MoE 是一种将多个子模型(专家)结合的技术,用于提升大语言模型Q(LLMs)性能。它主要由稀疏 MOE 层和门控网络(路由)组成。稀疏 MOE 层替代传统 Transformer 中的前馈神经网络(FFN)层,包含多个独立的专家网络,每个专家都是一个 FFN。门控网络负责决定输入的 token 被发送到哪个或哪些专家进行处理,其决策过程基于学习的参数,并与网络其他部分一起进行预训练。
在 Transformer 诞生之前,RNN(循环神经网络)和 CNN(卷积神经网络)在序列处理领域各领风骚。但 RNN 处理长序列时容易出现梯度消失或梯度爆炸的问题,就像一个记忆力不太好的学生,处理长文章时,前面的内容记不住,后面的又混淆;CNN 虽然在提取局部特征上表现出色,可对长距离依赖关系的捕捉能力欠佳,就好比只盯着眼前的局部风景,而忽略了远方的整体美景。
Transformer 则巧妙地摒弃了 RNN 的顺序处理方式和 CNN 的局部处理局限,引入了自注意力机制,这就像是给模型装上了一个 "全局雷达",能够同时关注输入序列中的各个位置,极大地提升了对长序列的处理能力,完美解决了上述难题。
在计算机视觉领域,Vision Transformer(ViT)把图像分成一个个小块,当作序列数据处理,在图像分类、目标检测、语义分割等任务中表现出色,让计算机也能像人类一样 "看懂" 图像。在跨模态学习领域,CLIP 模型将图像和文本关联起来,实现了从文本到图像的检索,比如你输入一段描述风景的文字,它就能找到对应的图片,仿佛拥有了跨越不同信息维度的 "超能力" 。
MOE 架构
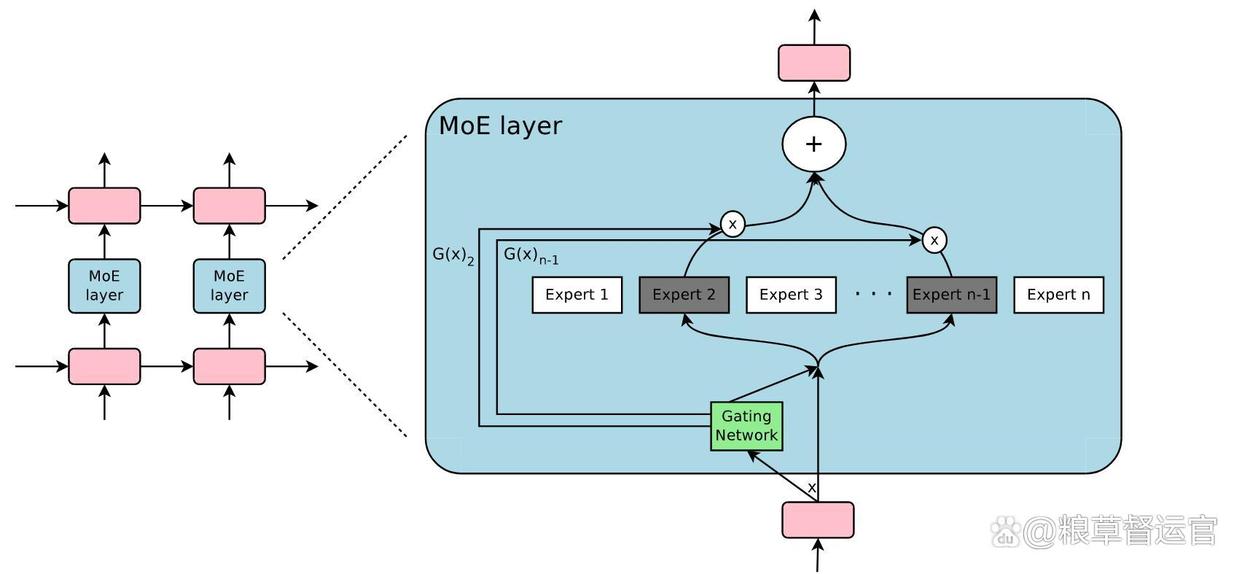
MOE,全称 Mixture of Experts,也就是混合专家模型,它的设计理念十分巧妙,就像是组建了一个超级 "专家团队" 。在 MOE 架构中,有多个不同的专家网络,每个专家都有自己的 "专长领域",专门负责处理特定类型的任务或数据。比如在处理自然语言时,有的专家擅长理解语法结构,有的则对语义理解更在行。
除了专家网络,MOE 还有一个关键组成部分 ------ 门控机制。门控机制就像是一个智能 "调度员",当输入数据进来时,它会对数据进行分析,然后根据数据的特点,把数据分配给最合适的专家网络进行处理。例如,当输入一段科技类文本时,门控机制会把它分配给擅长处理专业术语和技术概念的专家。
