文章目录
-
- [1. 相关资源](#1. 相关资源)
- [2. 核心特性](#2. 核心特性)
- [3. 安装与部署](#3. 安装与部署)
-
- [3.1 环境准备](#3.1 环境准备)
- [3.2 部署RagFlow](#3.2 部署RagFlow)
- [3.3 更新RagFlow](#3.3 更新RagFlow)
- [3.4 系统配置](#3.4 系统配置)
- [4. 接入本地模型](#4. 接入本地模型)
-
- [4.1 接入 Ollama 本地模型](#4.1 接入 Ollama 本地模型)
-
- [4.1.1 步骤](#4.1.1 步骤)
- [4.1.2 常见问题](#4.1.2 常见问题)
- [4.2 接入 VLLM 模型](#4.2 接入 VLLM 模型)
- [5. 应用场景](#5. 应用场景)
- [6. 总结](#6. 总结)
1. 相关资源
2. 核心特性
- 🍭 "Quality in, quality out"
- 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。
- 真正在无限上下文(token)的场景下快速完成大海捞针测试。
- 🍱 基于模板的文本切片
- 不仅仅是智能,更重要的是可控可解释。
- 多种文本模板可供选择。
- 🌱 有理有据、最大程度降低幻觉(hallucination)
- 文本切片过程可视化,支持手动调整。
- 有理有据:答案提供关键引用的快照并支持追根溯源。
- 🍔 兼容各类异构数据源
- 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
- 🛀 全程无忧、自动化的 RAG 工作流
- 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。
- 大语言模型 LLM 以及向量模型均支持配置。
- 基于多路召回、融合重排序。
- 提供易用的 API,可以轻松集成到各类企业系统。
3. 安装与部署
3.1 环境准备
-
依赖工具 :安装 Docker 与 Docker Compose。
-
系统要求:
bash# 查看vm.max_map_count值,要求其不能小于 262144 sysctl vm.max_map_count # 小于的话,进行设置 sudo sysctl -w vm.max_map_count=262144 # 永久生效,修改 /etc/sysctl.conf vim /etc/sysctl.conf # 修改文件中以下内容 vm.max_map_count=262144
3.2 部署RagFlow
bash
cd ~/workspace/ai/tools && git clone --depth 1 https://github.com/infiniflow/ragflow.git && cd ragflow/docker
# 使用CPU
# docker compose -f docker-compose.yml up -d
# 使用GPU
docker compose -f docker-compose-gpu.yml up -d
# 确认服务器状态
docker logs -f ragflow-server默认通过 http://localhost 即可访问 RagFlow 控制台,首次登录需要设置管理员密码。
3.3 更新RagFlow
bash
# 更新 RagFlow
docker compose down
git pull origin main
docker compose pull
docker compose -f docker-compose-gpu.yml up -d3.4 系统配置
-
系统配置涉及以下三份文件:
.env:存放一些基本的系统环境变量,比如 SVR_HTTP_PORT、MYSQL_PASSWORD、MINIO_PASSWORD 等。service_conf.yaml.template:配置各类后台服务。docker-compose.yml: 系统依赖该文件完成启动。
请务必确保.env文件中的变量设置与service_conf.yaml.template文件中的配置保持一致!
-
如果不能访问镜像站点
hub.docker.com或者模型站点huggingface.co,请按照.env注释修改RAGFLOW_IMAGE和HF_ENDPOINT。 -
./docker/README解释了service_conf.yaml.template用到的环境变量设置和服务配置。 -
如需更新默认的
HTTP服务端口(80), 可以在docker-compose.yml文件中将配置80:80改为<YOUR_SERVING_PORT>:80。 -
所有系统配置都需要通过系统重启生效
docker compose -f docker-compose-gpu.yml up -d。
4. 接入本地模型
笔者实验环境为 Ubuntu24.04,宿主机启动 Ollama 服务 + Docker Compose部署 RagFlow
4.1 接入 Ollama 本地模型
4.1.1 步骤
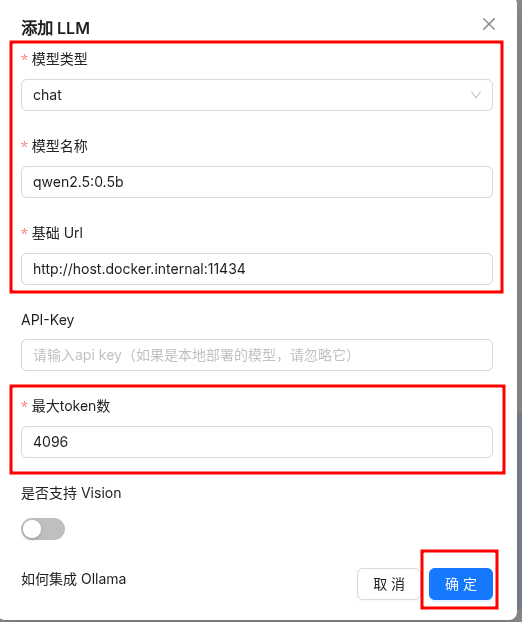
- 点击
RagFlow平台右上角头像→模型供应商,选择Ollama,点击添加模型。 - 选择
模型类型,输入模型名称、基础URL、最大token数,其他选项可使用默认设置即可,点击确定。其中:模型名称为 Ollama 服务中的模型名称,可通过ollama list获取

基础URL为 Ollama 服务地址,例如http://host.docker.internal:11434
4.1.2 常见问题
-
Connection refused问题
使用官方文档中的
http://host.docker.internal:11434作为基础URL,可能会出现httpconnectionpool (host=localhost, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError ('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))错误,此时需要直接使用宿主机的IP地址。 -
解决步骤:
-
设置 Ollama 服务监听地址
bash# 修改 ollama.service 文件,添加 OLLAMA_HOST 环境变量 sudo vim /etc/systemd/system/ollama.service # 在 [Service] 下添加 Environment="OLLAMA_HOST=0.0.0.0:11434" # 重新加载配置文件 sudo systemctl daemon-reload sudo systemctl restart ollama # 查看服务状态,确保 ollama 服务以 :::11434 启动 sudo netstat -tulnp | grep ollama # 重启Dify docker compose down docker compose up -d -
开启防火墙端口
如果仍有问题,考虑是否防火墙拦截了
11434端口,需要配置防火墙规则。bashsudo ufw allow 11434/tcp && sudo ufw reload -
在docker容器中测试地址连通性
bash# 进入Dify容器 docker exec -it ragflow-server bash # 测试地址连通性 curl http://host.docker.internal:11434 # 应成功返回 Ollama is running # 或者使用本机IP地址测试 curl http://192.168.163.248:11434 # 应成功返回 Ollama is running -
获取本机IP地址(容器外执行)
bash# 获取本机IP地址,假如输出为 192.168.163.248 hostname -I | awk '{print $1}'
-
4.2 接入 VLLM 模型
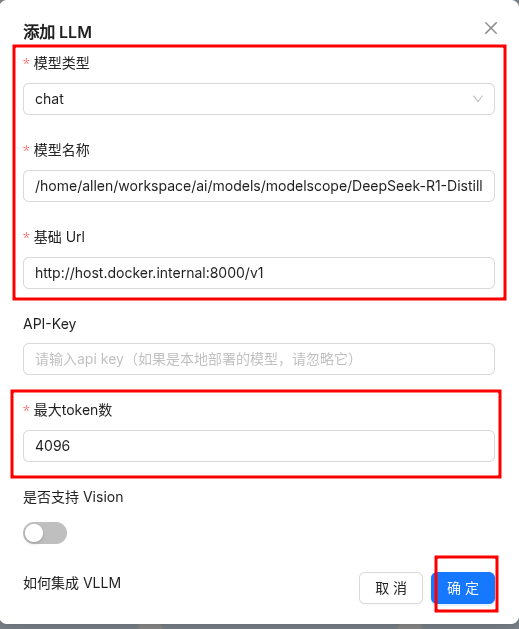
- 点击
RagFlow平台右上角头像→模型供应商,选择VLLM,点击添加模型。 - 选择
模型类型,输入模型名称、基础URL、最大token数,其他选项可使用默认设置即可,点击确定。其中:模型名称为 Ollama 服务中的模型名称,可通过ollama list获取

基础URL为 Ollama 服务地址,例如http://host.docker.internal:8000/v1
值得注意的是:笔者测试的模型名称为 /home/allen/workspace/ai/models/modelscope/deepseek-ai___DeepSeek-R1-Distill-Qwen-1.5B 时,RagFlow 识别到的实际模型名称为 /home/allen/workspace/ai/models/modelscope/deepseek-ai,导致提示 Fail to access model(/home/allen/workspace/ai/models/modelscope/deepseek-ai).**ERROR**: MODEL_ERROR - Error code: 404 - {'object': 'error', 'message': 'The model"/home/allen/workspace/ai/models/modelscope/deepseek-ai"does not exist.', 'type': 'NotFoundError', 'param': None, 'code': 404} 问题。
5. 应用场景
🔹 知识库智能问答
🔹 自动化数据分析
🔹 私有化客服机器人
6. 总结
RagFlow 通过 RAG 优先设计 与 开箱即用的部署方案,降低了企业构建大模型应用的门槛。其核心优势包括:
- 精准检索:结合语义搜索与关键词匹配,提升回答可靠性。
- 灵活扩展:模块化架构支持快速适配新模型与业务需求。
- 企业级安全:数据全程本地处理,无第三方依赖。
通过本文指南,开发者可快速完成 RagFlow 的部署、模型接入与应用开发,加速 AI 技术在实际业务中的落地。