Adversarial Training Towards Robust Multimedia Recommender System
题目翻译:面向鲁棒多媒体推荐系统的对抗训练
论文链接:点这里
标签:多媒体推荐、对抗训练、推荐系统鲁棒性
摘要
随着多媒体内容在网络上的普及,迫切需要开发能够有效利用多媒体数据中丰富信息的推荐解决方案。由于深度神经网络在表示学习方面的成功,近期多媒体推荐的研究主要集中在探索深度学习方法以提升推荐准确率。然而,到目前为止,针对多媒体表示的鲁棒性及其对推荐性能影响的研究仍然很少。本文旨在揭示多媒体推荐系统的鲁棒性问题。基于最先进的推荐框架和深度图像特征,我们展示了整体系统并不鲁棒:对输入图像施加微小(但有针对性)的扰动,就会严重降低推荐准确率。这一发现不仅揭示了多媒体推荐系统在预测用户偏好时的潜在弱点,更重要的是暗示了通过增强系统鲁棒性来提升性能的可能性。为此,我们提出了一种名为"对抗性多媒体推荐"(Adversarial Multimedia Recommendation, AMR)的新方法,通过对抗学习构建更鲁棒的多媒体推荐模型。其核心思路是在训练过程中模拟对手(adversary),对目标图像施加旨在降低模型准确率的扰动,并让模型学习在这种对抗中保持性能。我们在两个具有代表性的多媒体推荐任务------图像推荐和视觉感知产品推荐------上进行了大量实验。实验结果验证了对抗学习的积极作用,并证明了 AMR 方法的有效性。
一、前言
-
推荐系统与多媒体内容的兴起
介绍了推荐系统在电子商务、媒体分享和社交网络等用户中心化在线服务中的核心地位,以及多媒体数据(如商品图片、用户上传的图像和短视频)在 Web 上的广泛应用,这些视觉信号为提高推荐质量提供了新的契机 。
-
多媒体推荐技术的发展演变
回顾了早期依赖人工标注标签或低层视觉特征(如颜色、纹理)的多媒体推荐方法,阐述了随着深度神经网络(DNN)在表示学习上的成功,近年来研究重心已转向将 CNN 等深度特征融入协同过滤模型,以提升推荐准确率 。
-
现有方法的鲁棒性隐患
指出尽管 DNN 特征能带来更高的推荐性能,但图像分类等领域的研究(如 Goodfellow 等人的对抗样本工作)表明,深度模型对微小但有目的的扰动极为敏感,这种脆弱性同样会影响下游的多媒体推荐任务 。文中通过对 VBPR 方法施加极小的像素级扰动,实验证明推荐排名会出现显著退化, 验证了多媒体推荐系统在面对对抗扰动时缺乏鲁棒性 。
-
提出 AMR 方法以增强鲁棒性
为此,作者构建了一种"对抗性多媒体推荐(AMR)"框架:在训练过程中引入一个对手(adversary),对图像深度特征添加旨在最大化 BPR 损失的扰动;模型参数则在原始样本和对抗样本上联合优化,从而在最小化推荐误差的同时提升对抗扰动的抵抗能力 。
-
主要贡献与实验概览
最后,作者总结了三方面贡献:
- 首次强调基于 DNN 特征的多媒体推荐系统存在的脆弱性;
- 提出了一种新颖的对抗训练策略以提升模型鲁棒性;
- 在 Pinterest 图像推荐和 Amazon 视觉感知产品推荐两个任务上进行了大量实验,验证了 AMR 方法在提升泛化性能和抗扰动能力方面的有效性 。
二、预备知识
图一
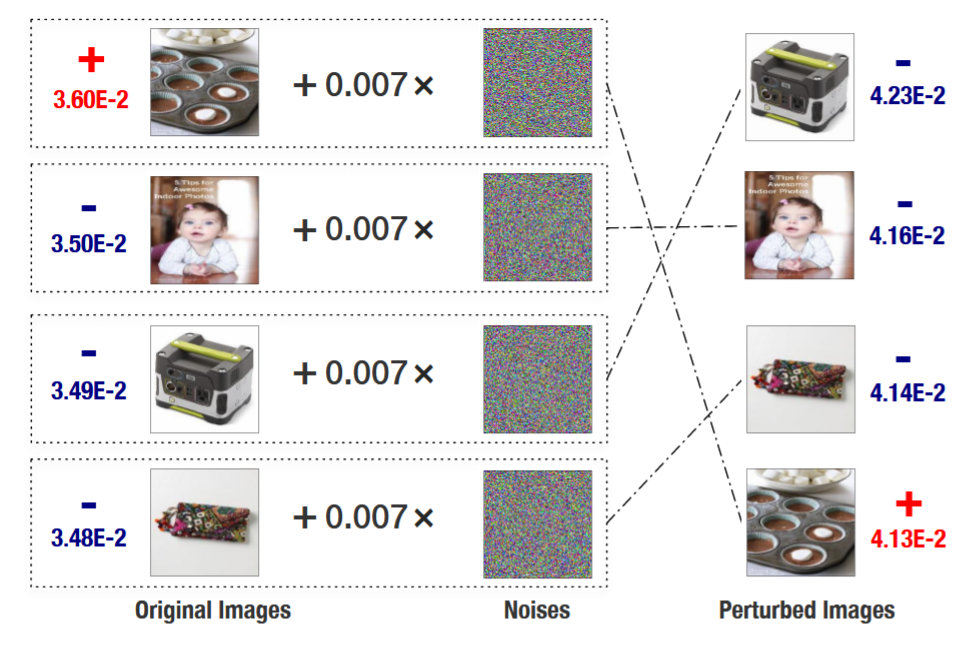
