基于计算机视觉的试卷答题区表格识别与提取技术
摘要
本文介绍了一种基于计算机视觉技术的试卷答题区表格识别与提取算法。该算法能够自动从试卷图像中定位答题区表格,执行图像方向矫正,精确识别表格网格线,并提取每个答案单元格。本技术可广泛应用于教育测评、考试管理系统等场景,极大提高答卷处理效率。
关键技术
- 表格区域提取与分割
- 图像二值化预处理
- 多尺度形态学操作
- 水平线与竖线精确检测
- 单元格定位与提取
1. 系统架构
我们设计的试卷答题区表格处理工具由以下主要模块组成:
- 答题区定位:从整张试卷图像中提取右上角的答题区表格
- 图像预处理:进行二值化、去噪等操作以增强表格线条
- 表格网格识别:精确检测水平线和竖线位置
- 单元格提取:根据网格线交点切割并保存各个答案单元格
处理流程:
输入图像 -> 答题区定位 -> 方向矫正 -> 图像预处理 ->
网格线检测 -> 单元格提取 -> 输出结果2. 核心功能实现
2.1 答题区表格定位
我们假设答题区通常位于试卷右上角,首先提取该区域并应用轮廓检测算法:
python
# 提取右上角区域(答题区域通常在试卷右上角)
x_start = int(width * 0.6)
y_start = 0
w = width - x_start
h = int(height * 0.5)
# 提取区域
region = img[y_start:y_start + h, x_start:x_start + w]接着使用形态学操作提取线条并查找表格轮廓:
python
# 转为灰度图并二值化
gray = cv2.cvtColor(region, cv2.COLOR_BGR2GRAY)
binary = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV, 11, 2)
# 使用形态学操作检测线条
horizontal_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_h, iterations=2)
vertical_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_v, iterations=2)2.2 图像预处理
为了增强表格线条特征,我们执行以下预处理步骤:
python
# 高斯平滑去噪
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 自适应阈值二值化
binary = cv2.adaptiveThreshold(
blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 21, 5)
# 形态学操作填充小空隙
kernel = np.ones((3, 3), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_CLOSE, kernel)2.3 表格网格线识别
这是本算法的核心部分,我们分别检测水平线和竖线:
2.3.1 水平线检测
使用形态学开运算提取水平线,然后计算投影找到线条位置:
python
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (horizontal_size, 1))
horizontal_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, horizontal_kernel, iterations=2)
# 提取水平线坐标 - 基于行投影
h_coords = []
h_projection = np.sum(horizontal_lines, axis=1)
for i in range(1, len(h_projection) - 1):
if h_projection[i] > h_projection[i - 1] and h_projection[i] > h_projection[i + 1] and h_projection[i] > width // 5:
h_coords.append(i)2.3.2 竖线检测
竖线检测采用多尺度策略,使用不同大小的结构元素,提高检测的鲁棒性:
python
# 使用不同大小的结构元素进行竖线检测
vertical_kernels = [
cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 12)), # 细线
cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 8)), # 中等
cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 4)) # 粗线
]
# 合并不同尺度的检测结果
vertical_lines = np.zeros_like(binary_image)
for kernel in vertical_kernels:
v_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, kernel, iterations=1)
vertical_lines = cv2.bitwise_or(vertical_lines, v_lines)2.4 表格竖线位置精确校正
由于竖线检测可能存在偏左问题,我们实现了复杂的位置校正算法:
python
# 竖线位置修正:解决偏左问题 - 检测实际线条中心位置
v_coords_corrected = []
for idx, v_coord in enumerate(v_coords_detected):
# 第2-11根竖线特殊处理
if 1 <= idx <= 10: # 第2-11根竖线
search_range_left = 2 # 左侧搜索范围更小
search_range_right = 12 # 右侧搜索范围大幅增大
else:
search_range_left = 5
search_range_right = 5
# 在搜索范围内找到峰值中心位置
# 对于特定竖线,使用加权平均来偏向右侧
if 1 <= idx <= 10:
window = col_sum[left_bound:right_bound+1]
weights = np.linspace(0.3, 2.0, len(window)) # 更强的右侧权重
weighted_window = window * weights
max_pos = left_bound + np.argmax(weighted_window)
# 强制向右偏移
max_pos += 3
else:
max_pos = left_bound + np.argmax(col_sum[left_bound:right_bound+1])2.4.1 不等间距网格处理
我们根据实际表格特点,处理了第一列宽度与其他列不同的情况:
python
# 设置第一列的宽度为其他列的1.3倍
first_column_width_ratio = 1.3
# 计算除第一列外每列的宽度
remaining_width = right_bound - left_bound
regular_column_width = remaining_width / (expected_vlines - 1 + (first_column_width_ratio - 1))2.5 单元格提取与保存
根据检测到的网格线,我们提取出每个单元格:
python
# 提取单元格的过程
cell_img = image[y1_m:y2_m, x1_m:x2_m].copy()
# 保存单元格图片
cell_filename = f'cell_0{q_num:02d}.png'
cell_path = os.path.join(output_dir, cell_filename)
cv2.imwrite(cell_path, cell_img)3. 技术创新点
- 多尺度形态学操作:使用不同尺寸的结构元素检测竖线,提高了检测的鲁棒性
- 表格线位置动态校正:针对不同位置的竖线采用不同的校正策略,解决了竖线偏左问题
- 不等间距网格处理:通过特殊计算处理第一列宽度不同的情况,更好地适应实际试卷样式
- 加权峰值搜索:使用加权策略进行峰值搜索,提高了线条中心位置的准确性
4. 使用示例
4.1 基本用法
python
from image_processing import process_image
# 处理单张图像
input_image = "./images/1.jpg"
output_dir = "./output"
image_paths = process_image(input_image, output_dir)
print(f"处理成功: 共生成{len(image_paths)}个单元格图片")4.2 批量处理
我们还提供了批量处理多张试卷图像的功能:
python
# 批量处理目录中的所有图像
for img_file in image_files:
img_path = os.path.join(images_dir, img_file)
output_dir = os.path.join(output_base_dir, f"result_{img_name}")
image_paths = process_image(img_path, output_dir)4.3 完整代码
pytthon
"""
试卷答题区表格处理工具
1. 从试卷提取答题区表格
2. 对表格进行方向矫正
3. 切割表格单元格并保存所有25道题的答案单元格
"""
import os
import cv2
import numpy as np
import argparse
import sys
import time
import shutil
class AnswerSheetProcessor:
"""试卷答题区表格处理工具类"""
def __init__(self):
"""初始化处理器"""
pass
def process(self, input_image_path, output_dir):
"""
处理试卷答题区,提取表格并保存单元格
Args:
input_image_path: 输入图像路径
output_dir: 输出单元格图像的目录
Returns:
处理后的图片路径列表,失败时返回空列表
"""
os.makedirs(output_dir, exist_ok=True)
temp_dir = os.path.join(os.path.dirname(output_dir), f"temp_{time.strftime('%Y%m%d_%H%M%S')}")
os.makedirs(temp_dir, exist_ok=True)
try:
# 1. 提取答题区表格
table_img, _ = self._extract_answer_table(input_image_path, temp_dir)
if table_img is None:
print("无法提取答题区表格")
return []
# 保存提取的原始表格图像
# original_table_path = os.path.join(output_dir, "original_table.png")
# cv2.imwrite(original_table_path, table_img)
# 2. 矫正表格方向
corrected_table = self._correct_table_orientation(table_img)
# cv2.imwrite(os.path.join(output_dir, "corrected_table.png"), corrected_table)
# 3. 提取表格单元格
image_paths = self._process_and_save_cells(corrected_table, temp_dir, output_dir)
# 4. 清理临时目录
shutil.rmtree(temp_dir, ignore_errors=True)
return image_paths
except Exception as e:
print(f"处理失败: {str(e)}")
shutil.rmtree(temp_dir, ignore_errors=True)
return []
def _extract_answer_table(self, image, output_dir):
"""提取试卷答题区表格"""
# 读取图像
if isinstance(image, str):
img = cv2.imread(image)
if img is None:
return None, None
else:
img = image
# 调整图像大小以提高处理速度
max_width = 1500
if img.shape[1] > max_width:
scale = max_width / img.shape[1]
img = cv2.resize(img, None, fx=scale, fy=scale)
# 获取图像尺寸
height, width = img.shape[:2]
# 提取右上角区域(答题区域通常在试卷右上角)
x_start = int(width * 0.6)
y_start = 0
w = width - x_start
