一、大模型的崛起与概念解析
在人工智能技术飞速迭代的当下,大模型已成为驱动行业发展的核心引擎。从技术定义来看,大模型(Large Model) 是指基于深度学习架构、具备海量参数规模(通常数十亿至数万亿级别),并通过大规模数据预训练实现通用能力的 AI 模型。
1.1 核心技术特征
-
参数规模:以经典模型为例,GPT-3 参数量达 1750 亿,而最新的 Qwen3-235B 等模型已突破 2000 亿参数,参数规模直接决定模型对复杂模式的学习能力。
-
训练模式:采用 "预训练 + 微调" 双阶段模式,预训练阶段在通用数据集中学习基础语义与知识,微调阶段针对特定任务优化。
-
能力边界 :支持自然语言处理、多模态交互等复杂任务,核心优势在于上下文理解 与生成逻辑连贯性。
1.2 技术本质
大模型的本质是通过神经网络模拟人类认知逻辑,其核心流程可分为编码、推理、解码三个阶段,整体逻辑如图 1 所示:
其核心逻辑可简化为如下代码:
\# 大模型核心逻辑抽象
def large\_model(input\_text, params, knowledge\_base):
  \# 1. 语义编码:将输入文本转化为向量
  text\_embedding = encoder(input\_text)
  \# 2. 上下文推理:基于参数与知识库计算输出
  output\_logits = neural\_network(text\_embedding, params, knowledge\_base)
  \# 3. 生成解码:将向量转化为自然语言
  return decoder(output\_logits)其中,params(参数)是模型 "记忆" 知识的载体,knowledge_base是预训练过程中沉淀的通用认知。
二、大模型在文本生成式 AI 产品中的核心架构地位
文本生成式 AI 产品(如豆包、腾讯元宝、百度文心)的架构可概括为 "大模型 + 应用层 + 调度层",其中大模型是决定产品能力的核心模块。
2.1 基础架构示意图
用户输入 负载均衡层 应用层-功能解析 调度层-模型路由 大模型集群-核心推理 输出优化层 用户输出
- 核心流程:用户输入经功能解析后,由调度层匹配对应模型(轻量模型处理简单任务,大模型处理复杂任务),最终通过输出优化层返回结果。
2.2 主流产品架构解析
