30岁程序员学习Python的第一天:网络爬虫
Requests库
1、requests库安装
windows系统通过管理员打开cmd,运行pip install requests!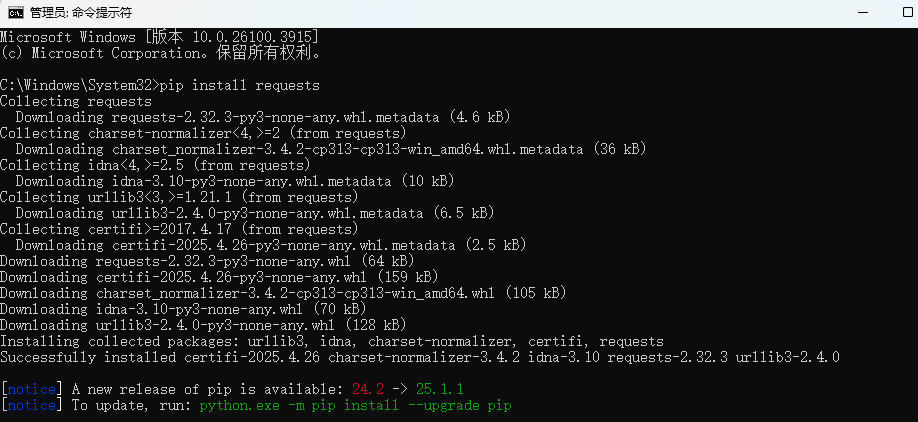
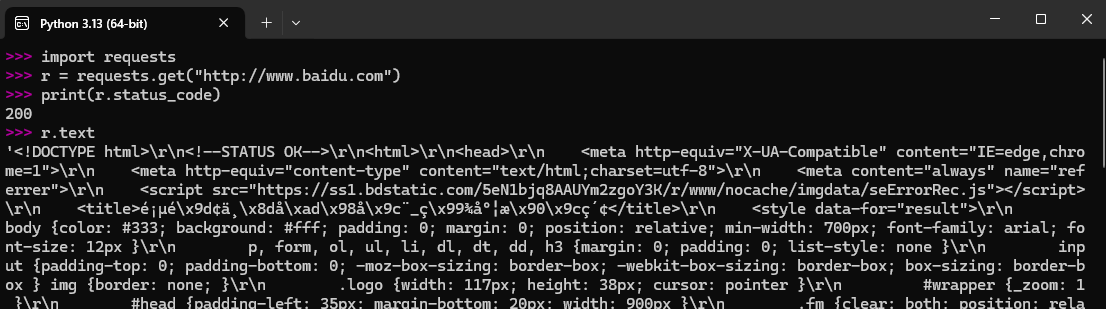
测试案例:
2、Requests库的两个重要对象
Response对象
Resoponse对象包含服务器返回的所有信息,也包含请求的Resquest信息
r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败
r.text HTTP相应内容的字符串形式,即,url对应的页面内容
r.encoding 从HTTP header中猜测的响应内容编码方式
r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
r.content HTTP响应内容的二进制形式
r.status_code: 200 表示成功 404或其他 表示某些原因产生的异常
r.encoding:如果header中不存在charset,则认为编码为ISO-8859-1,r.text根据r.encoding显示网页内容
r.apparent_encoding:根据网页内容分析出的编码方式,可以看作是r.encoding的备选。
Request对象3、Requests库的异常
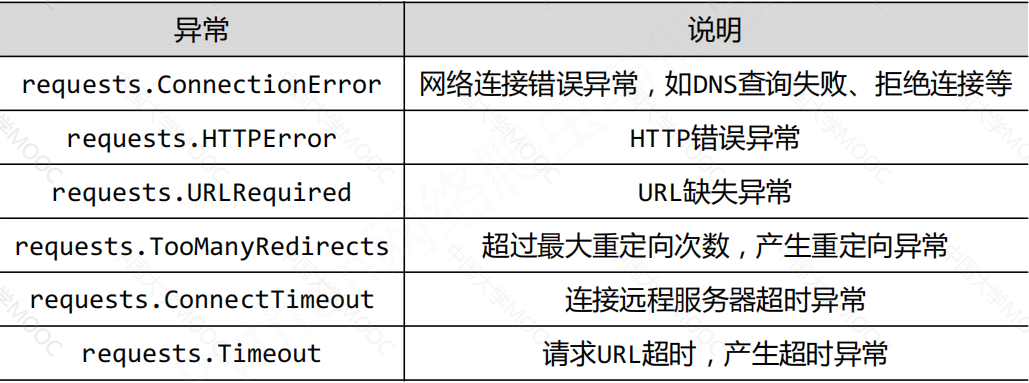
r.raise_for_status(): 如果不是200,产生异常requests.HTTPError
该方法在方法内部判断r.status_code是否等于200,不需要增加额外的if语句,该语句便于利用try_except进行异常处理
python
import requests
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == '__main__':
url = "http://www.baidu.com"
print(getHTMLText(url))4、Requests库的7个主要方法
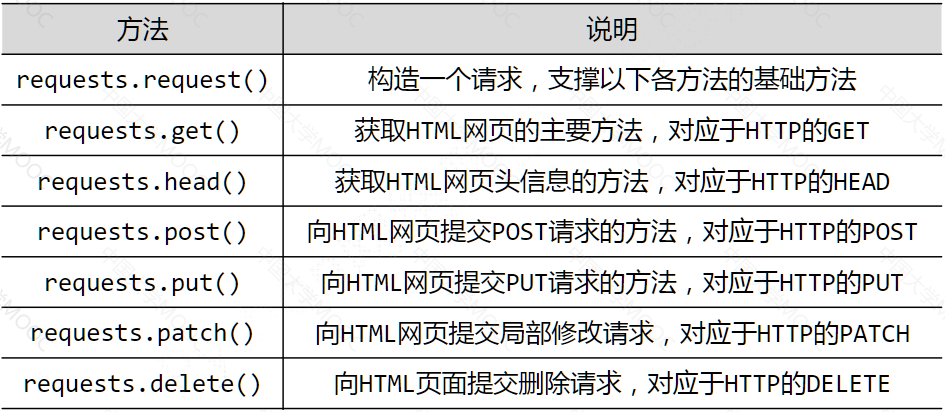
此7个方法与HTTP协议中的方法一致。
python
>>> import requests
>>> r = requests.head('http://httpbin.org/get')
>>> r.headers
{'Date': 'Tue, 06 May 2025 00:29:49 GMT', 'Content-Type': 'application/json', 'Content-Length': '307', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
