简要讨论使用第三方调试工具或在多个项目中复用自己的调试工具
今天的工作主要是在提升调试界面的可用性和美观性。昨天已经整理了布局代码,今天的目标是继续优化调试界面,使其更易用。我们已经为调试工具添加了许多新功能,并且在实现过程中反复思考并确定了合适的架构设计。这个过程也让我们展示了如何进行探索性开发,并且如何设计一个能够支持大量复杂操作的架构。
目前,我们正处于最终的优化阶段,重点是让界面更整洁、更加实用。这不仅仅是为了美化界面,更多的是为了能更有效地展示数据和让界面在需要的地方更加友好。调试工具的核心目标是更清晰地显示程序运行中的信息,特别是那些在代码中难以直观看到的部分。能够实时查看这些信息非常有价值,因为它能帮助我们发现潜在问题。
在这个过程中,我们也发现了很多能够改进的地方。例如,第一次在屏幕上显示性能条时,我们就发现了一些性能瓶颈,这些是在没有调试工具的情况下无法察觉的。通过可视化程序状态,能够帮助我们快速定位问题,尤其是在看不见的部分。
在开发这种工具时,理想情况下,我们会构建一个能够在多个项目中复用的调试库,这样每次都不需要重新实现。市场上也有一些可以购买或使用的外部调试工具包,这类工具的优点是可以减少调试代码对主项目的影响,因为调试代码通常在游戏发布时会被剔除,只有在开发过程中使用。这使得即使调试代码有些许问题,也不会影响到最终用户体验,因为它不在最终产品中运行。
我们也讨论了如何将这种调试工具发展成一个可以在不同项目中使用的库,这样每次开发新项目时都能直接用到这些功能。调试代码通常在不同项目中比较相似,因此将其标准化并复用是一个不错的选择。


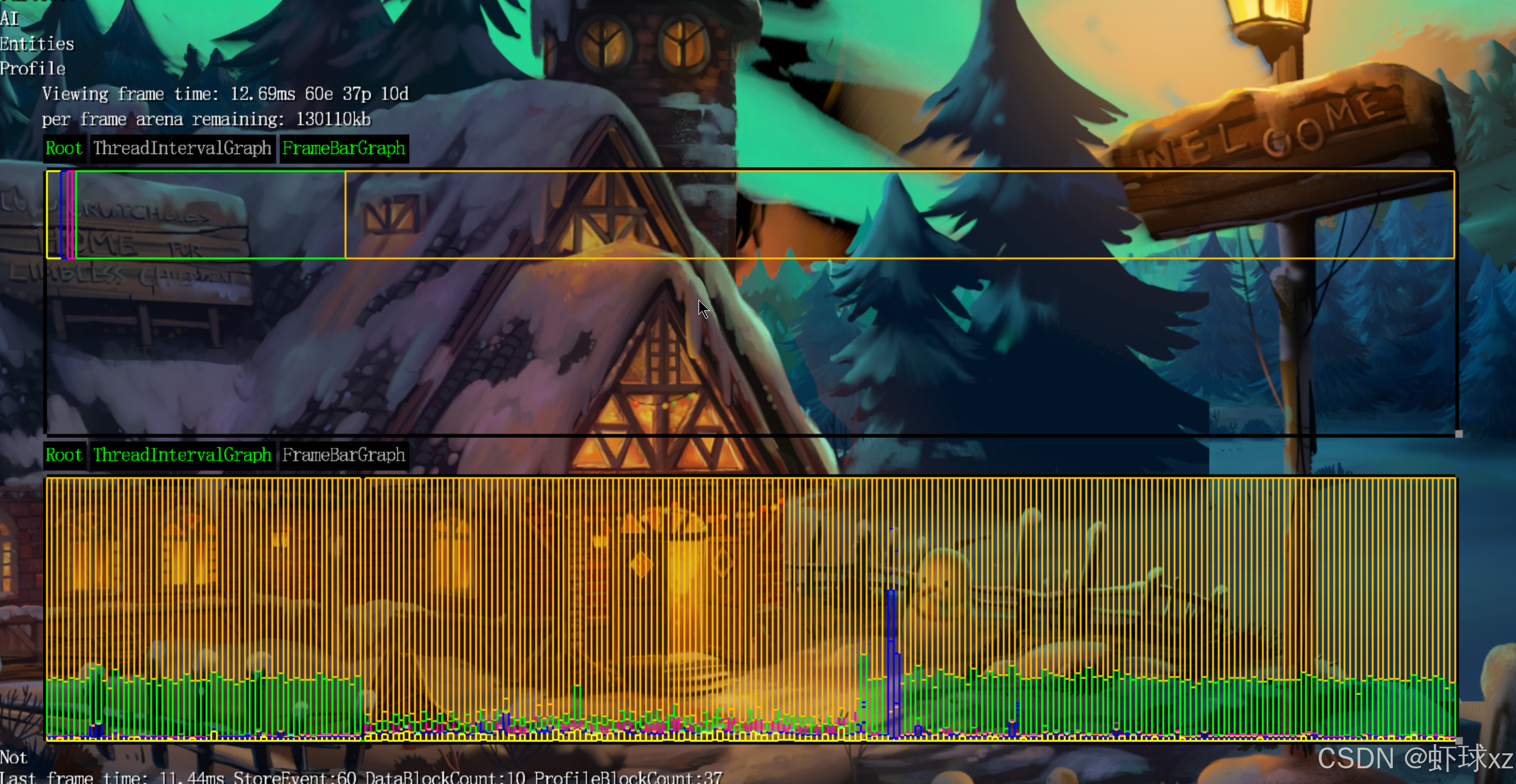
启动游戏并设定今天的开发目标
今天的目标是进一步完善调试工具中的性能分析窗口,并使其更具可用性。昨天的进展是成功地添加了一些按钮,我们可以通过这些按钮暂停、移动并查看一些具体的调试数据。尽管这些功能都已经可以正常使用,但在继续开发之前,我们希望集中精力完善性能分析窗口。
目前,性能分析窗口的渲染效果还不够清晰,因此需要进行一些优化。现在,窗口只能显示一层数据,我们希望能够显示多层信息,类似于之前实现的功能,虽然它被关闭了。此外,还可以考虑将条形图的边框涂黑,或者用其他方式来使其更易于查看,从而提升界面的可用性。总体目标是让这些功能更加直观、易用。
接下来,我们打算添加一个按钮,用来显示类似标准性能分析器的"Top List",这将允许我们查看某个函数或所有函数中,哪些函数占用了最多的总时间。这个功能会让我们以排序的形式查看这些信息,从而更容易识别性能瓶颈。
为了确保这些功能的正常实现,还需要确认调试工具的某些功能是否按预期工作。例如,我们希望能够轻松创建并默认打开多个不同类型的性能分析视图。在当前的框架中,已经成功实现了这一点,因此接下来可以通过调整设置,确保如果需要,多个分析视图能够同时展示。
在调整分析窗口时,还发现了一些细节需要优化。例如,窗口中显示的图形条形过大,可能在屏幕上占用过多空间,因此需要减小它们的默认尺寸。这将确保如果多个分析视图同时显示时,它们不会显得过于拥挤,保持界面的整洁。
总的来说,虽然当前的实现已经非常接近预期,但还有一些细节需要进一步调整和优化。今天的任务主要是完善这些小细节,使得调试工具的使用更加顺畅和高效。
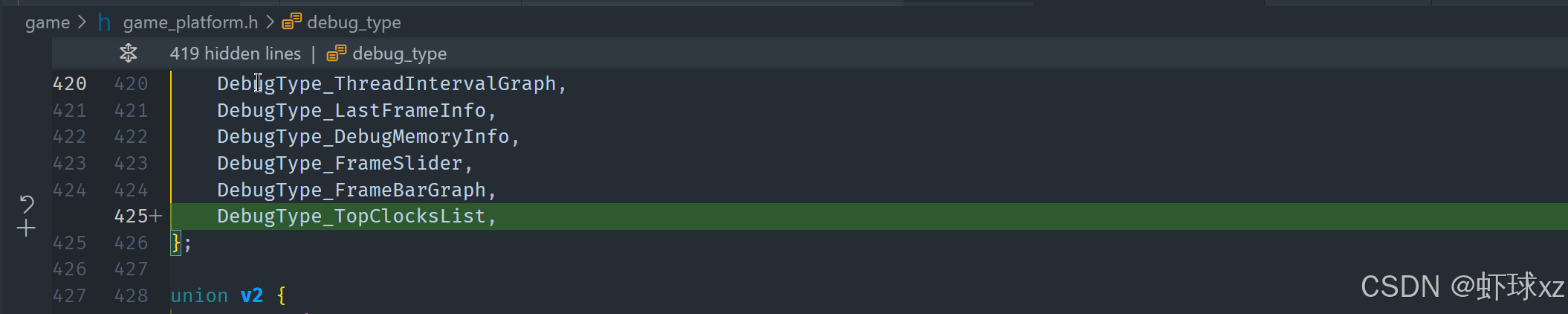
game_debug.cpp:添加按周期计数降序打印调试元素的能力
接下来的任务是添加一个"Top View"功能,也就是一个用于显示排序后函数列表的界面。这个视图将展示所有函数在执行过程中所消耗的总时间,并以从高到低的顺序排列,便于我们快速定位哪些函数是性能开销最大的部分。这种形式与标准性能分析器中常见的"Top Clocks List"类似,计划通过打印每个函数占用资源的一行信息来实现这一功能。
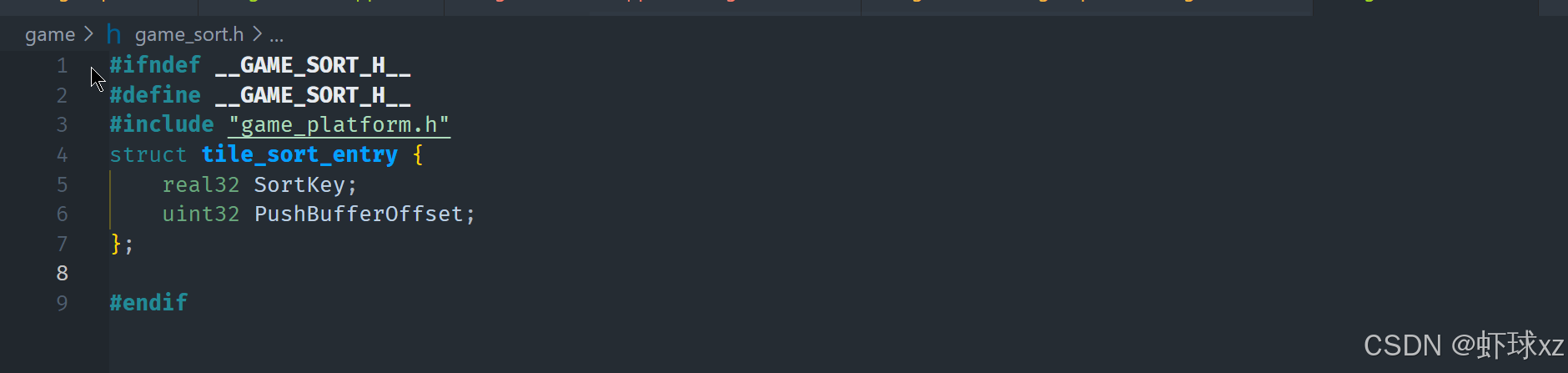
实现这一功能时,希望能复用之前已经写好的排序代码。之前的排序逻辑已经存在,因此希望能够直接将相关部分提取出来使用,而不需要重新实现一遍。目前的排序结构是用于渲染系统中的,核心结构名为 TileSortEntry,它包含一个排序键(sort key)和一个 push buffer 偏移值。这种结构实际上可以通用化,只要提供一个排序键(例如浮点数),以及一个对应的索引,就可以实现对任意数据的排序。
因此,决定将这部分排序逻辑提取出来,做成一个通用的排序模块。由于项目中还没有一个专门的工具文件用于存放通用逻辑,就准备新建一个文件,专门用于实现这个通用排序功能。这需要一些基础的编辑器配置支持,例如自动添加文件头模板等,目前还没有设置好这些辅助功能,未来也许会实现类似 Emacs 中已有的那种自动模板插入功能,简化添加新文件的流程。
虽然暂时还缺乏这些便利工具,但仍决定继续推进当前任务,即编写排序工具文件并实现必要的排序逻辑,为之后的 "Top Clocks List" 功能做好准备。这个功能的目标是提升调试工具的可视化能力和性能分析效率。
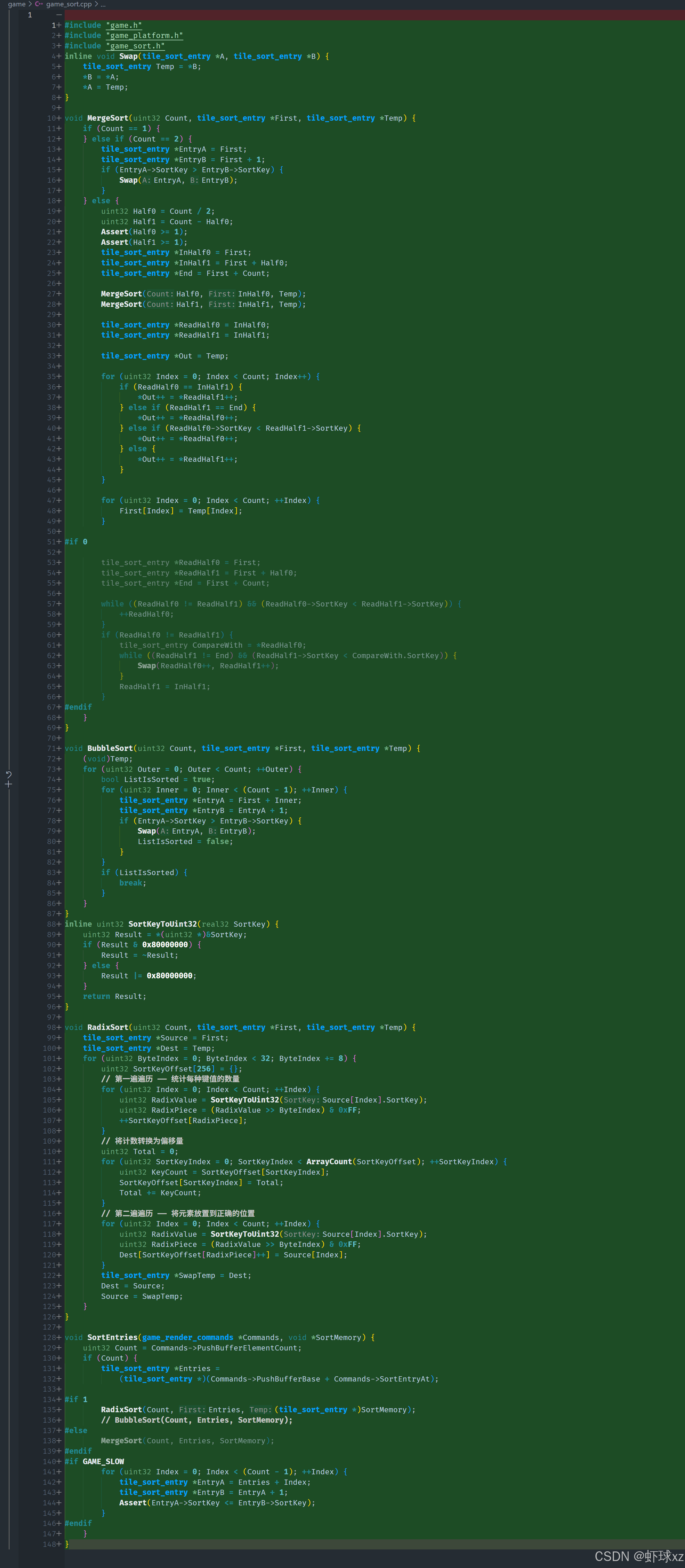
game_sort.cpp:将排序代码从 game_render_group.h 和 game_render.cpp 中拆分出来
我们接下来需要为排序功能创建一个新的,打算暂时称为 sort 文件,也就是一个用于排序功能的模块。
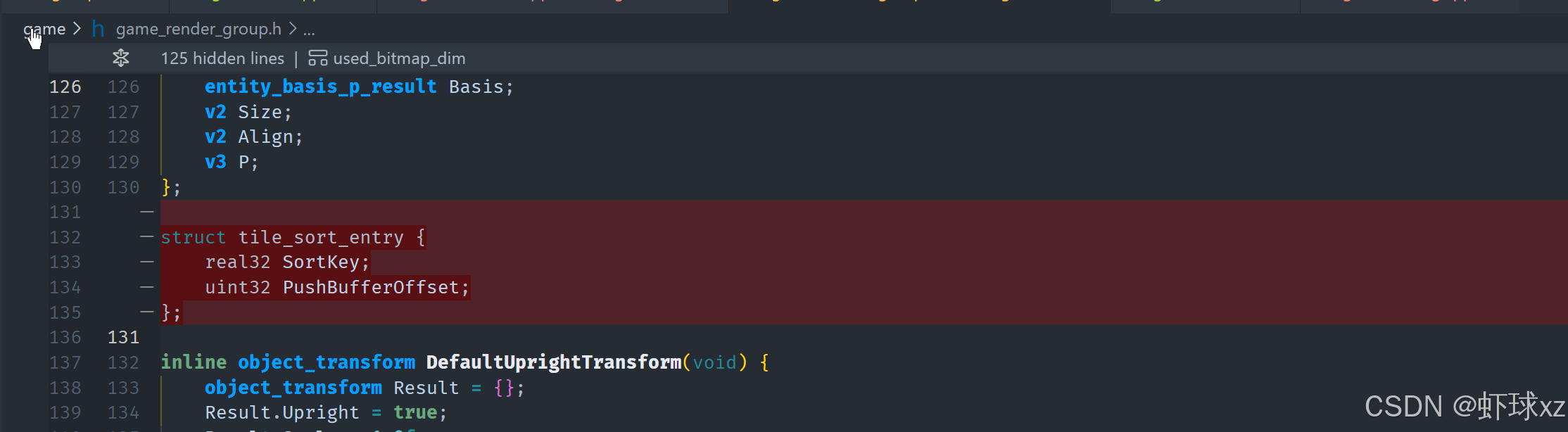
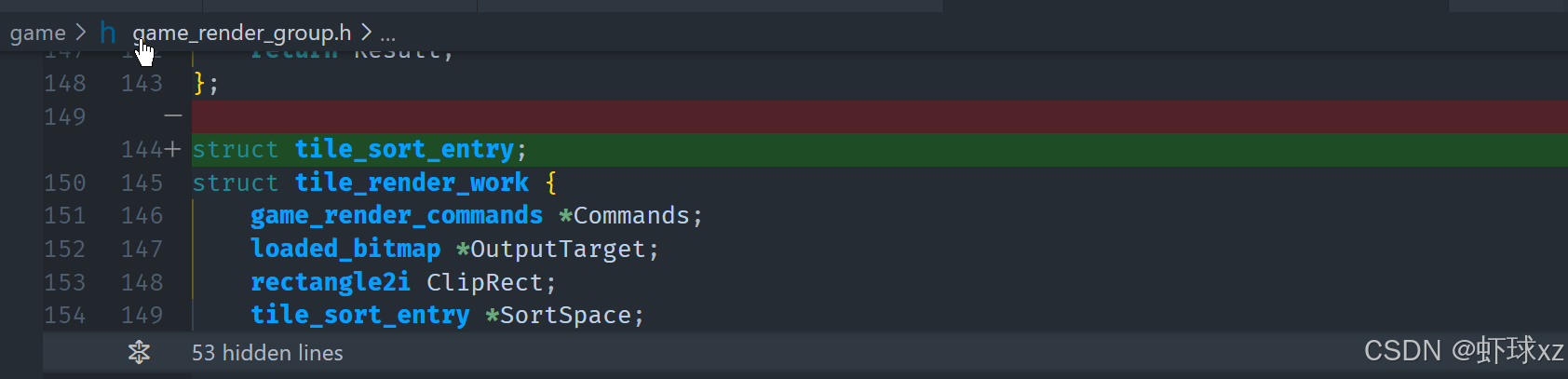
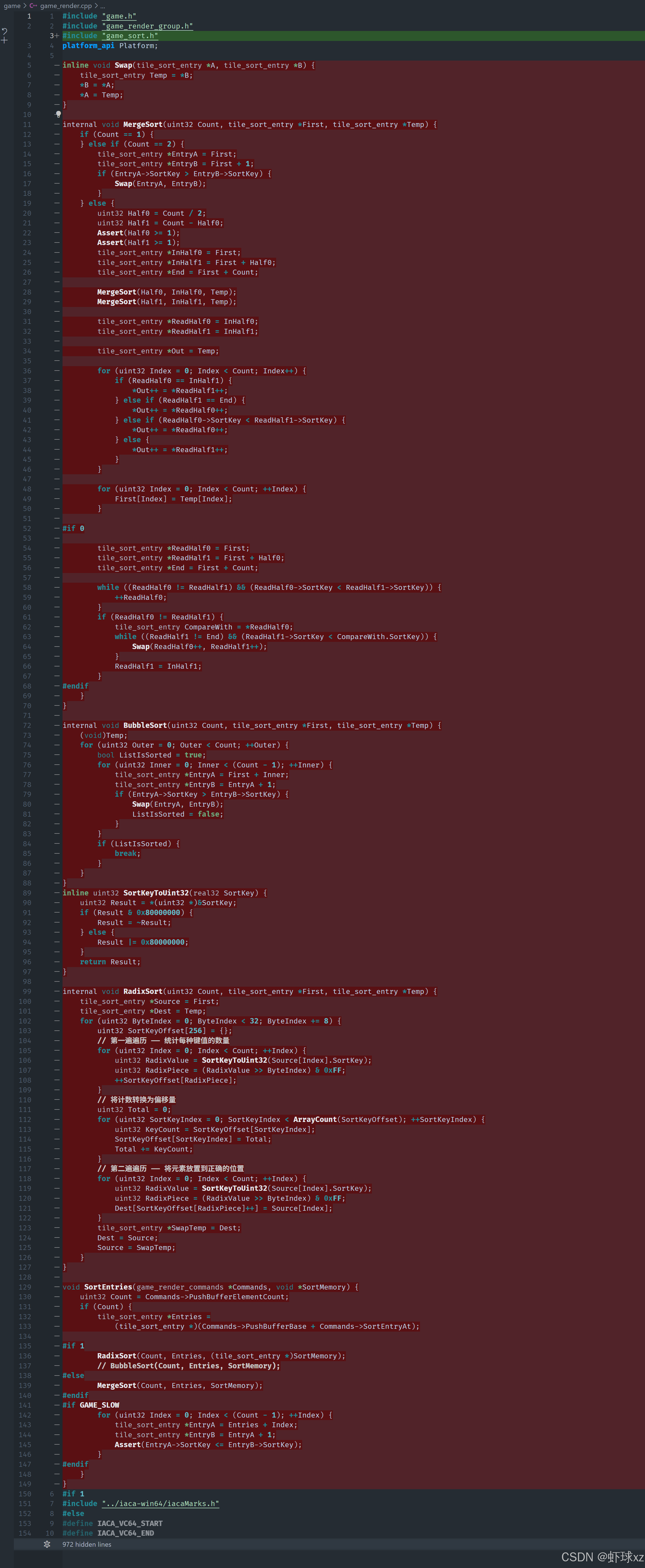
在这个新的 sort 文件中,我们将已有的排序结构和排序逻辑抽取了出来。原本代码中用于排序的是一个叫做 tile_sort_entry 的结构,我们对其进行了泛化处理,将其命名为 sort_entry,以便它在通用场景中也适用。原本的 push_buffer_offset 字段也被重命名为 index,以更准确地描述其用途。这些改动没有改变排序逻辑本身,只是为了使其更通用、复用性更强。