h = int(height * 0.5)
# 提取区域
region = img[y_start:y_start + h, x_start:x_start + w]
# 转为灰度图并二值化
gray = cv2.cvtColor(region, cv2.COLOR_BGR2GRAY)
binary = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV, 11, 2)
# 检测表格线
kernel_h = cv2.getStructuringElement(cv2.MORPH_RECT, (max(25, w // 20), 1))
kernel_v = cv2.getStructuringElement(cv2.MORPH_RECT, (1, max(25, h // 20)))
horizontal_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_h, iterations=2)
vertical_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_v, iterations=2)
# 合并线条
grid_lines = cv2.add(horizontal_lines, vertical_lines)
# 膨胀线条
kernel = np.ones((3, 3), np.uint8)
dilated_lines = cv2.dilate(grid_lines, kernel, iterations=1)
# 查找轮廓
contours, _ = cv2.findContours(dilated_lines, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 筛选可能的表格轮廓
valid_contours = []
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
area = cv2.contourArea(contour)
if area < 1000:
continue
aspect_ratio = float(w) / h if h > 0 else 0
if 0.1 <= aspect_ratio <= 3.0:
valid_contours.append((x, y, w, h, area))
if valid_contours:
# 选择面积最大的轮廓
valid_contours.sort(key=lambda c: c[4], reverse=True)
x, y, w, h, _ = valid_contours[0]
# 调整回原图坐标
x_abs = x_start + x
y_abs = y_start + y
# 提取表格区域并加一些padding确保完整
padding = 10
x_abs = max(0, x_abs - padding)
y_abs = max(0, y_abs - padding)
w_padded = min(width - x_abs, w + 2 * padding)
h_padded = min(height - y_abs, h + 2 * padding)
table_region = img[y_abs:y_abs + h_padded, x_abs:x_abs + w_padded]
return table_region, (x_abs, y_abs, w_padded, h_padded)
# 如果未找到有效轮廓,返回预估区域
x_start = int(width * 0.75)
y_start = int(height * 0.15)
w = int(width * 0.2)
h = int(height * 0.4)
x_start = max(0, min(x_start, width - 1))
y_start = max(0, min(y_start, height - 1))
w = min(width - x_start, w)
h = min(height - y_start, h)
return img[y_start:y_start + h, x_start:x_start + w], (x_start, y_start, w, h)
def _correct_table_orientation(self, table_img):
"""矫正表格方向(逆时针旋转90度)"""
if table_img is None:
return None
try:
return cv2.rotate(table_img, cv2.ROTATE_90_COUNTERCLOCKWISE)
except Exception as e:
print(f"表格方向矫正失败: {str(e)}")
return table_img
def _process_and_save_cells(self, table_img, temp_dir, output_dir):
"""处理表格并保存单元格"""
try:
# 预处理图像
binary = self._preprocess_image(table_img)
# cv2.imwrite(os.path.join(output_dir, "binary_table.png"), binary)
# 检测表格网格
h_lines, v_lines = self._detect_table_cells(binary, table_img.shape, output_dir)
# 如果未检测到足够的网格线
if len(h_lines) < 2 or len(v_lines) < 2:
print("未检测到足够的表格线")
return []
# 可视化并保存表格网格
self._visualize_grid(table_img, h_lines, v_lines, output_dir)
# 提取并直接保存单元格
image_paths = self._extract_and_save_cells(table_img, h_lines, v_lines, output_dir)
return image_paths
except Exception as e:
print(f"表格处理错误: {str(e)}")
return []
def _preprocess_image(self, image):
"""表格图像预处理"""
if image is None:
return None
# 转为灰度图
if len(image.shape) == 3:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
else:
gray = image.copy()
# 高斯平滑
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 自适应阈值二值化
binary = cv2.adaptiveThreshold(
blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 21, 5)
# 进行形态学操作,填充小空隙
kernel = np.ones((3, 3), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_CLOSE, kernel)
return binary
def _detect_table_cells(self, binary_image, image_shape, output_dir):
"""检测表格网格,基于图像真实表格线精确定位"""
height, width = image_shape[:2]
# 1. 先检测水平线
horizontal_size = width // 10
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (horizontal_size, 1))
horizontal_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, horizontal_kernel, iterations=2)
# 提取水平线坐标
h_coords = []
h_projection = np.sum(horizontal_lines, axis=1)
for i in range(1, len(h_projection) - 1):
if h_projection[i] > h_projection[i - 1] and h_projection[i] > h_projection[i + 1] and h_projection[
i] > width // 5:
h_coords.append(i)
# 使用聚类合并相近的水平线
h_coords = self._cluster_coordinates(h_coords, eps=height // 30)
# 2. 确保我们至少有足够的水平线定义表格区域
if len(h_coords) < 2:
print("警告: 水平线检测不足,无法确定表格范围")
h_lines = [(0, int(y), width, int(y)) for y in h_coords]
v_lines = []
return h_lines, v_lines
# 获取表格垂直范围
h_coords.sort()
table_top = int(h_coords[0])
table_bottom = int(h_coords[-1])
# 3. 增强竖线检测 - 使用多尺度检测策略
# 使用不同大小的结构元素进行竖线检测
vertical_kernels = [
cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 12)), # 细线
cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 8)), # 中等
cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 4)) # 粗线
]
# 合并不同尺度的检测结果
vertical_lines = np.zeros_like(binary_image)
for kernel in vertical_kernels:
v_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, kernel, iterations=1)
vertical_lines = cv2.bitwise_or(vertical_lines, v_lines)
# 只关注表格区域内的竖线
table_region_v = vertical_lines[table_top:table_bottom, :]
# 计算列投影
col_sum = np.sum(table_region_v, axis=0)
# 4. 更精准地寻找竖线位置
# 使用自适应阈值计算
local_max_width = width // 25 # 更精细的局部最大值搜索窗口
threshold_ratio = 0.15 # 降低阈值以捕获更多可能的竖线
# 自适应阈值计算
threshold = np.max(col_sum) * threshold_ratio
# 扫描所有列查找峰值
v_coords_raw = []
i = 0
while i < len(col_sum):
# 查找局部范围内的峰值
local_end = min(i + local_max_width, len(col_sum))
local_peak = i
# 找到局部最大值
for j in range(i, local_end):
if col_sum[j] > col_sum[local_peak]:
local_peak = j
# 如果局部最大值大于阈值,认为是竖线
if col_sum[local_peak] > threshold:
v_coords_raw.append(local_peak)
# 跳过已处理的区域
i = local_peak + local_max_width // 2
else:
i += 1
# 5. 去除过于接近的竖线(可能是同一条线被重复检测)
v_coords_detected = self._cluster_coordinates(v_coords_raw, eps=width // 50) # 使用更小的合并阈值
# 6. 检查找到的竖线数量
expected_vlines = 15 # 预期应有15条竖线
print(f"初步检测到竖线数量: {len(v_coords_detected)}")
# 7. 处理识别结果
if len(v_coords_detected) > 0:
# 7.1 获取表格的左右边界
v_coords_detected.sort() # 确保按位置排序
# 竖线位置修正:解决偏左问题 - 检测实际线条中心位置
v_coords_corrected = []
for idx, v_coord in enumerate(v_coords_detected):
# 在竖线坐标附近寻找准确的线条中心
# 对于第2-11根竖线,使用更大的搜索范围向右偏移
if 1 <= idx <= 10: # 第2-11根竖线
search_range_left = 2 # 左侧搜索范围更小
search_range_right = 12 # 右侧搜索范围大幅增大
else:
search_range_left = 5
search_range_right = 5
left_bound = max(0, v_coord - search_range_left)
right_bound = min(width - 1, v_coord + search_range_right)
if left_bound < right_bound and left_bound < len(col_sum) and right_bound < len(col_sum):
# 在搜索范围内找到峰值中心位置
# 对于第2-11根竖线,使用加权平均来偏向右侧
if 1 <= idx <= 10:
# 计算加权平均,右侧权重更大
window = col_sum[left_bound:right_bound+1]
weights = np.linspace(0.3, 2.0, len(window)) # 更强的右侧权重
weighted_window = window * weights
max_pos = left_bound + np.argmax(weighted_window)
# 强制向右偏移2-3像素
max_pos += 3
max_pos = min(right_bound, max_pos)
else:
max_pos = left_bound + np.argmax(col_sum[left_bound:right_bound+1])
v_coords_corrected.append(max_pos)
else:
v_coords_corrected.append(v_coord)
# 使用修正后的坐标
v_coords_detected = v_coords_corrected
left_bound = v_coords_detected[0] # 最左边的竖线
right_bound = v_coords_detected[-1] # 最右边的竖线
# 7.2 计算理想的等距离竖线位置,但使第一列宽度比其他列宽
ideal_vlines = []
# 设置第一列的宽度为其他列的1.5倍
first_column_width_ratio = 1.3
# 计算除第一列外每列的宽度
remaining_width = right_bound - left_bound
regular_column_width = remaining_width / (expected_vlines - 1 + (first_column_width_ratio - 1))
# 设置第一列
ideal_vlines.append(int(left_bound))
# 设置第二列位置
ideal_vlines.append(int(left_bound + regular_column_width * first_column_width_ratio))
# 设置剩余列
for i in range(2, expected_vlines):
ideal_vlines.append(int(left_bound + regular_column_width * (i + (first_column_width_ratio - 1))))
# 7.3 使用修正后的列位置
v_coords = ideal_vlines
# 进一步向右偏移第2-11根竖线(总共15根)
for i in range(1, 11):
if i < len(v_coords):
v_coords[i] += 3 # 向右偏移3像素
else:
# 如果没有检测到竖线,使用预估等距离
print("未检测到任何竖线,使用预估等距离")
left_bound = width // 10
right_bound = width * 9 // 10
# 计算除第一列外每列的宽度
first_column_width_ratio = 1.5
remaining_width = right_bound - left_bound
regular_column_width = remaining_width / (expected_vlines - 1 + (first_column_width_ratio - 1))
# 设置列位置
v_coords = []
v_coords.append(int(left_bound))
v_coords.append(int(left_bound + regular_column_width * first_column_width_ratio))
for i in range(2, expected_vlines):
v_coords.append(int(left_bound + regular_column_width * (i + (first_column_width_ratio - 1))))
# 8. 检验最终的竖线位置是否合理
if len(v_coords) == expected_vlines:
# 计算相邻竖线间距
spacings = [v_coords[i + 1] - v_coords[i] for i in range(len(v_coords) - 1)]
avg_spacing = sum(spacings[1:]) / len(spacings[1:]) # 不计入第一列的宽度
# 检查是否有间距异常的竖线(除第一列外)
for i in range(1, len(spacings)):
if abs(spacings[i] - avg_spacing) > avg_spacing * 0.2: # 如果间距偏差超过20%
print(f"警告: 第{i + 1}和第{i + 2}竖线之间间距异常, 实际:{spacings[i]}, 平均:{avg_spacing}")
# 如果是最后一个间距异常,可能是最后一条竖线位置不准
if i == len(spacings) - 1:
v_coords[-1] = v_coords[-2] + int(avg_spacing)
print(f"修正最后一条竖线位置: {v_coords[-1]}")
# 9. 转换为线段表示
h_lines = [(0, int(y), width, int(y)) for y in h_coords]
v_lines = [(int(x), int(table_top), int(x), int(table_bottom)) for x in v_coords]
# 10. 强制补充缺失的水平线 - 期望有5条水平线(4行表格)
if len(h_lines) < 5 and len(h_lines) >= 2:
h_lines.sort(key=lambda x: x[1])
top_y = int(h_lines[0][1])
bottom_y = int(h_lines[-1][1])
height_range = bottom_y - top_y
# 计算应有的4等分位置
expected_y_positions = [top_y + int(height_range * i / 4) for i in range(1, 4)]
# 添加缺失的水平线
new_h_lines = list(h_lines)
for y_pos in expected_y_positions:
# 检查是否已存在接近该位置的线
exist = False
for line in h_lines:
if abs(line[1] - y_pos) < height // 20:
exist = True
break
if not exist:
new_h_lines.append((0, int(y_pos), width, int(y_pos)))
h_lines = new_h_lines
# 11. 最终排序
h_lines = sorted(h_lines, key=lambda x: x[1])
v_lines = sorted(v_lines, key=lambda x: x[0])
print(f"最终水平线数量: {len(h_lines)}")
print(f"最终竖线数量: {len(v_lines)}")
# 12. 计算并打印竖线间距,用于检验均匀性
if len(v_lines) > 1:
spacings = []
for i in range(len(v_lines) - 1):
spacing = v_lines[i + 1][0] - v_lines[i][0]
spacings.append(spacing)
avg_spacing = sum(spacings[1:]) / len(spacings[1:]) # 不计入第一列的宽度
print(f"竖线平均间距: {avg_spacing:.2f}像素")
print(f"竖线间距: {spacings}")
return h_lines, v_lines
def _cluster_coordinates(self, coords, eps=10):
"""合并相近的坐标"""
if not coords:
return []
coords = sorted(coords)
clusters = []
current_cluster = [coords[0]]
for i in range(1, len(coords)):
if coords[i] - coords[i - 1] <= eps:
current_cluster.append(coords[i])
else:
clusters.append(int(sum(current_cluster) / len(current_cluster)))
current_cluster = [coords[i]]
if current_cluster:
clusters.append(int(sum(current_cluster) / len(current_cluster)))
return clusters
def _visualize_grid(self, image, h_lines, v_lines, output_dir):
"""可视化检测到的网格线并保存结果图像"""
# 复制原图用于绘制
result = image.copy()
if len(result.shape) == 2:
result = cv2.cvtColor(result, cv2.COLOR_GRAY2BGR)
# 绘制水平线
for line in h_lines:
x1, y1, x2, y2 = line
cv2.line(result, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)
# 绘制垂直线
for line in v_lines:
x1, y1, x2, y2 = line
cv2.line(result, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)
# 绘制交点
for h_line in h_lines:
for v_line in v_lines:
y = h_line[1]
x = v_line[0]
cv2.circle(result, (int(x), int(y)), 3, (0, 255, 0), -1)
# 只保存grid_on_image.png
if output_dir:
cv2.imwrite(os.path.join(output_dir, "grid_on_image.png"), result)
def _extract_and_save_cells(self, image, h_lines, v_lines, output_dir, margin=3):
"""提取单元格并保存到输出目录"""
height, width = image.shape[:2]
# 确保线条按坐标排序
h_lines = sorted(h_lines, key=lambda x: x[1])
v_lines = sorted(v_lines, key=lambda x: x[0])
# 保存图片路径
image_paths = []
# 检查线条数量是否足够
if len(h_lines) < 4 or len(v_lines) < 10:
print(f"警告: 线条数量不足(水平线={len(h_lines)}, 垂直线={len(v_lines)})")
if len(h_lines) < 2 or len(v_lines) < 2:
print("错误: 线条数量太少,无法提取任何单元格")
return image_paths
# 记录表格结构
print(f"表格结构: {len(h_lines)}行, {len(v_lines) - 1}列")
# 创建题号到行列索引的映射
question_mapping = {}
# 第2行是1-13题(列索引从1开始,0列是题号列)
for i in range(1, 14):
if i < len(v_lines):
question_mapping[i] = (1, i)
# 第4行是14-25题(列索引从1开始,0列是题号列)
for i in range(14, 26):
col_idx = i - 13 # 14题对应第1列,15题对应第2列,...