MOE 架构的优势十分显著。从计算效率来看,由于每次只激活部分专家网络,而不是让整个模型的所有参数都参与计算,大大减少了计算量,降低了能耗。这就好比一个工厂,不需要所有工人同时开工,只需根据订单类型,安排相关专业的工人工作,既节省了人力成本,又提高了生产效率。
在模型规模扩展方面,MOE 架构具有很强的灵活性。通过增加专家网络的数量,就能轻松扩展模型的规模,提升模型的能力,而不需要对模型结构进行大规模改动。在处理复杂任务时,不同专家各司其职,能够更好地捕捉数据中的复杂模式,提高模型的准确性和鲁棒性。比如在图像识别中,不同专家可以分别关注图像的颜色、形状、纹理等特征,最后综合判断,提升识别准确率。
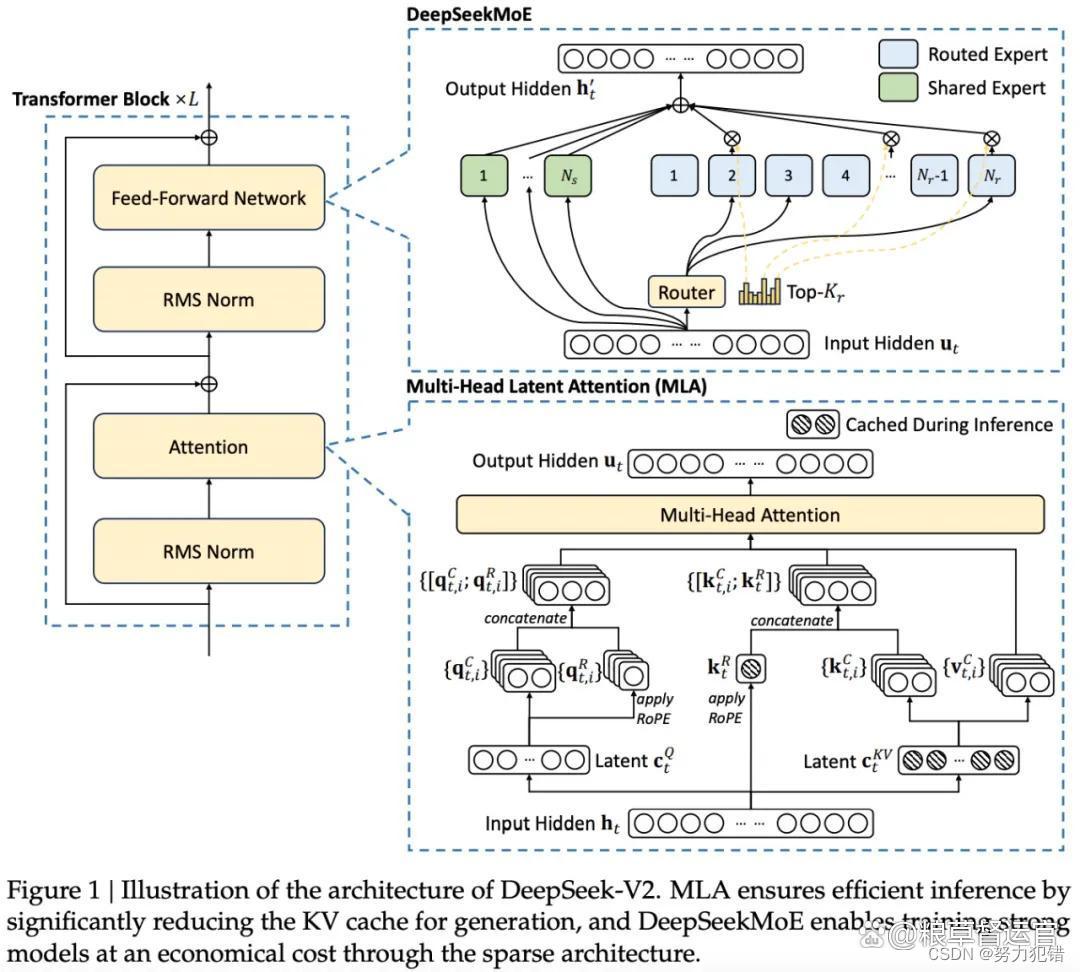
在自然语言处理领域,不少大型语言模型都采用了 MOE 架构,像 GPT-4、DeepSeek-V3 等,它们在语言生成、问答系统、文本翻译等任务中表现出色。以 DeepSeek-V3 为例,其采用的 DeepSeekMoE 架构,通过细粒度专家、共享专家和 Top-K 路由策略,实现了模型容量的高效扩展。每个 MoE 层包含 1 个共享专家和 256 个路由专家,每个 Token 选择 8 个路由专家,最多路由至 4 个节点。这种稀疏激活的机制,使得 DeepSeek-V3 能够在不显著增加计算成本的情况下,拥有庞大的模型容量,在多项评测中成绩优异。
在计算机视觉领域,Vision-MoE(V-MoE)将 ViT 中的密集 FFNN 层替换为稀疏 MoE,使得模型能够通过增加专家数量来大幅扩展,提升了图像分类、目标检测等任务的性能。在推荐系统中,Facebook 的混合专家推荐系统利用 MoE 模型对用户的兴趣进行建模,根据用户的不同行为和偏好,为用户精准推荐内容,实现了个性化推荐 。
DeepSeek Architect
两者关系:相辅相成
MOE 架构和 Transformer 架构并不是孤立存在的,它们就像一对默契十足的搭档,相互融合,共同发挥出更强大的威力。那么,它们是如何携手合作的呢?
