基于STR图谱数据的多任务模型及去噪
摘要
随着基因组学的不断发展,STR(短串联重复)图谱分析已成为基因型预测和身份鉴定的重要工具。本文基于STR图谱数据,通过多种机器学习模型,探索不同去噪方法对基因型数据处理和贡献者人数预测的影响。
数据处理方面,首先从提供的Excel文件中读取了样本数据,并对其进行了预处理,包括数据清洗和特征提取。在处理过程中,重点关注了每个样本的等位基因数量、Size值和Height值等基因特征。这些数据为后续模型训练和验证提供了可靠的基础。
针对问题一,我们从指定的Excel文件中读取样本数据。该文件包含了不同STR基因标记的多个样本信息。通过查找文件中列的头部信息,代码识别出包含样本文件名、标记、染料以及等位基因、Size、Height数据的列位置。会从提供的STR图谱数据中提取具体的基因特征,如等位基因数量、Size值和Height值等。,我们使用策树、随机森林、KNN、支持向量机(SVM)、逻辑回归和神经网络。对于每种模型,首先进行训练,然后在验证集上进行预测,并计算出准确率、精确度、召回率和F1分数等性能指标。 为了进一步提高模型的精度,结合了多种优化技术,包括特征选择、超参数优化、类别不平衡处理和集成学习。
针对问题二,提取了样本的等位基因数量、峰高、峰大小等特征,并通过这些特征计算了一系列与混合比例相关的变量。为了预测混合比例,代码构建了多个特征集,包括基本峰高特征、前五个峰高、峰高的分布形状、峰高差异和比值特征等。使用这些特征,模型计算了每个特征与混合比例之间的相关性,并为不同的贡献者数量(如2、3、4、5人)构建了独立的预测模型。在模型训练过程中,针对每个贡献者数量的样本,选择了最相关的特征(前15个),并使用随机森林、支持向量回归(SVR)、梯度提升树(GBT)等多种模型进行训练。通过5折交叉验证评估模型性能,并最终选择表现最佳的模型。代码还进行了误差分析,包括计算每个模型的RMSE和R²值,并在不同贡献者数量下可视化了模型性能。
针对问题三,我们构建了多个基于不同贡献者人数的预测模型,通过机器学习技术对基因型数据进行分析和预测。在特征提取部分,我们为机器学习模型准备了特征矩阵,选取了数值型特征列,并排除了非特征性列,如基因座编码和贡献者人数等。我们将数据按贡献者人数分组,分别为2、3、4、5人组建立不同的机器学习模型。对于每一组,我们进行了特征选择,并使用5折交叉验证来训练和验证模型。具体地,2人组采用了随机森林回归,3人组使用支持向量机(SVM),4人组使用K近邻(KNN),而5人组使用随机森林集成模型。对于每个模型,我们计算了交叉验证的准确率,并生成了混淆矩阵来评估模型性能。 针对问题四,实现了六种不同的去噪方法在STR图谱数据上的应用,对不同去噪方法(如卡尔曼滤波、傅里叶变换、中值滤波、非局部均值滤波、高斯滤波和小波去噪)对于问题一、二建立模型的精度进行评价。
关键词:STR图谱分析,贡献者人数预测,机器学习,去噪方法,特征选择
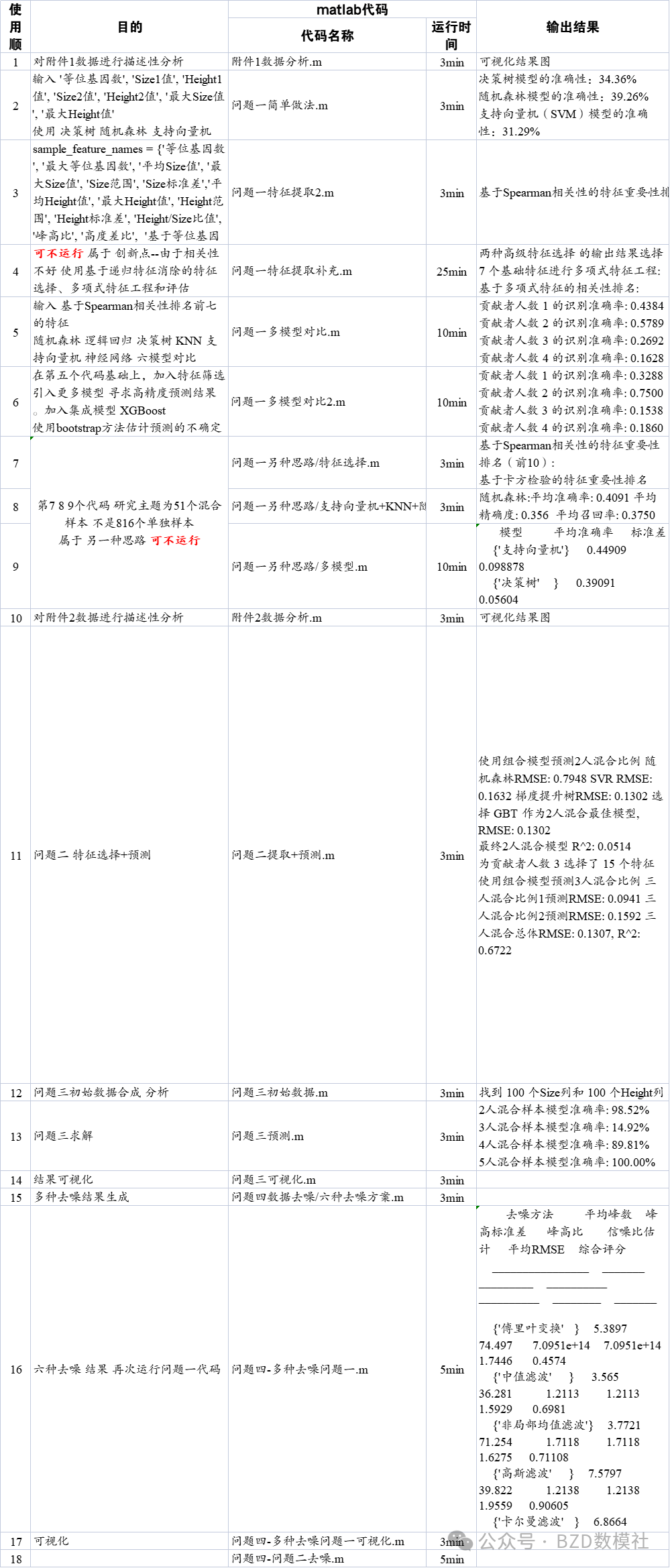
从统计结果来看,三位贡献者的混合样本数量最多,共256份,其次为两位贡献者样本240份,四位贡献者样本176份,五位贡献者样本144份。饼图进一步显示,三人混合约占30%、二人占28%、四人占21%、五人占16%,比例分布明显。水平柱状图与极坐标图的呈现则对比清晰,极坐标图中四个点沿圆周分布,半径长短代表样本数差异,直观体现贡献者人数越多样本量越少的趋势。