if col_idx < len(v_lines) and 3 < len(h_lines):
question_mapping[i] = (3, col_idx)
# 提取每道题的单元格
saved_questions = []
for q_num in range(1, 26):
if q_num not in question_mapping:
print(f"题号 {q_num} 没有对应的行列索引映射")
continue
row_idx, col_idx = question_mapping[q_num]
if row_idx >= len(h_lines) - 1 or col_idx >= len(v_lines) - 1:
print(f"题号 {q_num} 的行列索引 ({row_idx}, {col_idx}) 超出表格范围")
continue
try:
# 获取单元格边界
x1 = int(v_lines[col_idx][0])
y1 = int(h_lines[row_idx][1])
x2 = int(v_lines[col_idx + 1][0])
y2 = int(h_lines[row_idx + 1][1])
# 打印单元格信息用于调试
if q_num in [1, 4, 13, 14, 25]: # 打印关键单元格的位置信息
print(f"题号 {q_num} 单元格: x1={x1}, y1={y1}, x2={x2}, y2={y2}, 宽={x2 - x1}, 高={y2 - y1}")
# 添加边距,避免包含边框线
x1_m = min(width - 1, max(0, x1 + margin))
y1_m = min(height - 1, max(0, y1 + margin))
x2_m = max(0, min(width, x2 - margin))
y2_m = max(0, min(height, y2 - margin))
# 检查单元格尺寸
if x2_m <= x1_m or y2_m <= y1_m or (x2_m - x1_m) < 5 or (y2_m - y1_m) < 5:
print(f"跳过无效单元格: 题号 {q_num}, 尺寸过小")
continue
# 提取单元格
cell_img = image[y1_m:y2_m, x1_m:x2_m].copy()
# 检查单元格是否为空图像
if cell_img.size == 0 or cell_img.shape[0] == 0 or cell_img.shape[1] == 0:
print(f"跳过空单元格: 题号 {q_num}")
continue
# 保存单元格图片
cell_filename = f'cell_0{q_num:02d}.png'
cell_path = os.path.join(output_dir, cell_filename)
cv2.imwrite(cell_path, cell_img)
# 添加到路径列表和已保存题号列表
image_paths.append(cell_path)
saved_questions.append(q_num)
except Exception as e:
print(f"提取题号 {q_num} 时出错: {str(e)}")
print(f"已保存 {len(saved_questions)} 个单元格,题号: {sorted(saved_questions)}")
