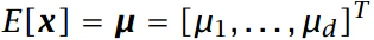
-
特征变量的方差
σ i 2 \sigma_i^2 σi2
-
特征变量间的协方差
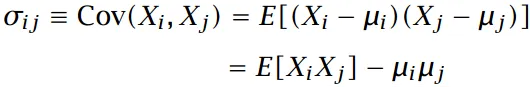
协方差描述了特征变量之间的关联,如果特征变量彼此独立、不相关,则协方差为零。
-
特征变量的相关性
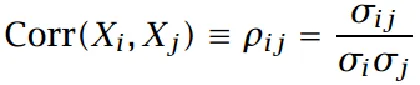
相关性把特征变量之间的协方差归一化到-1,+1,特征变量如果不相关,则相关性为0。
多元数据的参数估计
- 最大似然估计的结果
-
样本均值向量
m = ∑ t = 1 N x t N ( m i = ∑ t = 1 N x i t N ) m=\frac{\sum^N_{t=1}x^t}{N}\quad (m_i=\frac{\sum_{t=1}^Nx^t_i}{N}) m=N∑t=1Nxt(mi=N∑t=1Nxit)
-
样本的协方差
-
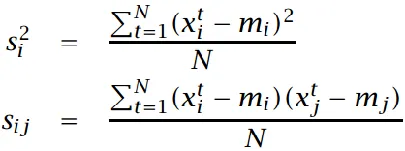
多元高斯分布
-
x ∼ N d ( μ , ∑ ) x\sim N_d(\mu,\sum) x∼Nd(μ,∑)
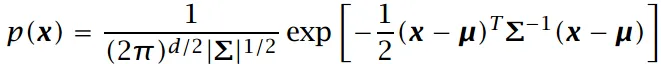
-
样本的协方差矩阵用S表示
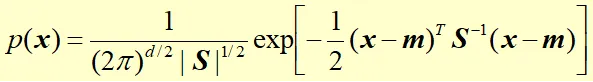
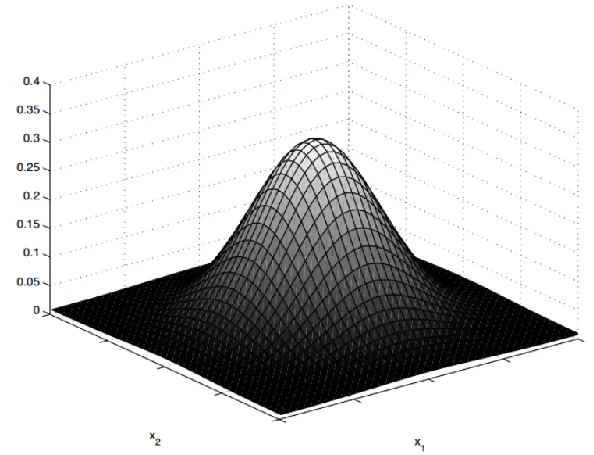
基于多元高斯分布的贝叶斯分类法
- 假定
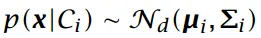
-
判别式为:
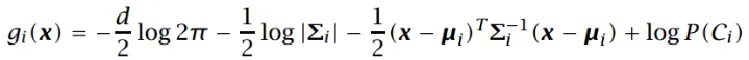
-
根据最大似然估计:
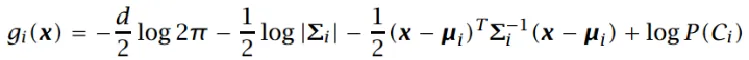
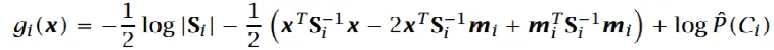
- 化简得:
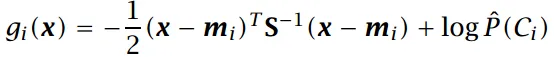
如果协方差矩阵为对角矩阵,化简结果为:
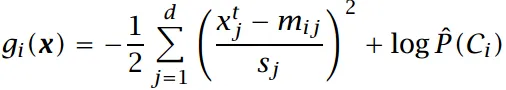
上式为朴素贝叶斯模型的基于高斯分布的判别式(NBM)。
讨论朴素贝叶斯模型
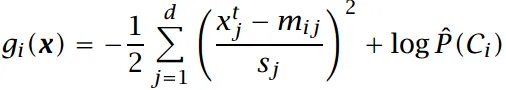
-
括号内为标准化的欧氏距离,消除量纲影响。
-
NBM是线性判别式,每个特征变量的分布都是高斯分布。
-
如果每个特征变量方差相同,或进行了归一化处理,NBM退化为:
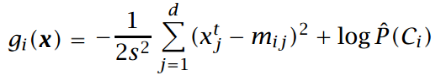
括号内为欧氏距离,不需要再标准化了。
-
最小距离分类:
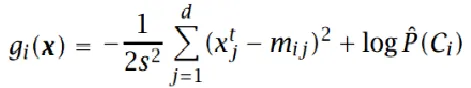
如果 p ^ ( C i ) \hat p(C_i) p^(Ci)相等:
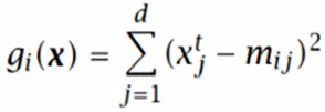
上式为最小距离分类方法
贝叶斯模型的简化形式
为了降低模型的复杂程度,降低计算量,需要对贝叶斯模型进行化简。
独立性假设
朴素贝叶斯的前提是假定样本实例的各个特征之间相互独立,此时, σ = 0 , ρ = 0 \sigma=0,\rho=0 σ=0,ρ=0
协方差矩阵退化为对角矩阵
公式:
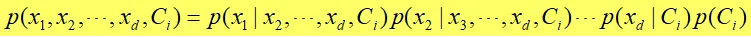
可以化简为:
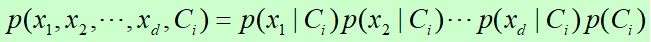
等价于:
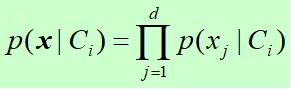
此时,多元数据的条件概率等于一元条件概率的乘积,每个特征变量都独立处理,不须再考虑协方差
三种朴素贝叶斯分类器
随机变量的预处理
- 样本实例的特征可以是连续的随机变量
- 也可以是离散的随机变量
- 不同类型的特征变量需要采用不同的概率模型处理
- 不同概率模型对应不同的贝叶斯模型的实现方法
- 对于连续随机变量:
- 采用高斯分布模型。
- 离散成多值状态,采用多值分布模型。
- 离散成二值状态,采用伯努力分布模型。
- 对于多值离散型随机变量
- 采用多值分布模型、
- 离散成二值状态,采用伯努力分布模型
贝叶斯模型的优点
- 分类效率稳定
- 对缺少数据不太敏感,常用于文本分类
- 对小规模数据表现很好,对大规模数据可分批增量式训练
- 能处理多分类任务
贝叶斯模型的缺点
- 特征较多或特征相关性较大时,分类效果不好。
- 对数据的表达形式很敏感。
- 需要知道先验概率(常取决于假设),因此存在一定误差。
朴素贝叶斯模型的三种实现形式
- 基于伯努力的NBM
- 处理二值随机变量的数据
- 基于多值分布的NBM
- 处理离散随机变量的数据
- 基于高斯分布的NBM
- 处理连续随机变量的数据
条件概率的数据平滑
如果某个离散随机变量的条件概率为0,那么条件概率连乘就会失败。
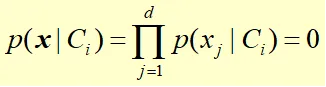
- 平滑方法:

