基本思想
支持向量机(SVM)实现二分类的基本思想是找到一个最优的超平面将不同类别的数据点分隔开,使两类数据点之间的间隔最大化,从而实现对新数据的准确分类。
详细阐述
1.构建分类超平面:
在二分类问题中,假设存在两类数据点,分别用不同的符号(如正例为 "+1",反例为 "-1")表示。SVM 的目标是在特征空间中找到一个超平面,将这两类数据点尽可能准确地分开。这个超平面可以用方程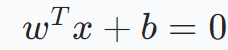 来表示,其中 w 是超平面的法向量,决定了超平面的方向,b是偏置项,决定了超平面与原点的距离。
来表示,其中 w 是超平面的法向量,决定了超平面的方向,b是偏置项,决定了超平面与原点的距离。
2.寻找最大间隔:
为了使分类器具有更好的泛化能力,SVM 不仅要找到能将两类数据分开的超平面,还要使这个超平面与两类数据点之间的间隔最大化。
间隔是指超平面到最近的数据点的距离,这些最近的数据点,在间隔边界上或者间隔边界与分类超平面之间的训练数据点被称为支持向量。
通过最大化间隔,可以使分类器对数据的扰动具有更强的鲁棒性。位于间隔边界以外的点,这些点对分类超平面的确定没有直接影响,不是支持向量,去掉非支持向量不影响分类结果。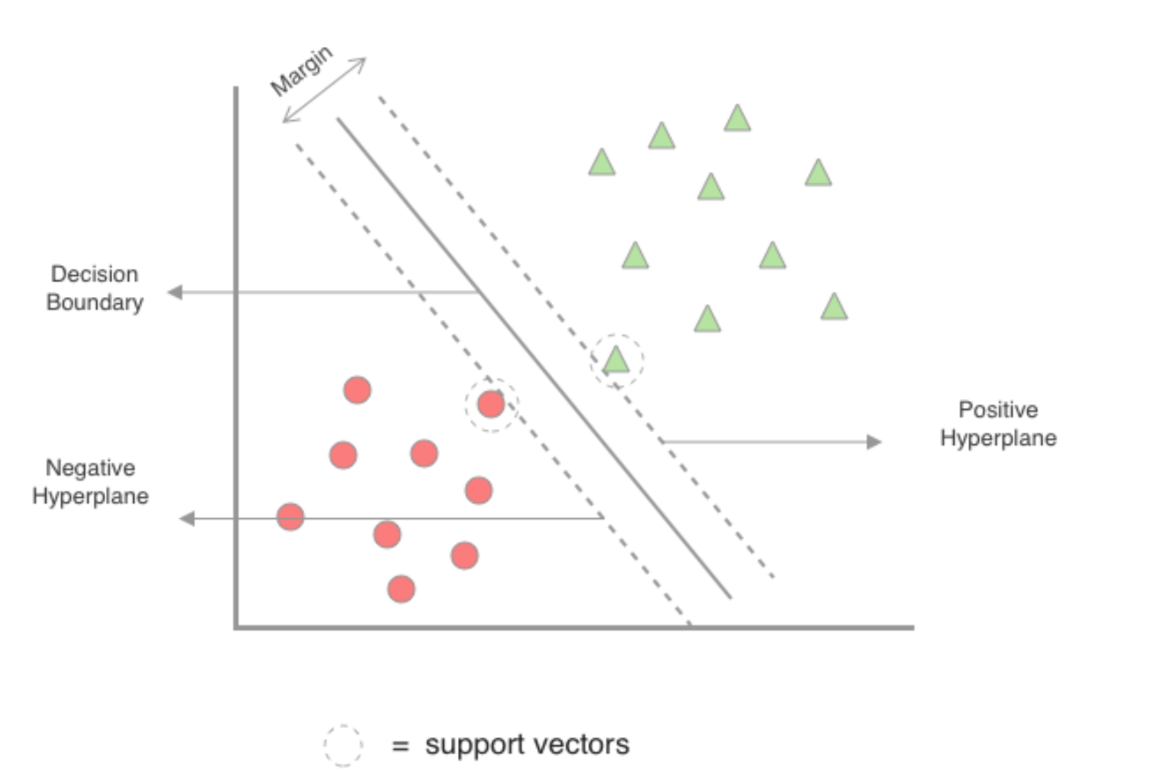
3.引入核函数:
当数据在原始特征空间中线性不可分时,SVM 通过引入核函数将数据映射到更高维的特征空间,使得在新的特征空间中数据变得线性可分。核函数可以在不直接计算高维特征空间中内积的情况下,实现将数据从低维空间映射到高维空间的效果,从而巧妙地解决了线性不可分的问题。
4.求解最优解:
将寻找最优超平面的问题转化为一个凸二次规划问题,通过求解这个优化问题,可以得到最优的超平面参数 w 和 b 。在求解过程中,通常会使用拉格朗日乘子法将原问题转化为其对偶问题进行求解,这样可以更方便地处理约束条件,并利用核函数的性质进行计算。
6.进行分类决策:
得到最优超平面后,对于新的待分类数据点x,通过计算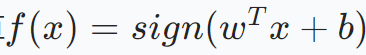 的值来判断其所属类别。如果f(x)=+1,则将x归为正类;如果f(x)=−1,则将x归为负类。
的值来判断其所属类别。如果f(x)=+1,则将x归为正类;如果f(x)=−1,则将x归为负类。
代码示例
实现 SVM 算法解决二分类问题(鸢尾花)主要步骤( 使用Python 和scikit-learn库实现):
加载数据集:使用datasets.load_iris()加载鸢尾花数据集,并选取前两类数据用于二分类任务。
划分数据集:使用train_test_split函数将数据集划分为训练集和测试集,其中测试集占比为 30%。
创建 SVM 分类器:使用SVC类创建一个线性核的 SVM 分类器。
训练模型:使用训练集数据对 SVM 模型进行训练。
进行预测:使用训练好的模型对测试集数据进行预测。
评估模型:使用accuracy_score函数计算模型的准确率并输出。
python
# svm_binary_classification.py
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 取前两类数据(数据太多,导前100条)
X = iris.data[:100]
y = iris.target[:100]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
# 创建 SVM 分类器实例
svm_classifier = SVC(kernel='linear')
# 训练模型
svm_classifier.fit(X_train, y_train)
# 进行预测
y_pred = svm_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型的准确率: {accuracy:.2f}")