图 1:展示了在图像上添加微小扰动如何对推荐结果产生巨大影响的示例。我们从某用户的历史交互中抽取了一张已交互图像(红色"+")和三张未交互图像(蓝色"□")。每张图旁的数字分别表示 VBPR 21 在加扰动前(左)和加扰动后(右)的排序得分。通过对图像施加尺度为 ε = 0.007 的微小扰动,已交互图像的得分和排名显著下降,尽管人眼几乎无法察觉这些扰动。这里的扰动由快速梯度符号方法(FGSM)生成 24。
图二
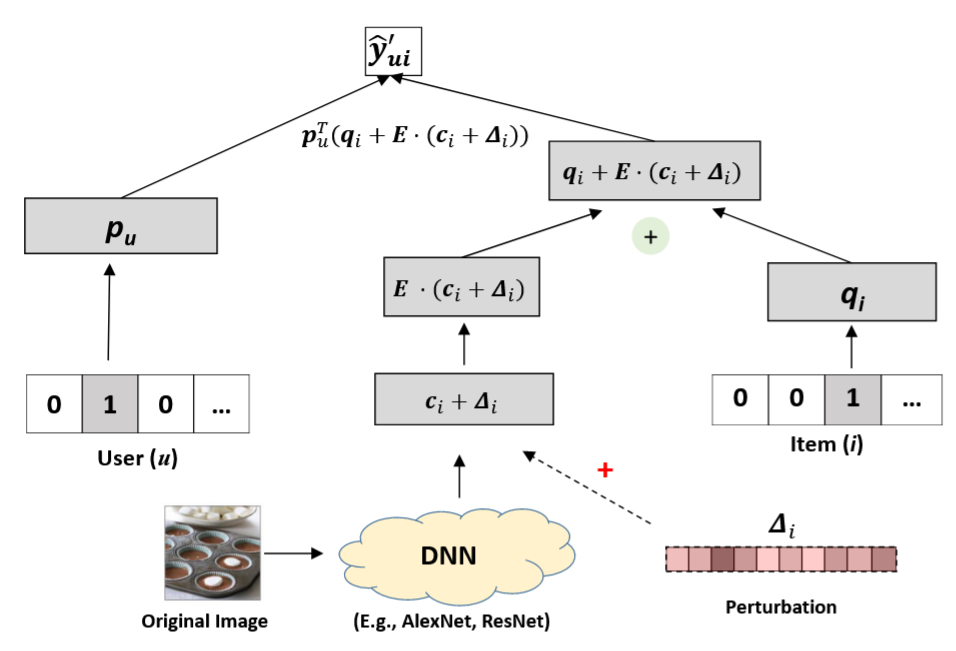
图 2:带有扰动 Δ i \Delta_i Δi 的预测模型示意图,该扰动被施加在由深度神经网络提取的图像特征向量上。
2.1 潜在因子模型
推荐的核心在于估计用户对物品的偏好。潜在因子模型(Latent Factor Model, LFM)的范式是将用户(以及物品)表示为一个潜在因子向量(latent vector),然后通过用户潜在向量与物品潜在向量的内积来估计偏好得分。形式化地,令 u u u 表示一个用户, i i i 表示一个物品, y ^ u i \hat y_{ui} y^ui 表示对用户 u u u 在物品 i i i 上的预测偏好得分,则 LFM 的预测模型可抽象为:
y ^ u i = ⟨ f U ( u ) , f I ( i ) ⟩ , \hat y_{ui} = \langle f_U(u),\, f_I(i)\rangle, y^ui=⟨fU(u),fI(i)⟩,
其中 f U f_U fU 表示将用户映射到潜在空间的函数(即 f U ( u ) f_U(u) fU(u) 为用户 u u u 的潜在向量); f I f_I fI 的含义类似,用于生成物品 i i i 的潜在向量。
对于潜在因子模型而言,函数 f U f_U fU 和 f I f_I fI 的设计对模型性能至关重要,而这一设计又取决于用于描述用户和物品的特征可用性。在最简单的情况下,如果只有 ID 信息可用,常见的做法是将每个用户(或物品)直接关联到一个向量上,即:
f U ( u ) = p u , f I ( i ) = q i , f_U(u) = \mathbf{p}_u,\quad f_I(i) = \mathbf{q}_i, fU(u)=pu,fI(i)=qi,
其中 p u ∈ R K \mathbf{p}_u\in\mathbb{R}^K pu∈RK 和 q i ∈ R K \mathbf{q}_i\in\mathbb{R}^K qi∈RK 分别称为用户 u u u 和物品 i i i 的嵌入向量, K K K 表示嵌入维度。该实例化方法即为矩阵分解(Matrix Factorization, MF)模型[27],它是一个简单但在协同过滤任务中非常有效的模型。
针对多媒体推荐, f I f_I fI 通常被设计为融合内容特征,以利用多媒体项目的视觉信号。例如,Geng 等人[18]将其定义为
f I ( i ) = E c i , f_I(i) = E\,c_i, fI(i)=Eci,
其中 c i ∈ R 4096 c_i\in\mathbb{R}^{4096} ci∈R4096 表示通过 AlexNet[28]提取的深度图像特征,矩阵 E ∈ R K × 4096 E\in\mathbb{R}^{K\times 4096} E∈RK×4096 将图像特征映射到潜在因子模型的向量空间。此类基于内容的建模还有一个附加好处:可缓解物品冷启动问题,因为对于训练外的新物品,也能通过其内容特征生成较为可靠的潜在向量。除了这种直接融合多媒体内容的方法外,还有更复杂的操作被提出。例如,Attentive Collaborative Filtering(ACF)模型[16]使用注意力网络来区分多媒体项目中不同组成部分的重要性,如图像中的不同区域或视频的各个帧。
由于潜在因子模型在预测未见过的用户--物品交互方面具有很强的泛化能力,它被公认为个性化推荐的最有效模型之一[16]。基于此,我们在潜在因子模型的基础上构建了我们的对抗式推荐方法,具体而言是针对多媒体推荐的 VBPR。接下来,我们介绍 VBPR 方法。
2.2 可视化贝叶斯个性化排序(Visual Bayesian Personalized Ranking)
可以说,如果用户在亚马逊上没有亲眼看到一件新款服饰,就不会轻易下单购买,因此物品的视觉外观在预测用户偏好时具有非常重要的作用。VBPR 正是为将这种视觉信息融入基于隐式反馈的偏好学习而设计的模型[21]。具体地,其预测模型可表示为:
y ^ u i = p u ⊤ q i + h u ⊤ ( E c i ) , \hat y_{ui} = p_u^\top q_i \;+\; h_u^\top\bigl(E\,c_i\bigr), y^ui=pu⊤qi+hu⊤(Eci),
其中:
- 第一项 p u ⊤ q i p_u^\top q_i pu⊤qi 是传统矩阵分解中用户 u u u 与物品 i i i 的内积,反映基于 ID 的协同过滤偏好;
- 第二项 h u ⊤ ( E c i ) h_u^\top (E\,c_i) hu⊤(Eci) 则将用户对视觉特征的偏好考虑进来: c i c_i ci 是通过深度网络提取的图像特征, E E E 将其映射到潜在空间,再与用户的视觉偏好向量 h u h_u hu 做内积。这样,VBPR 能同时利用协同信号与视觉信号来预测 y ^ u i \hat y_{ui} y^ui。
其中第一项 p u ⊤ q i p_u^\top q_i pu⊤qi 与矩阵分解(MF)相同,用于建模协同过滤效应;第二项 h u ⊤ ( E c i ) h_u^\top (E\,c_i) hu⊤(Eci) 则用于根据物品的图像 建模用户偏好。具体地, p u ∈ R K \mathbf{p}_u\in\mathbb{R}^K pu∈RK( q i ∈ R K \mathbf{q}_i\in\mathbb{R}^K qi∈RK)分别表示用户 u u u(物品 i i i)的 ID 嵌入, h u ∈ R K \mathbf{h}_u\in\mathbb{R}^K hu∈RK 是用户在图像潜在空间中的偏好向量, c i ∈ R D \mathbf{c}_i\in\mathbb{R}^D ci∈RD 是物品 i i i 的视觉特征向量(由 AlexNet 提取),矩阵 E ∈ R K × D E\in\mathbb{R}^{K\times D} E∈RK×D 将视觉特征映射到潜在空间。超参数 K K K 为嵌入维度,若使用 AlexNet,则 D = 4096 D=4096 D=4096。我们可以将此模型视作一个潜在因子模型,通过定义
f U ( u ) = p u , h u , f I ( i ) = q i , E c i , f_U(u) = \\mathbf{p}_u,\\;\\mathbf{h}_u,\quad f_I(i) = \\mathbf{q}_i,\\;E\\,\\mathbf{c}_i, fU(u)=pu,hu,fI(i)=qi,Eci,
其中 ⋅ , ⋅ \\cdot,\\cdot ⋅,⋅ 表示向量拼接。注意,在公式 (2) 中,我们仅保留了 VBPR 在交互预测中的核心项,为了简洁省略了其他偏置项。
为了估计模型参数,VBPR 使用 BPR 的成对排序损失(pairwise ranking loss)[10]来针对购买和点击等隐式交互数据进行优化。其假设是模型应当对已交互的用户--物品对给出比未交互对更高的评分。为实现这一假设,对于每一个观测到的交互 ( u , i ) (u,i) (u,i),BPR 最大化该对与其未观测对之间的评分差距。其需最小化的目标函数为:
L BPR = ∑ ( u , i , j ) ∈ D − ln σ ( y ^ u i − y ^ u j ) + β ∥ Θ ∥ 2 , L_{\text{BPR}} = \sum_{(u,i,j)\in D} -\ln\sigma\bigl(\hat y_{ui}-\hat y_{uj}\bigr)\;+\;\beta\|\Theta\|^2, LBPR=(u,i,j)∈D∑−lnσ(y^ui−y^uj)+β∥Θ∥2,
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 sigmoid 函数, β \beta β 控制对模型参数的 L 2 L_2 L2 正则化强度以防止过拟合。集合
D = { ( u , i , j ) ∣ u ∈ U , i ∈ I u + , j ∈ I ∖ I u + } D = \{(u,i,j)\mid u\in U,\;i\in I_u^+,\;j\in I\setminus I_u^+\} D={(u,i,j)∣u∈U,i∈Iu+,j∈I∖Iu+}
包含了所有的成对训练实例,这里 U U U、 I I I 分别表示所有用户和所有物品, I u + I_u^+ Iu+ 表示用户 u u u 的已交互物品集合。由于成对训练实例数量庞大,Rendle 等人[10]建议使用随机梯度下降(SGD)进行优化,这样比批量梯度下降的计算成本更低且收敛更快。
2.2.1 VBPR 的脆弱性
尽管 VBPR 为多媒体推荐提供了合理的解决方案,我们认为它在预测用户偏好时并不够鲁棒。如图 1 所示,即便对候选图像施加微小的像素级扰动 ,也可能导致其排名发生巨大变化,超出预期。需要注意的是,图像 i i i 会被深度神经网络(DNN)转换为特征向量 c i c_i ci,预测模型正是利用 c i c_i ci 来估计用户对该图像的偏好(即 h u ⊤ ( E c i ) h_u^\top(Ec_i) hu⊤(Eci) 项)。由此可见,VBPR 的脆弱性可能源于两种情况:
- 特征敏感性 :微小的像素级变化引起了 c i c_i ci 的大幅变化,进而使预测值大幅波动;
- 预测器敏感性 :尽管 pixel 扰动仅导致 c i c_i ci 的微小波动,但模型对这些小波动极为敏感,从而导致预测值发生显著变化。
值得注意的是,这两种可能性都可能同时成立(例如在不同实例中各自出现),并且已有研究工作对此提供了支持。例如,Goodfellow 等人[24]表明许多深度神经网络模型对像素级扰动不具鲁棒性(为第一种可能性提供了证据),而 He 等人[29]则指出矩阵分解模型对用户与物品嵌入上的有目的扰动不够鲁棒(为第二种可能性提供了证据)。无论究竟是哪种原因,这都表明整体多媒体推荐系统的泛化能力较弱------如果将预测函数想象成高维空间中的一条曲线,就可推断该曲线并不平滑,在许多点上存在剧烈波动。我们认为,只要方法中未采取针对性措施,其他基于深度特征的多媒体推荐方法同样会存在这种脆弱性。在本工作中,我们通过对抗学习来解决这一普遍存在的问题,据我们所知,这在多媒体推荐领域尚属首次探索。
三、对抗式多媒体推荐
3.1 预测模型
注意,本工作的重点在于训练鲁棒的多媒体推荐模型,而不是设计全新的预测模型。因此,我们直接采用 VBPR 的框架,并对其做了小幅简化:
y ^ u i = p u ⊤ ( q i + E c i ) , \hat y_{ui} = p_u^\top\bigl(q_i + E\,c_i\bigr), y^ui=pu⊤(qi+Eci),
其中 p u ∈ R K p_u\in\mathbb{R}^K pu∈RK、 q i ∈ R K q_i\in\mathbb{R}^K qi∈RK、 E ∈ R K × D E\in\mathbb{R}^{K\times D} E∈RK×D、 c i ∈ R D c_i\in\mathbb{R}^D ci∈RD 的含义与公式 (2) 中相同。与 VBPR 相比,该"视觉感知"推荐模型的区别在于:每个用户仅使用一个嵌入向量 p u p_u pu,而 VBPR 中用户有两个嵌入向量 p u p_u pu 和 h u h_u hu。这种简化主要是为了在嵌入维度 K K K 相同的情况下,与传统矩阵分解模型进行公平对比(即保证两者具有相同的表示能力)。此外,我们在实验中也尝试过两种用户嵌入方式,未观察到显著性能差异。
3.2 目标函数
近来的多项研究表明,对抗训练能够提升机器学习模型的鲁棒性[24]、[29]、[30]。受此启发,我们设计了对抗训练方法来改进多媒体推荐模型。其基本思路包括两方面:
- 构造对手(adversary):通过对模型输入(或参数)添加扰动,以降低模型性能;
- 对抗训练:在对手扰动的作用下,训练模型使其依然保持良好表现。
1. 对手构造
构造对手(adversary)的目标是尽可能地降低模型的性能。通常,对抗性扰动可施加在模型输入上[24]或模型参数上[29]。针对图 1 所示的脆弱性问题,一个直观的解决方案是在模型输入------即图像的原始像素------上添加扰动 ,因为排序结果的意外变化正是由对像素的扰动引起的。通过这种方式训练模型以抵御对抗扰动,可以同时提高提取图像深度特征的深度神经网络(DNN)和预测用户偏好的潜在因子模型(LFM)的鲁棒性。然而,该方案在实践中难以实施,主要有以下两个原因:
首先,这要求整个系统能够端到端地训练 ;换言之,图像特征提取的 DNN 必须在推荐模型训练过程中同时更新。由于用户--物品交互数据本身非常稀疏,而 DNN 通常拥有大量参数,如果同步训练 DNN,极易出现过拟合问题。
其次,这会大幅增加学习复杂度 。对于一个训练实例 ( u , i ) (u, i) (u,i),推荐模型部分仅需更新两个嵌入向量 p u \mathbf{p}_u pu 和 q i \mathbf{q}_i qi 以及特征转换矩阵 E E E,而 DNN 模型则必须更新整个深度网络,其参数量大数个数量级。此外,为了更新扰动,还需要通过 DNN 进行梯度反向传播,这同样非常耗时。
为了避免像素级扰动带来的困难,我们改为对图像的深度特征向量 c i c_i ci 添加扰动。具体地,扰动后的模型表示为:
y ^ u i ′ = p u ⊤ ( q i + E ⋅ ( c i + Δ i ) ) , \hat y'_{ui} = p_u^\top\bigl(q_i + E\cdot(c_i + \Delta_i)\bigr), y^ui′=pu⊤(qi+E⋅(ci+Δi)),
其中 Δ i \Delta_i Δi 表示对手在深度图像特征向量上添加的扰动。图 2 对该扰动模型进行了示意。此种扰动方式具有两方面的意义:
- DNN 模型仅作为图像特征提取器,不参与对手构造流程,也不会在此过程中被更新,从而使学习算法更加高效;
- 对抗训练虽不能提升深度图像表示 c i c_i ci 本身的质量,但可增强其在矩阵分解潜在空间中的表示能力(即 E c i E\,c_i Eci,因为矩阵 E E E 将通过对抗训练进行更新以提高鲁棒性)。
现在我们考虑如何寻找能够对模型产生最大影响的最优扰动 ,这些扰动也被称为**"最坏情况扰动"[24]。由于模型在训练时是为了最小化 BPR 损失(见公式 (3)),一个自然的想法是将扰动的目标设为与之相反 ------最大化 BPR 损失**。令
Δ = Δ i ∈ R ∣ I ∣ × D \Delta = \\Delta_i\in\mathbb{R}^{|I|\times D} Δ=Δi∈R∣I∣×D
表示对所有图像的扰动矩阵,其中第 i i i 列为 Δ i \Delta_i Δi。我们通过在训练数据上求解以下最优化问题来获得最优扰动:
Δ ∗ = arg max Δ L BPR ′ = arg max Δ ∑ ( u , i , j ) ∈ D − ln σ ( y ^ u i ′ − y ^ u j ′ ) , \Delta^* = \arg\max_{\Delta} L'{\text{BPR}} = \arg\max{\Delta} \sum_{(u,i,j)\in D} -\ln\sigma\bigl(\hat y'{ui} - \hat y'{uj}\bigr), Δ∗=argΔmaxLBPR′=argΔmax(u,i,j)∈D∑−lnσ(y^ui′−y^uj′),
subject to ∥ Δ i ∥ ≤ ϵ , i = 1 , ... , ∣ I ∣ , \text{subject to } \|\Delta_i\|\le\epsilon,\quad i=1,\dots,|I|, subject to ∥Δi∥≤ϵ,i=1,...,∣I∣,
其中 ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 表示 L 2 L_2 L2 范数, ϵ \epsilon ϵ 是控制扰动幅度的超参数。约束 ∥ Δ i ∥ ≤ ϵ \|\Delta_i\|\le\epsilon ∥Δi∥≤ϵ 用于避免通过无界增大 Δ i \Delta_i Δi 规模而取得的平凡最优。需要注意的是,与原始的 BPR 损失相比,此处的扰动版 BPR 损失中移除了对模型参数的 L 2 L_2 L2 正则化项 ,因为 Δ \Delta Δ 的构造基于当前模型参数的固定值,与其无关,因而可安全去除。
2. 模型优化
为了降低模型对对抗扰动的敏感度,除了最小化原始的 BPR 损失之外,我们还要最小化对手的目标函数。令 Θ \Theta Θ 表示模型参数集合,包括所有用户的嵌入向量 p u p_u pu、所有物品的嵌入向量 q i q_i qi 以及变换矩阵 E E E。我们将模型的优化目标定义为:
Θ ∗ = arg min Θ L B P R + λ L B P R ′ \Theta^* = \arg\min_{\Theta}\;L_{\mathrm{BPR}} + \lambda\,L'_{\mathrm{BPR}} Θ∗=argΘminLBPR+λLBPR′
即
Θ ∗ = arg min Θ ∑ ( u , i , j ) ∈ D − ln σ ( y \^ u i − y \^ u j ) − λ ln σ ( y \^ u i ′ − y \^ u j ′ ) + β ∥ Θ ∥ 2 . \Theta^* = \arg\min_{\Theta} \sum_{(u,i,j)\in D} \bigl-\\ln\\sigma(\\hat y_{ui}-\\hat y_{uj}) -\\lambda\\,\\ln\\sigma(\\hat y'_{ui}-\\hat y'_{uj})\\bigr +\beta\|\Theta\|^2. Θ∗=argΘmin(u,i,j)∈D∑−lnσ(y\^ui−y\^uj)−λlnσ(y\^ui′−y\^uj′)+β∥Θ∥2.
- 其中, λ \lambda λ 是控制对手损失对整体训练影响程度的超参数;
- 当 λ = 0 \lambda=0 λ=0 时,对抗项失效,方法退化为标准的 VBPR;
- 在该式中,对手的损失 L B P R ′ L'_{\mathrm{BPR}} LBPR′ 相当于对模型的一种正则化,使其更具鲁棒性,因而也被称为"对抗正则器"(adversarial regularizer)。
为了将两者统一,我们将其表述为一个极小--极大(minimax)目标函数。模型参数 Θ \Theta Θ 作为极小化方(minimizing player),扰动 Δ \Delta Δ 作为极大化方(maximizing player):
( Θ ∗ , Δ ∗ ) = arg min Θ arg max Δ L B P R ( Θ ) + λ L B P R ′ ( Θ , Δ ) , (\Theta^*, \Delta^*) = \arg\min_{\Theta}\,\arg\max_{\Delta}\; L_{\mathrm{BPR}}(\Theta) \;+\;\lambda\,L'_{\mathrm{BPR}}(\Theta, \Delta), (Θ∗,Δ∗)=argΘminargΔmaxLBPR(Θ)+λLBPR′(Θ,Δ),
其中对每个 i = 1 , ... , ∣ I ∣ i=1,\dots,|I| i=1,...,∣I∣,都有 ∥ Δ i ∥ ≤ ϵ \|\Delta_i\|\le\epsilon ∥Δi∥≤ϵ。
相比 VBPR,我们的 AMR 多出了两个需要指定的超参数------ ϵ \epsilon ϵ 和 λ \lambda λ。二者都对推荐效果至关重要,需谨慎调优。特别地,若数值过大,模型虽能更好地抵御对抗扰动,却可能破坏正常的训练过程;若数值过小,则削弱了对手的影响,无法提升模型的鲁棒性与泛化能力。
除了极小--极大目标以外,我们也可以通过引入随机扰动来提升模型鲁棒性,即令模型在参数的随机噪声下仍能保持良好表现。但实验(图 4)表明,这种"随机噪声"方法效果不及我们的极大化对手策略。另一种思路是只优化对抗正则项 L B P R ′ L'_{\mathrm{BPR}} LBPR′,但这样测试时使用的是干净模型,往往难以在无扰动场景下获得良好效果。
我们的极小--极大形式,也可视为一种数据增强策略:同时在原始数据和扰动数据上优化模型。在下一节中,我们将讨论如何优化该极小--极大目标函数。
这一节的核心就是告诉我们,想让多媒体推荐系统在"被人故意捣乱"时依然表现稳定,得做两件事:
先确定"坏人"怎么捣乱(构造对手)
- 我们不直接在原始图片上动手,而是在网络提取出来的"图像特征向量"上加一点小扰动。
- 这些扰动故意让系统的评分动起来------把它们当成"最坏情况",也就是让推荐效果最糟糕的那种小改变。
- 为了防止"坏人"加得太大,我们限制每次加的量不能超过一个幅度上限(就像打游戏不能放太大招)。
再让模型学会对抗这些捣乱(模型训练)
- 普通训练只有一个目标:在干净数据上把预测误差降到最低。
- 对抗训练多了一个"防守"目标:在加入了最坏扰动后,依然要把预测误差降得低一些。
- 损失函数里加了个权重λ,控制"防守"目标和"正常训练"目标各占多大比重。λ=0时就是普通训练;λ很大时就专注"防守"了。
把这两个过程合在一起,就变成了一个"博弈"------模型想把两种误差(干净的和捣乱后的)都降到最低,对手想把捣乱后的误差推到最高。最后模型在这种"你追我赶"的过程中,既能学会正常推荐,又能学会抵御那些最坏的小扰动,让鲁棒性更强。
思考
1. 这个模型解决了什么问题?
传统的多媒体推荐(如 VBPR)虽然能利用深度图像特征提升准确率,却对"对抗性扰动"极度敏感:只要在输入图像或其深度特征上加上人眼难以察觉的微小噪声,推荐排序就会大幅波动,说明模型在真实场景下可能被恶意干扰并性能崩溃。AMR 的出现,就是为了解决多媒体推荐系统在遭遇这类"最坏情况扰动"时的脆弱性,提高其鲁棒性与安全性。
2. 它是怎么解决的?
-
扰动设计(构造对手)
- 不直接在原始像素上动手,而是在深度神经网络提取出的图像特征向量 c i c_i ci 上加限幅扰动 Δ i \Delta_i Δi;
- 这些扰动被优化为"最坏情况",即能够最大化推荐模型的 BPR 损失,使模型在此扰动下表现最差。
-
对抗训练(模型优化)
- 在常规最小化 BPR 损失的基础上,同时最小化"被扰动"情况下的 BPR 损失,两者加权构成新的目标函数;
- 该目标可写成一个"极小--极大"博弈:模型参数 Θ \Theta Θ 要把总损失降到最低,对手 Δ \Delta Δ 要把扰动损失推到最高;
- 通过这样的训练,模型不仅在干净数据上学习用户偏好,也学会了抵御最糟糕的特征扰动。
3. 启示
- 鲁棒性不能靠事后修补:对于深度特征驱动的推荐系统,必须在训练阶段就模拟真实世界可能遭遇的恶意或随机扰动,否则上线后极易被"小打小闹"击垮。
- 对抗训练是一种有效的正则化:将最坏情况扰动纳入损失,可以在提升鲁棒性的同时,对模型起到类似数据增强和正则化的作用,有助于泛化。
- 多媒体推荐需要兼顾效率与安全:直接对像素端做端到端对抗训练成本极高,AMR 通过在深度特征层面加扰动,既避免了对大规模 DNN 反复微调的开销,也能取得良好效果,为工业落地提供了可行思路。
鲁棒性不能靠事后修补 :对于深度特征驱动的推荐系统,必须在训练阶段就模拟真实世界可能遭遇的恶意或随机扰动,否则上线后极易被"小打小闹"击垮。
-
对抗训练是一种有效的正则化 :将最坏情况扰动纳入损失,可以在提升鲁棒性的同时,对模型起到类似数据增强和正则化的作用,有助于泛化。
-
多媒体推荐需要兼顾效率与安全:直接对像素端做端到端对抗训练成本极高,AMR 通过在深度特征层面加扰动,既避免了对大规模 DNN 反复微调的开销,也能取得良好效果,为工业落地提供了可行思路。