2.2.1 字节跳动豆包(基于云雀模型)
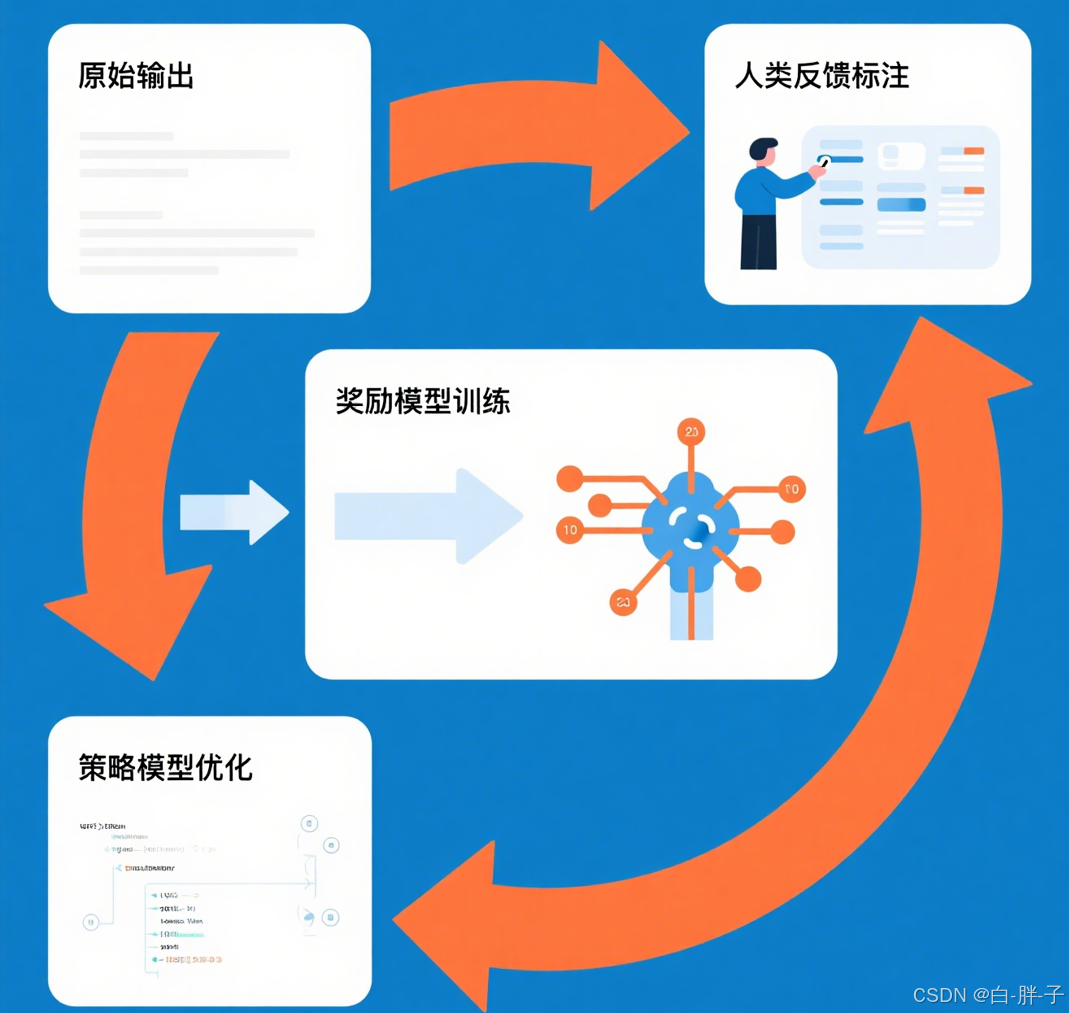
云雀模型作为豆包的核心引擎,采用 Transformer 架构,其推理流程中 RLHF 优化模块的作用如图 3 所示:
核心推理代码如下:
\# 豆包核心推理流程示例
class DoubaoEngine:
  def \_\_init\_\_(self):
  self.base\_model = "云雀-7B" # 基础大模型
  self.rlhf\_optimizer = RLHFModule() # 强化学习优化模块
  def generate(self, user\_query, context):
  \# 1. 上下文拼接
  full\_context = self.\_merge\_context(user\_query, context)
  \# 2. 大模型推理
  raw\_output = self.base\_model.generate(
  input\_ids=full\_context,
  max\_length=2048,
  temperature=0.7 # 控制生成随机性
  )
  \# 3. RLHF优化输出
  optimized\_output = self.rlhf\_optimizer.optimize(raw\_output)
  return optimized\_output- 技术亮点:通过 RLHF(基于人类反馈的强化学习)优化生成结果,提升对话自然度。
2.2.2 腾讯元宝(双模型架构)
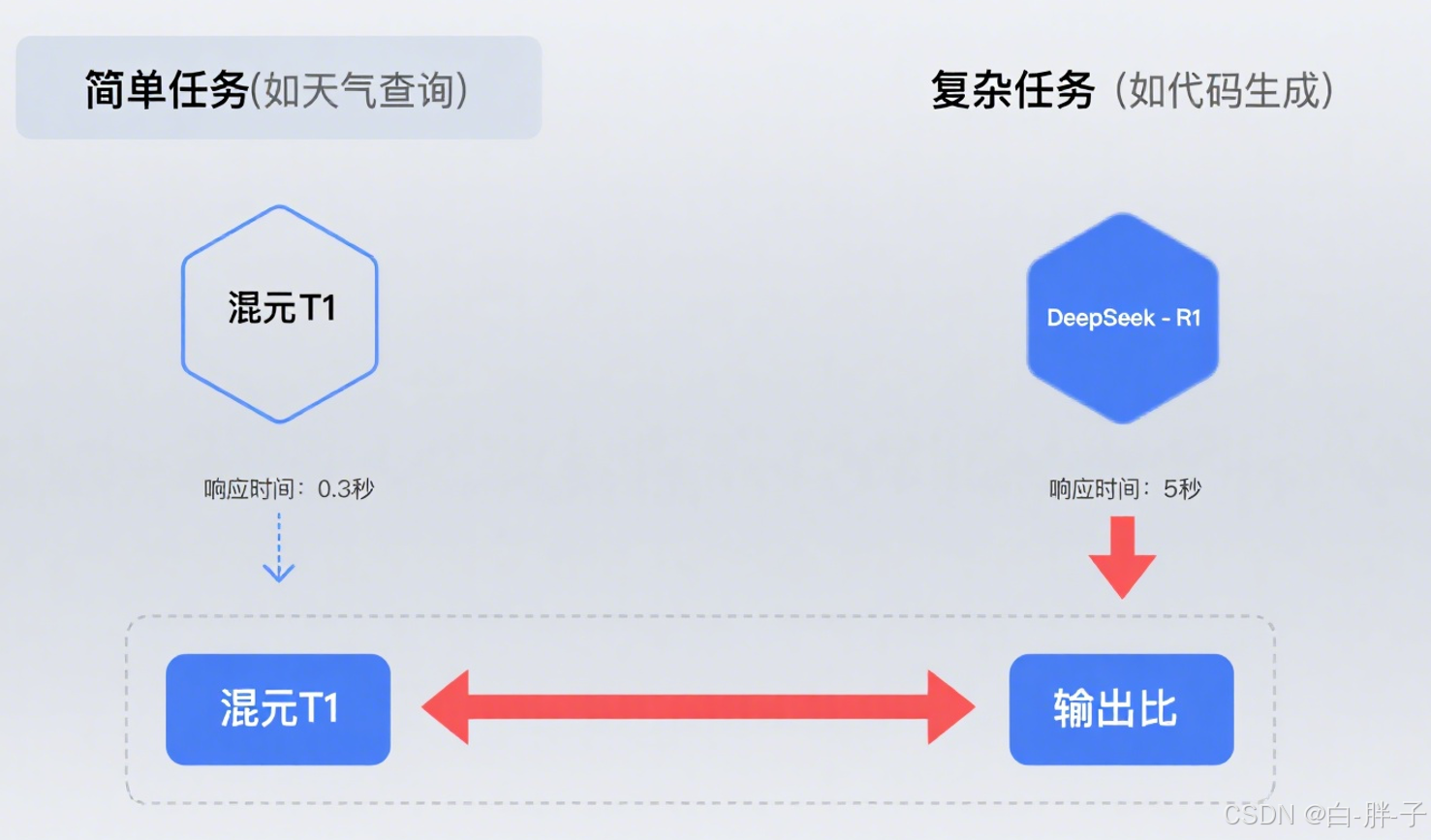
采用 "轻量模型 + 大模型" 协同模式,其模型调度策略如图 4 所示:
核心调度逻辑如下:
\# 腾讯元宝双模型调度示例
class YuanBaoEngine:
  def route\_request(self, user\_query):
  \# 任务复杂度判断
  if self.\_is\_simple\_task(user\_query): # 天气查询、短句问答等
  return "混元T1" # 3B轻量模型,低延迟
  else: # 代码生成、长文本创作等
  return "DeepSeek-R1" # 13B大模型,高准确率