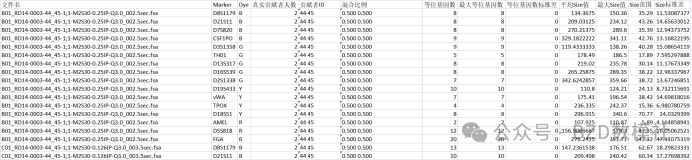
特征名称 Spearman相关性 p值
{'显著等位基因数' } 0.20685 2.4577e-09
{'高度差比' } 0.18871 5.6008e-08
{'Height1值' } 0.16313 2.8088e-06
{'高度比例方差' } 0.13725 8.3843e-05
{'相邻峰间距平均值' } 0.12019 0.00058063
{'Height2值' } 0.1128 0.0012568
{'平均Height值' } 0.098133 0.0050206
{'Height/Size比值' } 0.085736 0.014291
{'最大Height值' } 0.078902 0.0242
{'Height范围' } 0.068854 0.049278
{'基于等位基因数的估计人数' } 0.066909 0.056065
{'基于最大等位基因数的估计人数'} 0.066909 0.056065
{'等位基因数' } 0.066794 0.056493
{'最大等位基因数' } 0.066794 0.056493
{'峰高比' } 0.063042 0.071881
5.1.3 人数预测模型的构建
根据前述步骤,我们提取了前七个最具代表性的特征(如高度差比,Size2值,峰高比等)。这些特征的索引在代码中被自动选定并从特征矩阵中提取出来。为了避免特征之间的量纲差异影响模型训练,特征数据通过标准化处理,即将数据转化为均值为 0 ,标准差为 1 的标准正态分布。标准化的公式为:
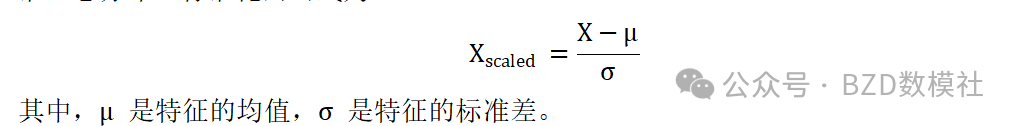
在数据集准备好之后,我们进行数据划分,将数据集按
用于训练,
用于测试。使用分层抽样方法,确保每个类别(贡献者人数)的样本比例在训练集和测试集之间保持一致。通过交叉验证,我们进一步优化模型性能,采用 5 折交叉验证来评估模型的稳定性与泛化能力。在每个交叉验证折中,我们都使用不同的训练集和验证集,以减少模型对数据的依赖。
模型训练与评估
模型训练部分使用了多种常见的分类模型,包括决策树,随机森林,KNN,支持向量机(SVM),逻辑回归和神经网络。对于每种模型,首先进行训练,






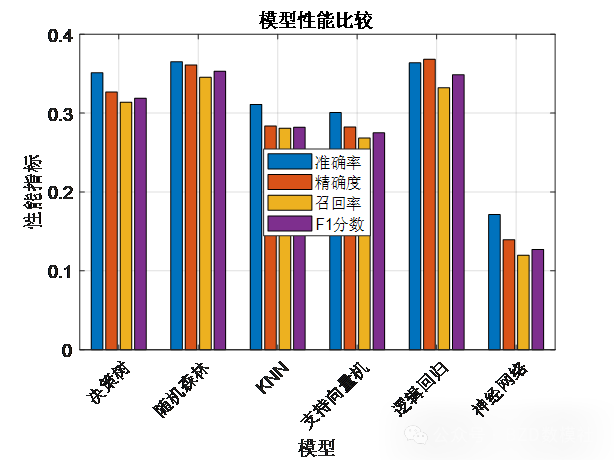
性能比较中,随机森林与逻辑回归的平均准确率最高,分别约0.37和0.36,精确度与F1值也均位于0.330.37区间,召回率略低但整体领先;决策树次之,准确率约0.35,指标较为均衡;KNN与支持向量机表现中等,准确率在0.300.31,精确度和召回率在0.26~0.29之间;神经网络最弱,准确率仅约0.22,伴随最低的精确度、召回率和F1值,说明其在此任务中未能有效学习特征。
5.1.3 高精度预测模型
在数据划分阶段,采用了分层抽样(Stratified Sampling),以确保训练集和测试集中的每个类别的比例一致。分层抽样能够避免在类别不平衡情况下,某一类别样本在训练或测试集中占比过大,进而影响模型的训练和评估结果。

