为什么要使用ElasticSearch
Elasticsearch 主要为系统提供搜索功能, MySQL 这类传统关系型数据库主要为系统提供数据存储功能
Elasticsearch 的优势 :
支持多种数据类型,非结构化,数值,地理信息。简单的 RESTful API,天生的兼容多语言开发。
提供更丰富的分词器,支持热点词汇查询。
近实时查询,Elasticsearch 每隔 1s 把数据存储至系统缓存中,且使用倒排索引提高检索效率 。支持相关性搜索,可以根据条件对结果进行打分。
天然分布式存储,使用分片支持更大的数据量
ElasticSearch中的基本概念
Index(索引)
作为名词理解的话,索引是一类拥有相似特征的文档的集合比如商品索引、商家索引、订单索引,有点类似于 MySQL 中的数据库表。作为动词理解的话,索引就是将一份文档保存在一个索引中。
Document(文档)
可搜索最小单位,用于存储数据,一般为 JSON 格式。文档由一个或者多个字段(Field)组成,字段类型可以是布尔,数值,字符串、二进制、日期等数据类型。
Type(字段类型)
每个文档在 ES 中都必须设定它的类型。ES 7.0 之前,一个 Index 可以有多个Type。6.0 开始,Type 已经被 Deprecated。7.0 开始,一个索引只能创建一个 Type :_doc。8.0之后,Type 被完全删除,删除的原因看这里:Removal of mapping types | Elasticsearch Guide 7.17 | Elastic
Mapping(映射)
定义字段名称、数据类型、优化信息(比如是否索引)、分词器,有点类似于数据库中的表结构定义。一个 Index 对应一个 Mapping。
Node(节点)
相当于一个 ES 实例,多个节点构成一个集群。
Cluster(集群)
多个 ES 节点的集合,用于解决单个节点无法处理的搜索需求和数据存储需求。Shard(分片): Index(索引)被分为多个碎片存储在不同的 Node 节点上的分片中,以提高性能和吞吐量。