接着,将这段排序代码放到了更合适的文件中,比如 game_sort.cpp,并在需要使用它的地方进行了包含。然后开始逐一清理其他模块中对旧结构的引用,把原本使用 tile_sort_entry 的地方改成使用新的 sort_entry,并将字段名同步更新为 index。
在 OpenGL 相关模块和渲染相关的模块中,也进行了相应的更新,因为这些模块需要进行排序操作。为了使这些模块可以使用新的排序功能,还需要在对应的代码文件中包含 game_sort.cpp。
最后还确认了用于排序的数据结构中包含排序所需的信息,比如排序的关键字(sort_key)和索引(index),确保排序逻辑可以在各种上下文中顺利复用。通过这一系列的改造,我们实现了一个更灵活、可复用的排序模块,方便未来在不同场景下调用。
新建game_sort.h game_sort.cpp
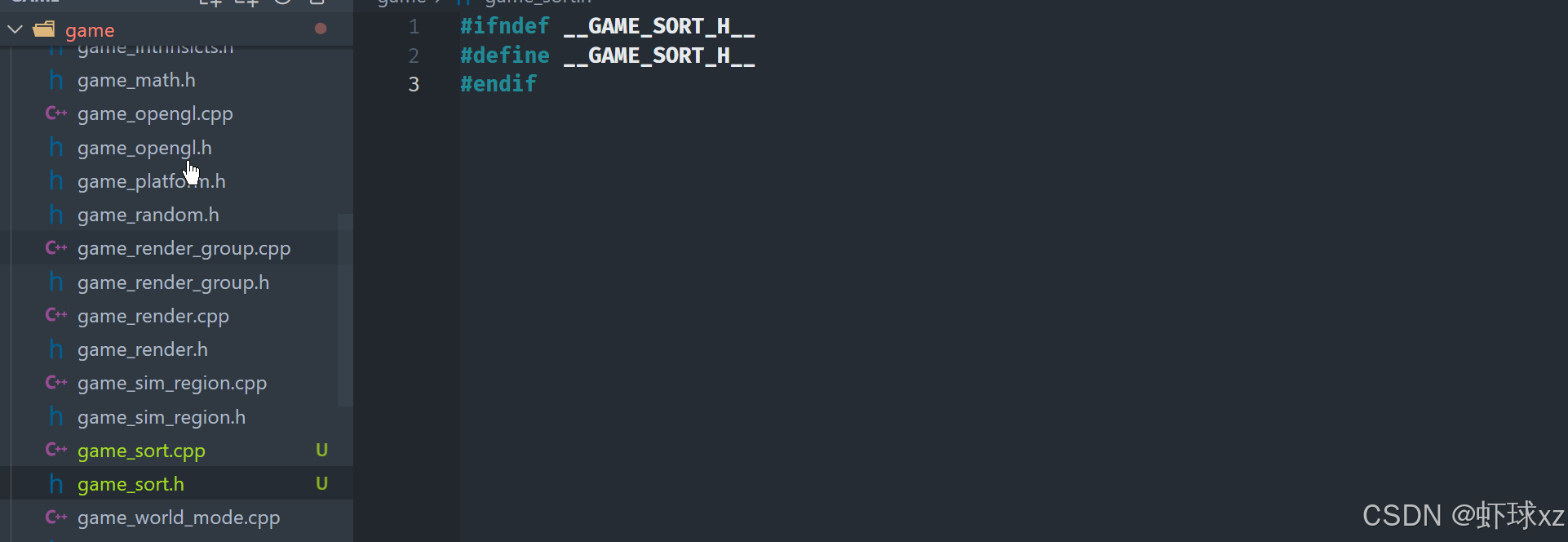

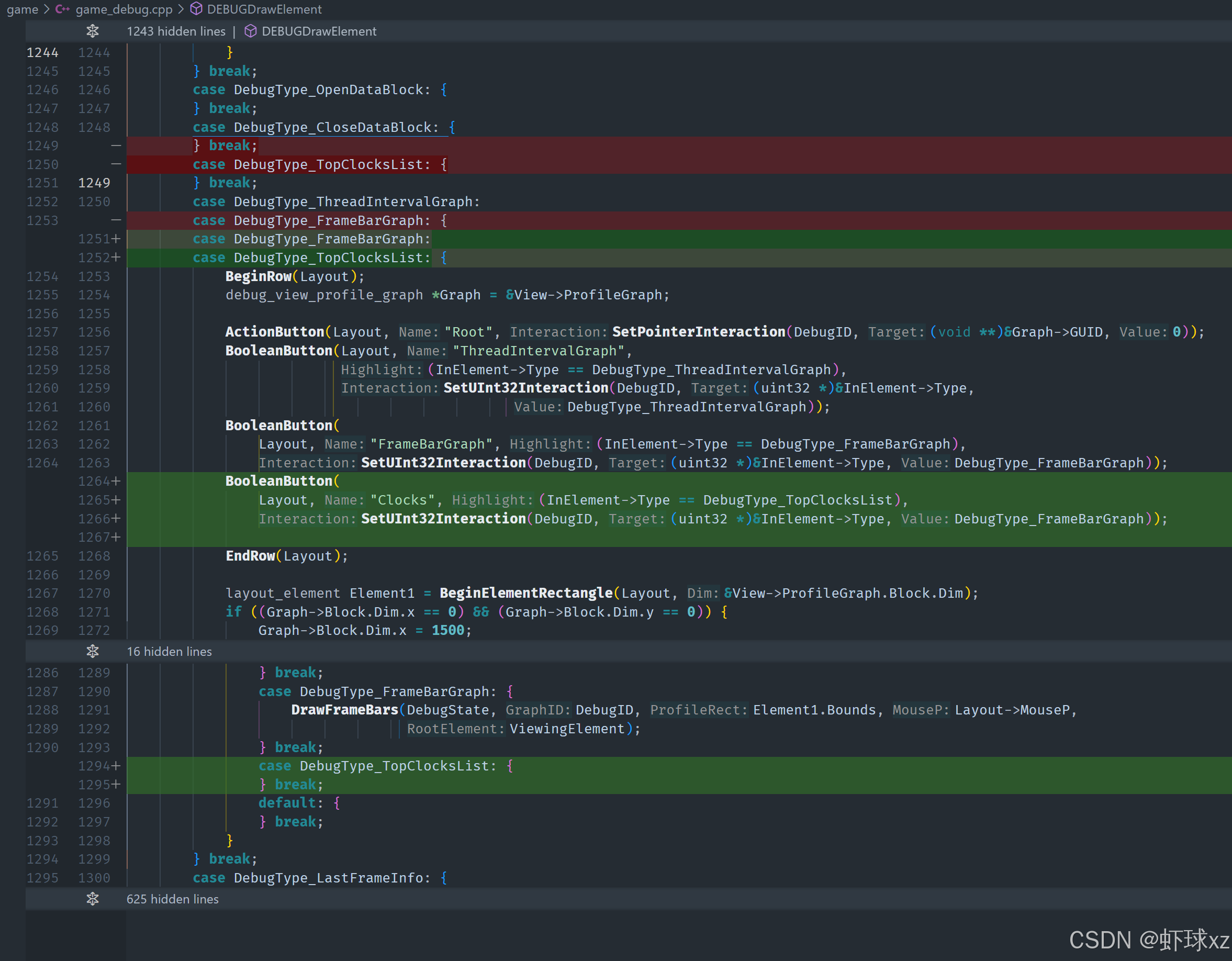
game_debug_interface.h:添加 DebugType_TopClocksList
我们接下来要定义一个新的视图模块,用于展示"Top Clocks List"(耗时函数列表)的视图类型。我们为此新建了一个对应的视图类型,并将其命名为 TopClocksList。这样我们就可以在多个不同的性能分析视图之间进行切换,包括原有的图形视图和新的列表视图。
为了保证这些视图之间的交互一致性,我们将新建的 TopClocksList 类型也加入到现有的视图切换系统中。这个系统支持不同视图的自由切换,同时在切换过程中保留界面布局、尺寸等相关设定,保证用户体验一致。
接下来,为了支持绘制这个新的列表视图,我们添加了一个绘制函数 DrawTopClocksList。该函数接受的参数与之前的绘图函数一致,以便复用现有的绘图基础设施和上下文环境。
当前阶段我们完成了:
- 新视图类型
TopClocksList的定义; - 把它整合进现有的视图切换系统中;
- 创建了对应的绘制接口
DrawTopClocksList,确保它能在渲染流程中被调用; - 所有视图在渲染和行为逻辑上统一处理,包括尺寸控制、状态管理和用户交互等。
这样一来,我们的性能分析工具就具备了图形和列表两种方式展现分析结果的能力,让我们能更直观、清晰地观察和理解程序中函数的执行时间及其分布。下一步就是填充 DrawTopClocksList 函数的具体内容,实现排序后的函数耗时列表的绘制逻辑。

game_debug.cpp:引入 DrawTopClocksList 函数
我们开始为"Top Clocks List"功能添加函数原型。虽然暂时不会实现具体功能,但先确保接口存在,以便验证抽象出来的排序模块没有被破坏。重新运行程序后,我们可以看到一个新的"clocks"模式,虽然它现在还没有实际的渲染输出,但其他部分运行正常。
接下来要做的是尝试实际绘制这个"Top Clocks List"。实现思路是遍历所有与性能分析相关的调试元素,然后打印出每个元素在某一帧中所消耗的总时钟周期(clock cycles)。目前系统中并没有现成的结构保存这种已排序的数据,不过我们在过去曾经处理过类似问题,所以大致流程比较清晰。
在当前设计中,所有与性能相关的事件(如代码块的开始与结束)都被挂在一个 ProfileGroup 中,这是一个调试变量链表(DebugVariableGroup),我们可以通过迭代该链表的方式获取所有性能分析事件。每个事件节点中都包含了一组按帧记录的数据,这些数据描述了该事件在各帧中出现的次数和持续时间。
我们遍历 ProfileGroup 的方式是从其 Sentinel 节点开始,然后按顺序读取每一个 DebugVariableLink。每个链接都会指向一个 DebugElement,其中包含事件的详细信息。在遍历过程中,我们会做一次断言,确认这个链接不是指向一个子分组,因为 ProfileGroup 中理论上不应存在嵌套组结构。
获取事件的过程是从 DebugElement->Frames[ViewingFrameOrdinal] 中取出对应帧的数据。这些数据是一个链表,记录了所有相同类型的事件发生的时间段。我们遍历这个事件链表,并将其中每个事件的 Duration 累加,从而得到该调试元素在该帧的总耗时(clock 总数)。
值得注意的是,这种统计方式并不会计算函数的"子函数耗时",即它调用的其他函数所花费的时间。当前阶段我们暂不考虑这部分开销,但后续可能会加入对子调用的分析支持。
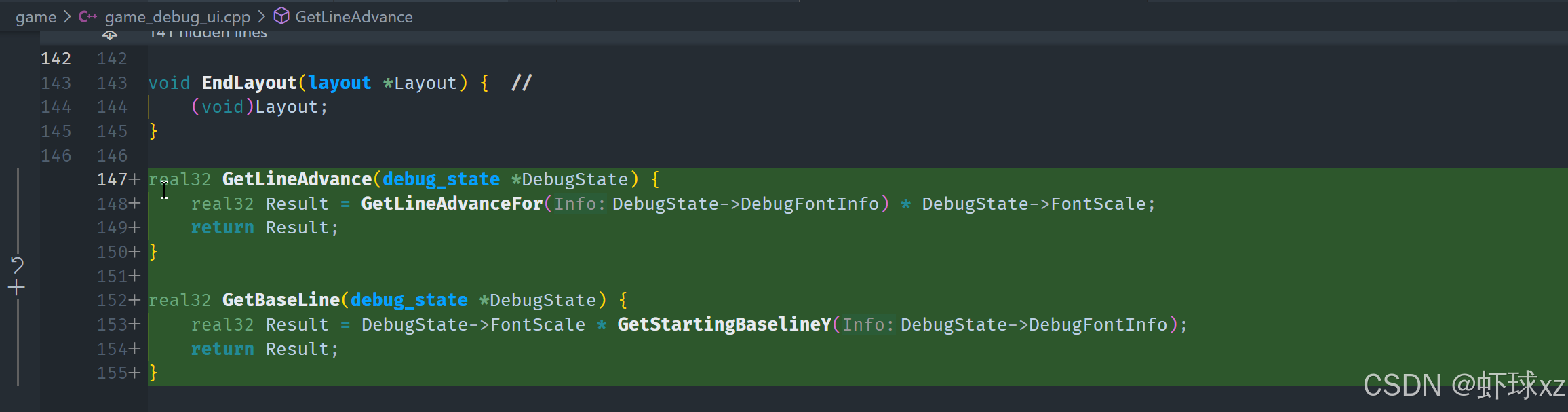
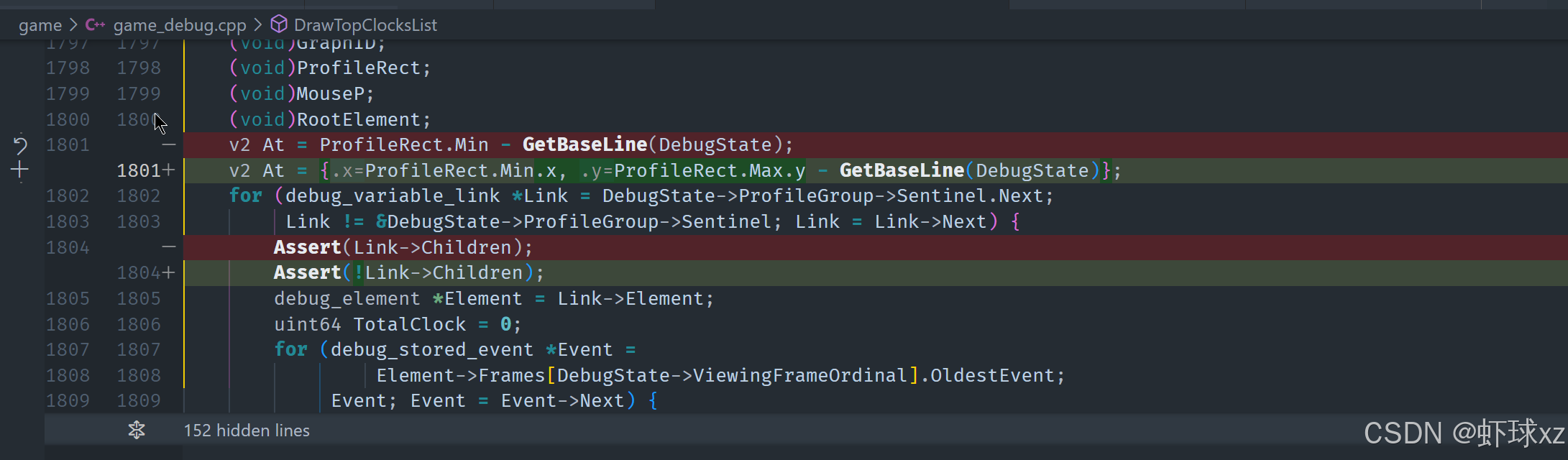
完成总耗时的统计后,我们会把这些信息以文本形式输出到屏幕上。文本渲染的起始位置由 ProfileRect 的最小 corner 决定,并通过每次调用 DrawTextOp 后向下偏移来模拟一行一行地打印。为实现良好的对齐与排版,我们还需要使用一些工具函数,如 GetLineAdvance 和可能需要的 GetBaseline(判断文本基线的函数)。
总结当前进展:
- 定义了 "Top Clocks List" 模式及其绘制接口;
- 验证排序模块接口未被破坏;
- 理清了如何通过
ProfileGroup获取各调试事件及其耗时信息; - 实现了初步的打印逻辑:计算每个事件在当前帧的时钟总耗时,并将其渲染为文本;
- 准备进一步完善文本渲染布局,如基线对齐与行间距调整。
下一步将会是整理输出格式、增加排序支持,以及后续可能的子调用时间分析。是否需要继续总结下一部分?

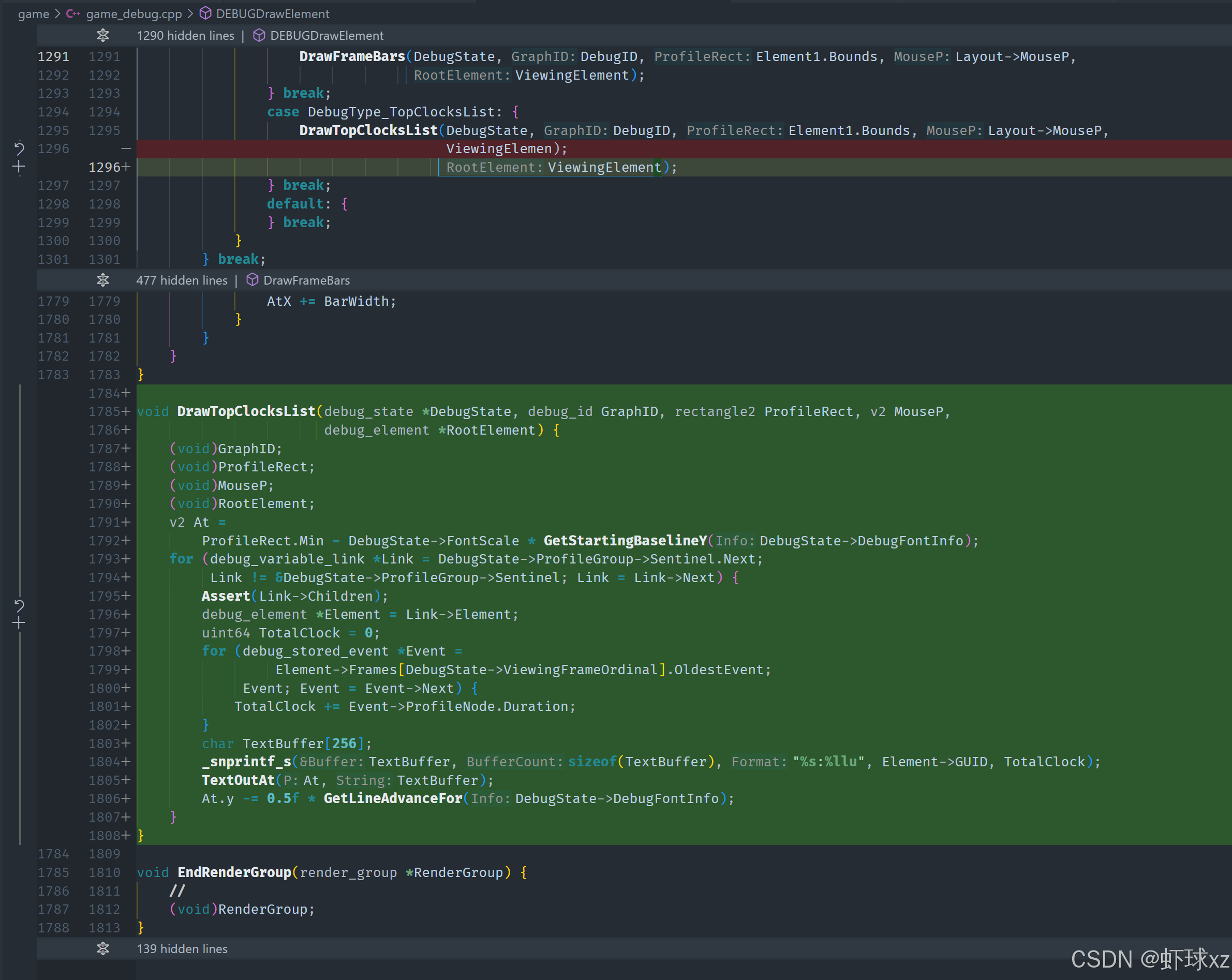
game_debug_ui.cpp:引入 GetBaseline
我们现在需要为"基线"提供类似"行高"的支持,理想的做法是将这一过程统一封装。这样可以确保所有计算都自动包含了缩放比例(scale)等因素,避免在不同地方重复书写,降低人为遗漏的风险。如果未来需要对这些细节进行调整,也能集中管理。
于是我们准备实现一个 GetBaseline 的函数,并与 GetLineAdvance 一样,作为文本排版计算的一部分,自动处理相关缩放等操作。同时,我们也要确保返回值是一个向量类型(vector),以便于后续与坐标处理保持一致。
接着回到"Top Clocks List"的渲染部分,当前运行后并没有任何输出。初步排查后,发现遍历 ProfileGroup 的时候,里面竟然没有任何成员。最初以为已经正确地添加了调试元素,但现在看来其实并没有。这显然是导致"Top Clocks List"渲染失败的根本原因。
我们再次回顾代码逻辑,发现之前对是否将调试元素添加进 ProfileGroup 的判断并不准确,可能只是表面上看似添加了,实际上并未生效。可能是我们没有看得足够仔细,遗漏了某些具体的添加逻辑。
接下来的工作将集中在:
- 统一并封装文本排版的基线计算逻辑;
- 查找并修复调试元素未正确加入
ProfileGroup的问题; - 一旦能成功遍历调试事件列表,再次尝试绘制"Top Clocks List"的内容。
这一轮工作主要暴露出两个问题:渲染位置参数未统一封装导致潜在误差,以及核心数据结构未正确初始化,导致功能表面正常但内部数据为空。下一步将针对这两个关键点进行修复和调整。

奇怪点击断点怎么没进来



断点进不来
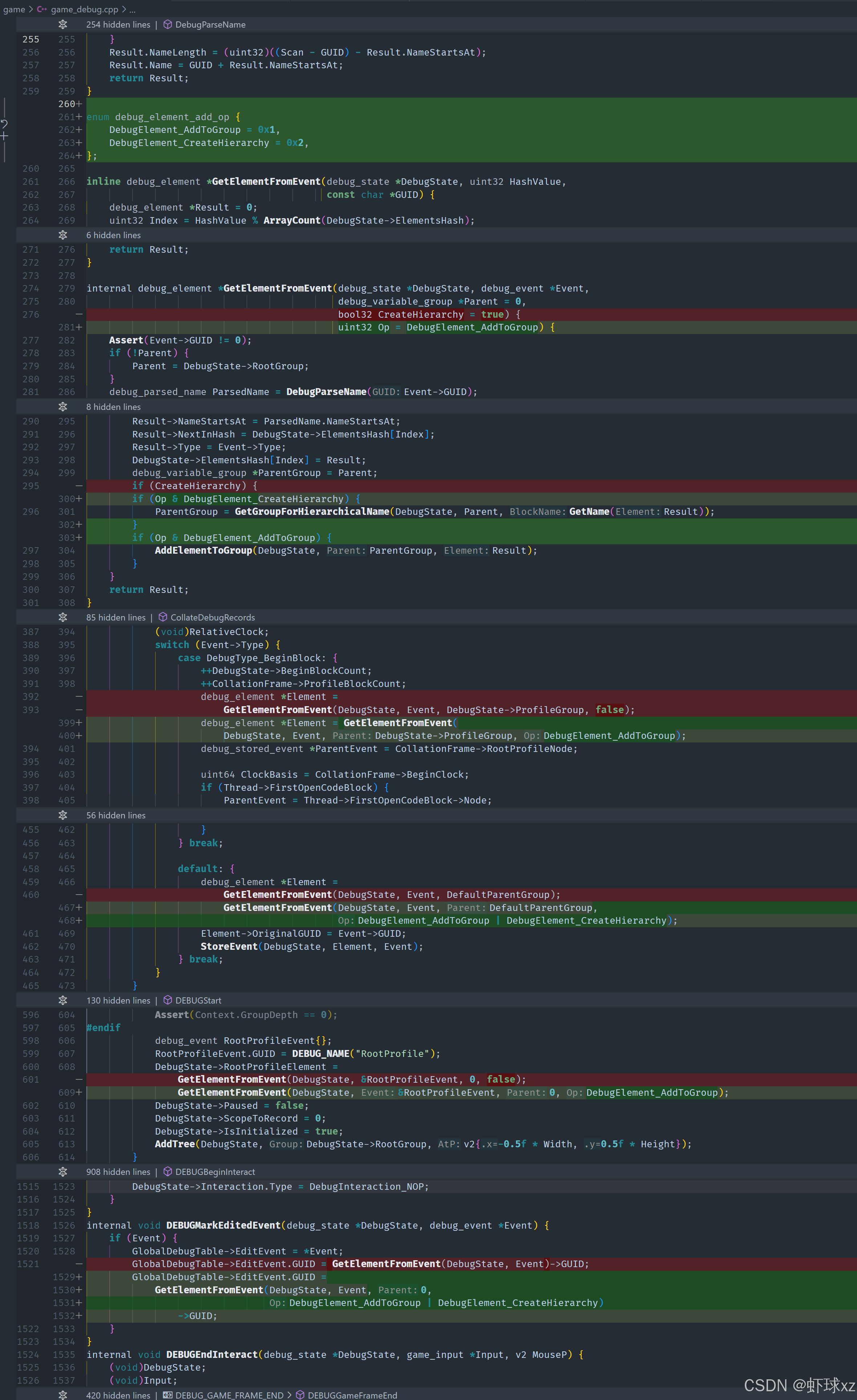
game_debug.h:引入 debug_element_add_op,以便更细致地控制元素的分析方式
当前的问题是调试元素没有被添加到预期的分组中。原因是我们当初假设不需要将这些元素添加进组中,但现在发现实际上确实有这个需求。因此必须调整逻辑来确保这些元素正确地加入调试组。
我们重新审视 GetElementFromEvent 这个函数,发现它的职责过多,功能被严重"重载",既涉及是否添加到组中,又涉及是否创建层级结构。为了解决这个问题并让行为更加可控,我们将这两个操作分离成两个独立的布尔参数:
AddToGroup:是否将该调试元素加入调试变量组;CreateHierarchy:是否为该调试元素构建层级结构。
这样可以精确控制每次调用时的行为。虽然这种写法不够优雅,但考虑到这是调试代码,稳定性优先,结构稍显粗糙也可以接受。
之后我们在原有代码基础上进行如下修改:
-
更新
GetElementFromEvent接口,显式传入AddToGroup和CreateHierarchy两个参数。 -
修改所有调用这个函数的位置:
- 有些调用只需要加入组;
- 有些既要加入组又要创建层级;
- 还有些不需要做任何附加操作;
- 所有调用都必须明确传入这两个参数,不再允许使用默认行为,以避免混淆。
-
将这两个新参数定义在通用位置,以便于所有模块共享访问。
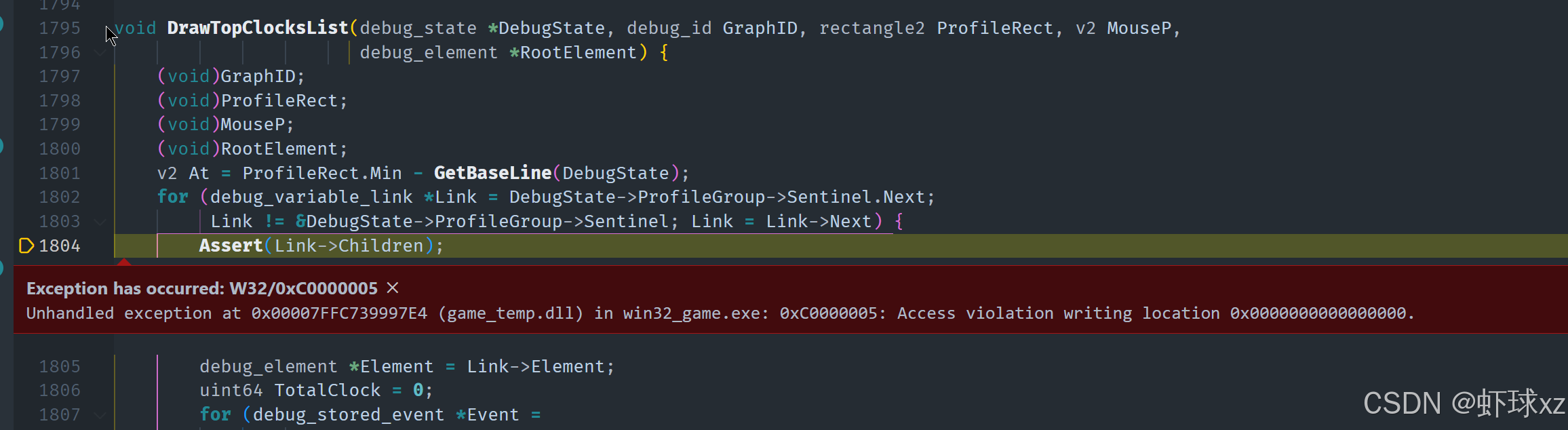
修正完成后,重新运行程序,验证元素是否成功加入分组。发现输出结果仍然为空,进一步调试后发现断言语句写反了,原意是"断言没有子元素",但实际代码写成了相反的意思,导致断言错误。我们修正了这个逻辑问题。
随后我们继续测试"Top Clocks List"的绘制效果,发现成功输出了对应的调试内容,但文本位置存在偏移问题。我们意识到:
- 当前文本起始坐标使用的是"最大 Y 值",也就是屏幕顶部;
- 然而文本是向下渲染的;
- 因此 Y 轴方向的递增导致排版顺序与人类阅读顺序相反。
为了解决这个问题,我们分别设置 X 和 Y 坐标起点,确保绘制时方向符合正常阅读逻辑。数学在这里又一次暴露出其细节的重要性,坐标系统中方向的一致性必须始终保持明确。
下一步,我们将继续完善绘制逻辑,使得整个调试界面信息展示更为清晰可控。

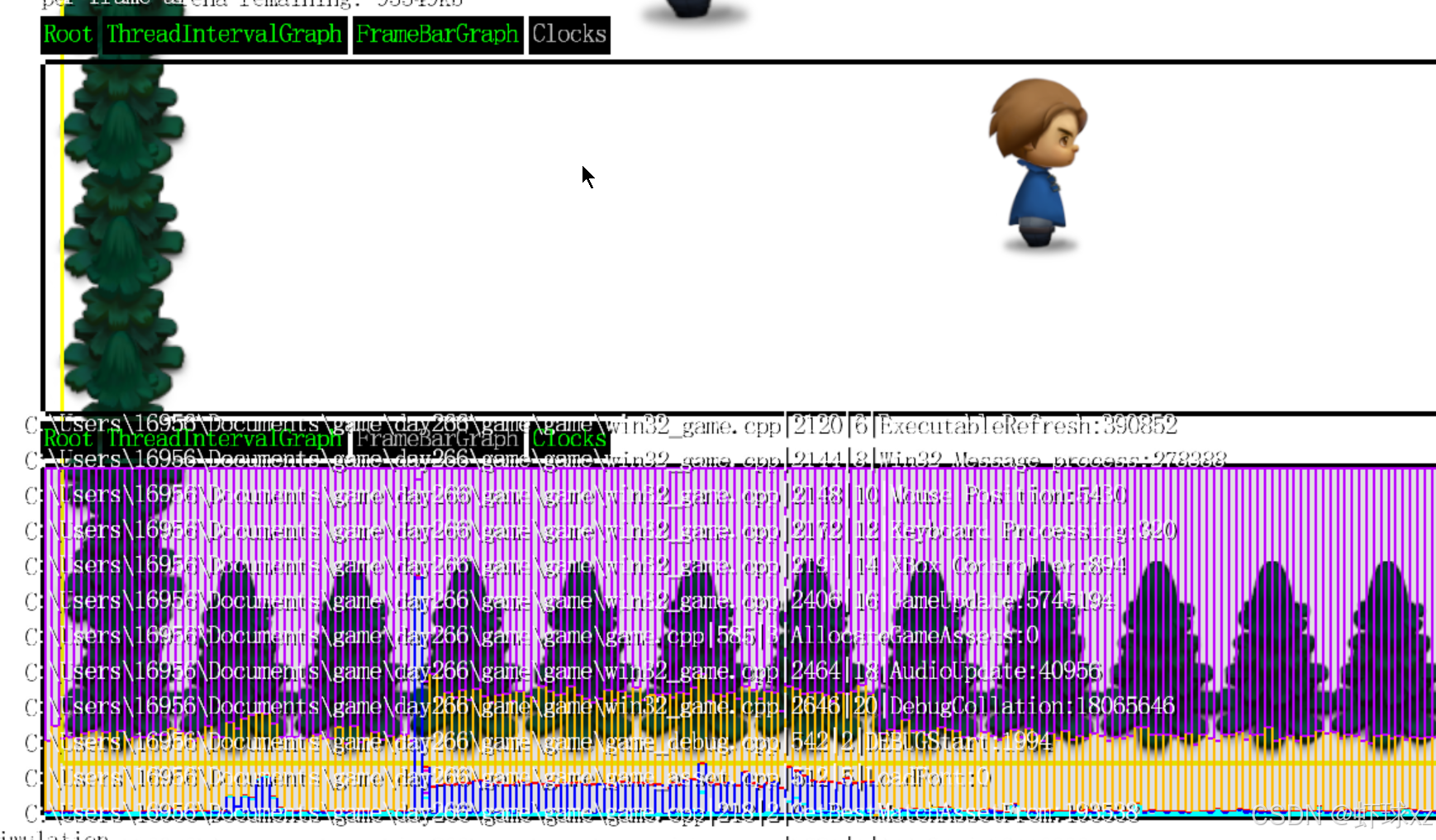
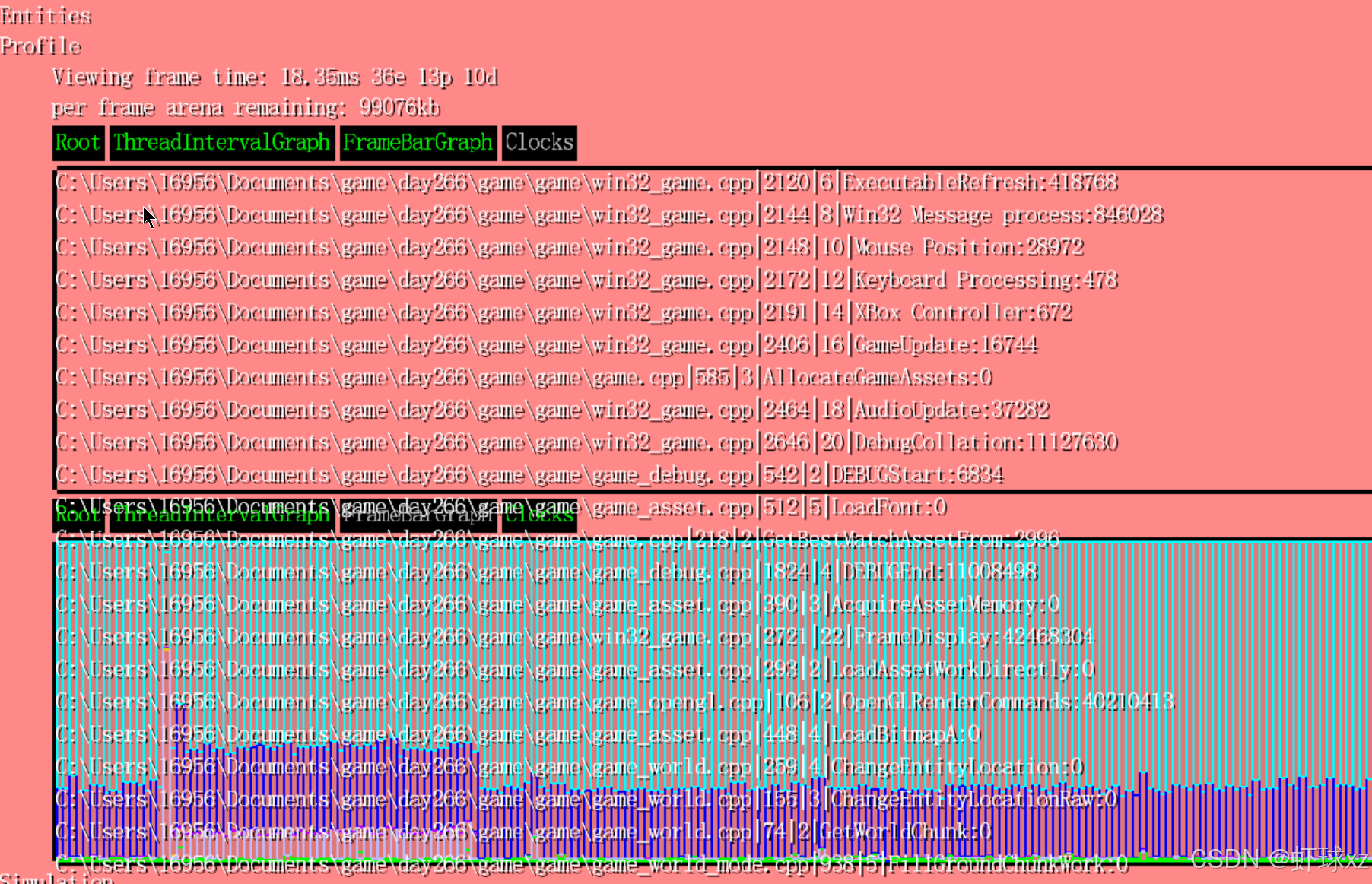
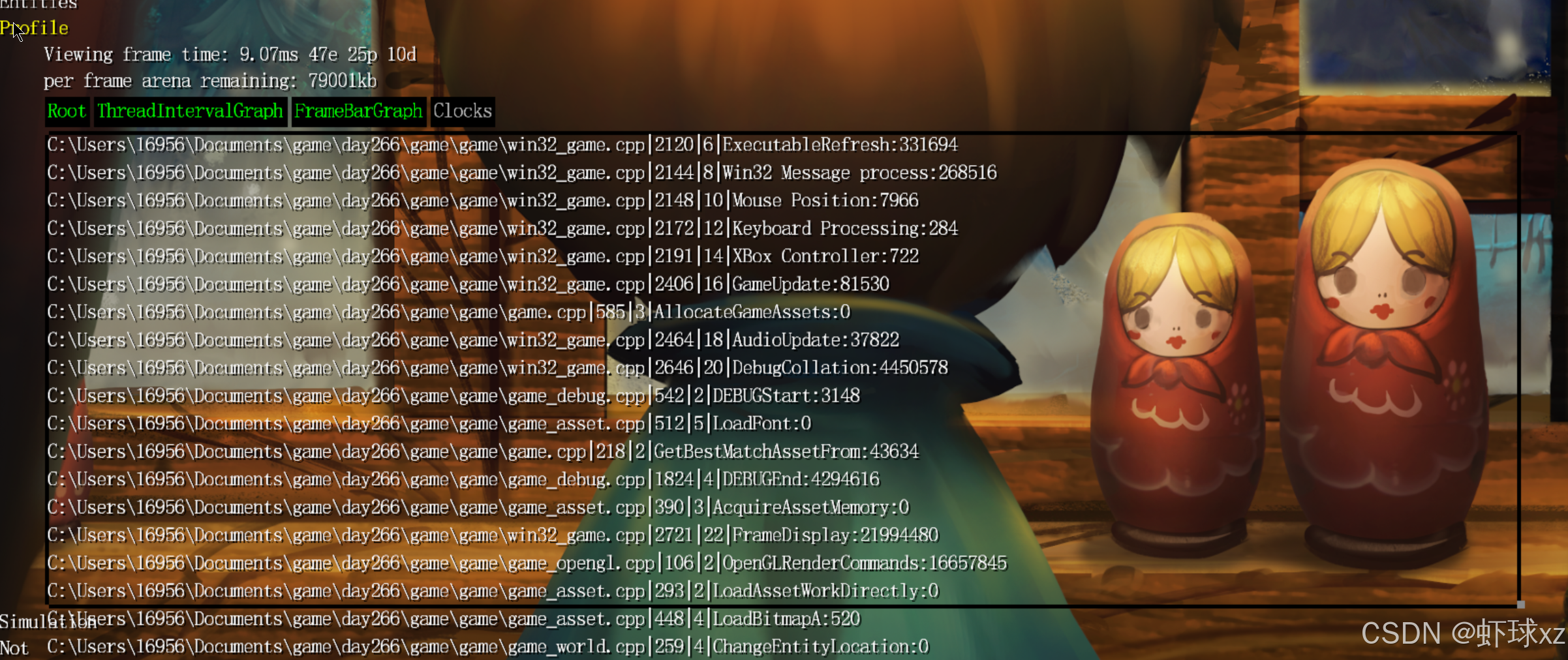
运行游戏并查看 DrawTopClocksList 的输出
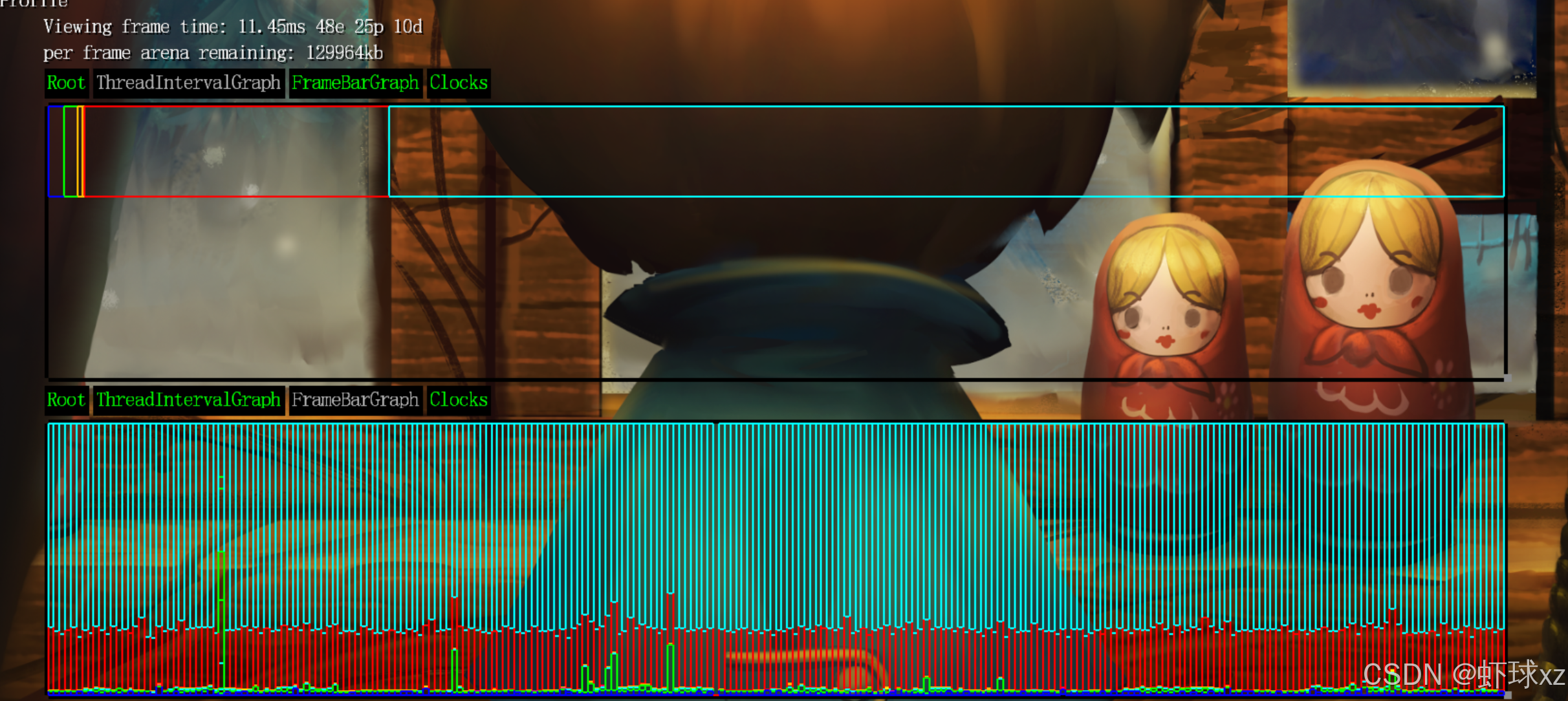
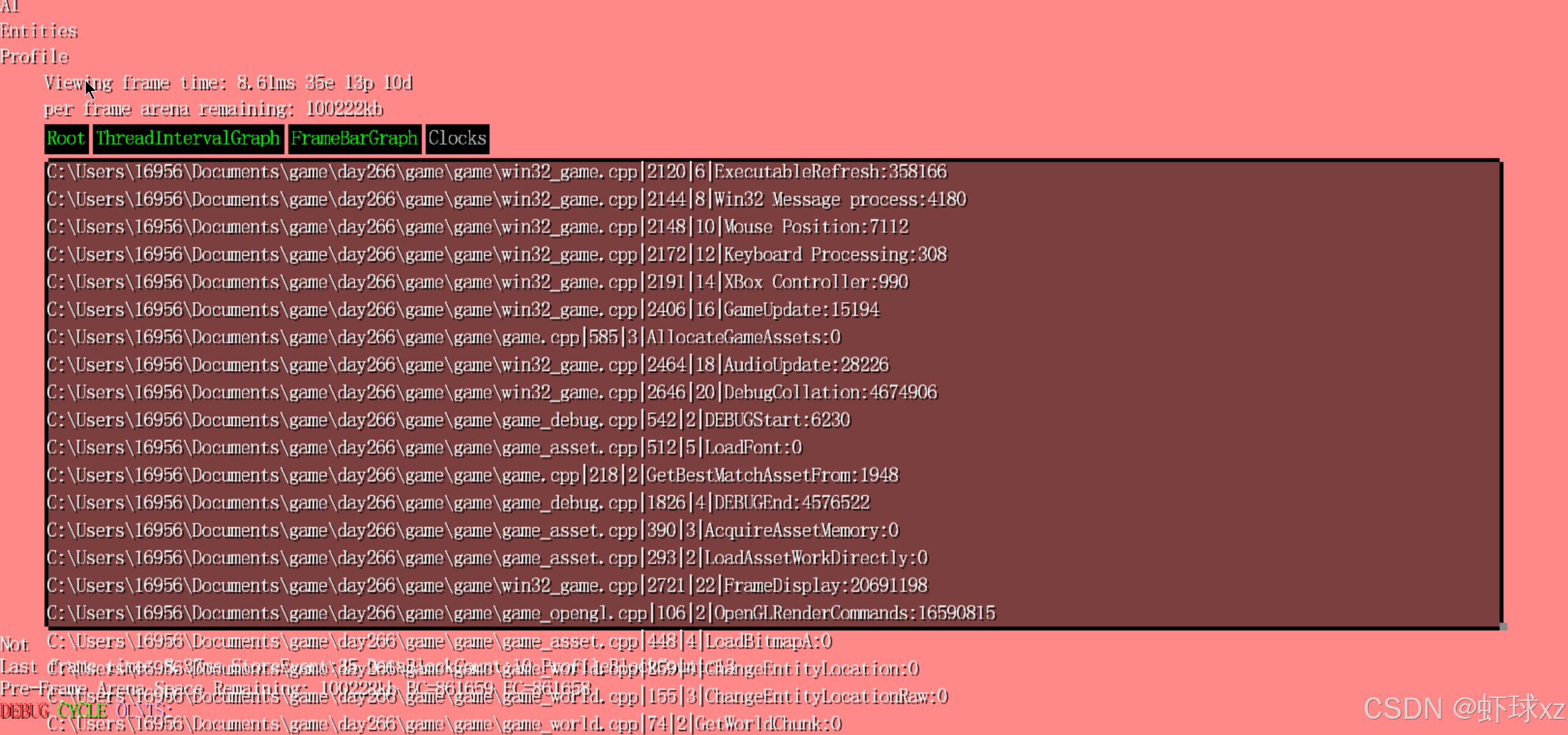
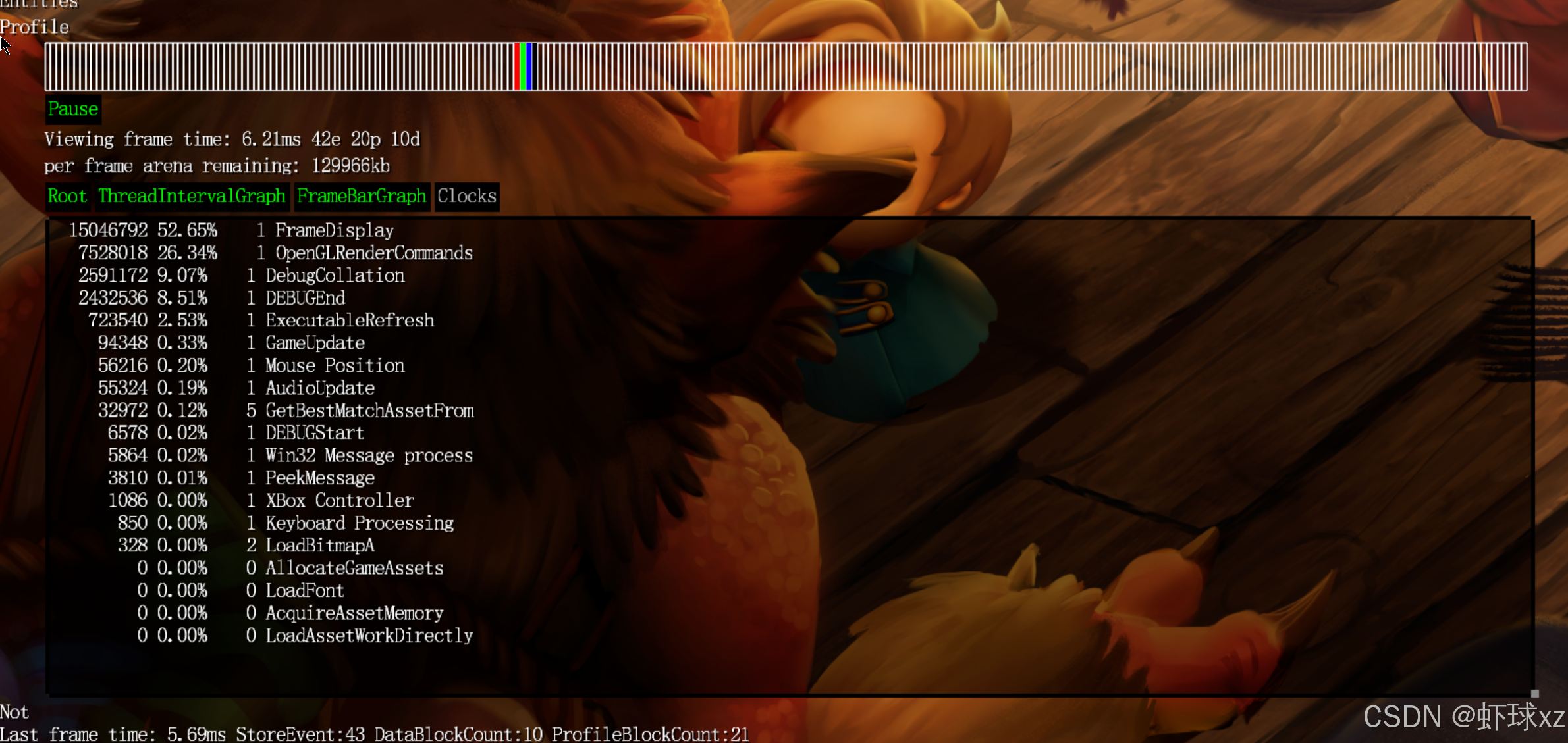
目前我们开始验证输出的调试信息是否真实可信。在界面中可以看到多个项目,例如输入处理、消息处理、鼠标位置、设置相关、游戏更新、竞争与渲染等。当切换到"游戏模式"后,这些显示的数据变得明显更大,表明各个模块在该模式下的处理耗时确实上升了。虽然没有进行严格的科学验证,但从观察结果来看,这些数值是合理的,输出内容具有一定可信度。
接下来引出了一个需要处理的问题:当前系统没有"列表区域"或"可滚动区域"的概念。因此,如果我们希望将这种输出做成可滚动的列表,例如显示完整的函数耗时记录并允许查看全部内容,我们无法直接实现,而是需要为该列表单独实现滚动机制、显示逻辑等。这显然不够通用。
目前的做法是将内容以硬编码的方式直接绘制到屏幕上,这种方式虽然短期可行,但缺乏扩展性和灵活性。如果将来需要多个不同的模块使用类似的结构展示调试数据,我们就必须重复实现这些绘制和交互逻辑。
因此,后续需要考虑一个更普适的机制 ------ 比如实现一个通用的"表格或列表输出系统",支持行列布局、滚动、选择等功能。这样不论是当前的"Top Clocks List",还是将来其他模块的调试输出,都能复用该系统,提高维护性和开发效率。
不过当前阶段暂时不考虑这一通用机制,我们优先完成现有调试列表的展示,使其内容更加丰富、实用,之后再统一考虑界面表现层的优化和抽象。需要我继续整理后续改进部分的思路吗?
game.cpp:默认启用 TopClocksList
当前的目标是优化调试界面的显示效果,特别是帧图(frame graph)相关的显示逻辑。首先做出的调整是:确保在默认情况下就能显示帧图,而不需要手动切换或激活,这样一启动调试界面就能立即看到帧图内容。
接着注意到一个界面显示上的问题:帧图背后的背景矩形(backdrop rectangle)似乎没有被正确绘制出来。虽然原本代码中确实有绘制背景矩形的逻辑,例如使用 push_rect 的调用,但实际运行时并没有显示出背景。这可能是因为绘制背景矩形的部分目前被嵌套在特定的上下文中,而其他调试区域或模块并未共享使用这一背景绘制逻辑。
为了解决这一问题,并提升界面一致性,计划将背景矩形的绘制逻辑抽离出来,放置在更高层次的位置。这样做的目的是让所有使用相似绘制逻辑的调试模块都能复用相同的背景绘制方式,不仅可以避免重复代码,还能保证整个调试界面在视觉风格上的统一性。
这种改动将使背景矩形的绘制变成一个通用行为,而不是局限于某一模块内部独有的处理方式。统一的背景层会在每个调试区域开始绘制时就自动应用,从而使调试界面的结构更加清晰、可维护性更高。
game_debug.cpp:让列表背景颜色变暗
当前的目标是在调试界面中优化"Top Clocks"列表的显示效果,使其更加清晰、实用和具可读性。
首先,对调试界面布局元素(layout elements)进行了改动。将背景色设为更深的颜色,以提升文本与背景之间的对比度,便于观察和分析信息。具体做法是,在生成调试元素所有者(owner)之后,立即填充一个较暗的矩形背景,统一所有元素区域的视觉效果,使内容更突出、界面更整洁。
接下来,明确了几项进一步的优化目标:
-
排序处理:
希望将这些调试元素按照所消耗的时钟周期数(clocks)进行排序,这样可以更直观地识别出耗时最多的部分,帮助快速定位性能瓶颈。
-
增加百分比显示:
除了显示原始时钟数值之外,也计划增加每个元素相对于总耗时的百分比,这样有助于理解各部分在整体性能中的占比。
-
精简显示信息:
当前调试元素显示的信息过于冗杂,很多细节并非分析性能时所必需。因此考虑将只保留调试元素的名称,移除其他无关字段,以提升信息密度和阅读效率。
-
复用已解析信息:
因为这些调试元素本身已经包含了解析过的结构信息,例如名称所在的位置等,所以不需要重新处理,只需直接使用
DebugElement中已有的字段,便可提取名称并显示。
最后,明确接下来的绘制逻辑将集中在 CookTopClocksList 的绘制环节中。将在其中实现排序、百分比计算、简化文本和背景绘制等功能,形成一个高可读性、简洁直观的高性能调用列表,帮助快速定位性能热点。
game_debug.cpp:只打印元素名称
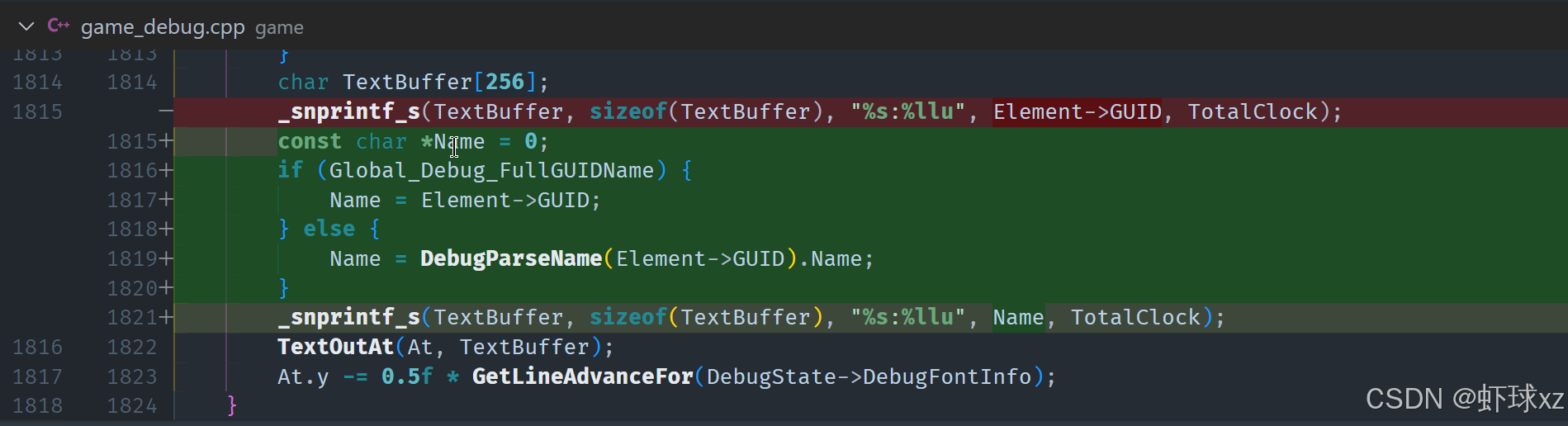
目前在处理调试界面的过程中,对"Top Clocks"信息的呈现方式进行进一步优化,使其更具可读性和对齐性,便于分析性能。
首先,在使用网格布局显示时,决定将每一行的起始位置偏移到调试元素名称的起始位置 name_starts_at,这样每一项都在视觉上对齐,更加整齐清晰,有利于快速浏览和理解各个性能计数项。
其次,为了提升数据对齐效果,当前不再直接使用默认的字符串输出方式。原因在于默认的打印方式无法很好地对齐数字,而调试时数字对齐是提升可读性的关键。因此,计划暂时采取一种"临时方案"来模拟对齐效果,比如在打印字符串前填充空格或使用固定宽度字符串等方法。虽然这种做法较为简单粗暴,但可以在短期内显著改善输出格式。
后续将考虑开发一个更完善的文本渲染系统,用于调试界面,尤其是针对表格类数据,使其具有良好的格式控制能力,例如对齐数字、小数点、列宽等,这样就可以在不依赖临时手段的情况下生成整洁的调试输出。
最后,通过以上调整,能够清楚看到各个模块在执行过程中的周期计数情况,从而更直观地识别出占用资源最多的部分。整体改进聚焦于提高信息密度、可视清晰度以及调试效率。
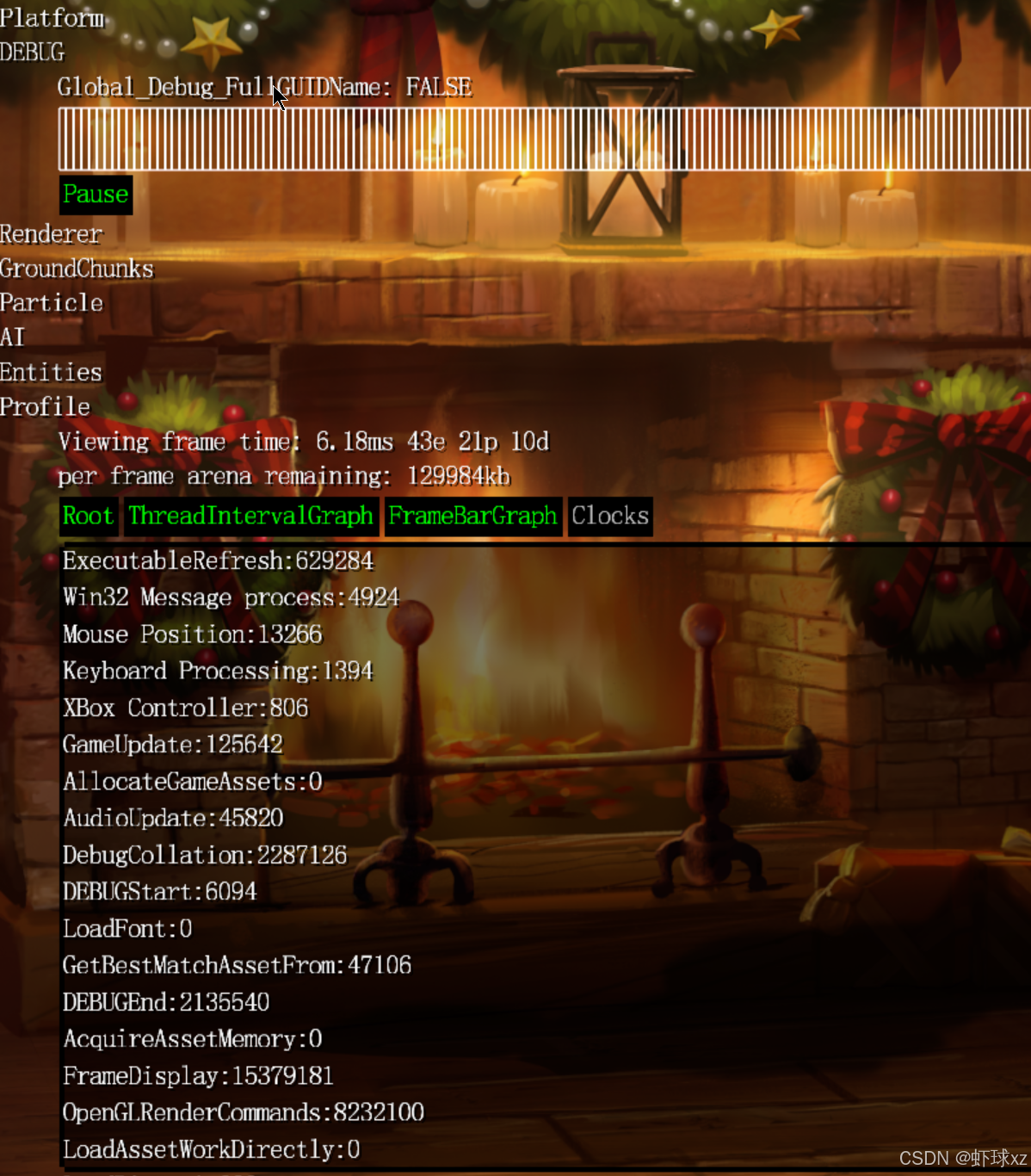
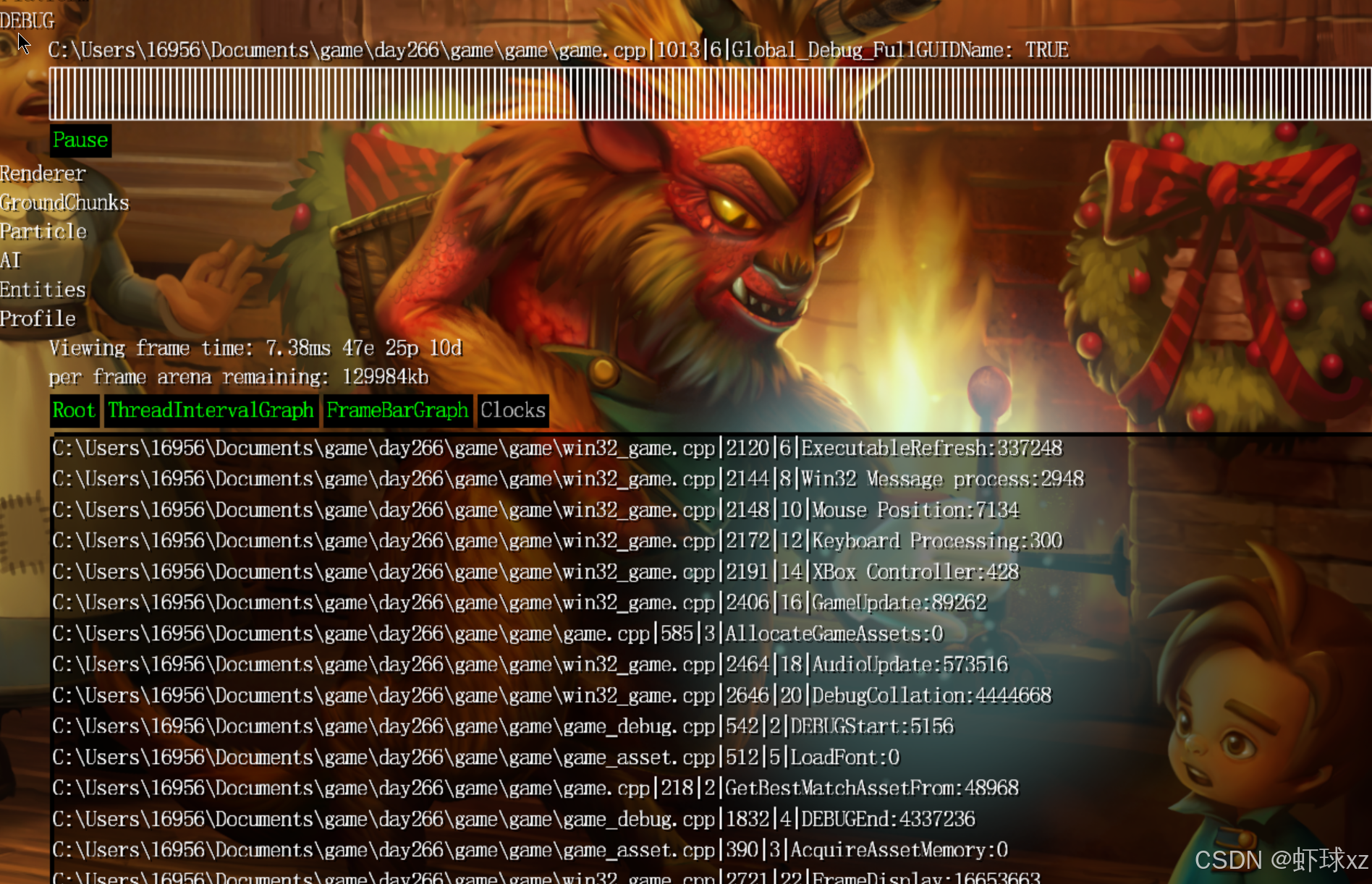
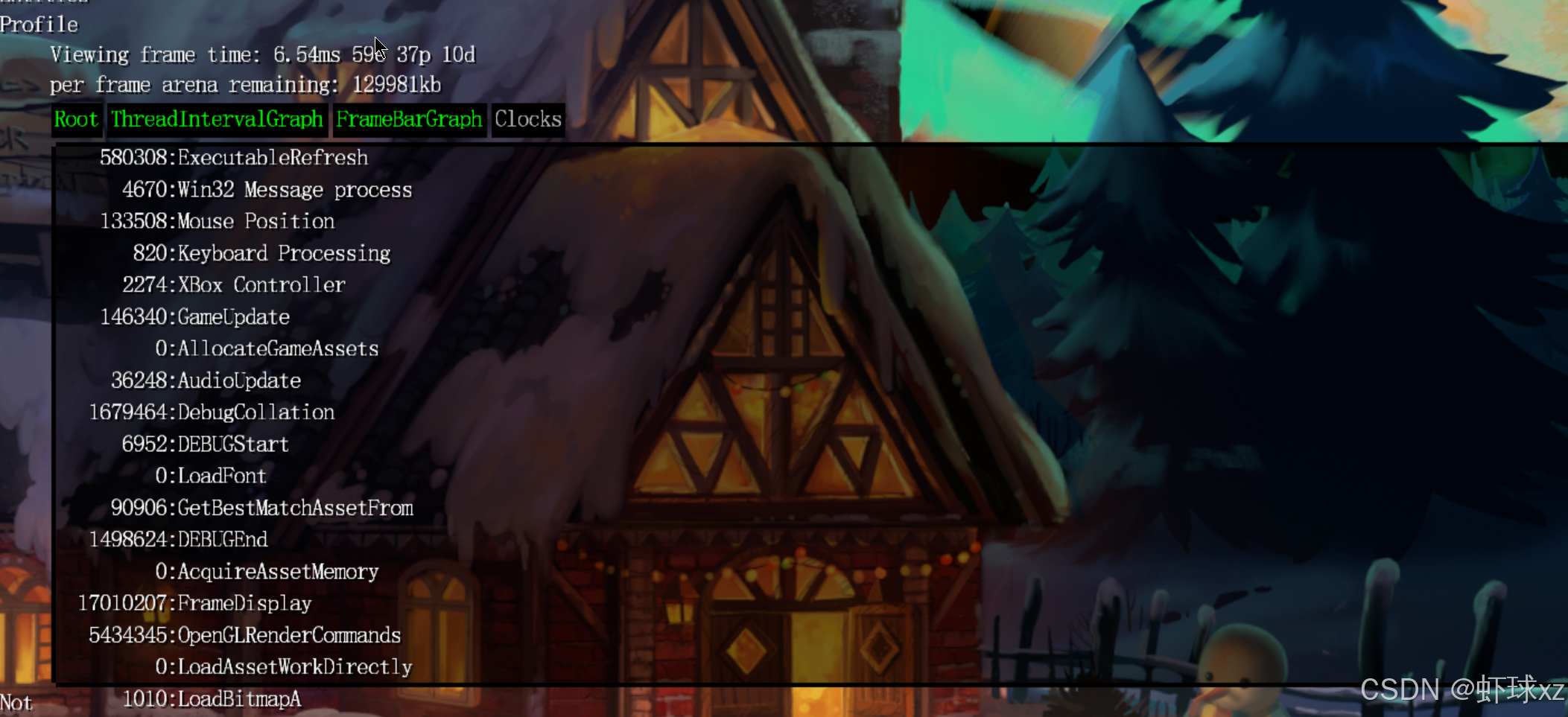
注意到当移动鼠标时,Win32 消息处理时间大幅增加
目前观察到一个有趣的现象:当移动鼠标或进行其他交互时,Windows 消息处理部分(Windows Message Processing)所消耗的时间会大幅上升,甚至达到原来的十倍左右。虽然绝对数值上不是特别大,但相较于静止状态下,这种增长仍然是非常明显的。这说明在用户交互时,系统在处理消息上的开销是显著增加的。不过目前还无法确定这些额外的处理时间是由系统本身消耗的,还是应用程序在处理消息时产生的额外开销。
虽然这部分不是最初的开发目标,但这一现象已经引起了关注,显示出调试工具的即时反馈能力对性能观察的价值。当前这些数据显示已经开始提供实际有用的信息。
接下来考虑对调试信息中添加"百分比"显示,以便更清楚地看到每个模块所占的总时间比例。为了实现这一目标,计划回顾和检查现有的调试统计数据(debug statistics),看看是否已有相关的数据结构或逻辑可以复用,从而避免重复造轮子。
此外,在查看过程中还发现有一部分代码似乎已经不再被使用,因此决定将其删除,简化逻辑,保持代码整洁。
当前的重点工作包括:
- 显示每个性能节点占用的百分比;
- 检查是否已有调试统计逻辑可复用;
- 清理冗余代码,避免维护开销;
- 持续关注调试数据显示是否准确,是否揭示潜在的性能瓶颈。
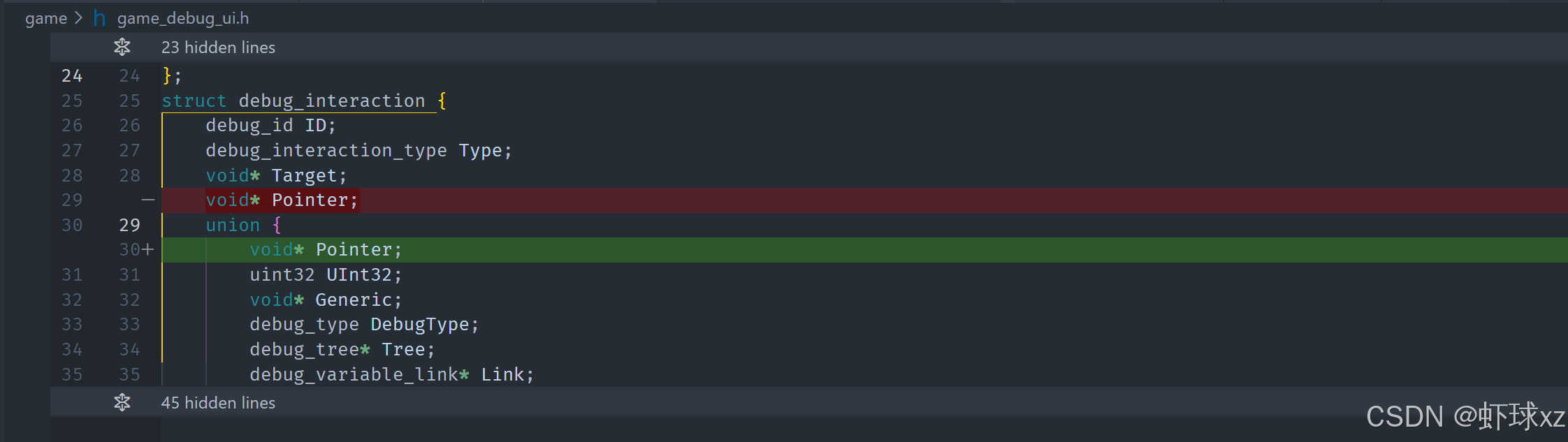
