一、向量空间的可视化解码
1.1 GloVe 词向量实例
取词向量维度 d = 50 d=50 d=50 的 GloVe 嵌入示例:
python
king_vec = [[0.50451, 0.68607, -0.59517, -0.022801, 0.60046, -0.13498, -0.08813, 0.47377, -0.61798, -0.31012, -0.076666, 1.493, -0.034189, -0.98173, 0.68229, 0.81722, -0.51874, -0.31503, -0.55809, 0.66421, 0.1961, -0.13495, -0.11476, -0.30344, 0.41177, -2.223, -1.0756, -1.0783, -0.34354, 0.33505, 1.9927, -0.04234, -0.64319, 0.71125, 0.49159, 0.16754, 0.34344, -0.25663, -0.8523, 0.1661, 0.40102, 1.1685, -1.0137, -0.21585, -0.15155, 0.78321, -0.91241, -1.6106, -0.64426, -0.51042]
] # 50维向量资料推荐
1.2 矩阵热力图编码
采用分段颜色映射策略:
数值范围:−2,2
颜色映射:蓝色(-2)→ 白色(0)→ 红色(+2)

我们忽略数字仅查看颜色,并且将"King"与其他单词进行比较(King 国王、Man 男人、Woman 女人):
从色块分布图中,可以很容易的看出 King、Man、Woman 这三组向量的结构其实非常接近,色块颜色非常集中,这是否能意味着国王、男人、女人这三个词之间是具有强关联甚至是子集的因果关系。
接下来看下另外一个示例列表,这个示例展示了更多单词的向量分布的规律: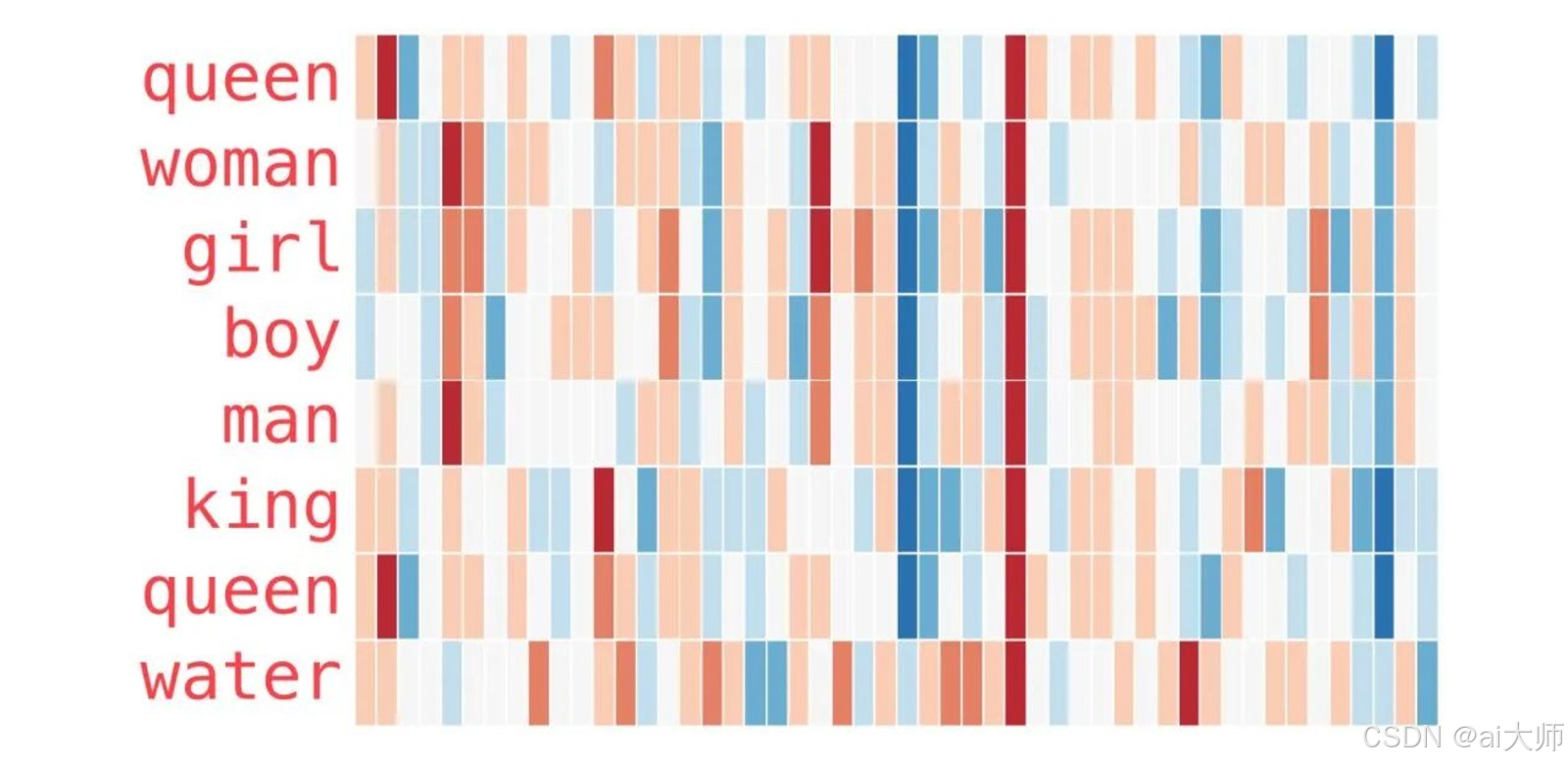
在这张分布图中也可以轻松看出一些信息:
- 这几个单词的词向量在中间都有一条直的红色列,代表它们在这个维度上是相似的,但是从数值来看我们看不出这个维度是什么。
- woman 和 girl 在很多地方都是相似的,man 和 boy 也一样。
- girl 和 boy 也有一些彼此相似的地方,但这些和 woman/girl 不同,这些差异是否可以总结出"年龄"这个维度?
- 上面的单词中,除了 water 其他的都和人相关,并且向量的倒数第三个元素是一个蓝色的色块,来到 water 这里却消失了。
- king 和 queen 非常接近,但是存在一些比较明显的差异,这部分差异是否能体现出"性别"这个维度?
除了单个词的向量能展示出一些有意思的信息,对向量进行 加减乘除 也能得到一些有意思的结果。在 NLP 界有一个非常著名的公式:
python
Queen = King - Man + Woman
女王 = 国王 - 男人 + 女人对这几个向量进行运算后,同样可视化出来,结果如下: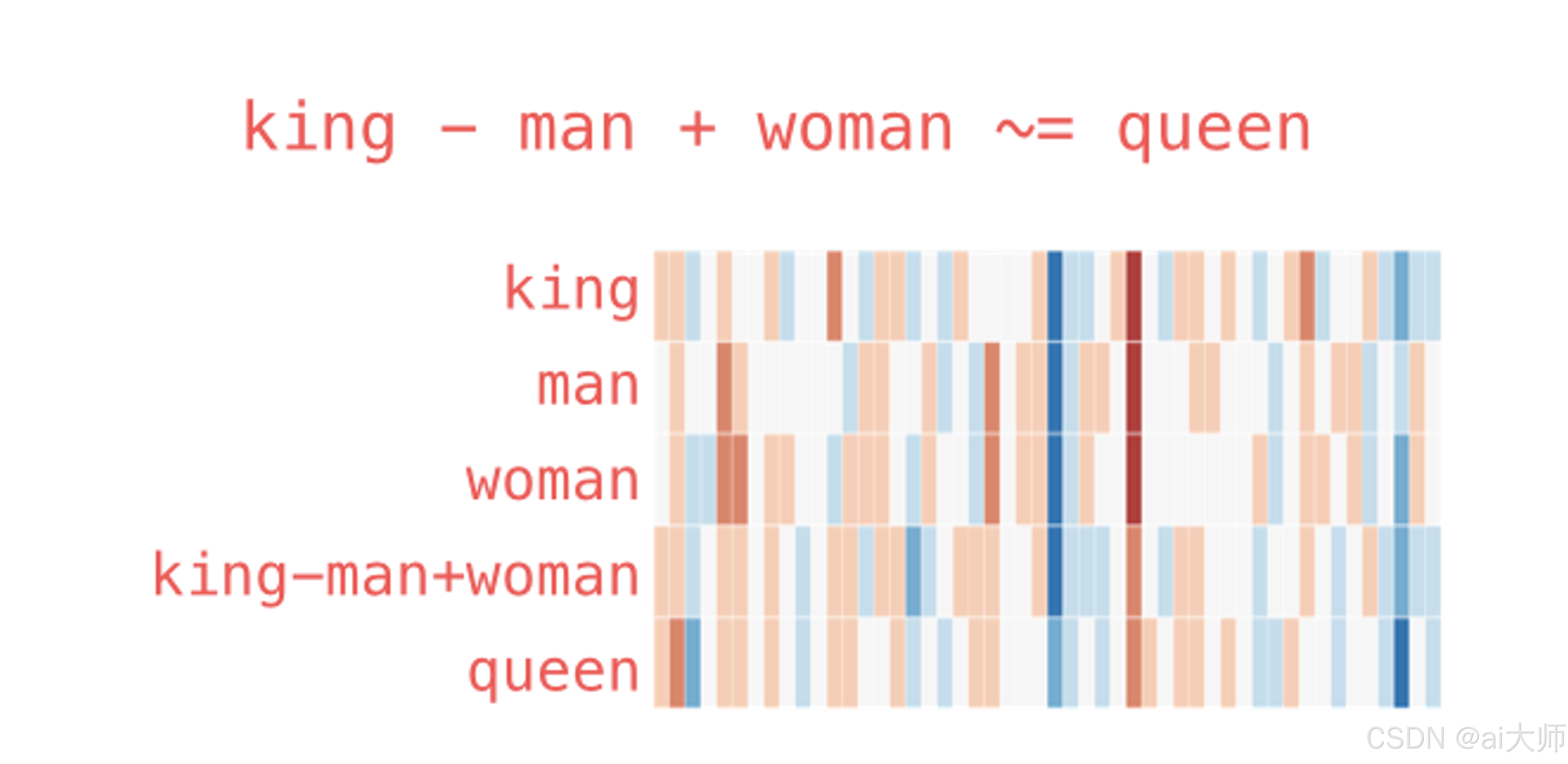
你会发现 king-man+woman 和 queen 的向量特征分布非常接近,也是 GloVe 集合中 40w 个字嵌入中最接近它的词。
资料推荐
这一个示例虽然不一定是一个正确的思路,但是从这个示例中仍然可以看到将对应的词转换成 Embedding 向量后,嵌入模型能够捕捉到数据的语义信息,并且语义上相近的词在向量空间中也会相近,这也为语义搜索提供了一个可能。