Replica(副本)
Index 副本,每个 Index 有一个或多个副本,以提高拓展功能和吞吐量。DSL(查询语言) :基于 JSON 的查询语言,类似于 SQL 语句。
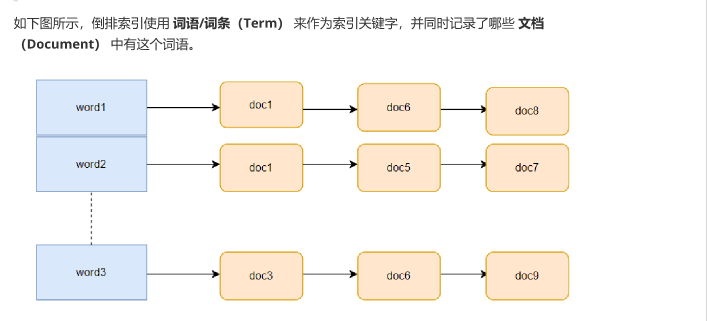
什么是倒排索引
倒排索引 也被称作反向索引(inverted index),是用于提高数据检索速度的一种数据结构,空间消耗比较大。
倒排索引首先将检索文档进行分词得到多个词语/词条,
然后将词语和文档 ID 建立关联,从而提高检索效率
倒排索引使用词语和词条来作为索引的关键字,记录哪些文档中有这些词语
什么是正排索引
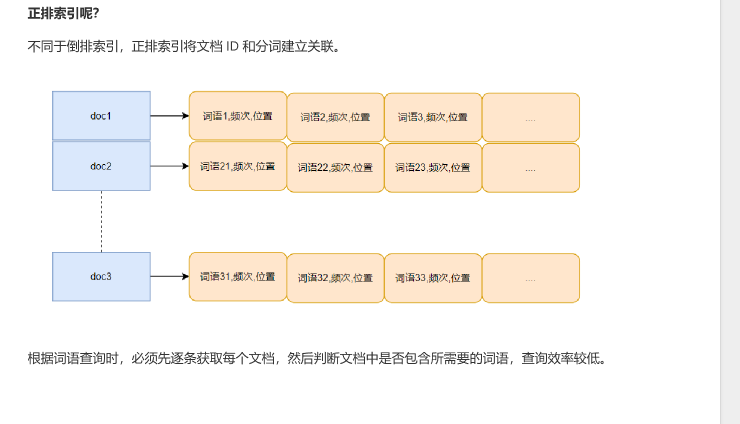
查询时,先逐条获取每个文档,然后再判断文档中是否有包含所需要的词语
正排索引和倒排索引的优缺点
正排索引:
优点:维护成本低,新增数据的时候只要在末尾新增一个ID