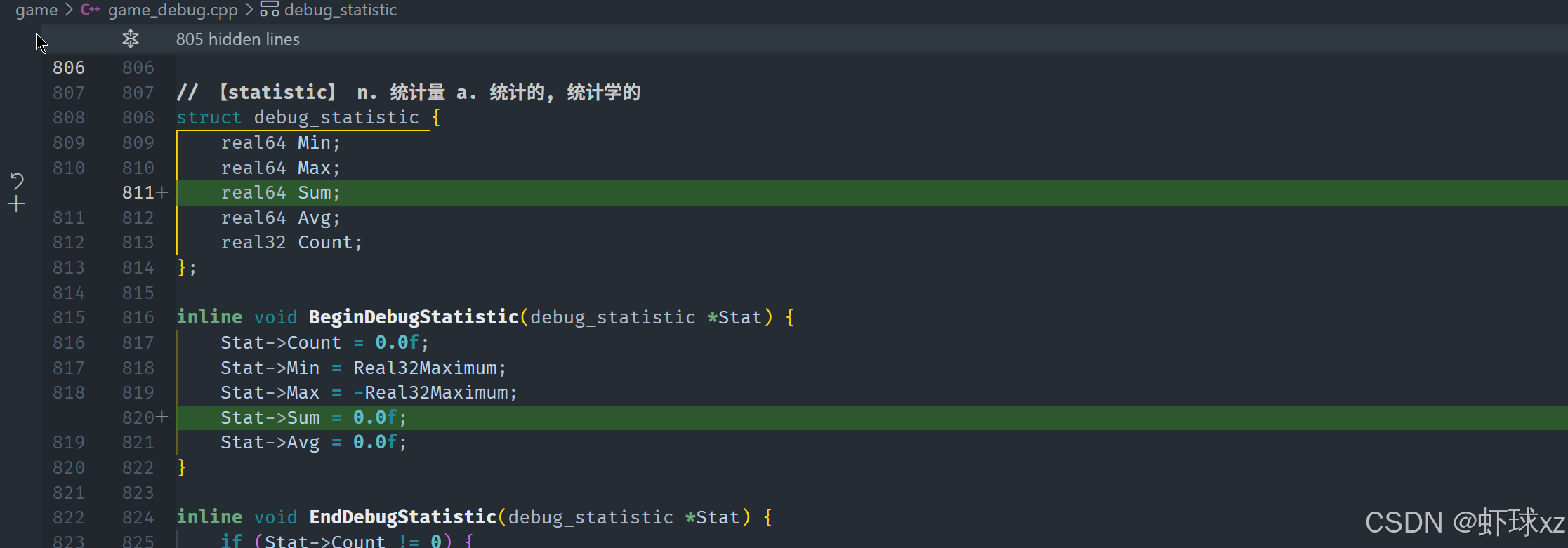
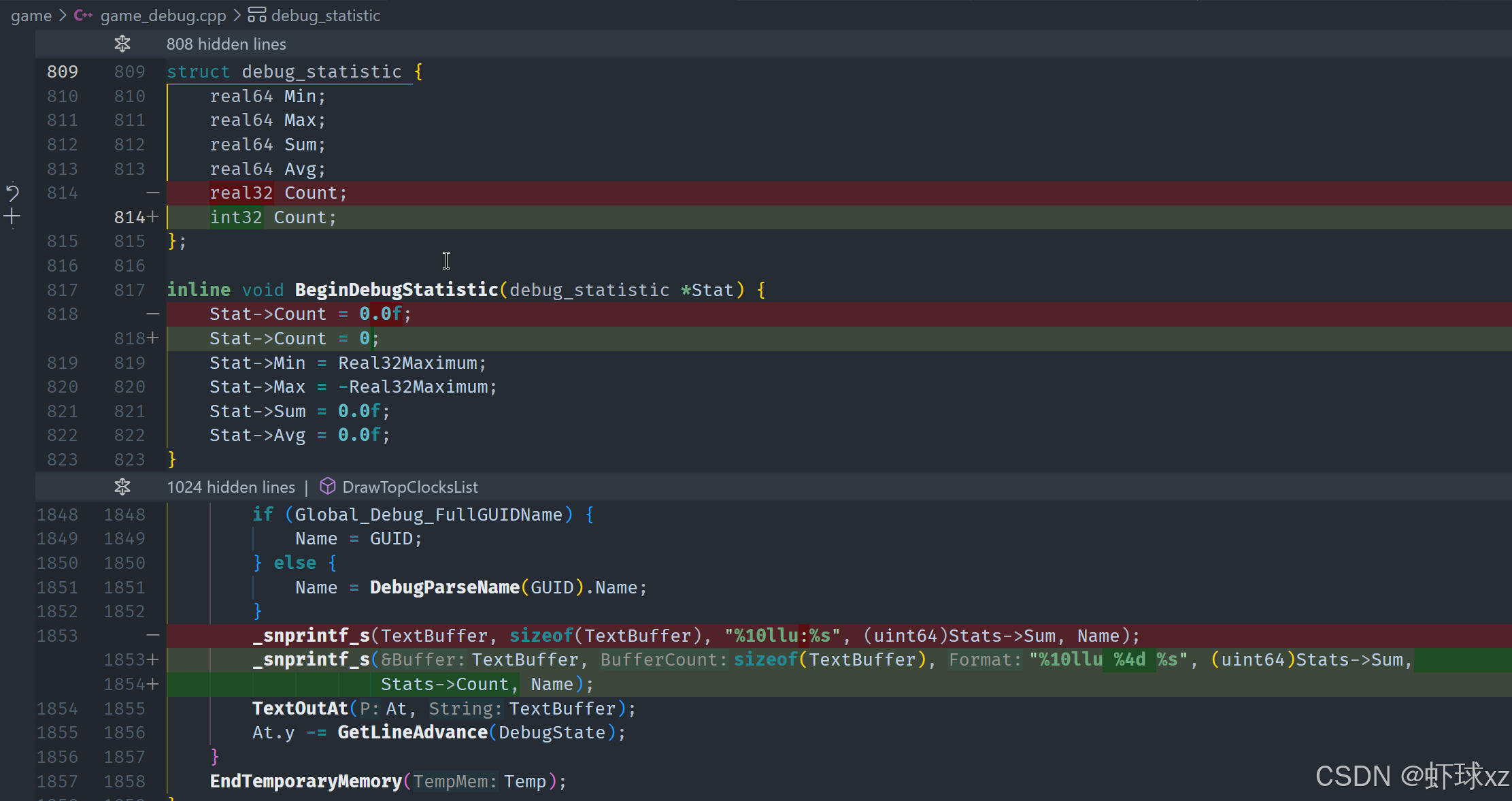
game_debug.h:为 debug_statistic 添加 Sum 字段
当前正在评估现有的 debug statistic 统计系统是否足够支持进一步的调试可视化和分析需求。虽然目前的系统支持记录最大值、平均值、样本数量等数据,但实际上这些数据的用途仍较为有限,并不能很好地服务于需要展示统计分布或做总量对比的场景。
考虑到现有设计的不足,计划对其扩展,使其更实用。具体来说,希望新增以下功能和统计数据:
- 最小值(min)
- 最大值(max)
- 平均值(average)
- 样本总数(count)
- 数值总和(sum),便于后续计算百分比
- 对比整体的百分比或占比
有了这些数据之后,可以在界面中对每个性能节点的表现做更清晰的比较,比如:哪个节点在某一帧中占用的时间最多,占据了总运行时间的百分之几等。
为了实现这一点,在遍历 debug 变量组时,原本的想法是希望能直接获取组中子项数量以优化创建过程。但很快意识到没有必要提前维护这类数量信息,因为组中变量项的数量相对较少,完全可以在遍历过程中动态获取,既更灵活也不会污染结构本身。
因此决定:
- 不在结构中添加专门的计数字段;
- 在需要排序和统计时直接遍历链表;
- 优化
debug statistic数据结构以支持更丰富的数据分析; - 为后续可视化(比如条形图、百分比显示等)打下基础。
目前重点在于增强统计能力而非渲染逻辑的复杂度,后续再统一优化输出格式。
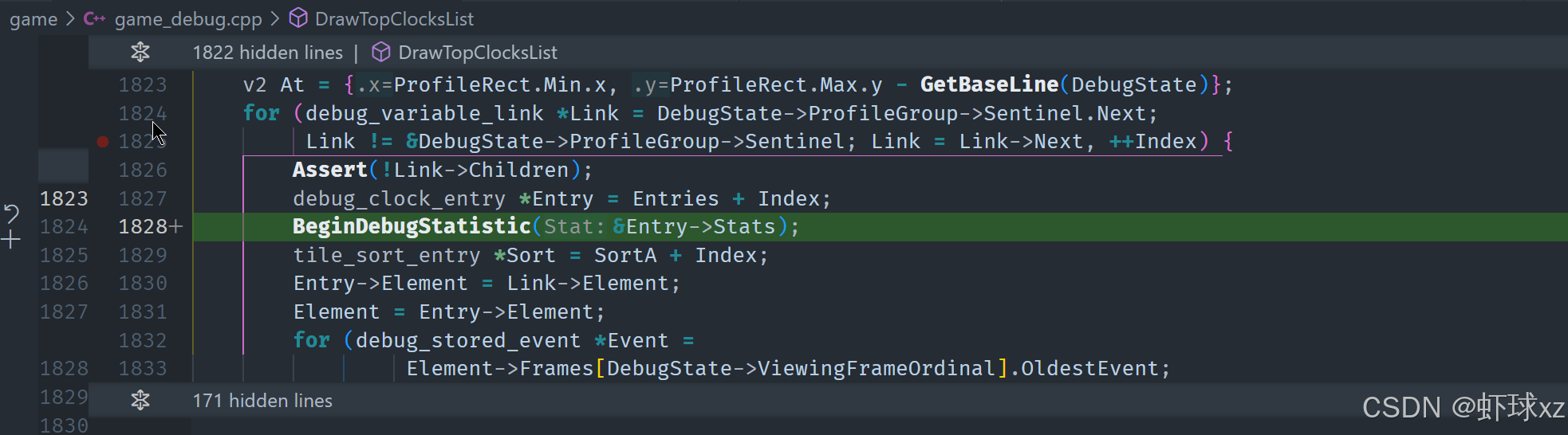
game_debug.cpp:让 DrawTopClocksList 支持显示百分比
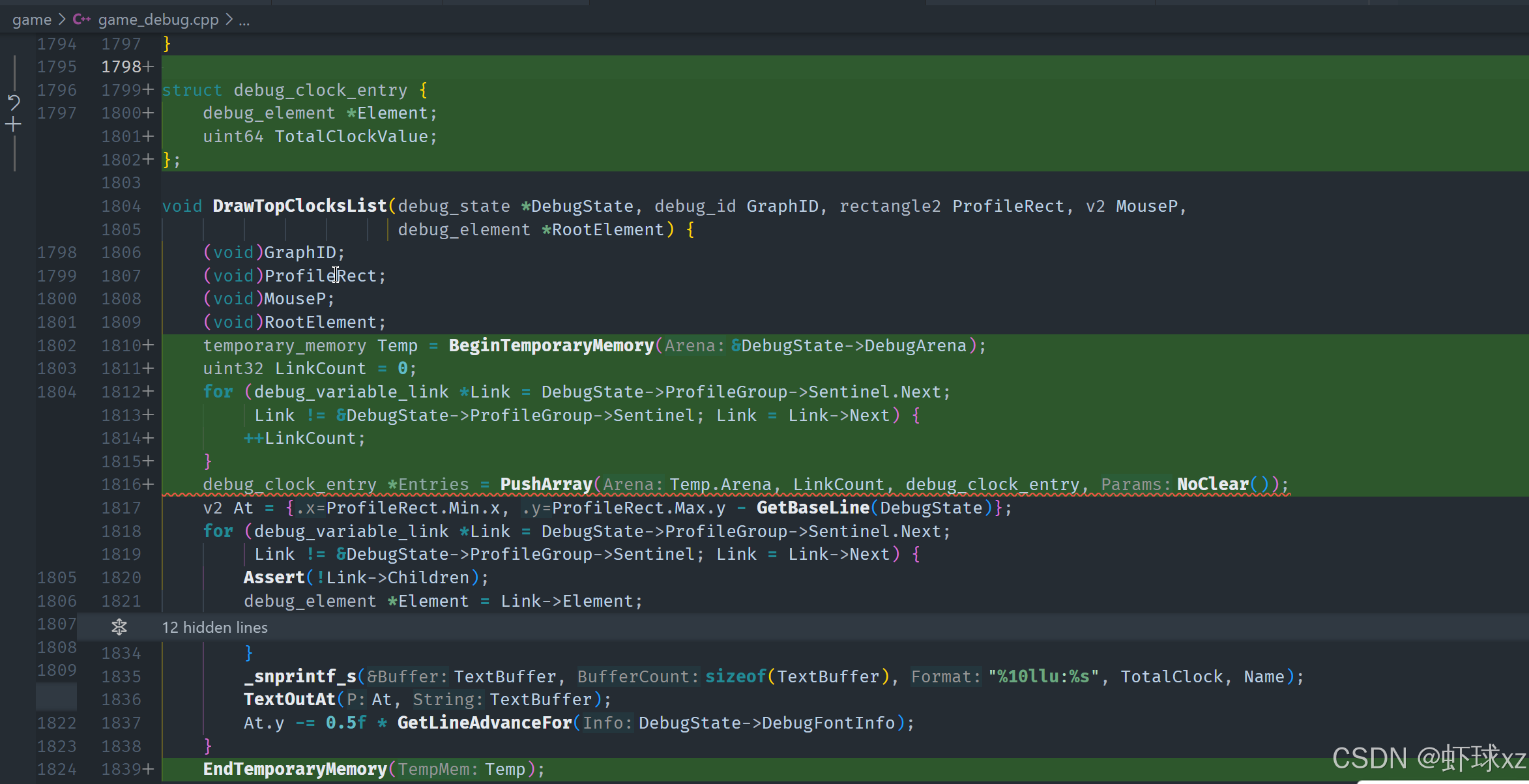
当前的目标是统计每个调试时钟项(clock entry)的耗时信息,并为后续排序和百分比计算打基础。由于事先无法确定这些 clock 项的具体数量,因此需要动态分配并跟踪这些项的临时数据结构。
首先,构建了一个临时的 ClockEntry 结构,结构中包含以下内容:
- 对应的调试元素(debug element)指针,便于后续识别与关联。
- 对应的总耗时或调试统计对象(debug statistic),用于累计采样值,并支持最小、最大、平均等分析。
接着执行以下步骤:
-
遍历所有的调试时钟项,统计数量。
-
在
debug state所在的内存区域(arena)上创建一个临时内存分配区,以避免长期占用资源。 -
使用
push_array_no_clear创建一个大小等于调试时钟项数量的临时数组,这样可以在后续处理中随意访问每一项。 -
不进行清除(clear)操作,是为了保留之前初始化的最小最大值设定状态,便于统计逻辑正常工作。
-
对于每个调试项:
- 将其对应的元素指针存储至
ClockEntry数组中; - 对其耗时值执行统计过程:调用
begin_debug_statistic初始化统计器; - 然后以该项耗时值作为输入,调用
record_debug_statistic; - 最后调用
end_debug_statistic完成一次样本的统计。
- 将其对应的元素指针存储至
该逻辑通过临时数组缓存所有时钟数据,使其可以在后续步骤中进行排序、百分比计算、可视化展示等操作。整体思路清晰,结构设计符合高性能调试工具的基本需求,内存分配也采用了合理的临时区域控制,避免内存污染。
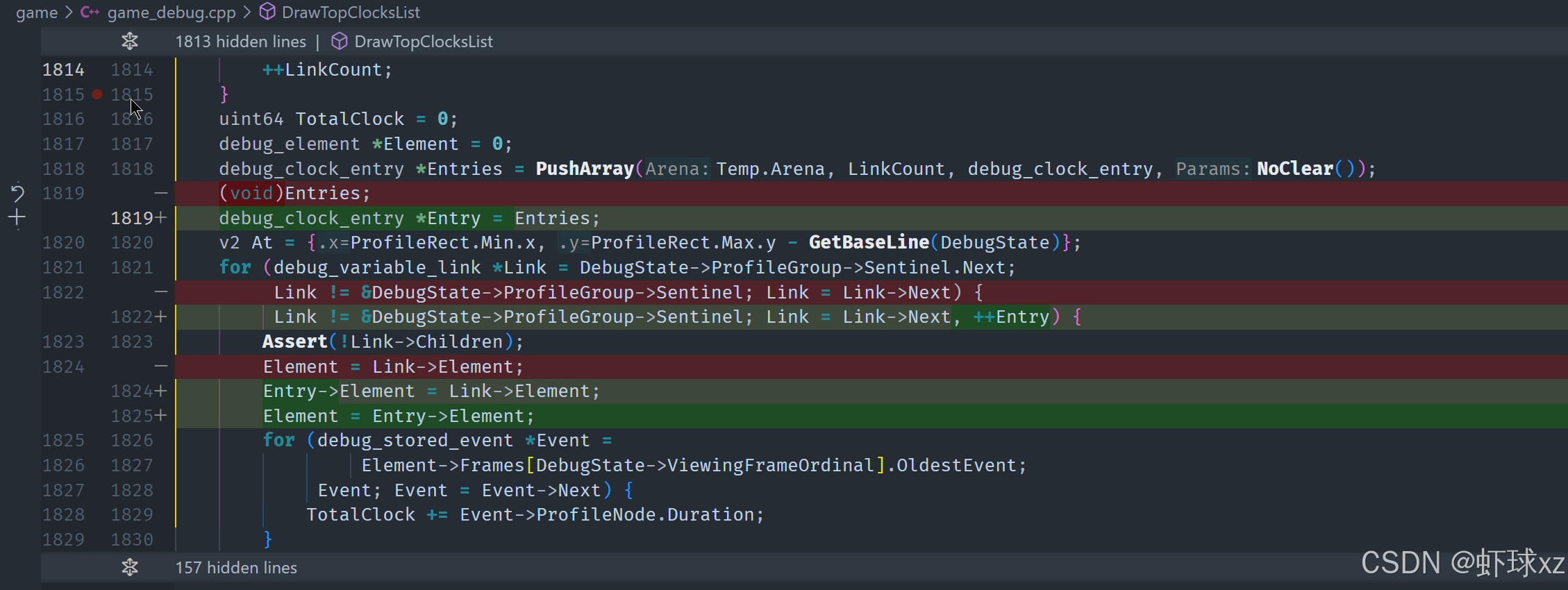
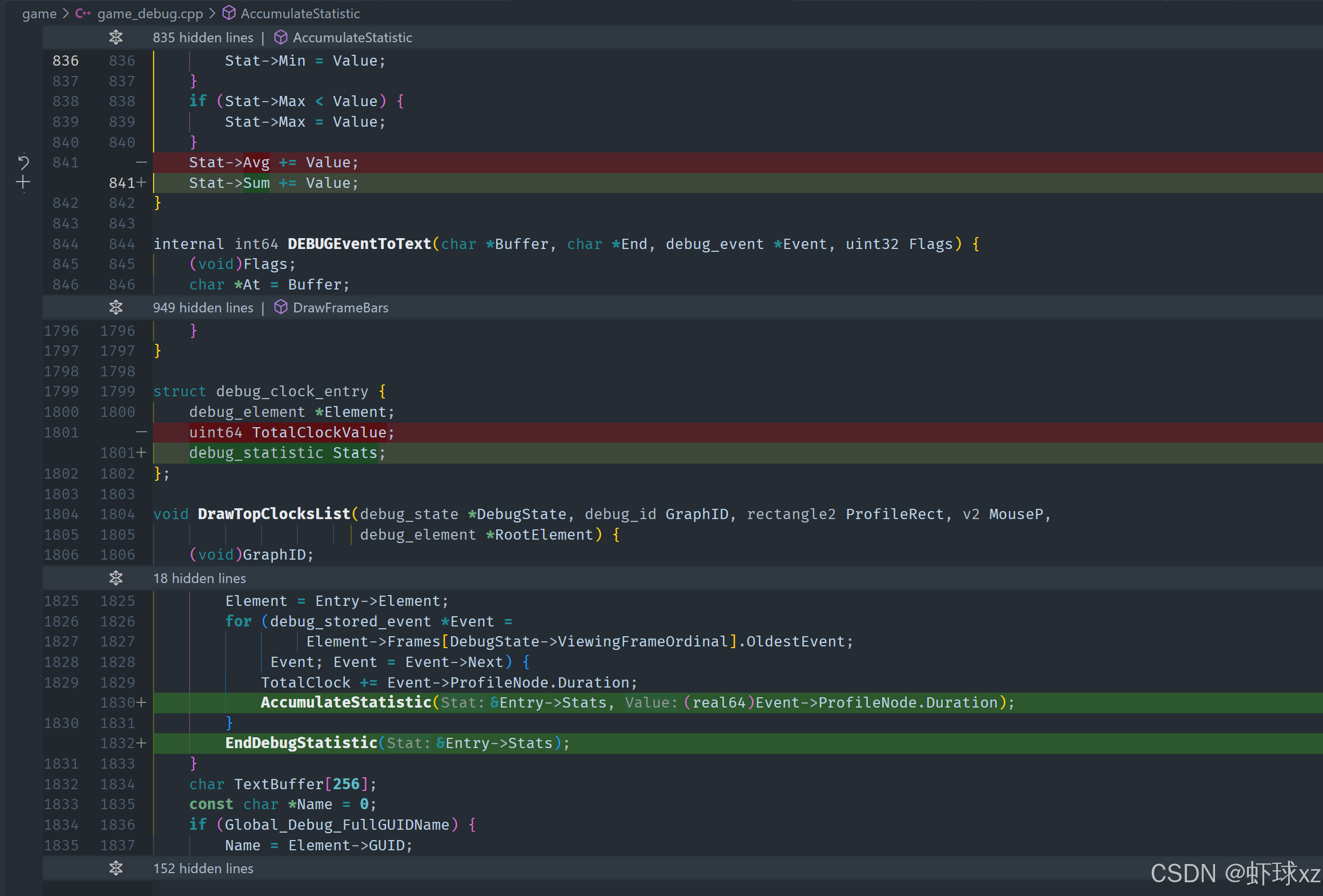
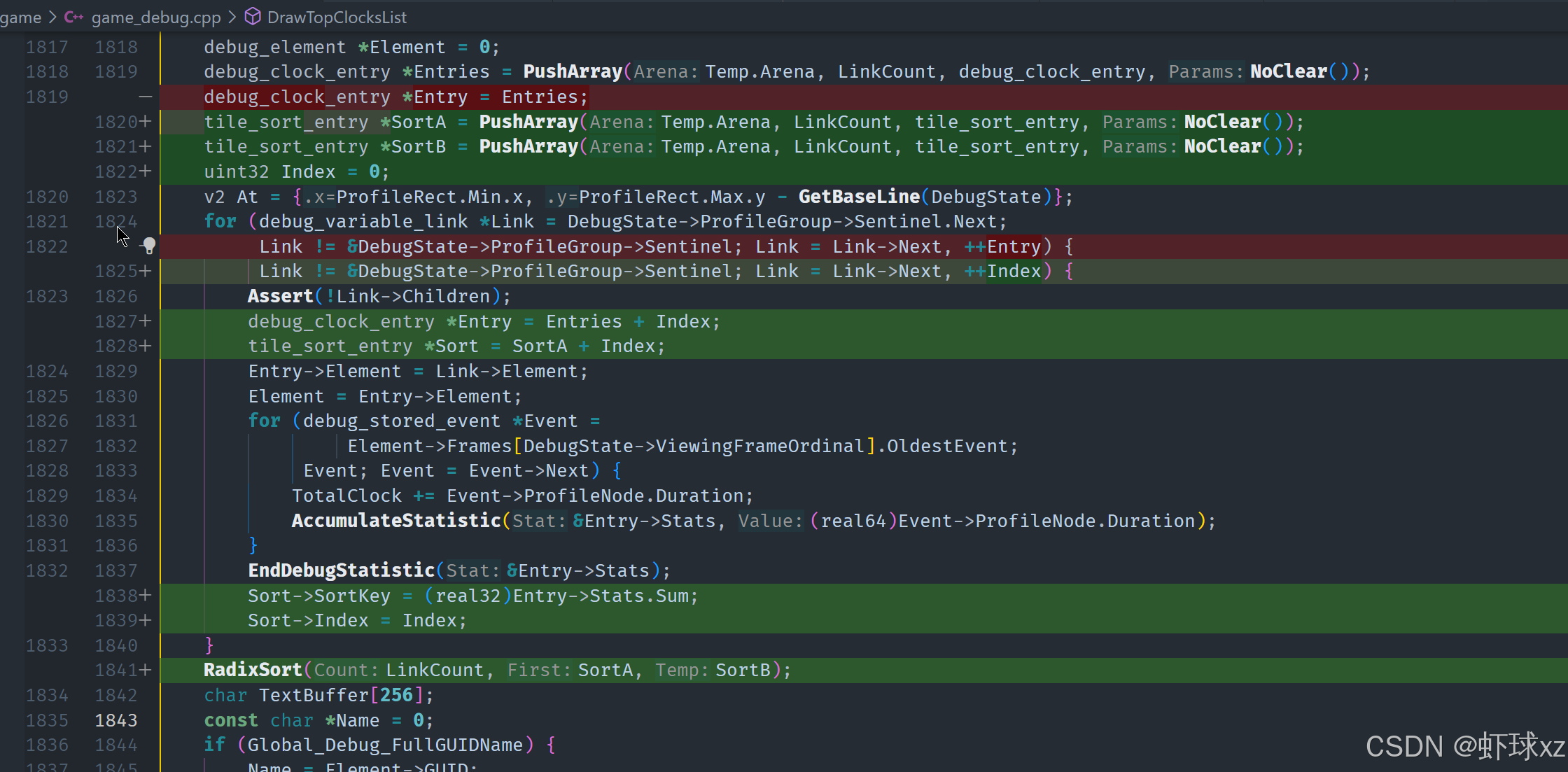
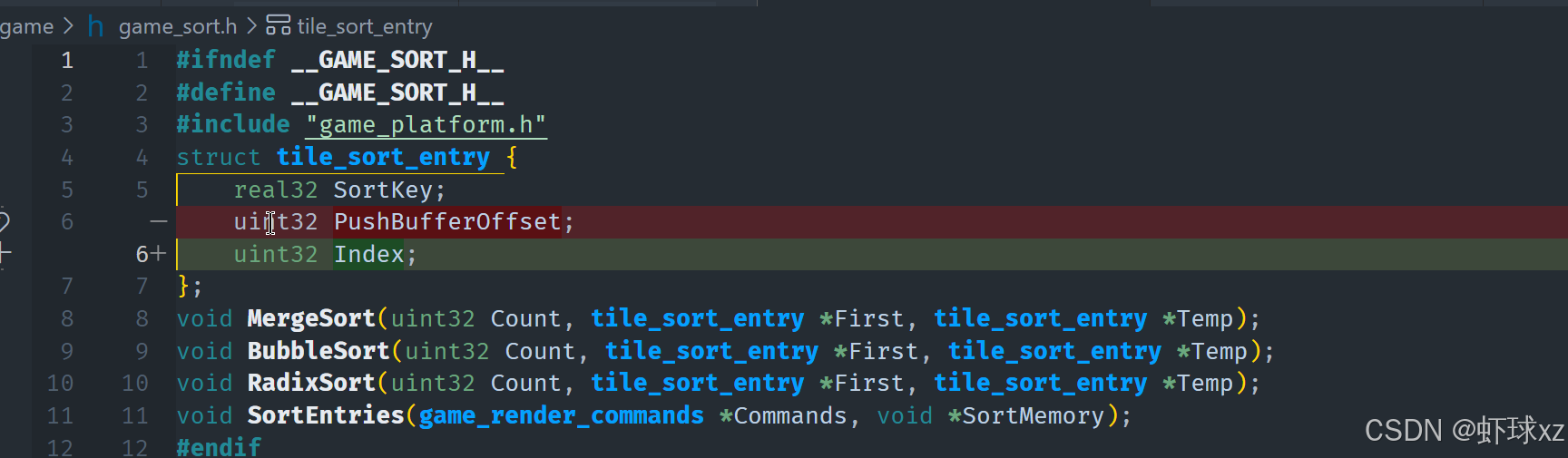
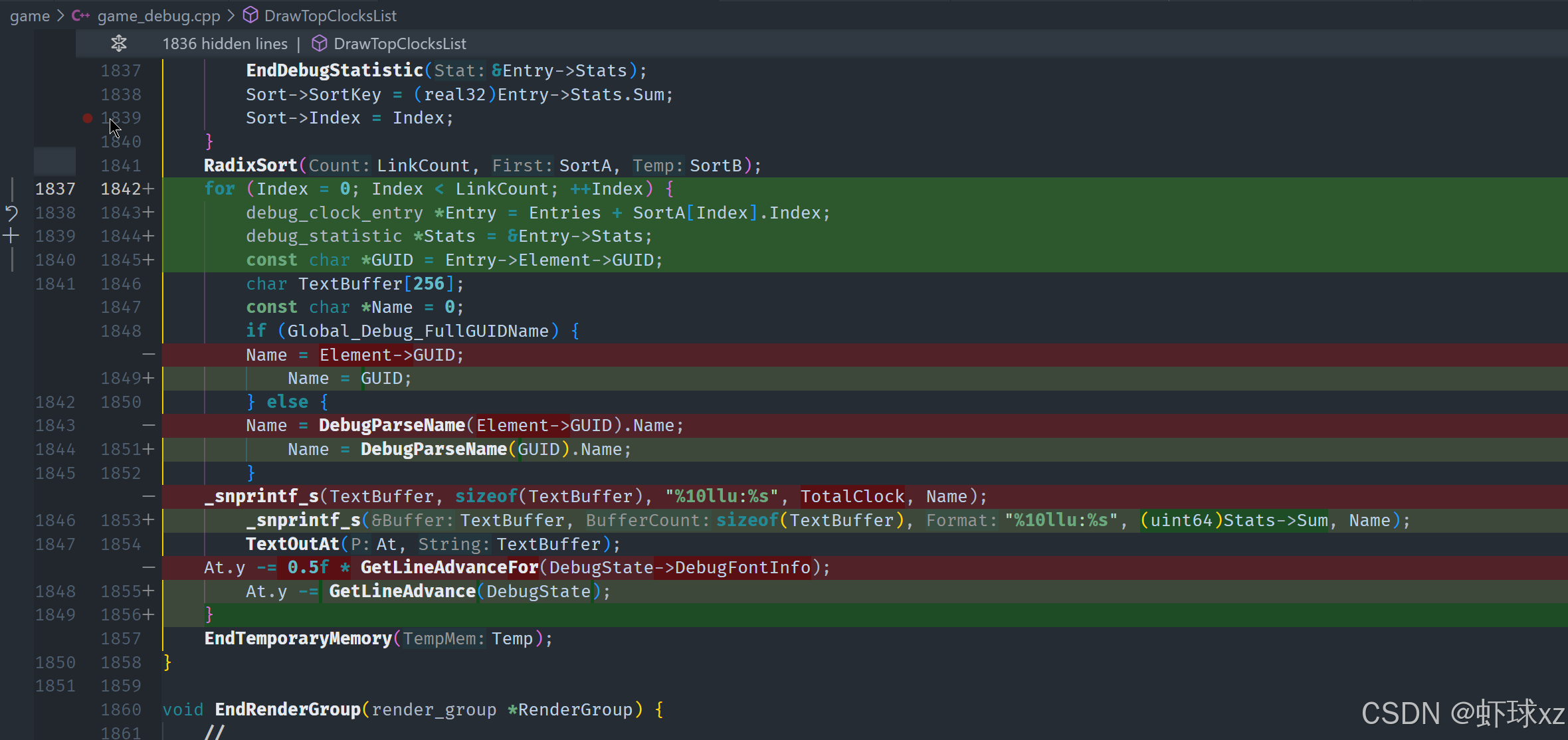
game_debug.cpp:准备对 DrawTopClocksList 进行排序处理
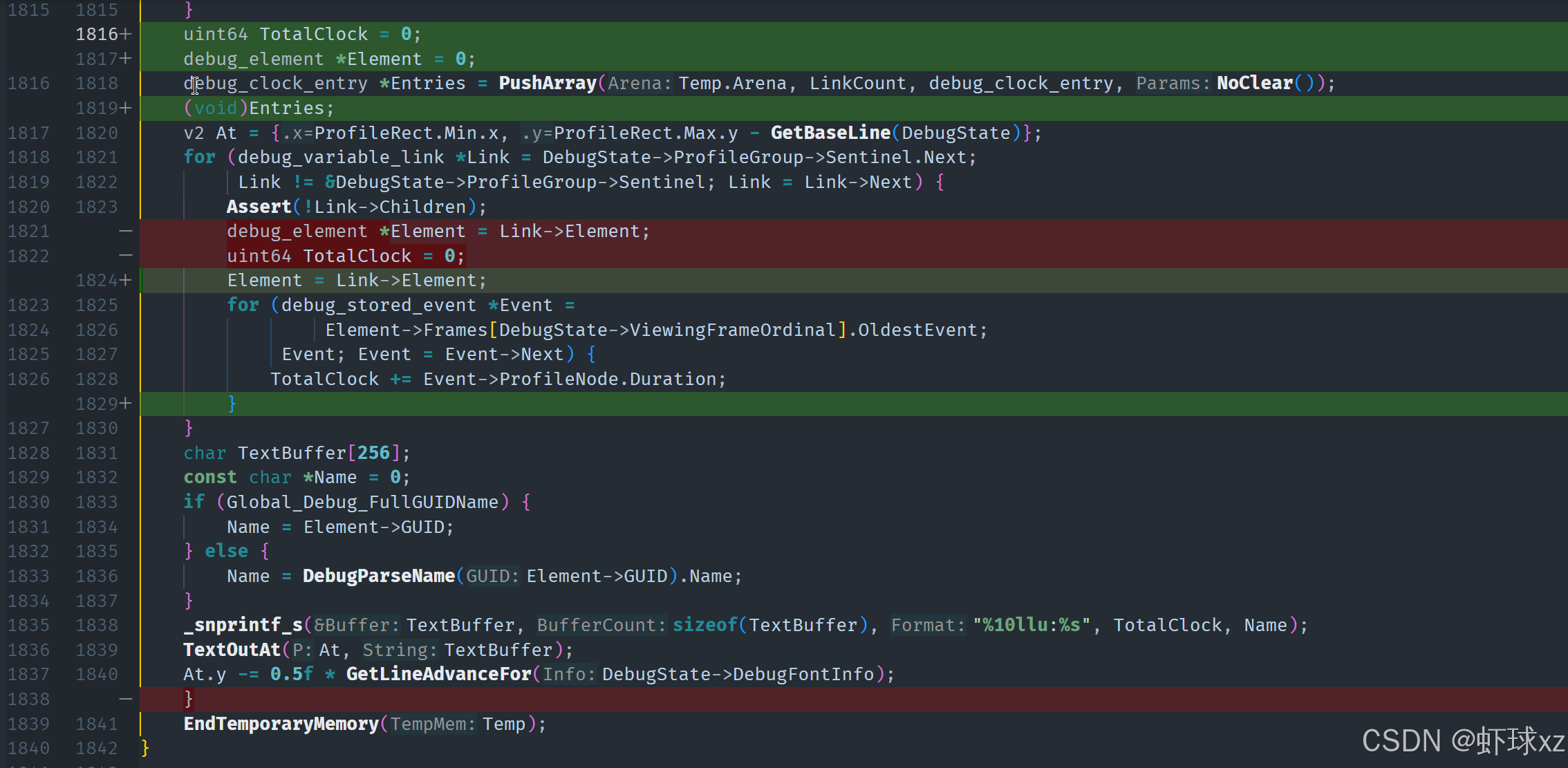
在这段内容中,目标是在前面建立的 ClockEntry 基础上,准备对其进行排序,并最终以有序方式输出调试时钟项的统计信息。整个过程分为以下几个主要步骤:
1. 准备排序所需的中间结构
创建了两个临时的排序数组 sort_a 和 sort_b,它们都在 debug arena 中临时分配,用于后续排序操作中的键值与索引存储。
sort_a是主排序数组,存储排序键(即统计信息的总和)和对应的索引。sort_b是辅助排序数组,用作排序算法中的缓冲区。
初始化 sort_a 时,为每一个时钟项设置:
key为对应统计项的总和(sum),即每个 clock entry 消耗的总周期数。index为该 entry 在数组中的索引,方便后续通过排序结果索引到具体项。
2. 执行排序操作
使用排序算法(如 radix sort)对 sort_a 进行排序,并利用 sort_b 作为辅助空间。
排序完成后,可以通过排序后的索引间接访问到原始的 ClockEntry 数据,实现按消耗总量从大到小的有序输出。
3. 有序打印排序结果
对排序后的每个 entry 执行以下操作:
- 读取排序数组中的索引,间接访问
ClockEntry。 - 取出对应的
debug_element和统计项的sum值。 - 将其以统一格式打印出来(后续还会考虑更精准的格式化打印方式)。
这一步的逻辑确保了输出按照耗时顺序排列,便于识别最耗时的模块。
4. 修复调试统计结构中 sum 的实现缺失
原有的统计结构中虽然定义了 sum 字段,但没有实际实现对它的累加与更新。因此:
- 修改统计逻辑,使其在每次采样值进入时累加到
sum字段。 - 保留
average的计算方式不变,但避免将平均值覆盖sum字段。 - 只有在采样数量有效时才计算平均值,确保
sum保持真实累积。
总结:
这部分工作的核心是为调试输出引入排序与有序展示功能,便于观察每个系统组件在运行时的周期占用情况。通过对统计结构进行改进,并利用排序算法,成功构建了一个临时但完整的调试分析视图框架,为后续的 UI 展示、性能分析或调试排查打下基础。
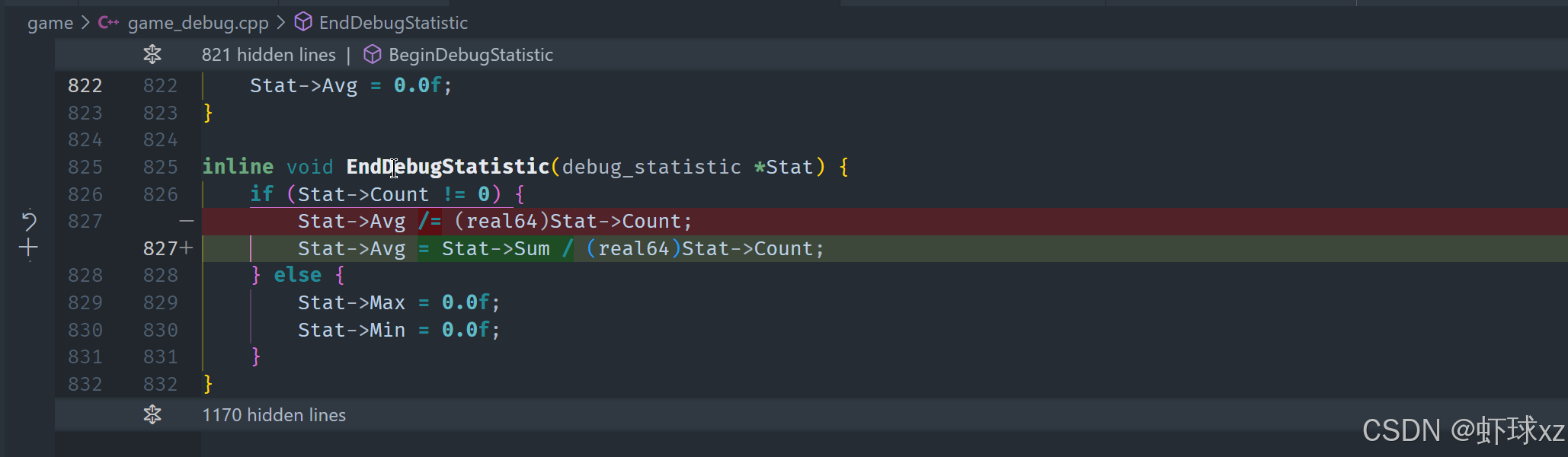
运行游戏并查看排序后的 TopClocksList
在这段内容中,进行了对调试输出排序方向的调整和结果验证,并完成了最终列表输出的准备。主要内容和逻辑如下:
1. 排序结果正确但方向相反
原先的排序逻辑成功运行,并第一次就达成预期效果,这是一个正面的结果。但也发现排序方向与实际需求相反:
- 当前将耗时最少的项排在了最上面。
- 实际上应将耗时最多的项排在顶部,以便在截断列表长度或窗口大小有限的情况下优先看到最关键的信息。
2. 修正排序方向的方式
为调整排序方向,决定在创建排序键时将值取反:
- 通过对排序键进行取负(如
-sum)操作,即可将排序方向反转。 - 这样能确保耗时越多的条目越靠前,从而提升可读性和使用效率。
该调整非常简洁,直接作用在排序前的键值生成处,无需变动其他结构或排序算法逻辑。
3. 最终效果验证与输出准备
调整后,输出内容已正确将高耗时项目置于列表顶部。接下来计划:
- 打印出更多与这些项目相关的信息以丰富显示。
- 考虑之后添加截断窗口限制,因此必须确保最重要的调试信息排在最前,避免被遮挡或遗漏。
4. 剩余工作延后处理
由于时间关系,当前先输出一部分基本信息,其他如输出格式美化、进一步功能扩展(如百分比、可视化等)将暂时延后,留待后续处理。
总结
本节实现了排序方向的修正,使调试输出更加符合使用预期。同时,为后续的截断优化、界面展示或性能分析提供了更可靠的数据基础。整个过程逻辑清晰、实现高效,是调试功能迭代中的关键步骤。

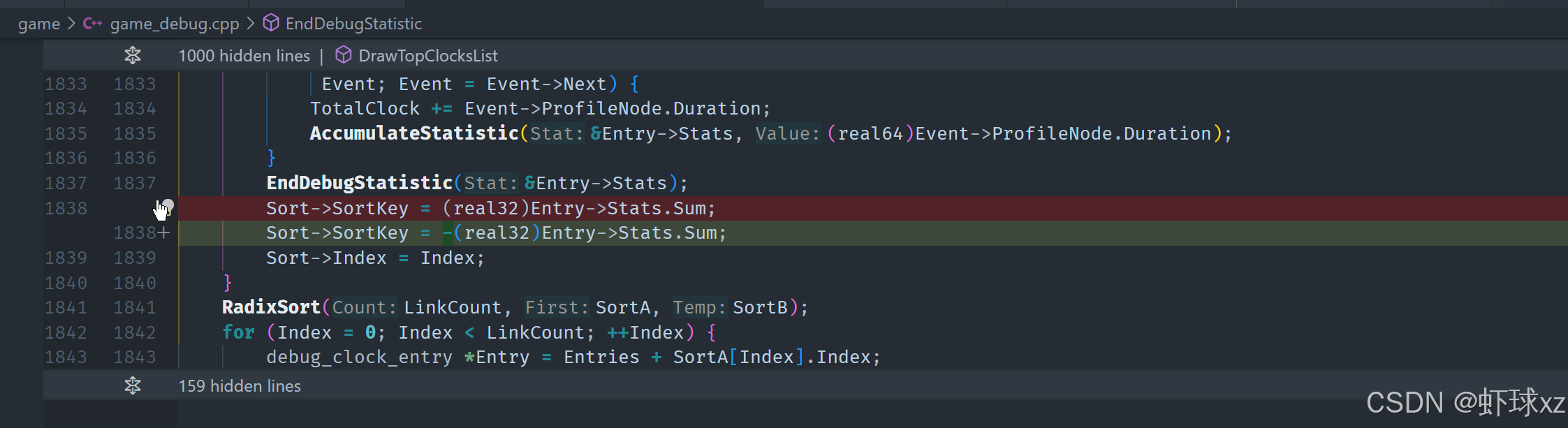
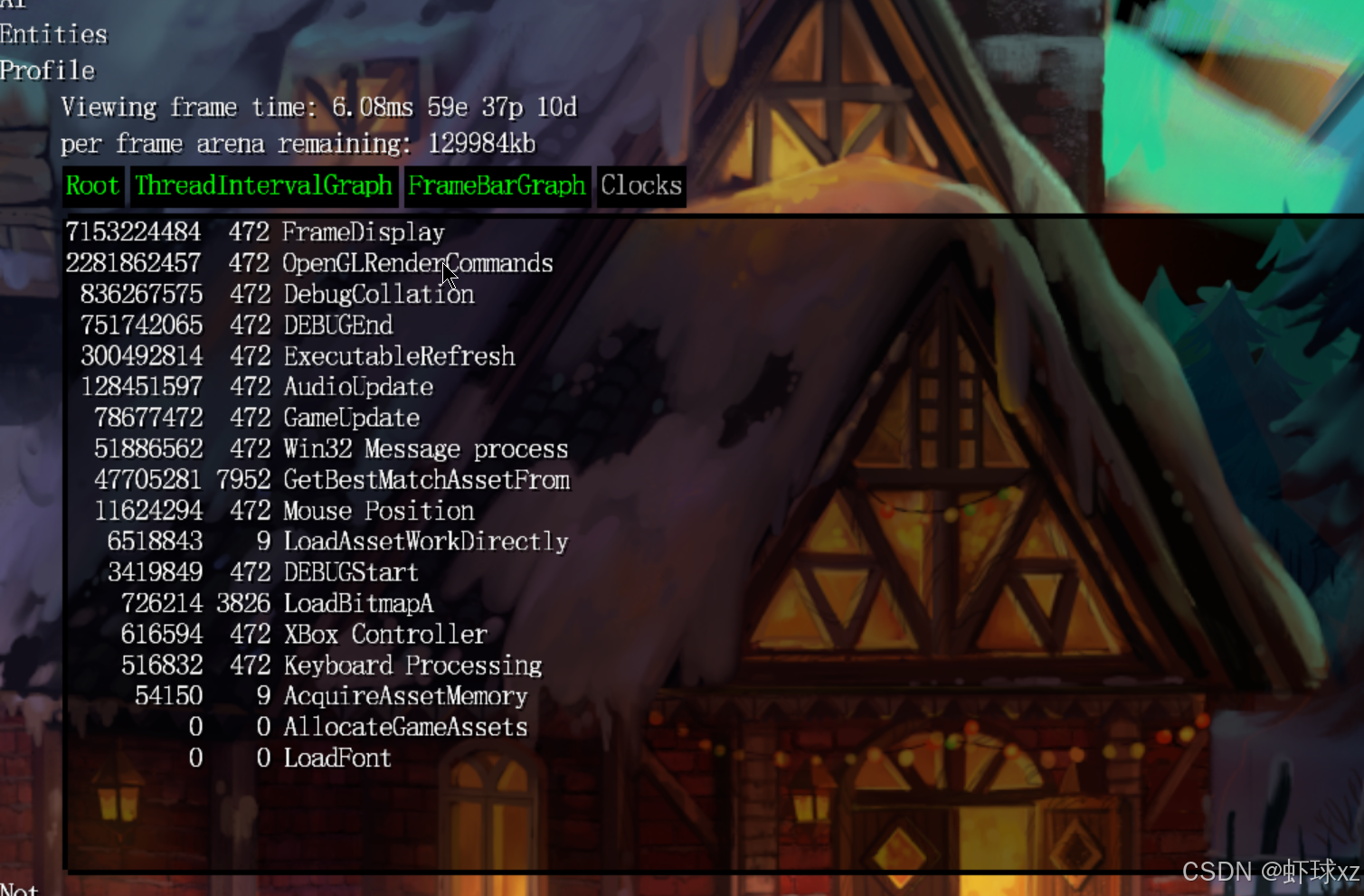
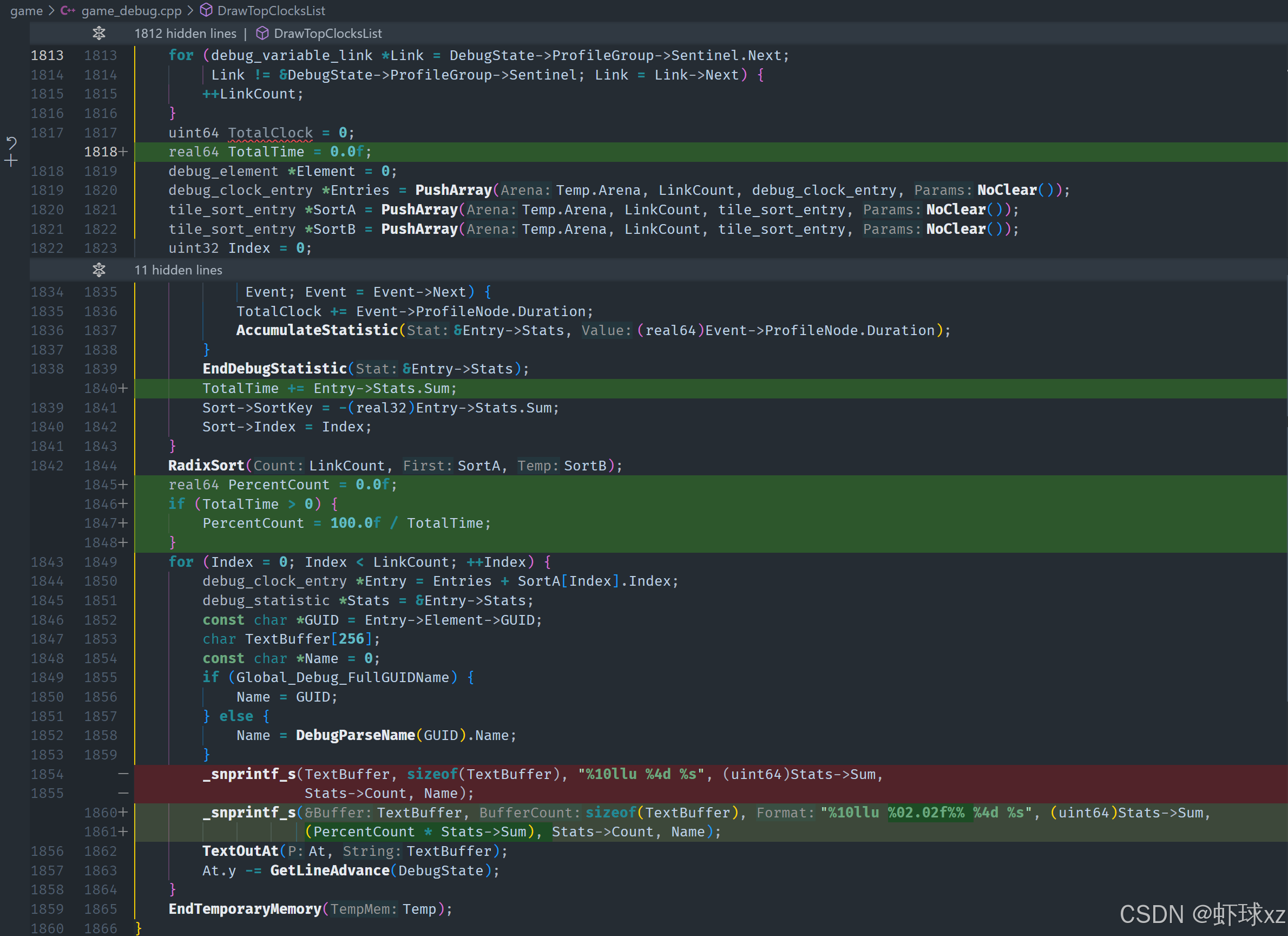
game_debug.cpp:为列表添加调用次数(Count)和百分比(Percentage)
在这部分内容中,继续对调试输出进行完善,主要添加了统计调用次数和执行时间百分比的功能,以更全面直观地展现性能数据。以下是详细整理总结:
1. 添加调用次数统计
开始在调试输出中加入每项操作的调用次数:
-
通过输出
stats.count字段,展示每个调试项被调用的次数。 -
举例:
- 显示某项资源请求了 17 次;
GetWorldChunk函数调用了 715 次;ChangeEntityLocation被调用了 278 次等。
这个数据反映出各个操作在实际运行中的调用频度,有助于判断热点代码区域。
2. 添加总执行时间统计及百分比计算
为了进一步提升数据的可读性,增加了每项操作占总执行时间的百分比:
步骤如下:
-
总时间累加:
- 每处理一个调试项时,将该项的
sum(总耗时)加到total_time中,得到一个累积总值。
- 每处理一个调试项时,将该项的
-
计算百分比转换因子(即百分比系数):
- 初始化一个变量
percent_coeff,初值为 0。 - 如果
total_time大于 0,则令percent_coeff = 100 / total_time。 - 这个因子后续用于将每个单项的耗时
sum转换为占比百分数。
- 初始化一个变量
-
生成最终输出值:
- 对每项,使用其
sum乘以percent_coeff得到百分比。 - 在打印输出中插入该百分比信息,紧跟在统计信息之前。
- 百分比后加上
%符号,与后续的调用次数一起显示。
- 对每项,使用其
3. 输出结构优化示例(逻辑上)
最终的输出结构更丰富、易读:
[占比 %] [调用次数] [调试项名] [总耗时]
12.4% 715 GetWorldChunk 239480 cycles
5.2% 278 ChangeEntityLocation 103200 cycles
1.0% 17 LoadAsset 19850 cycles4. 价值与意义
通过引入调用次数和占总时间百分比的统计,显著提升了调试数据的实用性:
- 可以一眼识别出"高频调用 + 高耗时"的瓶颈函数。
- 可以更容易发现某些可能存在性能问题的区域。
- 百分比化的数据便于在不同运行条件下比较,具有通用性和可视化潜力。
这部分的修改属于调试系统可视化和实用性的重要增强环节,能够有效辅助性能优化与问题定位。是否还需要加入排序或颜色高亮等视觉提示功能?
count 怎么一直增加
100.0f / TotalTime 是为了高效计算每个条目占总时间的百分比,逻辑上完全等价于标准百分比公式:
百分比 = (某项时间 / 总时间) × 100%只不过是提前算好这个系数,避免在循环中反复除法。
打印% 用%%
乘以 100 是为了把「比例」变成「百分比」。
百分比和比例的区别:
- 比例(fraction):
0.25→ 表示 1/4,也就是 25% - 百分比(percentage):
25.0%→ 乘了 100,变成人更容易理解的格式
为什么要这样显示?
如果你不乘以 100,输出的就是:
0.013245用户看不出这个数字直观代表什么,换成乘以 100 后变成:
1.32%这才更容易判断"这个函数占了总时间的 1.32%",清晰直观。
举例:
如果某段函数运行耗时是总时间的 0.13245,也就是:
比例 = 0.013245
百分比 = 0.013245 × 100 = 1.3245%总结:
乘以 100 是为了把比例变成常用的百分比单位,让数值变得人类可读、易于比较。
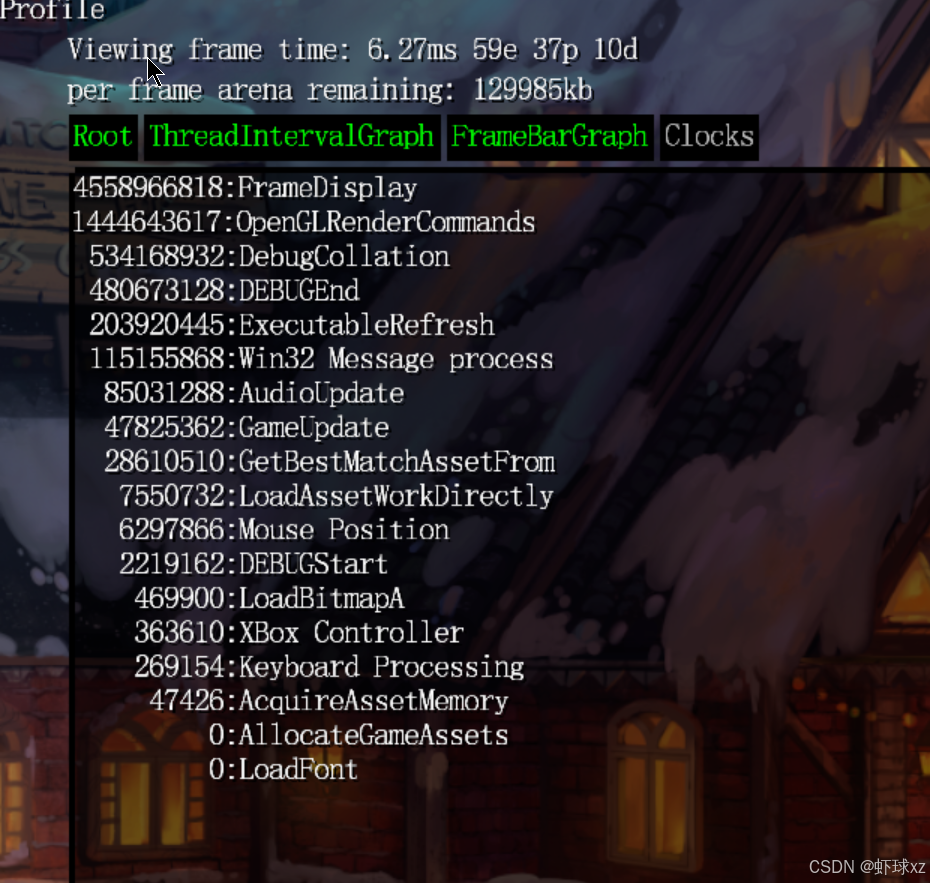
运行游戏并查看 TopClocksList
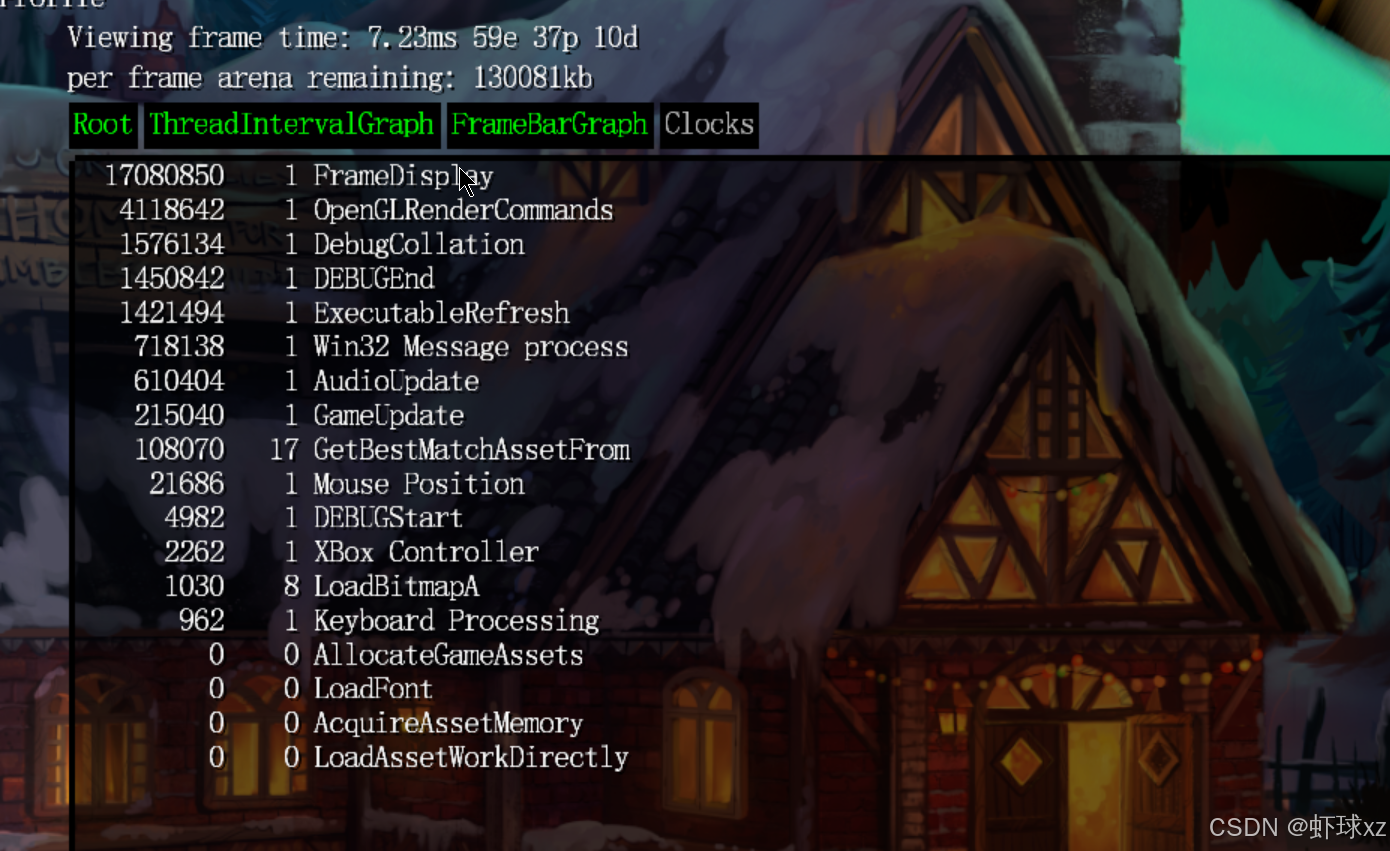
我们现在已经可以看到每个部分所占用的时间百分比了。从可视化结果来看,越是排在顶部的函数,其耗时百分比越高,而底部的则越低,这正是我们预期的效果。
但要注意,这些百分比是包含子节点(children)执行时间的"总耗时"百分比,也就是说,如果一个父节点下面包含子节点,那么其统计时间会把子节点所消耗的时间也算进去。
例如在统计 GameUpdate 和 GameUpdateAndRender 这两个部分的时间时,看到它们都显示大约 20% 的耗时,其实是因为它们测量的是同一段代码的执行时间,只是出现在不同的命名或层级中,所以显示出来的耗时百分比是一样的。
因此在查看这些数据时,我们要注意:
- 父节点的耗时包含了所有子节点的时间;
- 两个看似不同的名称,可能其实是对同一个逻辑块进行的多次计时;
- 百分比之和可能大于 100%,因为存在重复计时(子节点耗时也被父节点重复累计);
- 这类统计适合用来找出最重的执行路径,而不是严格的单独时间消耗。
继续深入分析这些数据的话,可以考虑引入"独占时间"(不包含子节点)统计方式,以获得更细粒度的性能分析结果。需要我帮你设计这部分的独占时间统计逻辑吗?
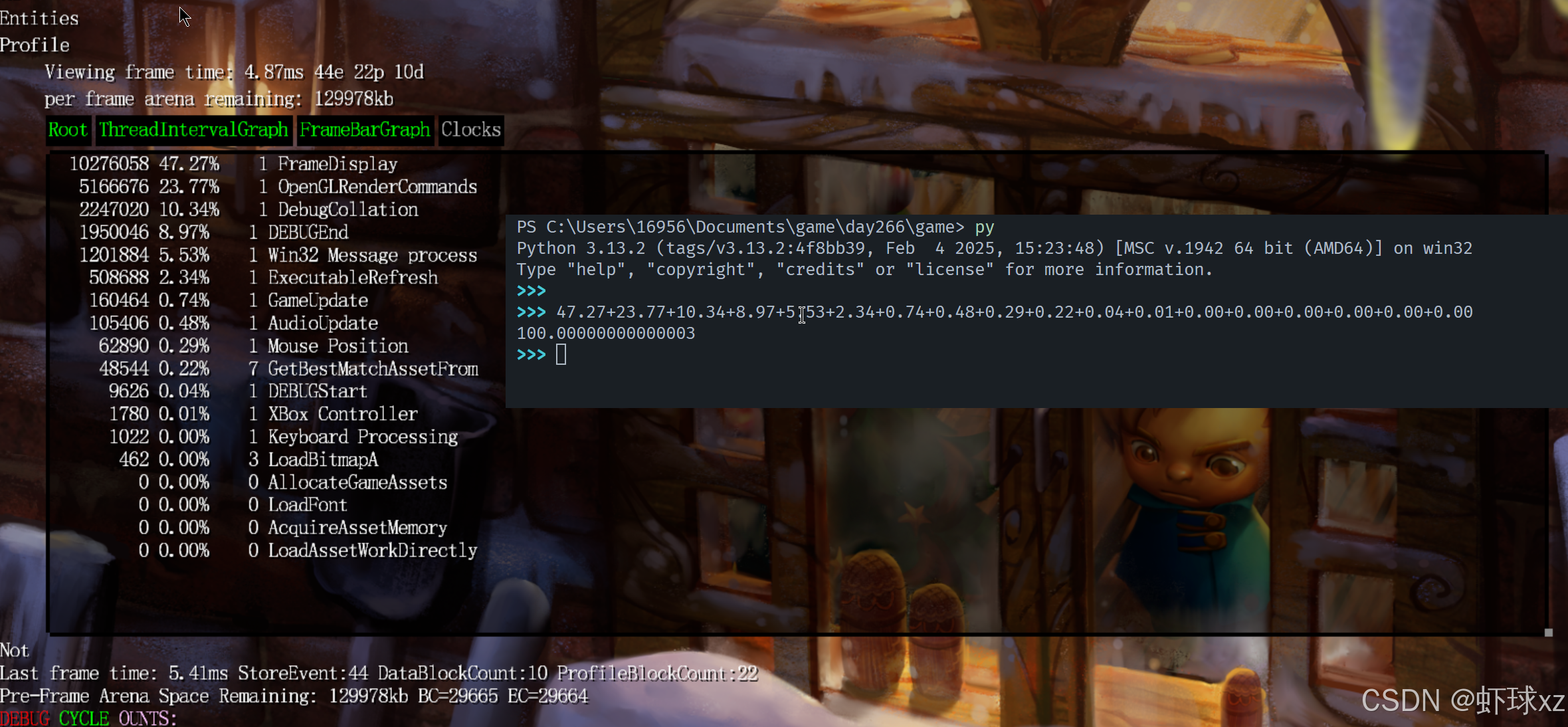
"我们加起来不会是 100%"α
当前的统计中,各个部分的时间百分比理论上应当能够加总为 100%,因为它们是基于总耗时计算得出的。然而,实际观察后发现总和似乎并不完全是 100%,这引起了注意和思考。
在回顾数据后,意识到这是由于当前统计逻辑中,每个部分的耗时百分比包含了其所有子节点的时间,因此产生了重复计数的现象。例如:
- 如果某个顶层函数调用了多个子函数,那么其统计时间就包含了子函数的所有执行时间;
- 如果这些子函数也分别有自己的百分比统计,这些统计值也会被累加到整体总时间中;
- 最终的结果是多个函数的时间出现了重叠,造成百分比加总超过 100% 的假象。
但实际上并没有错误,因为"总时间"的定义是累加所有事件的耗时,而这些事件之间可能存在嵌套。换句话说,这是**"包含子节点"的总耗时百分比**。
这种统计方式在实际分析时并不总是有用。例如:
GameUpdate和GameUpdateAndRender看起来都占用了相同的时间百分比;- 但实际上
GameUpdate只是调用了GameUpdateAndRender,自己并没有多少逻辑; - 所以它显示占用了大量时间其实是因为其子节点(例如
GameUpdateAndRender)的执行时间被包含在内; - 因此在进行性能分析时,我们更希望看到"独占时间",也就是不包含子节点的实际耗时,这样才能判断某个代码块本身是否值得优化。
虽然现在的逻辑还没有实现"独占时间"的计算,但这部分逻辑并不复杂,后续可以添加支持。同时也验证了调试界面在遍历和显示这些统计信息时仍然正常工作,路径没有丢失。
总结:
- 当前显示的百分比是"含子节点"的总耗时;
- 所有部分合计可能超过 100%,因为存在重复统计;
- 下一步建议引入"独占时间"统计,以便更精确评估每个代码块自身的性能消耗;
- 目前整体统计逻辑运行正常,后续可以逐步完善。
需要我帮你写一个计算"独占时间"的统计逻辑吗?
Q&A 问答环节
在等待其他操作的过程中,我们观察并指出了一个现象:当前的调试信息列表中没有重复的条目。而这背后的原因值得深入分析。
我们注意到,在某些地方,比如底层调试代码中,确实可能会出现重复的条目。那么,为什么调试系统的大部分地方都不会出现重复条目,而某些地方又会出现呢?
根本原因在于 代码热重载机制 与调试系统对 GUID(全局唯一标识符)的使用方式有关:
- 在调试系统中,每一个被调试的代码块都会生成一个唯一的 GUID,用于标识该代码块对应的调试元素(如性能计时器、断点标记等);
- 当代码发生重载(如重新编译或更新)时,即使逻辑相同,生成的 GUID 可能会变化,因为在内存中它已不再被视为同一段代码;
- 所以,如果调试系统没有正确清除旧的调试数据,新旧代码块对应的 GUID 就会共存,从而在某些场合出现了"重复"的调试条目;
- 然而,在当前展示的这些调试视图中没有看到重复条目,是因为这里展示的是没有经历重载的、仍处于稳定状态的代码路径,这些路径下的 GUID 没有变化,因此条目也不会重复;
- 相对地,在底层调试(如 depot 层)的代码中,由于系统正在频繁更新调试结构体或代码模块,GUID 更可能发生变化,因此会产生多个看似"重复"的调试块------但实际上它们来源于不同的代码重载版本。
这说明当前调试系统的行为与代码的动态更新状态密切相关,并且还揭示了一个有趣特性:调试系统对每次代码变化的反应会体现在它的 GUID 管理方式上,从而可能引发调试信息的分裂和增殖。这既是调试信息一致性的挑战,也是一种有用的追踪机制,帮助识别哪些代码段在运行时被重新加载。
总结:
- 当前界面中没有重复条目,是因为代码没有重载,GUID 未变;
- 底层调试中可能有重复,是因为代码发生了热重载,生成了新 GUID;
- GUID 变化是由于调试系统视新代码为新的逻辑块;
- 这是调试系统自动追踪代码变化的一部分行为。
通过再投资资本收益是否可以避税?
在美国,确实存在通过再投资资本收益来延迟缴纳税款的合法方式。其核心机制旨在为资本投资者提供一定的税务优惠,以激励长期投资。这些机制被广泛应用于高净值人群中,目的是减少短期税务负担,从而在法律框架内实现延迟或降低纳税义务。以下是一些主要方式的详细说明:
1. 1031 交换(Like-Kind Exchange)
- 适用于房地产投资。
- 将出售一个投资性房地产所得的收益再投资到另一个类似的房地产中,可以延迟缴纳资本利得税。
- 要求再投资资产必须是"类似性质"的(即都是用于投资或业务目的的房地产),并需在特定的时间框架内完成。
- 并不是免税,而是递延纳税,直到最终不再进行交换并变现。
2. Qualified Opportunity Zones(合格机会区)
- 投资者将资本利得再投入到被政府指定的"机会区"基金中,可以获得延期缴税、减免部分税款甚至最终免除新投资收益的税务。
- 原有资本利得税可以延期数年,新投资产生的增值在持有满 10 年后可以完全免税。
3. 长期资本利得税优惠
- 持有超过一年的投资将被归类为长期资本利得,税率比普通所得税低很多(最高 20%,相比于普通收入最高 37%)。
- 因此,再投资资本收益并长期持有,可以避免落入更高税率。
4. 基金结构与税务优化(例如 ETF 内部再平衡)
- 投资某些基金(如 ETF)时,基金可以内部进行资产买卖而不触发资本利得事件,因此投资者只在卖出基金份额时才需要缴税。
- 这是一种延迟资本利得税负的工具。
5. 资本损失冲抵
- 可以将其他投资中的资本损失用于抵消资本收益,从而减少应纳税额。
- 若当年亏损多于收益,最多可抵扣 $3,000 的普通收入,其余亏损可递延到未来年份。
总结:
这些税务策略的共同点是,并非直接免税,而是通过结构设计或再投资实现递延纳税 。这样做在法律框架内是允许的,且往往被富人利用来优化税务结构,达到合法节税的目的。制度设计本身就是为了鼓励投资、刺激经济增长,但也确实让财富阶层有了更多规避实际税负的空间。
为什么加起来不会接近 100%?
我们最开始怀疑所有时间百分比加起来不应该是100%,因为时间记录中存在重复统计 (即父代码块会包含子代码块的时间)。在脑中设想时,我们误以为:由于是重复统计的,那么总和应该超过100%。但后来意识到一个关键点------所有的百分比其实都是基于这个"重复统计后"的总时间来计算的 ,因此,虽然时间被重复计算了,但这个总时间已经"包容了"这些重复,所以用它做分母时,得到的各个百分比仍然是统一基准下的比值,自然它们加起来就还是100%。
具体逻辑如下:
- 我们的统计逻辑中,每个代码块的耗时,包括了其子块的时间。
- 所有代码块的耗时加总,会包含重复部分(比如父子重复)。
- 然而,我们在计算百分比时,用的总时间也是包含重复 的,也就是说,百分比的基准(分母)已经是"重复时间"的总和。
- 所以,每个块的百分比是它自己(含子块)时间占"包含重复的总时间"的比例,加起来就会是100%。
举个例子:
| 模块 | 包含的时间(周期) | 百分比计算 |
|---|---|---|
| GameUpdate | 1000 | 1000 / 5000 * 100% = 20% |
| GameUpdateAndRender | 1000 | 1000 / 5000 * 100% = 20% |
| 其他 | ... | ... |
| 总和 | 总时间5000(含重复) | 百分比加起来 ≈ 100%(逻辑成立) |
这种统计方式的问题 是,它无法精确反映某个代码块本身"净耗时",因为它把所有子函数也算进来了。下一步的优化方向应该是:
- 将"净耗时"与"含子块总耗时"分开统计。
- 这样可以看到"这个函数本身值得关注"还是"它本身没问题但调用了开销大的子函数"。
结论是:
我们确实加起来是100%,这是符合当前统计逻辑的。虽然有重复统计,但分母也是包含重复的时间,因此逻辑上成立。最初的怀疑是因为没意识到分母已同步考虑了重复。这个系统可以再进一步增强,以排除重复统计,展示更清晰的性能瓶颈。
如何实现自我更新一个 exe?目前我是用一个第二个 exe 覆盖主 exe。主 exe 启动 updater.exe 后关闭自己,然后 updater 等待半秒后复制... 有没有更聪明的方法?
当前实现的自我更新机制是通过创建第二个 MVC(程序副本)来实现的。该流程包括以下步骤:
- 主程序执行自我更新请求;
- 主程序关闭自身;
- 启动第二个进程(或副本程序);
- 第二个进程等待半秒;
- 然后将新版本文件拷贝覆盖旧版本;
- 更新完成。
这个方法虽然有效,但显得笨重,因此在思考是否有更聪明的方法。核心问题在于:
- 如何优雅地替换当前运行中的可执行文件;
- 如何让系统在不中断服务或引起不必要的资源消耗的前提下完成更新;
- 是否存在不依赖延迟和副本的更清洁机制。
所以接下来的重点是探讨改进这套流程的可能方案,包括但不限于:
- 使用操作系统级的原子文件替换机制;
- 借助守护进程或服务模式(例如有一个专门的更新器负责替换并重启主程序);
- 通过内存映射或重定向启动,避免直接操作正在运行的文件。
百分比可以显示小数位吗?
关于是否可以让百分比显示小数位,答案是可以的。实现这一点的关键在于需要使用浮点数格式进行打印输出。
当前的系统中可能还没有实现浮点数的打印机制,但这本身不是问题,因为这是可以实现的功能。下一步就是去实现一个浮点数的格式化输出函数。完成之后,只需要按照正确的格式进行输出即可。
具体来说,就是将原本用于整数输出的格式改成支持小数的浮点格式,比如使用 %.2f%% 这样的格式字符串,就可以将百分比值显示为两位小数。
因此,这里主要是指出:
- 百分比的小数显示完全可行;
- 只需要实现一个支持浮点格式的打印机制;
- 实现后就可以使用小数百分比输出,不存在技术障碍;
- 这可能是未来调试工具中一个值得添加的改进功能。
game_debug.cpp:将百分比以浮点数形式打印
当前的重点在于格式化输出百分比时,输出宽度和对齐方式未达到预期。原意是希望百分比数值在文本中对齐,为此尝试使用格式说明符指定最小宽度。然而,实际输出中这些设置似乎被忽略或未正确生效,导致显示混乱或对齐不齐。
问题分析如下:
- 试图指定输出宽度为至少三位数字,但输出结果未体现这一设置;
- 预期效果是让所有数字右对齐,使整体输出美观且易读;
- 使用的是浮点数格式化字符串,但可能忘记了正确的语法;
- 意图是同时控制小数位数(如两位小数)以及字段宽度。
格式设置的正确方式示例应为:%6.2f
其中:
6表示总宽度至少为 6 个字符;.2表示保留两位小数;f表示浮点数。
如果想显示百分号,可以组合为 %6.2f%%,表示占位六位、两位小数并加上百分号。
总结内容:
- 当前输出格式中的宽度指定未按预期工作;
- 需要复习并正确使用格式化语法来控制对齐和小数;
- 为了统一输出视觉效果,应明确总宽度和小数精度;
- 建议使用
%6.2f%%类似的方式达到效果; - 这种处理有助于提高调试输出的可读性与专业度。
如何调查鼠标移动时输入处理周期计数增加的问题?
在输入处理过程中,当鼠标移动时周期计数(cycle count)增加,针对这一现象,可以进行以下详细分析和处理策略:
首先可以明确的是,这种周期计数的上升确实出现在特定代码区域,比如 Windows 消息处理相关部分。由于之前的测试已经观察到,在用户点击后周期数明显上升,并能通过调试回溯定位到对应的处理函数,因此可以初步确认问题区域。
具体的调查步骤如下:
-
增加时间测量块(timing block)
可以在代码中更细致地加入调试时间测量(debug timing block),将大的处理流程细分成更小的逻辑段,例如分开记录:窗口消息接收、消息分发、鼠标事件处理等每一个环节的时间消耗。
-
使用暂停和回溯观察跳变点
在调试过程中使用暂停功能,在周期数明显上升的帧进行静态观察,并回溯至某一帧前的状态,查看此帧与前一帧在周期数上的变化是否与某些事件(如鼠标点击、移动)对应。
-
定位特定函数
观察周期数明显上升时的函数调用栈,通过调试器的栈信息或自定义记录,找出是哪些具体的函数在输入事件处理时额外增加了开销。
-
对比不同输入事件
可以尝试比较不同类型的输入事件(例如键盘输入、鼠标点击、鼠标移动)在周期数上的差异,从而缩小调查范围。例如如果只有鼠标移动时周期数增加,说明可能与鼠标位置更新、区域重绘等有关。
-
排查重复或冗余调用
检查是否在鼠标事件处理中触发了不必要的逻辑,比如窗口刷新、重新计算布局、资源分配等,这些都会显著增加周期数。
-
观察事件密度与响应关系
鼠标移动事件在系统中属于高频率事件,如果响应代码没有优化(比如进行了不必要的内存操作或图形更新),即使是微小的处理逻辑也会在频繁触发下积累为大量周期。
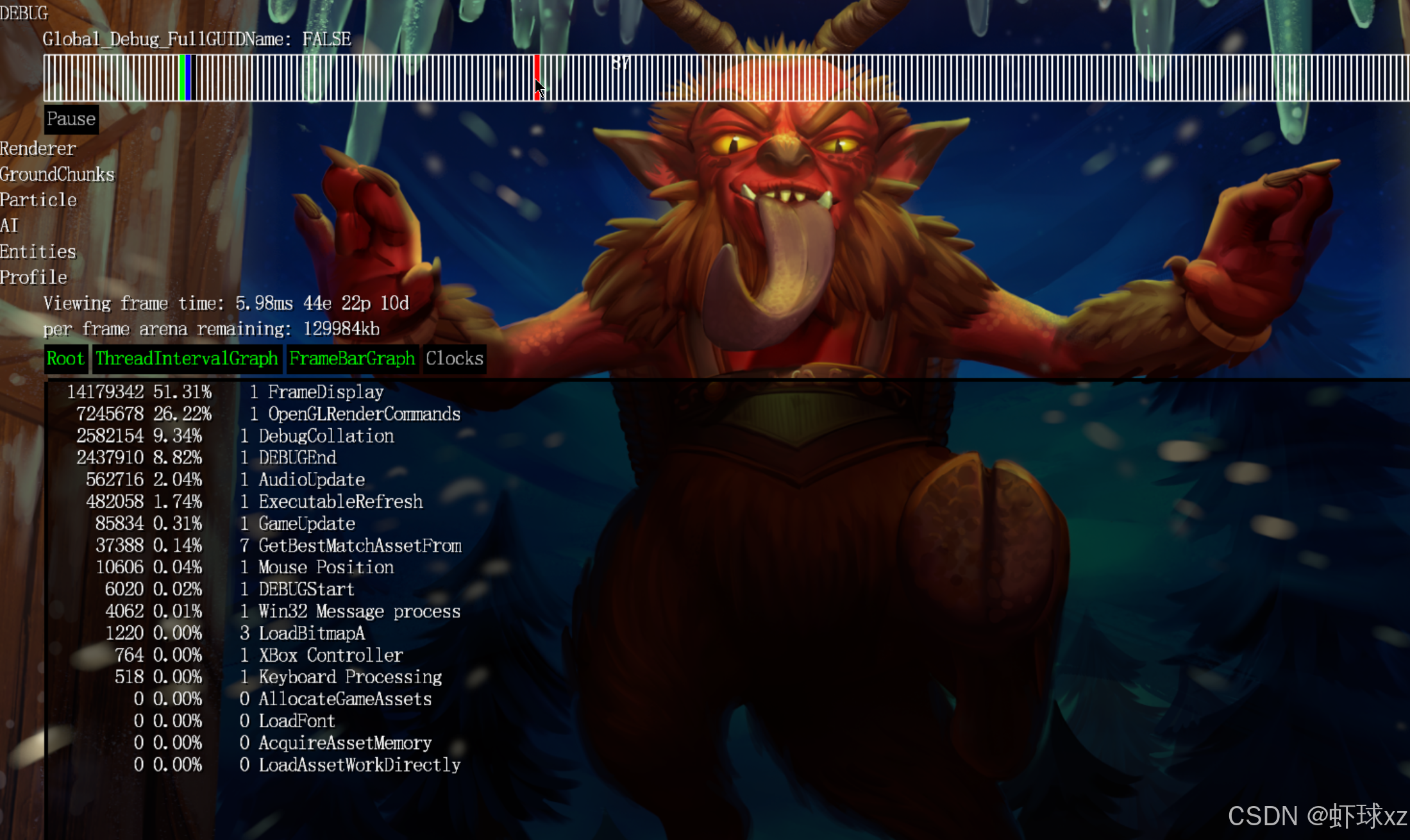
欣赏这个性能分析器β
我们通过分析发现,在系统中并没有特意为某些调试功能编写额外逻辑,仅仅由于所有的事件流程都经过同一个调试通道,使得我们可以随时跳转到任意帧,并查看完整的信息,包括所有线程的调用情况,这是非常强大且方便的。
在具体的分析过程中发现,在"输入处理(input processing)"这一部分,周期数和资源占用出现明显上升,并且"Win32 消息处理(Win32 Message Processing)"与之同步上升,这说明瓶颈可能就集中在输入处理部分。也就是说,处理鼠标或键盘事件时,会触发一系列资源消耗,造成周期增长。
进一步排查定位到 Win32ProcessPendingMessages 函数,这是应用中唯一一处真正执行输入处理工作的地方。相比之下,其他部分几乎都是由操作系统 Windows 自身处理的。
为了进一步确认具体是哪一部分导致了时间增长,尝试在 Win32ProcessPendingMessages 内部插入一个新的调试区块,用于统计时间,这一块命名为 "Win32KeyMessages"。然而通过结果可以看到,这一块并没有被频繁调用,因为这部分可能只与键盘事件相关,跟当前分析的鼠标移动无关。
由此可推断:问题更可能是出现在 PeekMessage 函数内部,这个函数是由 Windows 系统调用的,不在用户控制范围内。从应用层的角度看,我们自己几乎没做什么额外工作,因此如果性能瓶颈出现在这里,很可能就是 Windows 在处理 PeekMessage 时进行了比较重的操作,比如涉及鼠标消息的队列维护、窗口区域更新判断等。
所以当前结论为:
- 周期时间增长主要集中在输入处理相关代码中。
- 增长的原因基本可以定位到
PeekMessage或类似由系统调用的部分。 - 自己的代码并没有做多余处理,也没有频繁被调用。
- 为了确认,可以进一步在
DispatchMessage等位置也插入调试计时点,以排查是否存在其它系统函数耗时。
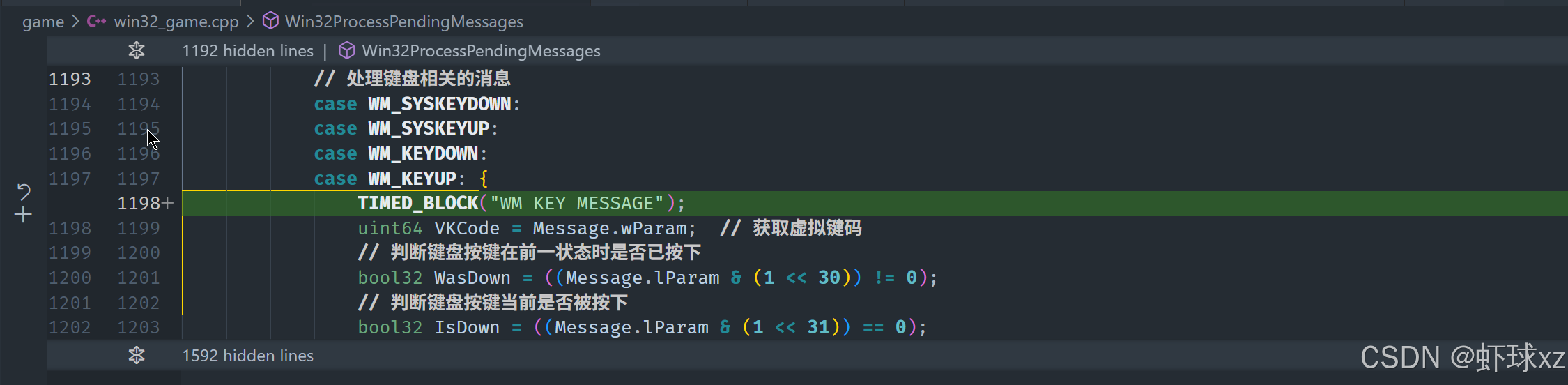
win32_game.cpp:将 PeekMessage 移出 while 条件并放入 TIMED_BLOCK
为了验证系统是否在 PeekMessage 上存在性能瓶颈,可以采取以下两种方式进行检查:
-
检查是否没有收到消息:首先,可以修改代码逻辑,在没有收到消息的情况下跳出消息循环。这可以帮助确保在没有新消息的情况下,消息循环不会继续执行,从而减少不必要的消耗。
-
对
PeekMessage进行计时 :为了进一步验证PeekMessage是否是瓶颈,可以在该函数调用处加上计时逻辑,将其包裹在一个新的计时区块内,记录每次执行PeekMessage的时间消耗。这可以帮助明确PeekMessage函数本身的执行时间,查看它是否对系统性能造成了较大的影响。
不过,在实际操作过程中,出现了一个问题:虽然已经在代码中加入了计时逻辑,PeekMessage 相关的计时信息并没有显示出来。可能是由于某些原因,计时区块没有正确插入或没有生效,导致无法看到预期的输出。
接下来,需要进一步排查为何计时逻辑没有生效,检查是否存在遗漏或其他影响输出的因素。需要确认是代码逻辑的错误,还是调试工具本身的问题。
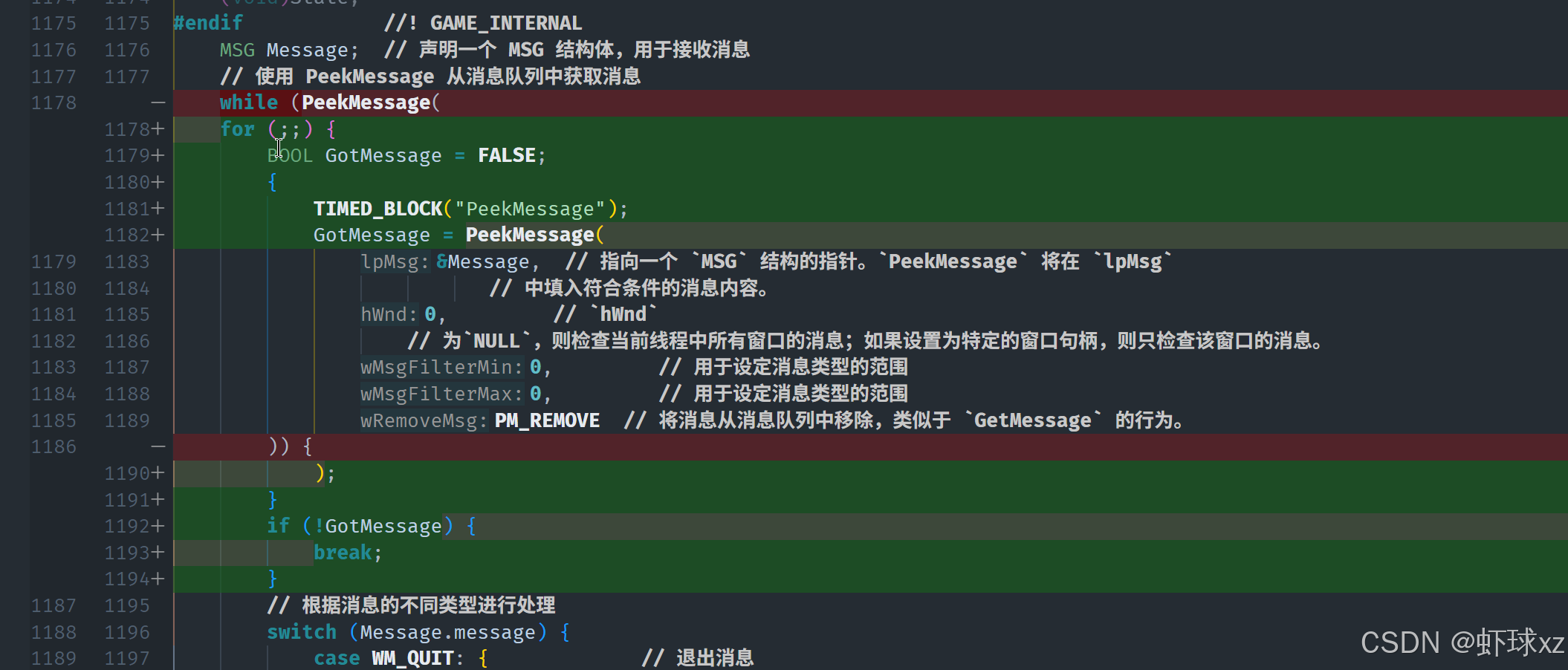
编译并运行,查看 PeekMessage 在分析器中的表现
首先,需要确认是否编译了正确的代码并运行了生成的可执行文件。通过执行编译并运行程序后,检查 PeekMessage 是否被正确计时。在此过程中,确认是否成功看到预期的 PeekMessage 信息,若能看到,则表示计时逻辑已正确应用且代码执行正常。
game.cpp:将 FrameSlider 移入 Profile 区块
在对 PeekMessage 进行性能分析后,发现 PeekMessage 调用消耗了大部分时间,约占 0.25% 的总时间。其他相关函数的消耗时间略高于这个值。分析表明,PeekMessage 主要由 Windows 系统处理,可能在执行线程队列的操作时花费了较长时间。虽然不清楚具体原因,但可以推测这是 Windows 系统内部的行为,且可能无法进一步优化。目前似乎没有其他相关问题需要解决。
没那么多
我的问题是 exe 下载了一个新的 exe,我希望它替换自己,但我不能删除或重命名正在运行的 exe。我可以接受游戏关闭再重新启动,这用于更新玩家端,而非开发使用
在讨论如何实时替换可执行文件时,首先需要考虑的是为什么要替换整个可执行文件,而不是使用动态链接库(DLL)。如果确实需要替换可执行文件,可以通过特定的技术实现。比如,可能会通过卸载当前的游戏代码或其他相关代码块来进行文件替换。这种操作通常涉及一定的管理工作,需要精确的代码控制。不过,具体的实现代码和过程在当前讨论中并没有完全展开。
win32_game.cpp:实现替换并自动重载运行中的可执行文件的功能
在讨论如何动态替换可执行文件时,首先需要确认可执行文件更新的时机。可以通过检查文件的时间戳来判断是否需要更新文件。具体实现时,需要设置路径并对比文件的修改时间,若发现文件已被更新,则触发重新加载。
实现过程中,如果发现需要重新加载程序,通常会遇到程序在运行时无法删除已加载的可执行文件的问题。这是因为Windows系统不允许删除正在使用的文件。然而,可以通过重命名文件的方式绕过这一限制。首先,将当前的可执行文件重命名,然后将新的可执行文件放置到原来的位置。这样,系统会加载新的文件,而旧的文件依然保留,只是被重命名。
需要注意的是,重新加载可执行文件会导致程序短暂的停机,因此在实现时应当权衡是否要自动触发这种操作,特别是在涉及到实时游戏或其他需要连续运行的应用时。此外,动态替换可执行文件可能会影响程序的稳定性,因此要确保这一操作不会导致其他潜在问题。
互联网:MoveFile1
在实现动态替换可执行文件时,首先需要将当前正在运行的可执行文件移动到一个"删除"位置,以便可以替换为新的可执行文件。首先,通过调用系统命令,确认当前文件是否存在并准备好进行替换。然后,进行如下操作:
- 移动当前可执行文件:首先,将当前运行的可执行文件移动到预定的"删除"位置,这样新的文件可以占据原来的位置。
- 删除旧的可执行文件:如果存在已经被替换的旧文件,也需要删除它,以便为新的文件腾出空间。
- 移动新的可执行文件:将新版本的可执行文件移动到原来位置,以替换旧的文件。
- 运行新的可执行文件:一旦替换完成,就需要启动新的可执行文件,通常通过创建进程来完成。
为了启动新的进程,可能需要填写进程信息,其中包括可执行文件的路径和命令行参数。在没有参数的情况下,通常命令行只会传递可执行文件的名称。需要注意的是,Windows不允许删除正在运行的文件,所以使用重命名和移动文件的方法来实现替换。
在此过程中,进行错误检查是很重要的,确保每一步都能正确完成。例如,检查文件是否存在,或者获取文件的时间戳来确认文件是否有更新。此外,为了确保系统稳定性,整个过程需要确保在没有文件的情况下不会执行替换操作。
总结来说,这一操作的核心是通过文件的移动、重命名和启动进程,完成可执行文件的动态替换。
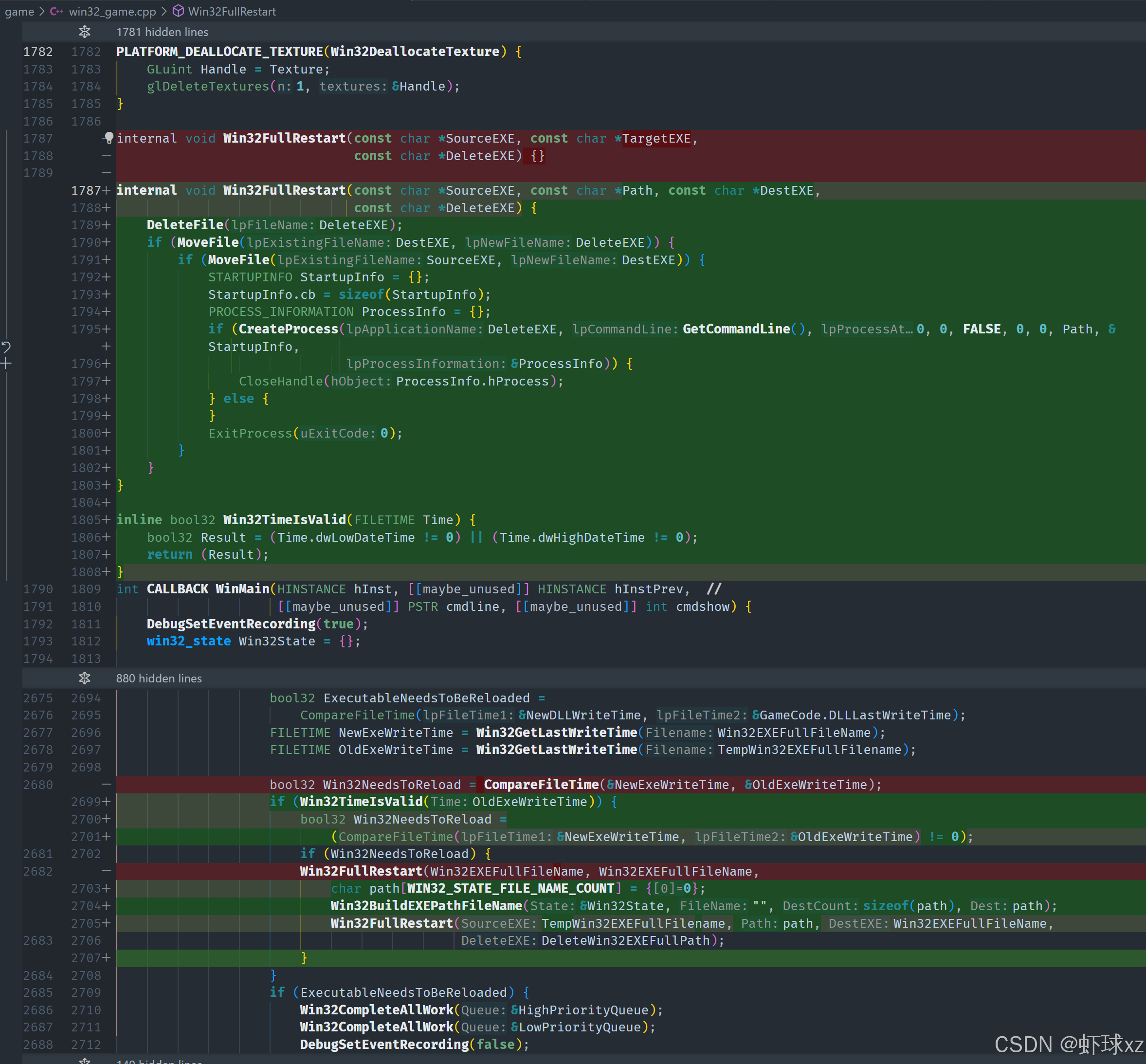
win32_game.cpp:修复 Win32TimeIsValid 条件判断
尝试再次进行可执行文件热重启的过程时,首先将原有的 win32_game_old.exe 移动到 win32_game_exit.exe 的位置,虽然这一步没有进行额外处理,但可以跳过记录。
启动程序后,首先在比较文件时间戳的代码位置停下,对比了新版本可执行文件和旧版本可执行文件的时间。判断出它们不相等,这是预期的结果,因为新的可执行文件其实是替换成了 Notepad。
为了确认结果是否正确,检查了一下 win32_game_temp.exe,发现该文件确实是 Notepad。但这个 Notepad 无法运行,可能是因为缺少依赖的 DLL 或其他系统配置问题,所以最终没有正确启动。这个结果比较无趣,不足以确认整个热重启流程是否有效。
于是删除了当前文件,想换成另一个更简单并能确保能运行的可执行程序来进行测试。例如考虑构建一些已有的项目工具,比如编辑器(editor)或者其它游戏内工具来验证替换流程是否成功运行。也考虑从系统的 Program Files 目录里找一些轻量级的小工具可执行文件进行替换测试,类似 Color Cop 这样的应用。
总的来说,流程是为了验证当可执行文件更新后,系统能否自动检测变化、正确替换并启动新的程序。当前问题出现在替换进去的可执行文件无法运行,从而影响了整体验证效果,因此需要选择一个能确定成功执行的程序来继续测试这个热更新启动流程。
调试器:尝试启动并终止γ
我们完成了热更新可执行文件的流程测试。在替换逻辑完成后,成功将新的可执行文件(如某测试程序)放置到指定路径,并尝试通过代码触发启动。我们确实看到了替换后的程序被启动了。接下来,我们调用自身终止函数,实现了"杀死自己"的操作,从而完成了整个"卸载旧程序 -> 启动新程序 -> 自我退出"的完整流程。这也验证了我们想要实现的运行时可执行文件替换机制是可行的。
在这整个过程中,最关键的一点是:
- 不能直接删除正在运行的可执行文件,Windows 系统不允许这么做。
- 不能复制新的可执行文件来覆盖旧文件,因为复制过程中也可能被系统阻止。
- 正确的方法是:先将旧可执行文件"移动"到一个临时的待删除位置,再将新的可执行文件"移动"到原位置 。这两个动作都必须使用系统级别的文件移动操作(如
MoveFile),因为 Windows 允许移动正在运行的可执行文件(只要目标文件名不同),从而规避了文件锁定问题。
此外,还需特别注意以下几点:
- 替换后的可执行文件是否能成功启动:需要确保它是有效的可运行程序,不能像之前测试 Notepad 那样,因为缺失依赖导致无法运行。
- 启动路径:新程序启动时的工作目录和相关参数需要设置正确,否则可能影响运行结果。
- 操作系统的差异性:需要在多个版本和配置不同的 Windows 系统上测试此机制,包括是否具备管理员权限等因素,因为不同系统可能存在安全策略或权限差异,影响文件操作或进程启动。
- 权限问题:某些系统可能限制非管理员账户启动新的程序或移动关键路径下的文件,因此实际使用中需谨慎处理权限管理。
整体来说,我们已经实现了一个可靠的运行时热重启机制,可以在不关闭整个系统或框架的前提下,平滑替换核心可执行文件并重新启动自身,适用于某些开发模式或运行时自动更新的场景。后续的重点将放在测试和容错处理上,确保在各种环境下都能稳定工作。