写在前面
此文章大部分不会引用最原始的概念,采用**`说人话`**的方式。
面试题一:三大范式是什么?目的是什么?必须遵循吗?
假设有一张表(学号,姓名,课程,老师)
是什么
- 第一范式
- 字段原子性
- 第二范式
- 解决部份依赖。应该非主键列完全依赖主键。比如(学号,姓名)不可以做主键,冗余了
- 又比如在 "学生课程表" 中,有 "学生 ID""课程 ID""学生姓名""课程名称" 等字段,复合主键是 "(学生 ID,课程 ID)"。其中,"学生姓名" 只依赖于 "学生 ID","课程名称" 只依赖于 "课程 ID",它们都依赖于复合主键的一部分,而不是整个复合主键,这就是部分依赖。
- 第三范式
- 解决传递依赖。比如A->B->C,应该是A,B一起,C能推导了不要放进去
目的
- 三大范式目的
- 让设计模式的职责更加的单一,方便后续扩展
- 肯定优先考虑,像模型和领域的划分都是通过表来进行的
必须遵循吗?反范式?目的?
- 反范式
- 遵循范式的基础上,增加冗余字段,空间换时间 先遵守规则,在进行调整
- 目的
- 优化性能
- 1.分库分表,优化联合查询join,分页查询(分库分表之后分页不了,冗余字段来优化)
- 2.快照字段解决问题---分页查询
当然,不是一上来就反范式、冗余字段。任何系统的设计起点都是三大范式为基础,否则说明是一家外包公司(表已经给好了)。
面试题二:MySQL存储引擎是什么?有哪些?区别是什么?
是什么
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表而不是基于库的,所以存储引擎也可以被称为表引擎。
有什么
MySQL常见存储引擎有:InnoDB、MyISAM、Memory
注意:区别可以从:锁级别、索引、计数器、事务、外键、存储文件结构、数据页大小 这几点出发。
InnoDB
- MySQL5.5之后
- 支持行级锁、事务、外键
- 支持聚簇索引
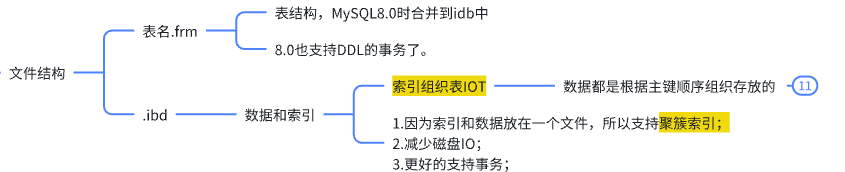
- 文件结构
- 没有计数器
- 为什么不像MySIAM一样维护一个计数器?
- InnoDB有事务,计数器需要动态变化,会有很多版本。回滚的话又变化。
- 维护这个影响性能【高并发和大数据场景】
- 为什么不像MySIAM一样维护一个计数器?
- InnoDB不能手动创建hash索引的,但有个自适应hash。
MyISAM
-
不支持行级锁、事务、外键,崩溃后无法恢复
- MyISAM的设计更侧重于简单的数据存储和读取性能,没有实现事务处理机制,因此不支持事务和行级锁
-
维护count计数器,select count(*)只需要O(1)时间复杂度。
- 为什么InnoDB没有,因为InnoDB支持事务,维护计数器的话会很复杂,可能需要回滚。
- 每张 MyISAM 的数据表都有一个 meta 信息有存储了row_count值,由表级锁保证一致性。因为她没有事务。
-
索引和数据是分开存储,只支持非聚簇索引
- 非聚簇索引,数据文件是分离的,索引保存的是数据文件的指针。
- 堆表
-
默认数据页1K
-
文件结构

Memory(少见)
- 数据存储在内存中
- Hash索引
- hash结构存储的
面试题三:如何创建索引、删除索引、查询索引?
sql
创建索引: CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, ...); //联合索引字段名顺序有讲究的
如果不加 CREATE 后面不加索引类型参数,则创建的是常规索引
查看索引: SHOW INDEX FROM table_name;
删除索引: DROP INDEX index_name ON table_name;面试题四:索引有什么类型?
可按照四个维度来区分?
数据结构
B+树
为什么用B+树
- 矮胖
- 矮:减少磁盘IO,每一层都要进行一次磁盘IO
- 胖:存储大量节点,从而降低树的高度
- 数据只在叶子节点
- 查询性能稳定
- 叶子节点采用双向链表
- 方便范围查询
- 有冗余节点
- 树调整的时候没有b-tree复杂
- 删除的时候因为冗余节点在非叶子节点,只删除叶子节点,因为叶子节点带数据,所以B+树不用调整叶子节点成非叶子节点 他非叶子节点只是加速查找,无数据
B树
- 非叶子节点也存数据
- 没有冗余系节点,树调整相对复杂,因为比如删除一个节点,如果不是叶子节点需要进行树调整,B+树的话有冗余节点在非叶子节点,叶子节点可以直接删除。
Hash索引
key-value的结构,不适合范围查询,适合散列且不需要范围查询。
字段数量
单列索引
只有一个字段的索引
联合索引
何为最左匹配原则见面试题七!
多个字段组成的索引,需要满足最左匹配原则,查询次数多的字段排前面,并且区分度高的。
字段特征
函数索引
**1、是什么:**函数作为索引。允许数据库管理员或开发者对表中的列执行表达式计算后的结果进行索引,而不是直接对列值或列的前缀值进行索引
2、使用场景:
- 日期和时间的计算:如查询特定年份、月份或日期的记录。
- 字符串处理:如查询字符串的某个子串或进行大小写不敏感的匹配。
- 数值计算:如查询某个数值范围经过计算后落在特定区间的记录。
**3、好处:**这种索引技术可以显著提高查询性能,特别是在需要对列值进行复杂计算或转换的查询场景中。
4、例子:
- 比如经常对name进行大小写模糊查询。
- -- 创建基于 LOWER() 函数的索引CREATE INDEX idx_username_lower ON users (LOWER(username));
主键索引
详细主键索引 VS 唯一索引见下面的面试题六!
即primaryKey,非空且唯一的索引。
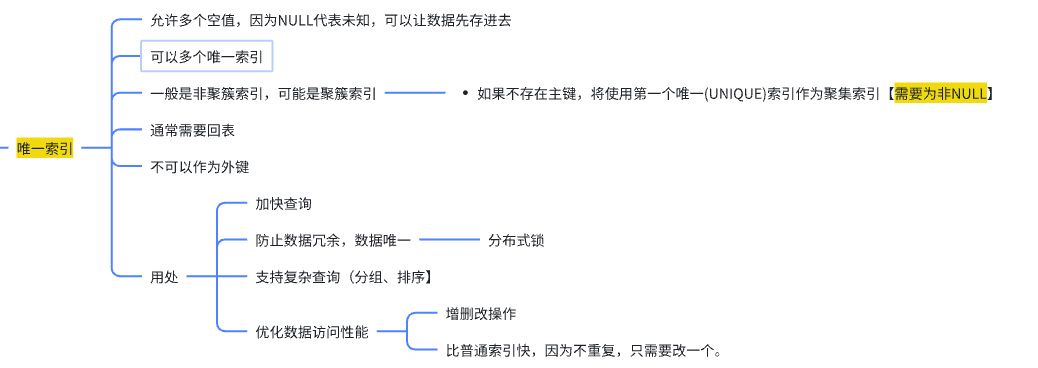
唯一索引
即只能出现一次的索引,独一无二。
普通索引/二级索引
- 查询时:叶子节点只存储主键id和对应的索引字段,所以一旦需要查询的字段有至少一个不在叶子节点,就需要徽标去查询聚簇索引。
- 修改时:普通索引只是一个索引的作用,数据在聚簇索引,所以数据有改动的话必须回表,否则就是脏数据。
hash索引
即哈希结构的索引,key-value的形式
前缀索引
将字符串的前length个字符作为索引,可以通过统计取出最高区分度的前缀长度。
sql
创建语法:ADD INDEX index_name (column_name(length));- 减少索引占用的存储空间,提升查询效率
- order by 就无法使用前缀索引;
- 无法把前缀索引用作覆盖索引;【因为存储的只是截取的部分字符串】
全文索引
是 MySQL 中专门用于高效检索文本内容的一种索引类型。它通过分词技术将大段文本拆解为关键词,并建立倒排索引,从而支持自然语言搜索和复杂关键词匹配。
- 区分倒排索引:全文索引的底层实现正是基于倒排索引的优化结构。MySQL的全文索引是 倒排索引在数据库中的具体实现。倒排索引(全文索引)专攻文本模糊匹配
数据特征
前置知识:
1、回表:MySQL的B+树结构查询数据都是到叶子节点查询字段,因此一旦不满足字段数量,就需要回到聚簇索引查询全量的字段,因为聚簇索引包含了所有的数据。
如图
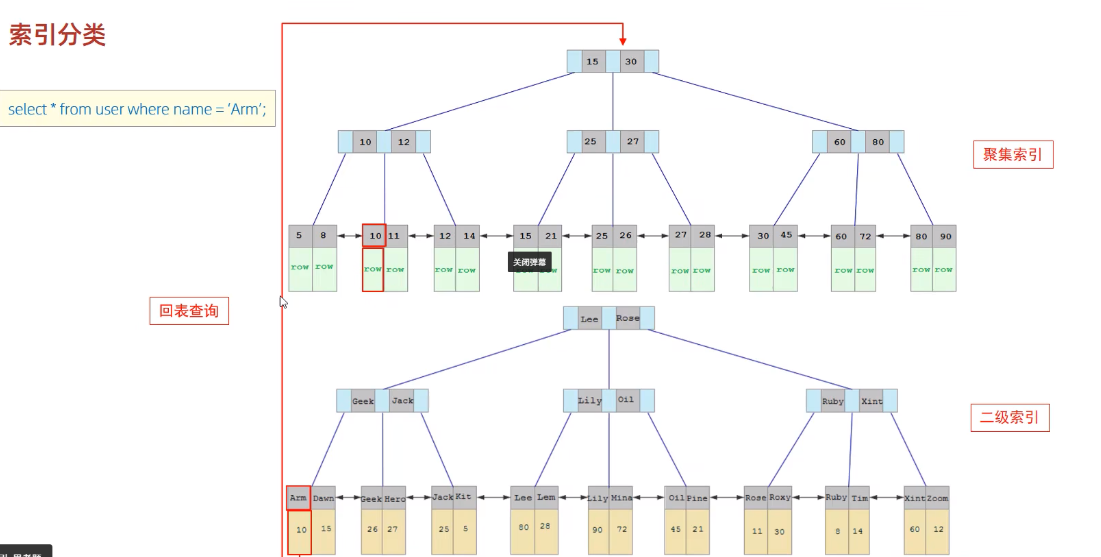
聚簇索引
详细区分主键索引和聚簇索引在面试题五!
聚簇索引是全量数据存储在叶子节点,任何select只要是聚簇索引都能在叶子节点找到,因此不需要回表去查询其他字段。
非聚簇索引/二级索引
- 查询时:叶子节点只存储主键id和对应的索引字段,所以一旦需要查询的字段有至少一个不在叶子节点,就需要徽标去查询聚簇索引。
- 修改时:普通索引只是一个索引的作用,数据在聚簇索引,所以数据有改动的话必须回表,否则就是脏数据。
面试题五:区分主键索引和聚簇索引
- 可以没有主键索引但是不能没有聚簇索引。所以聚簇索引不一定是主键索引,主键索引一定是聚簇索引
- 因为表的数据都是存放在聚簇索引的叶子节点里,所以 InnoDB 存储引擎一定会为表创建一个聚簇索引,且由于数据在物理上只会保存一份,所以聚簇索引只能有一个,也就是文件.ibd。
面试题六:主键索引 VS 唯一索引
主键索引:如下思维导图

唯一索引:如下思维导图
面试题七:何为最左匹配原则
就是比如字段(A,B,C)联合索引,要想索引生效,比如查询时不能跳过字段,说人话就是where(B,C)会失效,但是where(B,C,A)不会失效。
你肯定疑惑为啥不应该是A,B,C的顺序,因为MySQL也不傻,底层会帮我调整顺序为where(A,B,C)。
面试题八:索引的设计原则是什么?