缺点:扫描文档,在文档中一个一个比较来查找关键词,查询效率极低
倒排索引:
优点:建立分词和文档ID的关系,大大提高查询效率
缺点:建立倒排索引的成本高,维护起来困难。文档的每次更新都意味着倒排索引的重建

说一下倒排索引的创建和检索流程
创建流程:
-
建立文档列表,每个文档都有一个唯一的文档 ID 与之对应。
-
通过分词器对文档进行分词 ,生成类似于**<词语,文档ID>** 的一组组数据。
-
将词语作为索引关键字,记录下词语和文档的对应关系,也就是哪些文档中包含了该词语。
检索流程:
-
根据分词查找对应文档 ID
-
根据文档 ID 找到文档
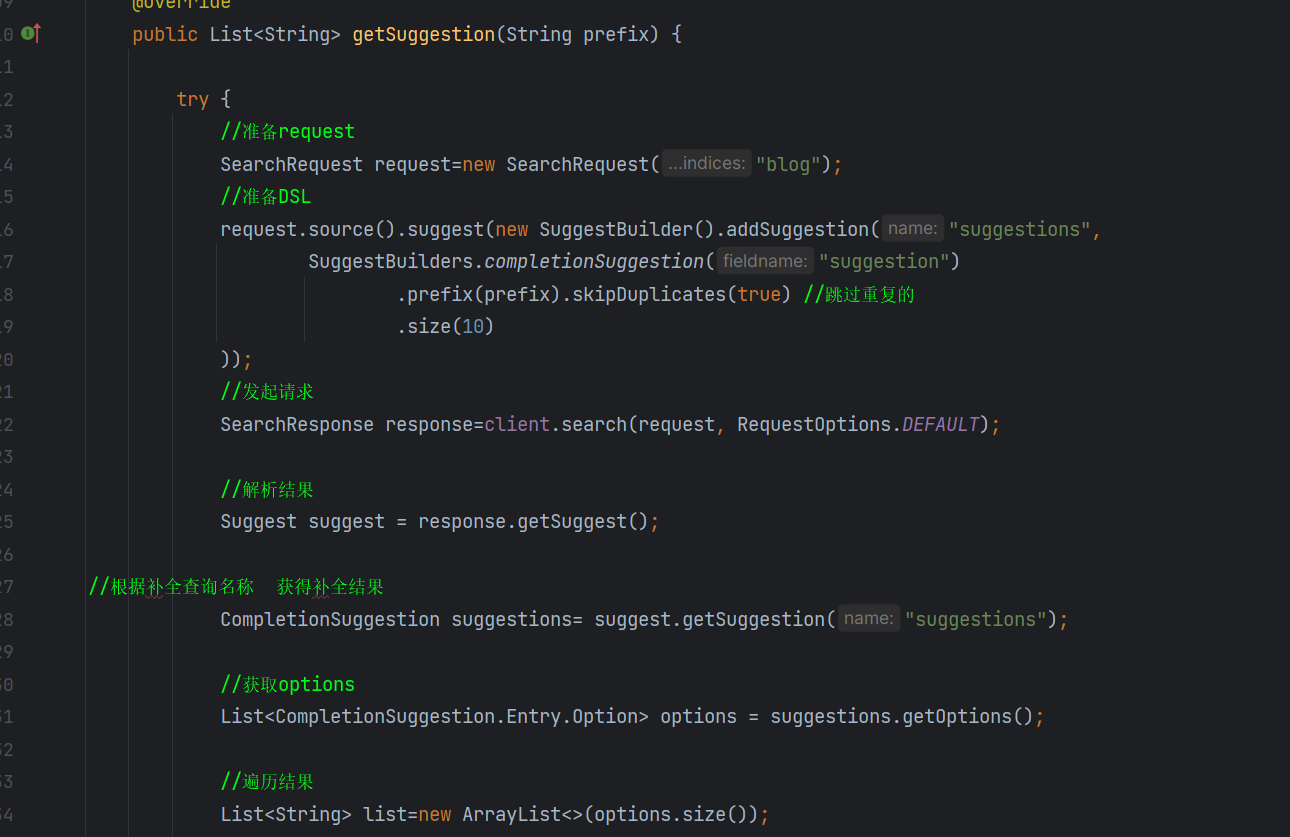
说一下ES的聚合搜索
内容+标签匹配
SearchRequest 指定我们要查找的索引的名字
BoolQueryBuilder 准备我们的DSL语句
然后用request**.source().query()** 来把我们弄好的DSL语句放进去然后发起请求
