《HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation》论文讲解
一、引言
本文提出了 HunyuanCustom,这是一个基于多模态驱动的定制化视频生成框架。该框架旨在解决现有视频生成模型在身份一致性(identity consistency)和输入模态多样性方面的不足。HunyuanCustom 支持图像、音频、视频和文本等多种条件输入,能够生成具有特定主题身份的视频,广泛应用于虚拟人广告、虚拟试穿、唱歌头像和视频编辑等领域。
二、相关工作
(一)视频生成模型
近年来,扩散模型推动了视频生成技术的发展,从静态图像合成进化到动态时空建模。现有方法主要集中在文本引导的视频生成或基于单一参考图像的视频生成,但在生成内容的精细控制和概念驱动编辑方面仍存在不足。
(二)视频定制化
1. 实例特定视频定制化
这种方法通过使用与目标身份相同的多张图像对预训练的视频生成模型进行微调,每种身份单独训练。例如,Textual Inversion 和 DreamBooth 将图像身份信息嵌入文本空间,实现与文本的有效交互。然而,这些方法依赖于实例特定优化,难以实现实时或大规模视频定制化。
2. 端到端视频定制化
这种方法通过训练额外的条件网络将目标图像的身份信息注入视频生成模型,使模型在推理阶段能够泛化到任意身份图像输入。一些工作专注于保持面部身份,如 ID-Animator 和 ConsisID 等。但现有方法在处理多个主题身份的维护和交互时仍有较大提升空间。
三、方法
(一)概述
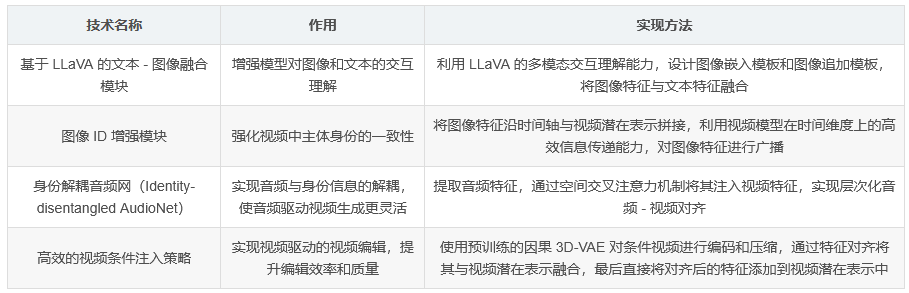
HunyuanCustom 以 Hunyuan Video 生成框架为基础,通过引入基于 LLaVA 的文本 - 图像融合模块和图像 ID 增强模块,实现对文本和图像的交互理解,增强模型对身份信息的把握。此外,为支持音频和视频条件注入,分别设计了音频和视频的特定注入机制。
(二)多模态任务
HunyuanCustom 支持以下四类任务:
-
文本驱动视频生成:基于 HunyuanVideo 的文本 - 视频生成能力,根据文本提示生成对应视频。
-
图像驱动视频定制:以输入图像提取身份信息,结合文本描述生成对应视频,支持人类和非人类身份以及多身份输入。
-
音频驱动视频定制:在图像驱动定制基础上融入音频,在文本描述场景中使主题与音频同步行动。
-
视频驱动视频定制:实现基于身份定制的对象替换或插入,可将目标身份插入背景视频。
(三)多模态数据构建
数据来源广泛,涵盖人类、动物、植物等八大类别。数据处理包括过滤和预处理、主体提取、视频分辨率标准化、视频标注和掩码数据增强等步骤,确保数据质量以提升模型性能。
1. 数据过滤和预处理
利用 PySceneDetect 分割视频为单镜头剪辑,使用 textbpn-plusplus 过滤含过多文本的剪辑,对视频进行裁剪和对齐,并通过 koala-36M 模型进一步优化。
2. 主体提取
-
单主体提取:使用 Qwen7B 模型标记帧中所有主体并提取 ID,用 Union-Find 算法计算 ID 出现频率,选择最高频 ID 作为目标主体。利用 YOLO11X 和 InsightFace 分别进行人体分割和面部检测。
-
非人类主体提取:使用 QwenVL 提取视频主体关键词,并通过 GroundingSAM2 生成掩码和边界框。
-
多主体提取:使用 QwenVL 和 Florence2 提取边界框,再通过 GroundingSAM2 进行主体提取,并进行聚类以去除不包含所有主体的帧。
(四)图像驱动视频定制
-
基于 LLaVA 的文本 - 图像交互:通过设计图像嵌入模板和图像追加模板,利用 LLaVA 的多模态交互理解能力,实现文本和图像的有效融合。