return image_paths
def process_image(input_image_path, output_dir):
"""处理试卷答题区,提取表格并保存单元格"""
processor = AnswerSheetProcessor()
return processor.process(input_image_path, output_dir)
def main():
"""主函数:解析命令行参数并执行处理流程"""
# 解析命令行参数
parser = argparse.ArgumentParser(description='试卷答题区表格处理工具')
parser.add_argument('--image', type=str, default="./images/12.jpg", help='输入图像路径')
parser.add_argument('--output', type=str, default="./output", help='输出目录')
args = parser.parse_args()
# 检查图像是否存在
if not os.path.exists(args.image):
print(f"图像文件不存在: {args.image}")
return 1
# 确保输出目录存在
os.makedirs(args.output, exist_ok=True)
print(f"开始处理图像: {args.image}")
print(f"输出目录: {args.output}")
# 处理图像
try:
image_paths = process_image(args.image, args.output)
if image_paths:
print(f"处理成功: 共生成{len(image_paths)}个单元格图片")
print(f"所有结果已保存到: {args.output}")
return 0
else:
print("处理失败")
return 1
except Exception as e:
print(f"处理过程中发生错误: {str(e)}")
return 1
if __name__ == "__main__":
sys.exit(main())5. 应用场景
- 考试批阅系统:大规模考试的答题卡批阅
- 教育测评平台:智能化教育测评系统
- 试卷数字化处理:将纸质试卷转换为电子数据
- 教学检测系统:快速评估学生答题情况
6. 算法效果展示

上图是测试的试卷图片,要求提取出填写的答题区。

上图展示了表格网格识别的效果,蓝色线条表示竖线,红色线条表示水平线,绿色点表示线条交点。
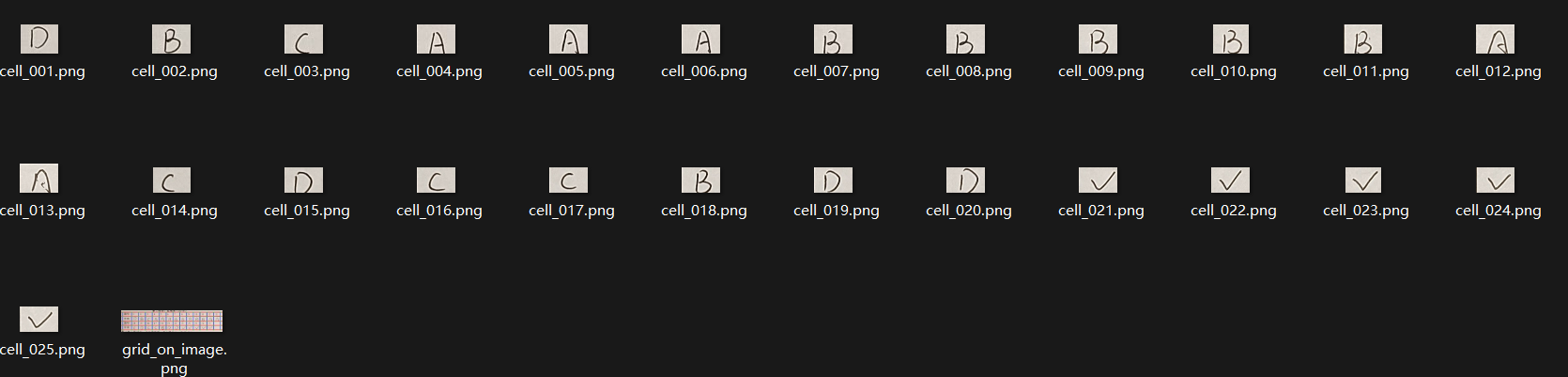
上图是从试卷中提取出的答案单元格。
7. 总结与展望
本文介绍的试卷答题区表格识别技术,通过计算机视觉算法实现了高效准确的表格定位和单元格提取。该技术有以下优势:
- 高精度:采用多尺度策略和位置校正算法,提高了表格线识别的精度
- 高适应性:能够处理不同样式的试卷答题区
- 高效率:自动化处理流程大幅提高了试卷处理效率
未来我们将继续优化算法,提高对更复杂表格的识别能力,并结合OCR技术实现答案内容的自动识别。
参考资料
- OpenCV官方文档: https://docs.opencv.org/
- 数字图像处理 - 冈萨雷斯
- 计算机视觉:算法与应用 - Richard Szeliski