然后request.source.form().size()来进行分页
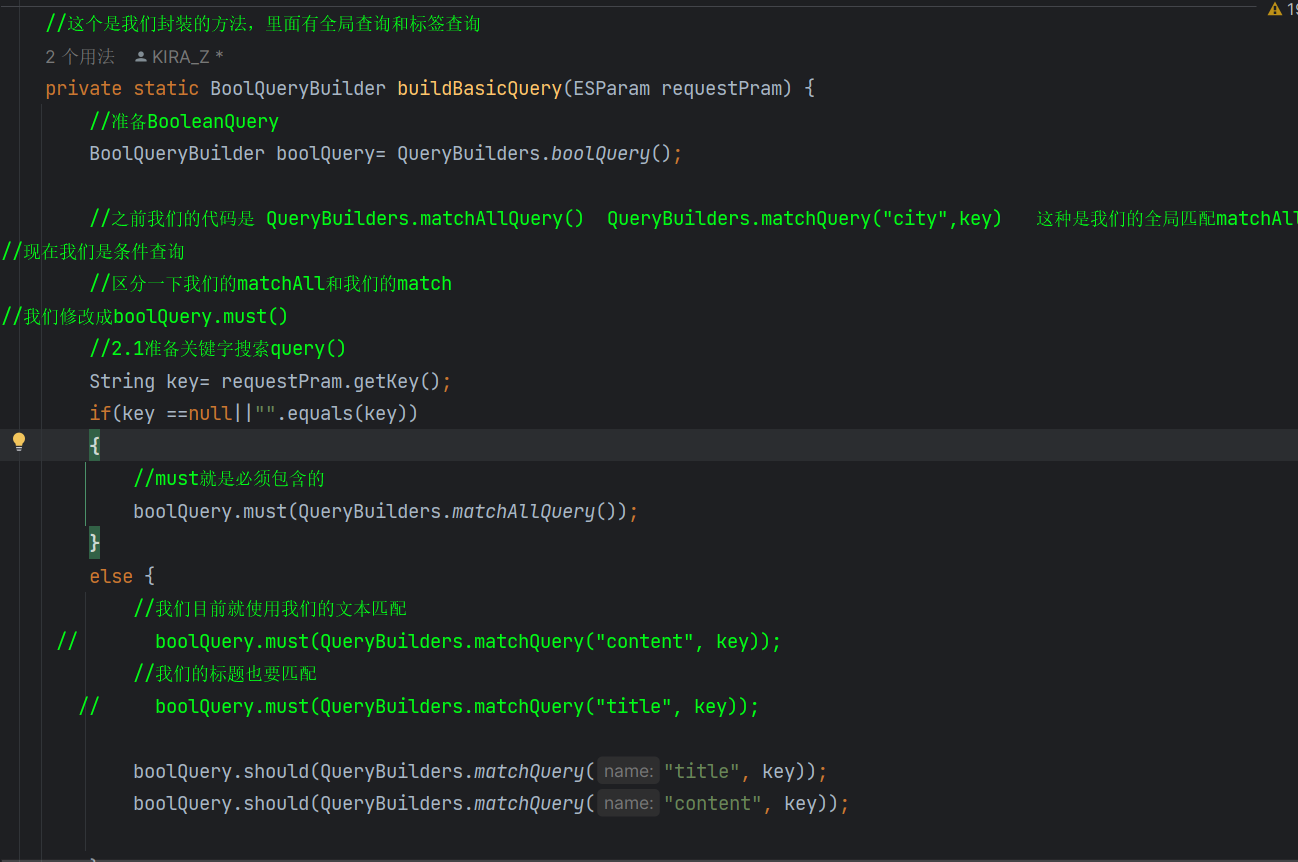
我自己封装了一个BoolQuery方法
如果我们的搜索栏没有指定东西,那么我们直接must 必须匹配 matchAllQuery
如果指定了东西 我们要用should 文本匹配content 标签匹配titile,有就匹配
如果两个都有,我们用must就表示必须同时匹配
如果用should,就是有就匹配
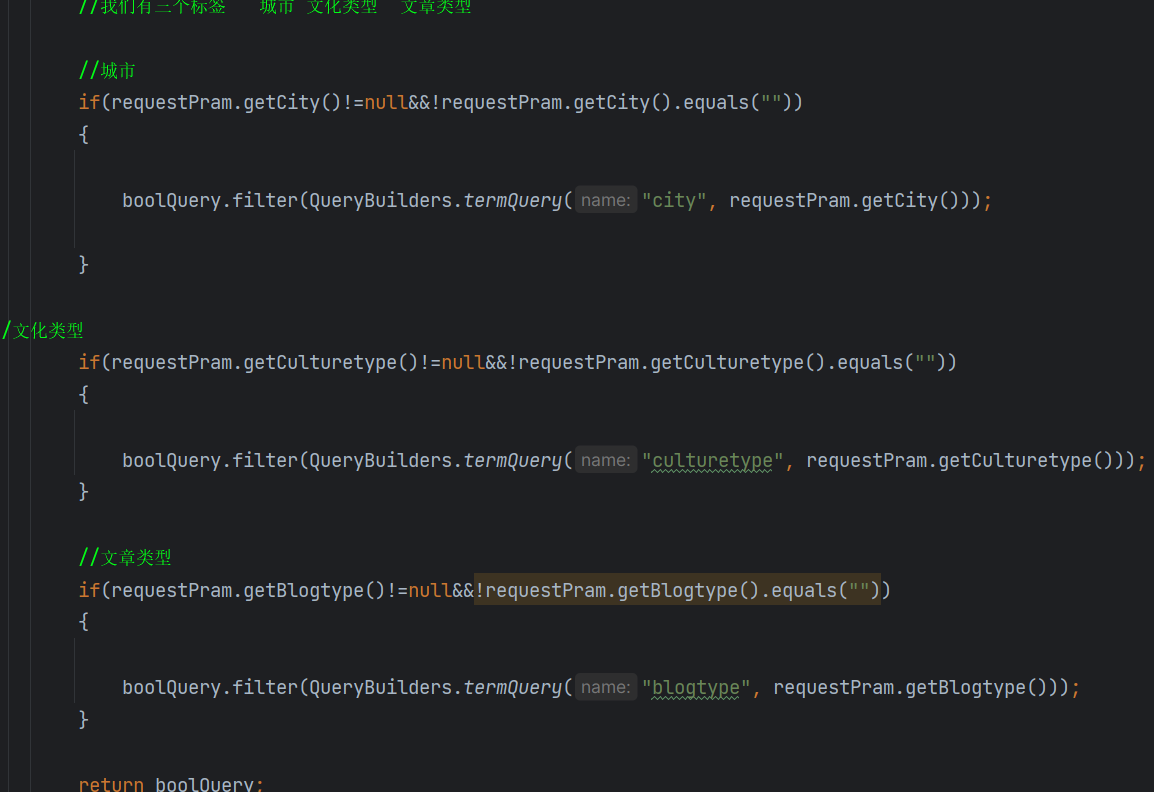
filter 来过滤我们的内容,然后我们用**term()**来进行标签匹配
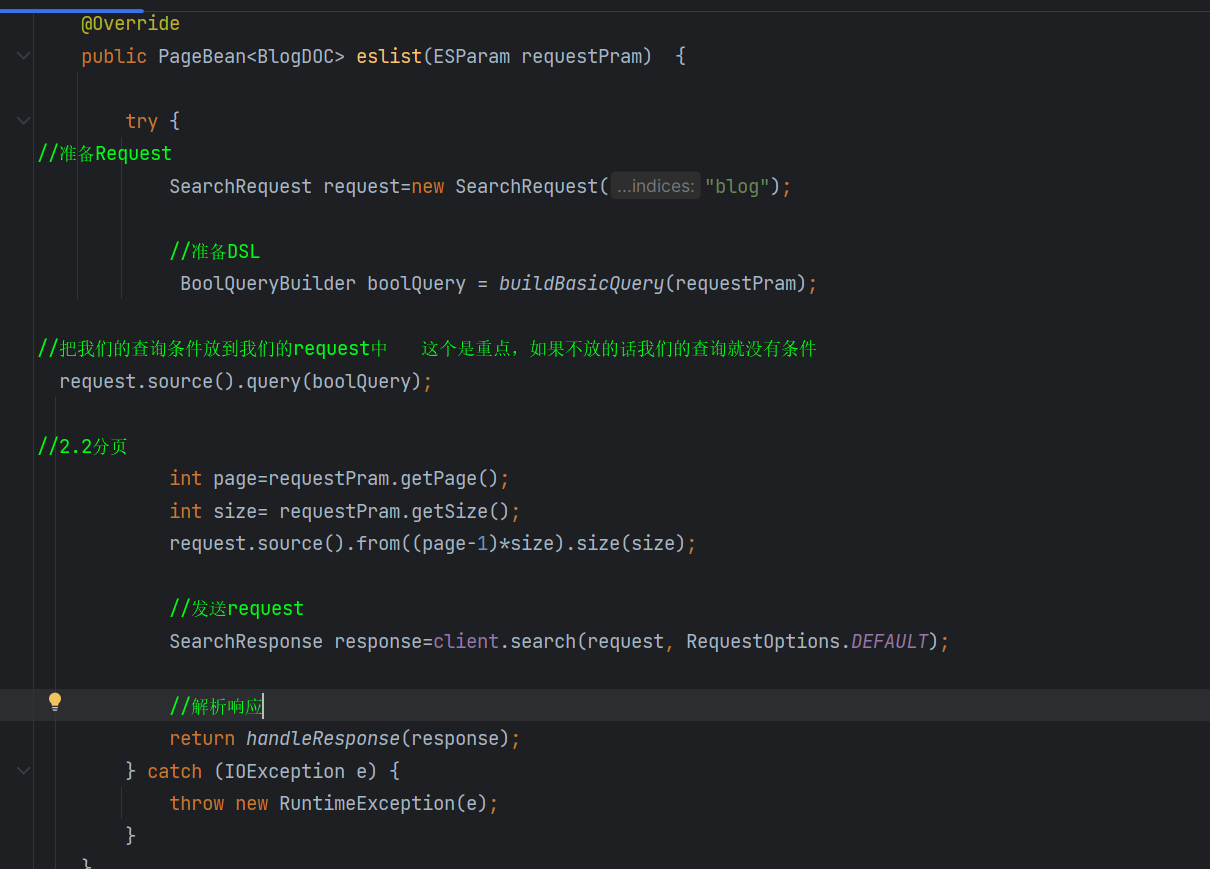
自动补全
在索引弄多一个suggestion字段,往里面放我们补全的字段,例如地点或标题以及其他
然后跳过重复匹配的