  def \_is\_simple\_task(self, query):
  \# 基于关键词与语义向量判断任务类型
  return len(query) < 20 and "查询" in query- 优势:通过 Spring Cloud Gateway 实现动态路由,支持千万级请求并发处理。
三、大模型技术演进与产品适配案例
3.1 近期主流模型对比
| 模型名称 | 参数量 | 核心优势 | 产品适配案例 |
|---|---|---|---|
| Kimi K2 | 万亿级(激活 32B) | 低功耗复杂任务处理 | 代码生成工具、智能文档分析 |
| Qwen3-235B | 2350 亿 | 数学与工程能力突出 | 科研辅助系统 |
| DeepSeek-R1 | 13B | 长上下文支持(32K Token) | 法律合同解析 |
3.3 技术趋势:混合推理架构
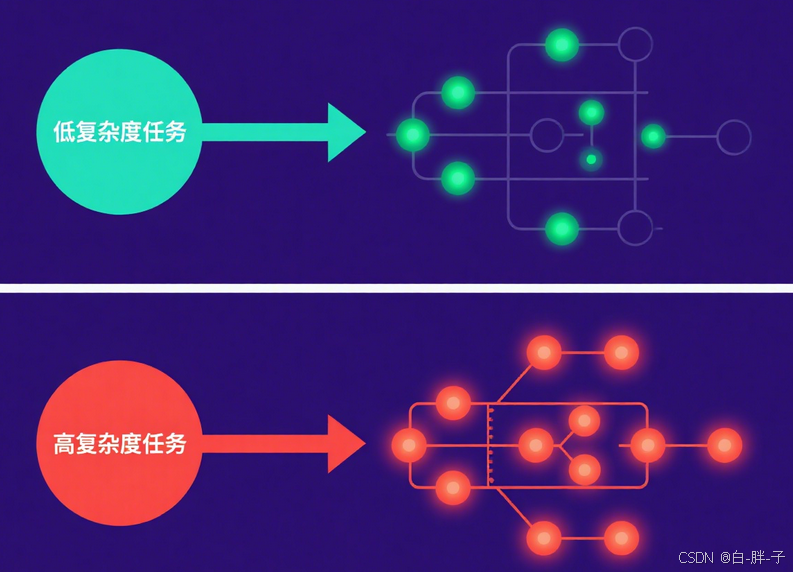
最新的模型设计采用 "混合推理" 模式,通过动态激活参数实现效率优化,其原理如图 6 所示:
核心逻辑代码如下:
\# 混合推理架构核心逻辑
def hybrid\_inference(model, input, complexity):
  \# 根据任务复杂度动态激活参数
  if complexity == "low":
  return model.activate\_layers(input, layers=1-10) # 轻量推理
  else:
  return model.activate\_layers(input, layers=1-48) # 全量推理该架构已应用于腾讯元宝的 "混元 T1+DeepSeek-R1" 双模型系统,使平均响应延迟降低 60%。
四、总结与展望
大模型作为文本生成式 AI 产品的 "中枢神经",其技术演进直接决定产品能力边界。从当前趋势来看,参数效率优化 (如激活参数动态调节)与垂直领域适配(如法律、代码生成)将成为核心方向。对于开发者而言,需重点关注:
-
模型调用接口的性能优化(如批量推理、缓存策略)
-
基于业务场景的微调策略(LoRA 等轻量微调技术)
-
多模型协同调度的工程实现
未来,随着大模型与边缘计算的结合,文本生成式 AI 产品将在移动端、嵌入式设备等场景实现更广泛的落地。