第十三届国际学习表征会议(ICLR 2025)于2025年4月24日至28日在新加坡博览中心隆重举行。ICLR是深度学习与表示学习领域的顶级国际会议之一,与NeurIPS和ICML并称为机器学习三大旗舰会议。
自2013年创办以来,ICLR每年举办一次,采用开放式同行评审机制,致力于推动人工智能、统计学、数据科学等领域的前沿研究。会议内容涵盖无监督、半监督和监督学习、强化学习、计算机视觉、自然语言处理、图神经网络、优化理论、可解释性、隐私保护、可持续性等多个方向。
本文详细介绍了论文《PointOBB-v2: Towards Simpler, Faster, and Stronger Single Point Supervised Oriented Object Detection》,该论文已被第十三届国际学习表征会议(ICLR 2025)接收,论文的第一作者为任博韬
该论文提出了一种改进的单点监督有向目标检测方法------PointOBB-v2。该方法通过生成类别概率图(Class Probability Map, CPM)并应用主成分分析来估计目标的方向和边界,无需依赖任何先验信息。此外,作者引入了分离机制,以解决高密度场景中目标重叠带来的混淆问题。实验结果表明,PointOBB-v2在DOTA-v1.0、v1.5和v2.0数据集上,相较于前沿方法PointOBB,训练速度提升了15.58倍,精度分别提高了11.60%、25.15%和21.19%。
本推文由任博韬撰写,审校为邓镝。
原文链接 :https://arxiv.org/abs/2410.08210
代码链接 :https://github.com/taugeren/PointOBB-v2/
实验室主页 :http://yangxue.site/
一、研究背景及主要贡献
有向目标检测在对小目标和密集目标进行精确标注中具有重要意义,特别是在遥感图像、零售场景分析、场景文字检测等应用中,有向边界框能够提供更精准的标注。然而,有向边界框(Oriented Bounding Box, OBB)的标注过程十分耗时且成本高昂,因此近年来涌现出大量弱监督方法,包括使用水平框监督和点监督的方法。代表性的水平框监督方法有H2RBox和H2RBox-v2,而点监督方法仅需为每个目标标注一个点及其类别,进一步降低了标注成本。当前主流的点监督方法主要包括P2RBox、Point2RBox和PointOBB等。
现有的点监督有向目标检测方法大致可分为三类:(1)基于SAM的方法依赖于强大的SAM模型,虽然在自然图像中效果良好,但在跨领域任务(如遥感图像)中,尤其是小目标和密集目标场景下表现有限,且由于后处理过程导致速度慢、内存消耗大;(2)基于先验的弱监督有向目标检测(Weakly Supervised Oriented Object Detection, OOD)方法通过引入人工先验来实现,但不同数据集需要不同的先验知识,降低了泛化能力,同时端到端设计也限制了方法的灵活性;(3)模块化的WOOD方法则摆脱了人工设计的先验,通过将伪标签生成与检测器解耦,实现了更高的灵活性与可扩展性,PointOBB即属于该范式的代表方法。
作为上一代的代表性方法,PointOBB虽然在模块化WOOD中具备一定优势,但仍存在实际应用中的不足:其伪标签生成过程极为缓慢(约为后续检测器训练时间的7-8倍),同时由于多视角变换导致显著的显存消耗,在密集目标场景中易出现显存溢出的问题。为避免溢出,需要限制候选感兴趣区域的数量,但这会导致性能下降。
针对上述问题,本文提出了PointOBB-v2方法,旨在设计一种更简单、更快速、更高效的点监督有向目标检测方法,在继承模块化WOOD优势的同时,解决PointOBB在速度和内存消耗上的瓶颈,使其更适用于实际应用场景。
文章的贡献主要为:
- 1)提出了一种新颖高效的点监督有向目标检测管道,摒弃了耗时耗存的教师-学生结构,显著提升了伪标签生成速度并降低了内存占用。
- 2)方法无需额外深度网络设计,仅依赖类别概率图生成精准的目标轮廓,并通过高效的主成分分析确定目标方向和边界,同时设计了矢量约束方法以区分密集场景下的小目标,提升检测效果。
- 3)实验结果显示,本文方法在多个数据集上持续优于PointOBB,在DOTA-v1.0/v1.5/v2.0数据集上分别取得11.60%/25.15%/21.19%的mAP提升,伪标签生成速度提升15.58倍,内存占用降低至约8GB且无需限制候选感兴趣区域的数量。
二、方法
-
-
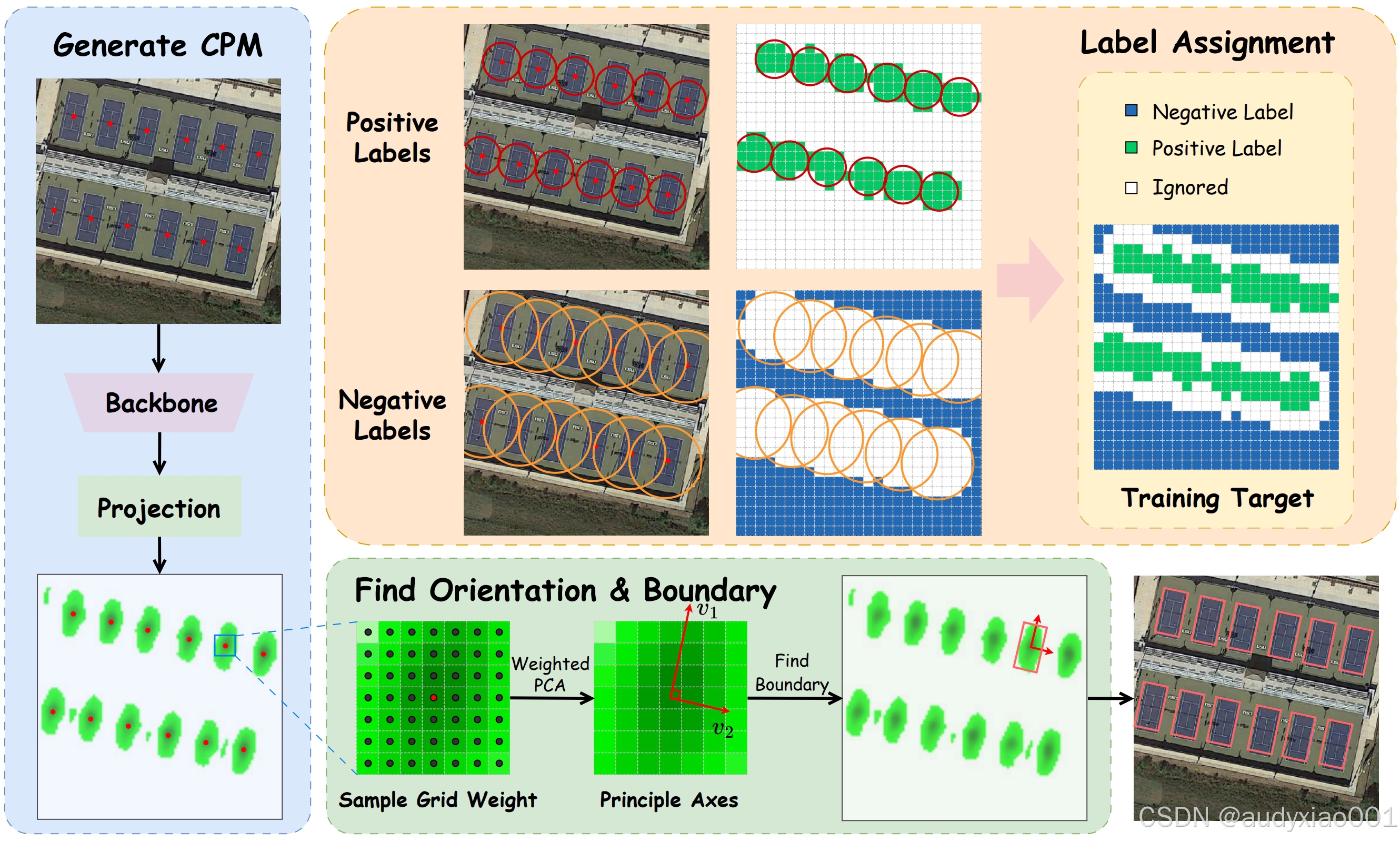
图1 PointOBB-v2的整体架构
-
PointOBB-v2分为三个步骤。首先,利用点标注生成类别概率图(CPM, Class Probability Map),并通过正负样本分配策略使得网络生成的CPM能够勾画物体轮廓。然后,通过非均匀采样和加权概率方法,从CPM中生成伪旋转边界框,并应用主成分分析推断物体方向。最后,使用生成的伪标签来训练一个已有的检测器(例如Oriented RCNN等)。此外,为了处理密集物体场景,引入区分相邻物体的机制,确保物体间的有效分离。
类别概率图(Class Probability Map, CPM)表示特征图上每个点的类别概率,其值介于 0, 1 之间。为了生成 CPM,模型首先将维度为的图像输入到一个ResNet50 + FPN中进行处理。随后取FPN中分辨率最高的特征图,通过投影层生成的CPM。
在获得类别概率图CPM后,根据类别概率在每个GT周围采样点,并对这些采样点应用主成分分析,以确定目标的方向。如模型图的底部所示,模型以真实目标为中心,在其周围基于CPM中对应目标类别的概率进行采样。具体而言,选择一个以真实目标为中心的7×7网格。对于每个网格点, 模型按照CPM权重加权到每个坐标点上,随后求出加权后坐标点的协方差矩阵。接着采用主成分分析得到两个方向的特征向量,对应于伪标签的长轴和短轴的方向。在确定了主要方向和次要方向后,沿着这些方向确定目标的边界。从中心点开始,沿着每个方向移动,当某个位置的值低于阈值时停止,该位置即为目标的边界。
在密集场景中,CPM会有相互连接的问题,所以即使找到了正确的方向,也有可能无法找到准确的边界。模型使用了一种简单的约束方法:对于每个真实目标
,我们首先找到与其最近的同类目标
-
-
其中,
-
上述方法得到伪标签后,用这些标签训练一个检测器(例如Oriented RCNN),最后使用训练好的检测器进行推理。
## 三、实验-
(1)实施细节
-
本文在四个公开数据集上进行了评估,包括DOTA-v1.0、DOTA-v1.5、DOTA-v2.0、RSAR和SKU110K-R。DOTA系列是面向遥感图像的目标检测数据集,包含多种目标类别和不同尺度的复杂场景:DOTA-v1.0包含2,806张图像和188,282个目标实例,DOTA-v1.5在此基础上增加了极小目标和新类别,共计403,318个实例,DOTA-v2.0进一步扩展到11,268张图像和1,793,658个实例。RSAR为面向SAR图像的旋转目标检测数据集,包含95,842张图像和183,534个标注实例。SKU110K-R则聚焦于零售场景中的密集目标检测,包含11,762张图像和110,712个标注实例。
实现方面,本文基于MMRotate库进行开发。在伪标签生成阶段,采用动量SGD优化器训练6个epoch,权重衰减设置为1e-4,初始学习率为0.005,在第4个epoch后衰减10倍,批大小为2。检测器的训练阶段使用MMRotate默认配置,数据增强仅使用随机翻转。所有实验均在两张GeForce RTX 3090显卡上完成。
-
(2)实验结果
-
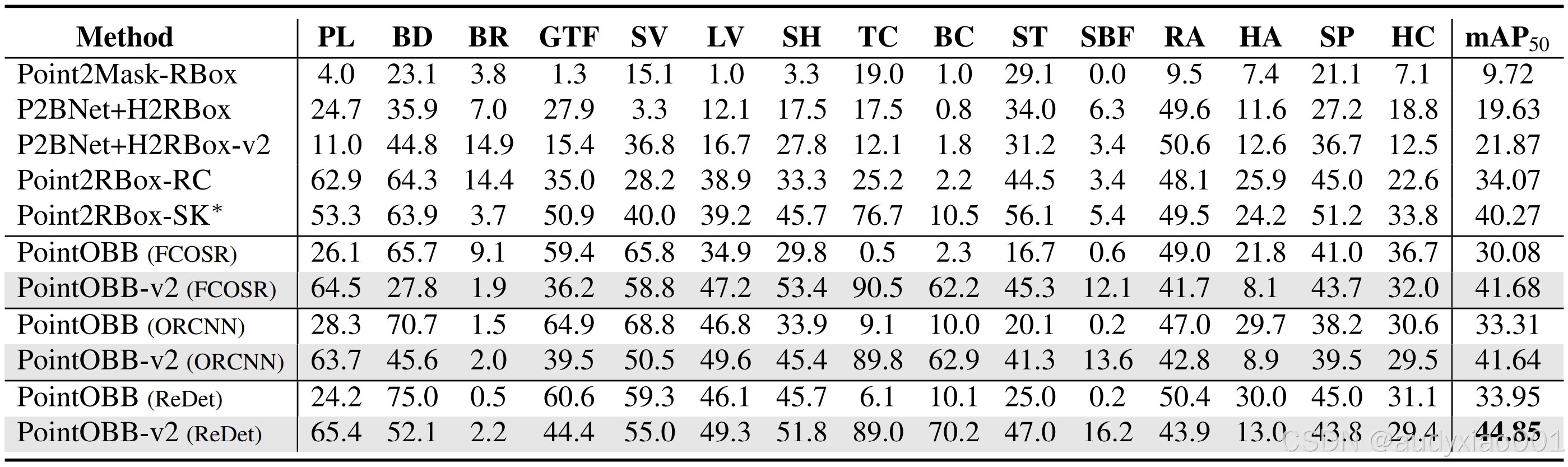
在DOTA-v1.0数据集上,本文方法在多个检测器下均取得了领先的性能。如表1所示,本文方法在三种不同检测器下分别获得了41.68%、41.64%、44.85%的mAP50,相比于PointOBB分别提升了11.60%、8.33%、10.90%。与不依赖人工先验知识的Point2RBox-RC相比,本文方法提升了10.78%;即便与引入手绘辅助边界的Point2RBox-SK相比,仍有4.58%的提升,证明了方法在无需人工先验的情况下依然具有强大的鲁棒性与有效性。
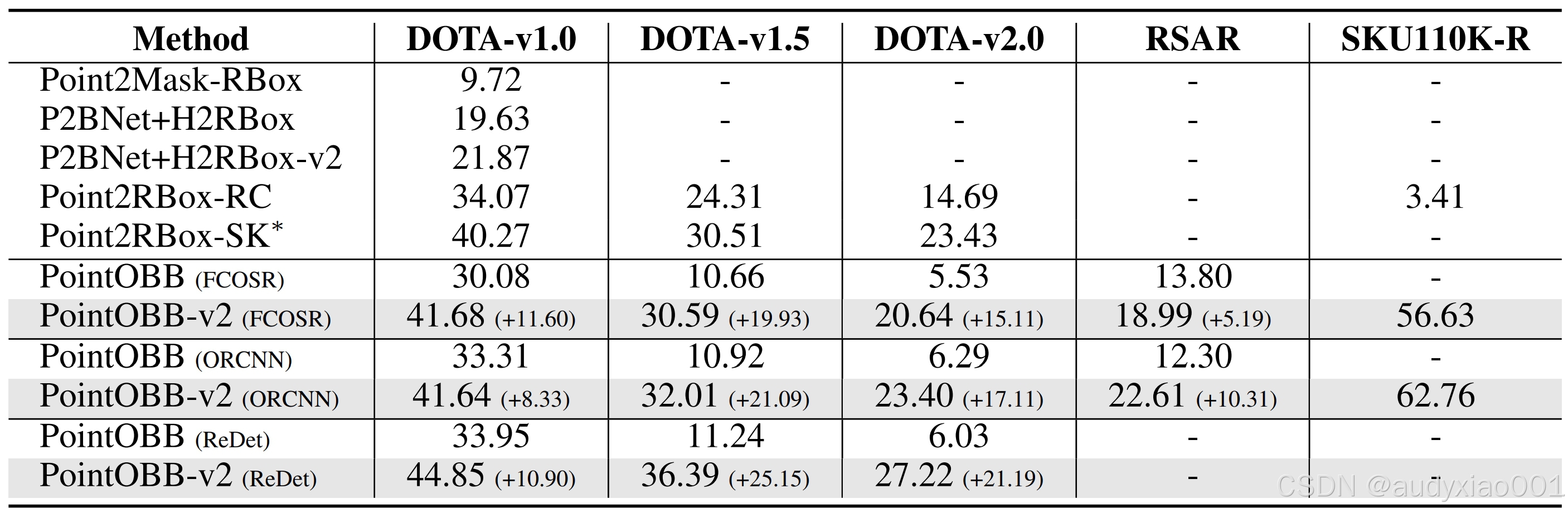
在更具挑战性的DOTA-v1.5与DOTA-v2.0数据集上,本文方法同样展现出显著优势。如表2所示,面对更多密集且小尺度目标的场景,本文方法通过引入的分离机制,有效缓解了伪标签生成过程中的目标混淆问题。在使用ReDet训练的情况下,本文方法在DOTA-v1.5和DOTA-v2.0上分别取得了36.39%和27.22%的mAP,分别较PointOBB提升了25.15%和21.19%,相较于DOTA-v1.0上的提升(10.90%)进一步扩大。此外,本文方法在DOTA-v1.5和DOTA-v2.0上均优于Point2RBox,即便面对融入人工先验知识的Point2RBox-SK,仍分别提升了5.88%和3.79%。
-
表1 PointOBB-v2在DOTA-v1.0上的实验结果
-
-
表2 PointOBB-v2在各个数据集上的实验结果
-
-
表3 PointOBB-v2在DOTA-v1.0上的训练时间
-

-
在计算资源方面,本文方法同样展现出更优的效率。由于采用了单分支结构,省去了教师-学生框架及多视角变换等设计,显著降低了计算开销。如表3所示,伪标签生成阶段仅需1.43小时,相比PointOBB的22.28小时快了15.58倍。在显存占用方面,本文方法在处理DOTA-v2.0等密集场景时的内存需求约为8GB,适配绝大多数GPU设备,而PointOBB在此场景下存在显存溢出问题,必须限制RoI提议数量才能运行,但这种限制会导致小目标漏检,严重影响性能。
## 四、总结与展望- 本文提出了PointOBB-v2,一种更简单、更快速、更高效的单点监督有向目标检测方法。该方法通过引入类别概率图和主成分分析来估计目标的方向与边界,摒弃了传统的教师-学生结构,从而大幅降低了时间与内存消耗。实验结果表明,PointOBB-v2在DOTA-v1.0、DOTA-v1.5、DOTA-v2.0等多个数据集上均显著优于现有方法,在训练速度上提升了15.58倍,在精度上分别提升了11.60%、25.15%、21.19%,尤其在小目标和密集场景中表现出更强的鲁棒性与优势。方法在提升检测精度的同时,兼顾了速度和内存效率,展现了良好的实用性与推广潜力。