可以从正向、逆向的角度出发:
- 正向
- 给数据量大且频繁的表创建索引
- 常where、order by、group by条件的列创建索引
- 联合索引,避免回表查询
- 字符串比较长的可以创建前缀索引
- 逆向
- 索引不是越多越好,会影响修改效率
面试题九:讲讲MySQL的主从复制
为什么需要主从集群?
一是读写分离,主库负责写操作,从库承担读请求,缓解主库压力,提升系统并发处理能力;
二是数据冗余备份,从库保存主库数据副本,当主库故障时,从库可切换为主库,保障业务连续性;
三是分担压力,从库能用于报表统计、数据分析等,减轻主库负载,优化整体性能 。
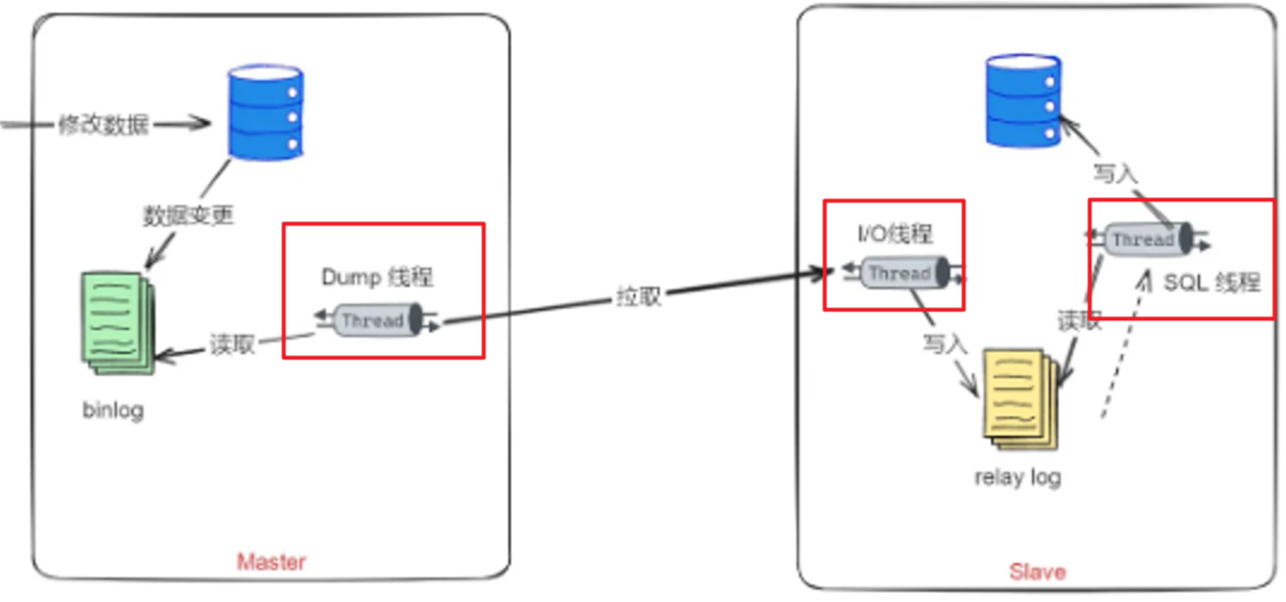
主从复制流程
3个阶段:
- 写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。Master 主库在事务提交时,会把数据变更记录在二进制文件Binlog中。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存(中继)日志中。从库(IOThread)读取数据库的二进制日志文件Binlog,写入到从库的中继日志Relay log。
- 回放 Binlog:回放 binlog,并更新存储引擎中的数据。slave(SQLThread)重做中继日志中的事件,将改变反映它自己的数据。
流程图