>>> r.text
>>> payload = {'key1':'value1','key2':'value2'}
>>> r = requests.post('http://httpbin.org/post',data=payload)
>>> print(r.text)
{
...
"data": "",
"form": {
"key1": "value1",
"key2": "value2"
},
...
}
>>> r = requests.post('http://httpbin.org/post',data='ABD')
>>> print(r.text)
{
...
"data": "ABD",
"form": {},
...
}
>>> payload = {'key1':'value1','key2':'value2'}
>>> r = requests.put('http://httpbin.org/put',data=payload)
>>> print(r.text)
{
...
"data": "",
"form": {
"key1": "value1",
"key2": "value2"
},
...
}requests.request(method,url,** kwargs)
method: 请求方式,对应get/put/post等7种
url: 拟获取页面的url链接
** kwargs: 控制访问的参数,共13个,可以是字典或字节序列,文件对象等
** kwargs: 控制访问的参数,均为可选项
params : 字典或字节序列,作为参数增加到url中
data : 字典、字节序列或文件对象,作为request的内容
json : JSON格式的数据,作为Request的内容
headers : 字典,HTTP定制头
cookies : 字典或Cookiejar,Request中的cookie
auth : 元组,支持HTTP认证功能
files : 字典类型,传输文件
timeout : 设定超时时间,单位为秒
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects : True/False,默认为True,重定向开关
stream : True/False,默认True,获取内容立即下载开关
verity : True/False,默认True,认证SSL证书开关
cert : 本地SSL证书路径
网络爬虫引发的问题
1、性能骚扰:Web服务器默认接受人类访问,编程水平和目录,网络爬虫容易给Web服务器带来巨大的资源开销。
2、法律风险:服务器上的数据有产权归属、获取数据后牟利将触犯法律。
3、隐私泄露:爬虫可能具备突破简单访问控制的能力,获得被保护的数据,从而泄露个人隐私。
网络爬虫的限制
来源审查:判断User-Agent进行限制
检查来访HTTP协议头的User-Agent域,只响应浏览器或者友好爬虫的访问。
发布公告:Robots协议
告知所有爬虫网站的爬取策略,要求爬虫遵守。
Robots协议(Robots Exclusion Standard)
网站告知网路爬虫那些页面可以抓取、那些不行,基本放置在网站根目录下robots.txt文件。
百度网站robots协议:
User-agent: Baiduspider
Disallow: /baidu
Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Googlebot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: MSNBot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
...Robots协议可通过自动或人工识别robots.txt,再进行内容爬取。
Robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险。
爬取实例
爬取京东商品
python
import requests
url = "https://item.jd.com/100038004353.html"
try:
r = requests.get(url)
r.raise_for_status()
r = encodings = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")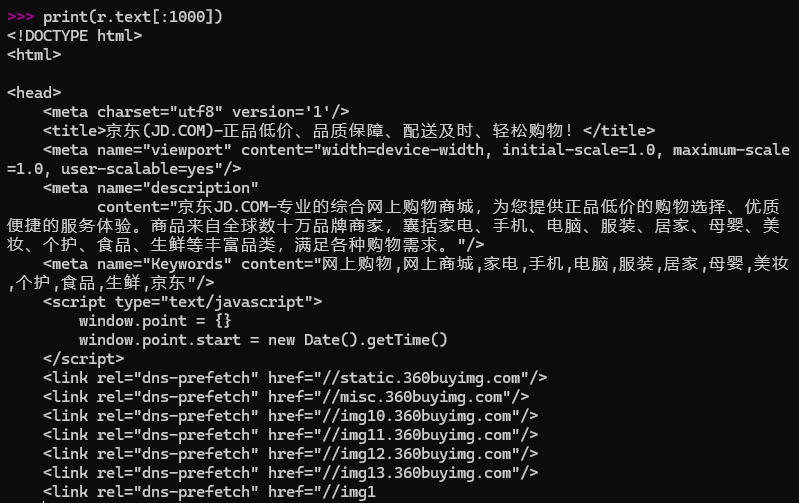
爬取亚马逊商品
python
import requests
url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
r = requests.get(url)
print(r.request.headers)
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers = kv)
print(r.request.headers)
print(r.status_code)
r.encodings = r.apparent_encoding
print(r.text[1000:2000])
except:
print('爬取失败')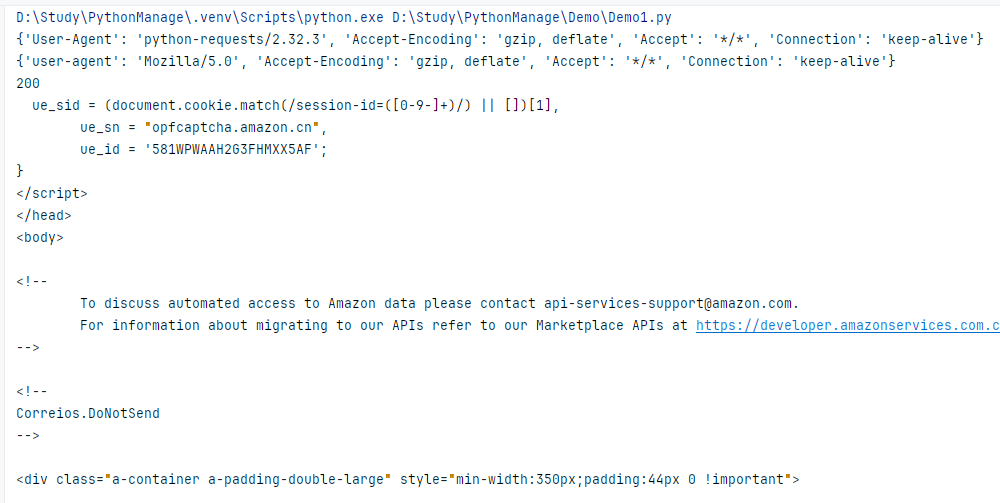
通过搜索引擎关键字爬取数据
python
import requests
url = "http://www.baidu.com/s"
try:
kv = {'wd':'Python'}
r = requests.get(url,params = kv)
r.raise_for_status()
r.encodings = r.apparent_encoding
print(r.url)
print(len(r.text))
except:
print('爬取失败')