
🌿自动化的思想
任何领域的发展原因------------"不断追求生产方式的改革,即使得付出与耗费精力越来愈少,而收获最大化"。由此,创造出方法和设备来提升效率。
- 如新闻的5W原则直接让思考过程规范化、流程化。
- 或者前端框架/后端轮子的出现,使得构建项目可以自动化,减少了不必要劳动。
- 爬虫也是如此,主要是为了执行自动化搜集、筛选信息的行为。比如想下载一个网站的所有壁纸图片,人工操作太麻烦,而使用爬虫可以自动化这一系列的操作。
一些计算机思想
- 自动化思维:所以,作为一个前后端开发者,面对问题,自动化思想总是很有用的,面对问题,下意识思考是否可以自动化会使得效率提升(当然,也要评估性价比)。
- 性价比思想:不是可以改进效率的方法就值得被推崇,在实际生产中,一些方法理论上可以改进效率,但也要考虑改革的成本。我们的目的是追求最终结果的极致性价比。(这是因为,生产领域必然要考虑除了理论外的其他现实因素,这也是项目/思想能否较好落地的因素。
🍂爬虫的出现与自动化前提
爬虫的出现是对web信息处理这一过程的自动化实现。
自动化的局限
在当下,计算机/设备只能对信息进行
规定好的、有限的思考和计算,不像人脑可以处理、自主学习。
- 题外话:(AI大模型看起来像人类,但背后是机器学习的那套,本身不具备思考能力,而是预测能力。在给足了充足的信息后,用户的行为和偏好很容易预测(如,视频推荐算法也是类似思想),由此,远没有自主思考的产生。)
自动化的前提
不是所有解决问题的方法都可以自动化,重复的,有规律的才可以。
- 举例:爬虫:获取网页信息,下载。/密码爆破:不断输入密码,尝试。
🌿爬虫
🍂定义
网络爬虫,是一种按照一定的规则,自动地在互联网上浏览网页并获取信息的程序或者脚本。
网络爬虫:与网络有关,由此要了解计算机网络知识网页:万维网(一种在互联网上面向大众提供的服务,一个基于超文本 的信息检索系统,通过互联网将全球的计算机网络连接起来,使用户能够通过浏览器访问和浏览网页。)
超文本:即把一切资源以web形式呈现,由此,需要了解HTTP相关知识(推荐书籍:《HTTP图解》)
🍂爬虫原理理解
● 一般流程
网络(互联网连接)`PC完成` ------------------> 服务器连接`PC、浏览器完成` ------------------> HTTP请求发起`浏览器完成` ------------------> HTTP请求发送给服务器`PC完成` ------------------> 服务器返回包接收、拆包`PC完成` ------------------> web内容分析、渲染、展现`浏览器完成`
解释
PC连接上互联网后,再连接到服务器,向它发起HTTP服务请求,服务器在没问题的情况下返回它所需要的内容。
- 连接互联网有PC的网络模块与系统应用完成,而不是它上面的第三方应用。没有PC的网络模块支持,应用也上不了网。即Pc网络模块(硬件)才是一切的基础。
- 常见使用过程中,发起请求的功能由浏览器代替用户执行,从而生成HTTP请求。而爬虫要自己发起,由此要编写一个可以像服务器发送HTTP请求的代码喽。
- 请求的接收:常见的也是由PC接收后解析。而爬虫只要有用的信息,所以自己自定义解析规则,写一个自动化解析的代码。
● 使用了爬虫的自动化流程
两种方式对比总结:
- 手动: 手动发起HTTP请求,依靠浏览器解析得到的web内容,用户直接观看。
需要用户一次次的点击。- 爬虫: 爬虫自动发起HTTP请求,自动接收内容,自动处理拆包,自动分析提取需要的内容,自动存储内容。
能用循环实现自动化重复操作,不需要人一个个点击且比人快得多本质就是把手动的全部过程都用代码表达了,而写加上了筛选规则和循环,使得爬虫可以不用手动控制(因为循环)的自主完成对内容的筛选(因为筛选规则)。
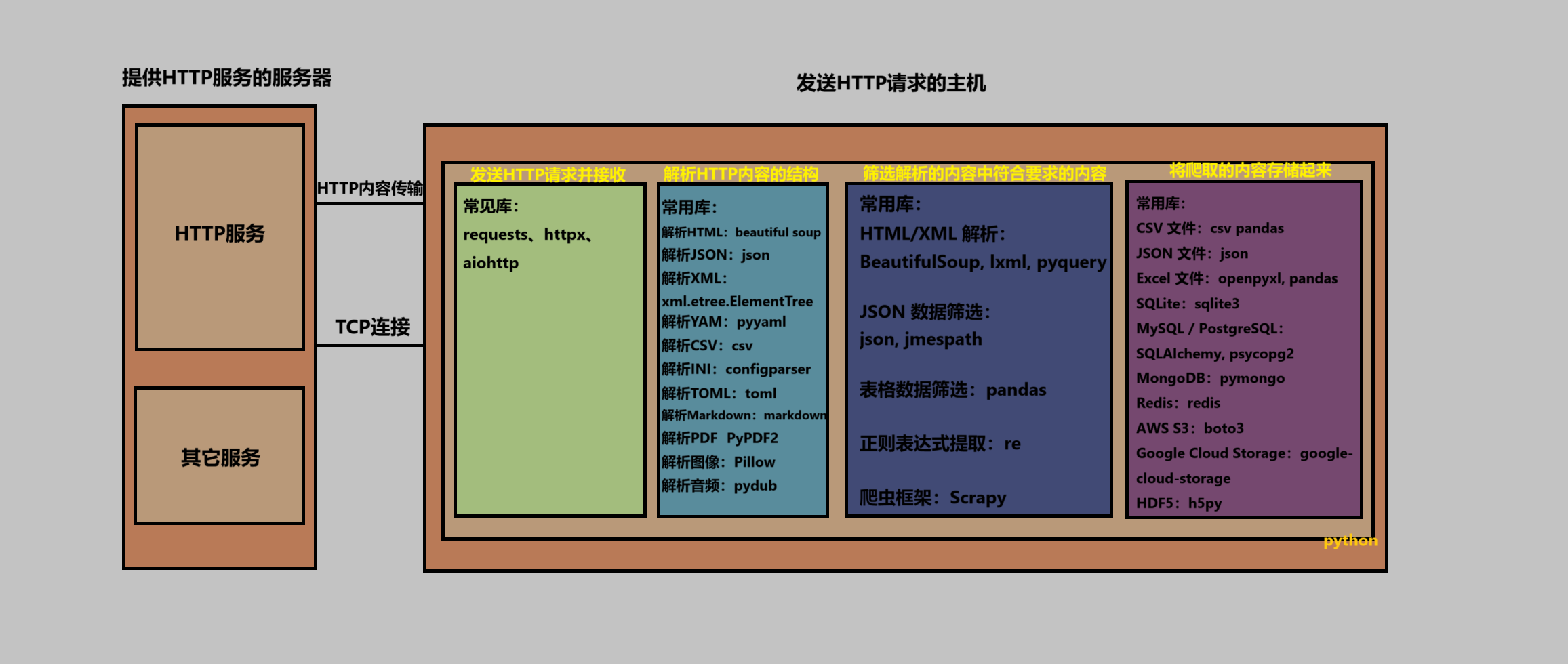
● 配套图
服务器与PC(python爬虫在PC上是如何实现的:相关库以及作用)
解释了爬虫流程:发送HTTP请求------>解析web内容------>筛选内容------>存储内容
以及PC与服务器上的HTTP服务的交互
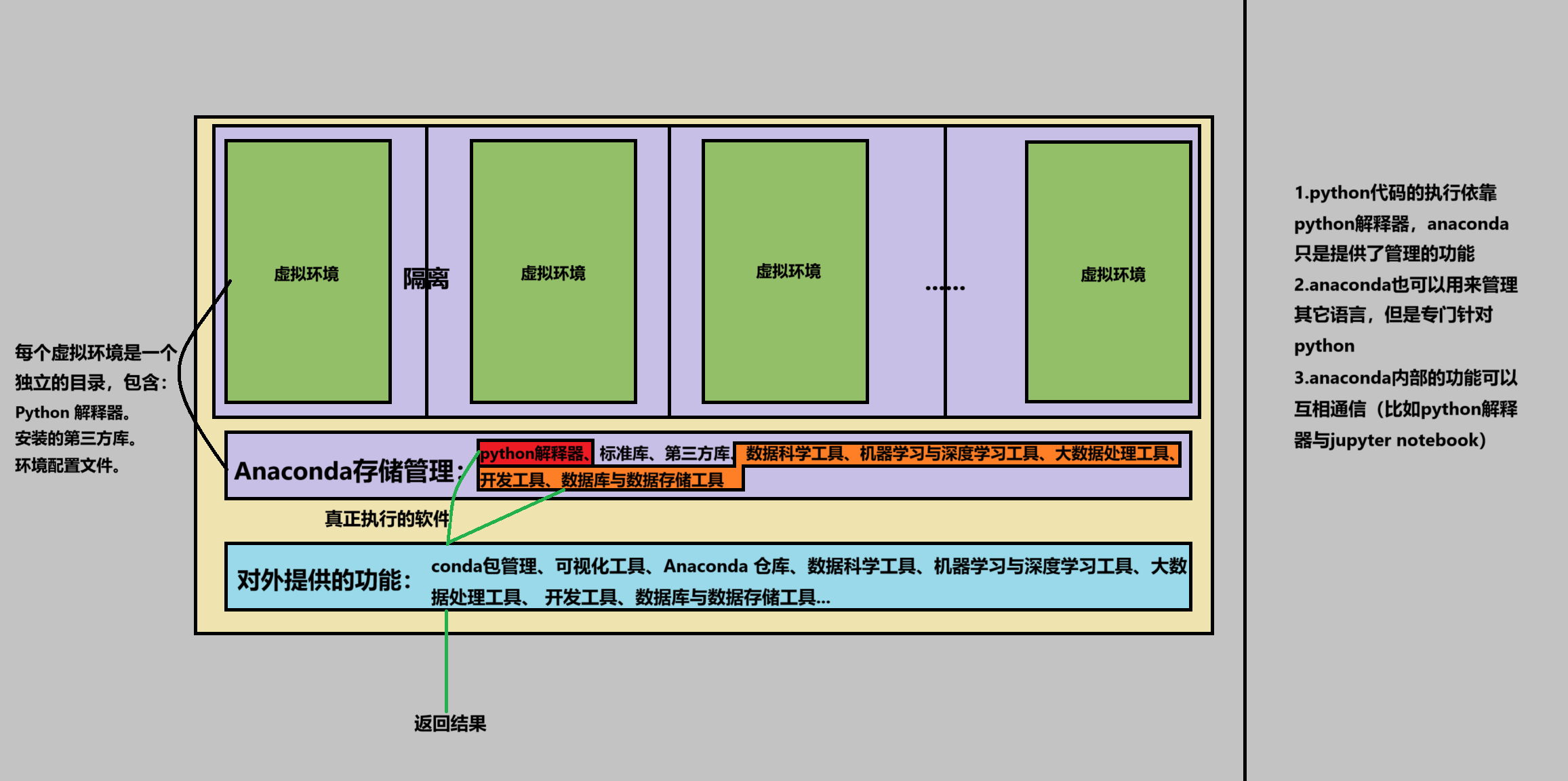
anconda的原理
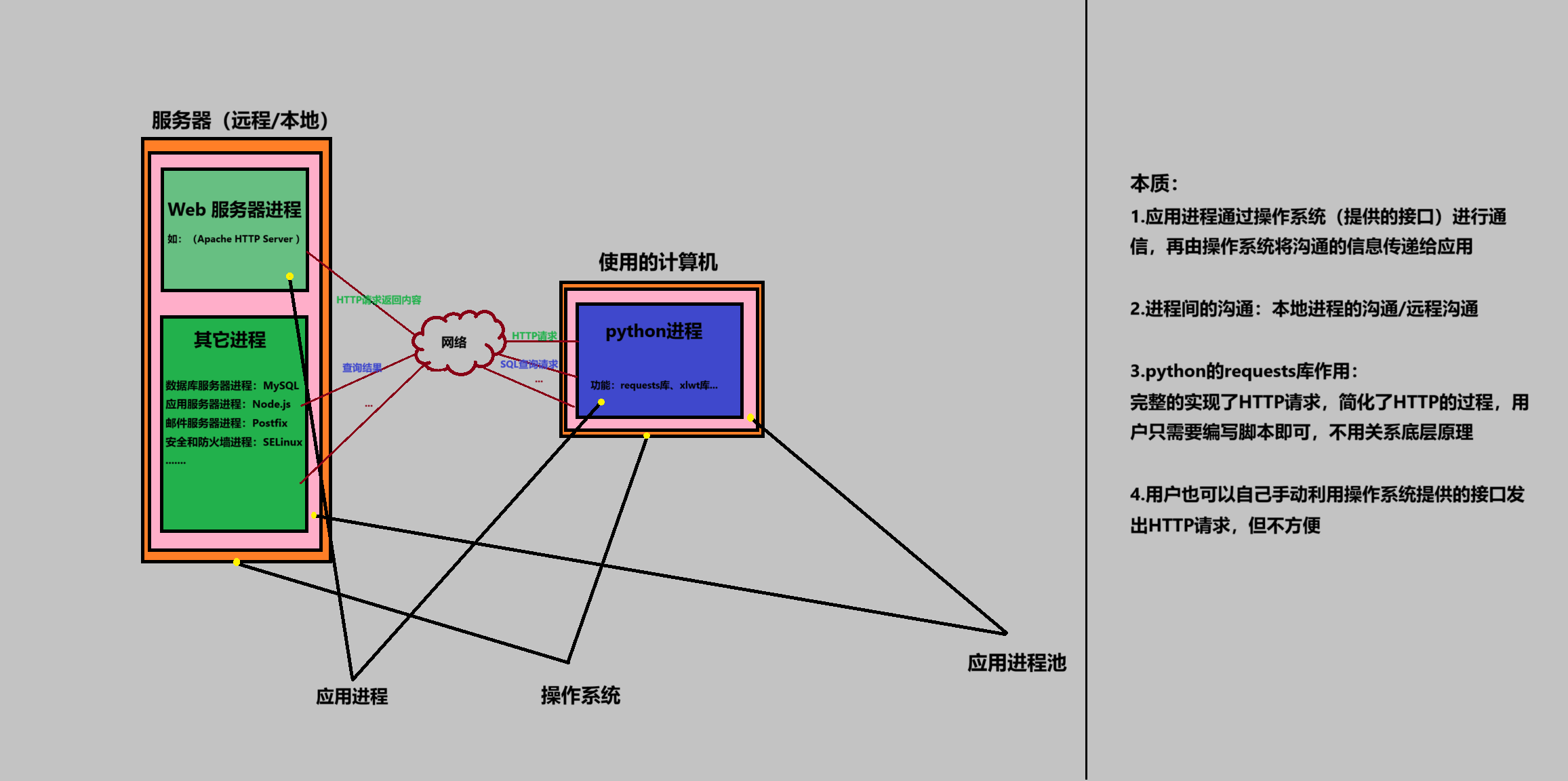
python进程下的爬虫即本质是进程间的交互,服务器提供HTTP服务的进程与Pc上爬虫进程的交互
涉及到网络分层模型
服务器提供的服务多种多样,除了HTTP服务还有SQL数据库服务。即PC可以使用服务器提供的多种服务,根据提供的服务不同,应用层发送的内容不同(万维网服务为web数据,数据库服务为数据库文件...)
🍂爬虫要注意啥
法律法规
合法性:不是所有资源都可以爬取,要遵守相关法律法规,保护自己也保护他人恶意爬虫:指不遵守法规且用技术来掩盖自己的踪迹,使得追查起来困难或者不可行爬虫与背后的流量请求
提供服务要消耗资源(电费、设备维护、域名、IP费用...),而每次的爬虫请求会与目标服务器交互,由此产生消耗,同时也会占据资源,影响正常用户的使用(最典型的例子:12306抢票)。由此,会给服务商提供负担。
- 无论是作为服务商或者用户,过度使用爬虫对双方都毫无意义,只有负向收益。而且,使用爬虫爬取没用信息对程序员也没啥用啊(😏毕竟要网络攻击有别的方法)
🍂一个入门例子
使用爬虫爬取豆瓣电影排行榜,感受自动化过程(本站就有教程,自行搜索,关键在于配置python环境,代码复制下来就能跑)
🌿学习爬虫的准备
🍂环境配置
本质上,你需要了解一种图灵完备语言(指的是python、Java...),但常见的用python,变成语言各有所长,而python在这方面最好用。
所以,下载python并且下载相关库
- 推荐内容 :
- anaconda(管理多版本python、隔离环境,允许不同项目支持不同python版本、机器学习初学的好软件)
- 环境变量(了解环境变量的作用)
- 理解文件相对路径、绝对路径以及CMD当前运行位置不同对应的不同影响
🍂理论知识
● 最基础前提
- 基本的网络知识:重要程度⭐⭐⭐⭐⭐
爬虫的精髓所在,在得到文件后就好处理(你瞪眼法人工分析也可以😏),关键是如何请求,如何得到。所以,这部分最重要。
● 次要基础
- HTTP协议基础:重要程度⭐⭐⭐
了解这个,才能在代码里模拟浏览器发送HTTP请求,实现发送请求自动化(一般是浏览器检测用户点击一次才发一次请求,我们要让这个过程自动化)
● 最末流基础
- Python编程基础:重要程度⭐⭐
至少有编程语言基础,python就可以边写爬虫边学了。(不然还要建立编程语言的基础,学习爬虫会困难一点)
- HTML和CSS基础:重要程度⭐⭐
因为爬虫代码涉及到对这些元素的分析,不懂标签,得到文件也看不懂,更别提爬取了