-
身份增强:通过时间轴拼接图像特征,并利用视频模型在时间维度上的高效信息传递能力,增强视频身份一致性。
-
多主体定制化:在单主体定制模型基础上进行微调,为每个条件图像分配不同的时间索引,以区分不同身份图像。
(五)多模态主体中心视频生成
1. 音频驱动视频定制
提出身份解耦音频网(Identity-disentangled AudioNet),提取音频特征并通过空间交叉注意力机制将其注入视频特征,实现层次化音频 - 视频对齐。
2. 视频驱动视频定制
采用高效的视频条件注入策略,先通过预训练的因果 3D-VAE 对条件视频进行编码和压缩,再通过特征对齐将其与视频潜在表示融合,最后直接将对齐后的特征添加到视频潜在表示中。
四、实验
(一)实验设置
使用以下指标评估视频定制性能:
-
身份一致性:使用 Arcface 检测并提取参考人脸和生成视频各帧的嵌入,计算平均余弦相似度。
-
主体相似性:使用 YOLOv11 检测并分割人类,再计算参考与结果的 DINO-v2 特征相似度。
-
文本 - 视频对齐:使用 CLIP-B 评估文本提示与生成视频的对齐程度。
-
时间一致性:使用 CLIPB 模型计算各帧与其相邻帧及第一帧的相似度。
-
动态程度:根据 VBench 测量物体的运动程度。
(二)单主体视频定制化比较
1. 基线方法
将 HunyuanCustom 与包括商业产品(Vidu 2.0、Keling 1.6、Pika 和 Hailuo)和开源方法(Skyreels-A2 和 VACE)在内的多种先进视频定制方法进行比较。
2. 定性比较
HunyuanCustom 在保持身份一致性的同时,具有更好的视频质量和多样性。
3. 定量比较
HunyuanCustom 在身份一致性和主体相似性方面表现最佳,与其他指标表现相当。
(三)多主体视频定制化实验和应用
1. 定性比较
HunyuanCustom 有效捕捉人类和非人类主体身份,生成符合提示的视频,且视觉质量高、稳定性好。
2. 虚拟人广告
HunyuanCustom 能够生成具有良好互动性的广告视频,保持人物身份和产品细节,使视频符合提示。
(四)音频驱动视频定制化实验
1. 音频驱动单主体定制化
HunyuanCustom 实现了在文本描述的场景和姿势中,使角色说出相应音频,生成多样化的视频。
2. 音频驱动虚拟试穿
结合文本提示和音频,生成具有指定服装的人物视频,同时保持身份一致性。
(五)视频驱动视频定制化实验
在视频主体替换任务中,与 VACE 和 Keling 相比,HunyuanCustom 有效避免边界伪影,实现与视频背景的无缝融合,并保持强烈的身份保护。
(六)消融研究
比较完整模型与三种消融模型(无 LLaVA、无身份增强、通过通道级拼接进行身份增强)的性能,结果表明 LLaVA 不仅传递提示信息,还提取关键身份特征;身份增强模块在细化身份细节方面有效;时间拼接有助于通过强大的时间建模先验有效捕捉目标信息,并最大限度地减少对生成质量的影响。
五、结论
HunyuanCustom 是一种新颖的多模态定制视频生成模型,能够实现主体一致的视频生成,并支持图像、音频和视频与文本驱动条件的结合。通过整合文本 - 图像融合模块、图像 ID 增强模块和高效的音频及视频特征注入过程,确保生成的视频符合用户特定要求,达到高保真度和灵活性。大量实验证明,HunyuanCustom 在各项任务中均优于现有方法,在身份一致性、真实性和视频 - 文本对齐方面表现出色,是可控视频定制领域的领先解决方案,为未来可控视频生成研究铺平了道路,并拓展了人工智能生成内容(AIGC)在创意产业及其他领域的潜在应用。
六、核心技术汇总表格