一种常见的融合方式是,将 MOE 架构中的稀疏 MoE 层替换 Transformer 模型中的前馈网络(FFN)层。在这种融合架构中,MoE 层里的各个专家网络就像 Transformer 的 "智囊团",专门负责处理不同类型的输入数据。当输入数据进入模型时,门控机制会根据数据的特点,将其分配给最合适的专家网络进行处理。处理完成后,专家网络的输出再经过后续的 Transformer 层进行进一步的特征提取和处理 。
这种融合方式的优势十分明显。一方面,MoE 架构的引入,使得模型在处理复杂任务时,能够根据不同的数据特点,调用不同的专家网络,就像一个经验丰富的医生,根据不同的病症,选择最合适的治疗方案,从而提高了模型的准确性和鲁棒性。另一方面,Transformer 架构的自注意力机制,能够让模型更好地捕捉数据中的长距离依赖关系,理解上下文信息,为 MoE 层的专家网络提供更全面、准确的输入,两者相互补充,实现了 1 + 1 > 2 的效果。
成功案例:融合带来的突破
ChatGPT - 4o 便是将 MOE 和 Transformer 架构融合的成功典范。它通过 MoE 机制,能够根据输入数据动态选择适合的专家网络,使得模型可以更好地处理多样化的任务。同时,结合 Transformer 的自注意力机制,ChatGPT - 4o 能够并行处理长序列数据,减少计算负担,提高了效率。这种架构的结合,让 ChatGPT - 4o 在自然语言处理任务中表现出色,无论是日常对话、文本创作还是知识问答,都能应对自如。
DeepSeek 系列模型同样表现亮眼。以 DeepSeek-V3 为例,其采用的 DeepSeekMoE 架构,通过细粒度专家、共享专家和 Top-K 路由策略,实现了模型容量的高效扩展。在实际应用中,DeepSeek-V3 在多项自然语言处理和计算机视觉任务中取得了优异成绩。在文本生成任务中,它能够生成逻辑清晰、内容丰富的文本;在图像识别任务中,也能准确识别各种物体和场景 。
这些成功案例充分证明,MOE 和 Transformer 架构的融合,为 AI 模型的发展开辟了新的道路,让我们看到了 AI 技术更广阔的应用前景。
展望未来,MOE 和 Transformer 架构的融合必将在 AI 领域绽放更加绚烂的光彩。随着技术的不断进步,我们有理由期待,在更多复杂的任务和场景中,这两种架构的结合能够创造出更强大、更智能的 AI 系统,推动自然语言处理、计算机视觉、医疗、金融等各个领域的发展,为我们的生活带来更多的便利和惊喜 。
什么是moe框架: