Golang 切片(slice)源码分析(一、定义与基础操作实现)
注意当前go版本代码为1.23
一、定义
slice 的底层数据是数组,slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。
数组是定长的,长度定义好之后,不能再更改。在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 3int 和 4int 就是不同的类型。
而切片则非常灵活,它可以动态地扩容。切片的类型和长度无关。
数组就是一片连续的内存, slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
golang
type slice struct {
array unsafe.Pointer
len int
cap int
}数据结构如下:
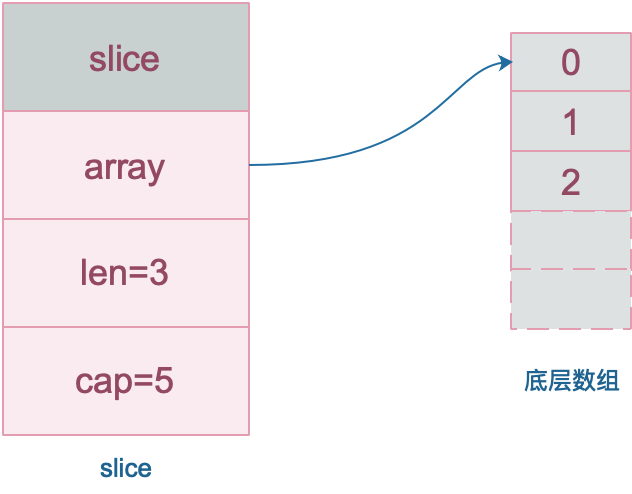
注意,底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
二、操作
2.1创建
src/runtime/slice.go 主要逻辑就是基于容量申请内存。
go
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 计算切片所需的内存大小,cap 为切片容量,et.Size_ 为每个元素的大小
// math.MulUintptr 执行无符号整数乘法,并返回结果和一个表示是否发生溢出的布尔值
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
// 检查以下几种错误情况:
// 1. overflow:容量计算时发生溢出
// 2. mem > maxAlloc:所需的内存超过最大可分配内存
// 3. len < 0:切片长度为负数
// 4. len > cap:切片长度大于容量
if overflow || mem > maxAlloc || len < 0 || len > cap {
// 注意:当用户执行 make([]T, bignumber) 时,产生 "len out of range" 错误,而不是 "cap out of range" 错误。
// 虽然 "cap out of range" 也是对的,但由于容量是隐式提供的,因此提示长度错误更清晰。
// 参考:golang.org/issue/4085
// 重新计算基于长度的内存大小,以便在容量溢出时提供更准确的错误信息(例如 len 也溢出)
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
// 再次检查溢出、内存超出限制以及长度为负数的情况
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen() // 长度错误,触发 panic
}
panicmakeslicecap() // 容量错误,触发 panic
}
// 调用 mallocgc 分配内存。
// mallocgc 是 Go 运行时中的函数,用于分配内存并在垃圾回收器中注册该内存。
// 参数:
// mem: 要分配的内存大小
// et: 切片元素的类型
// true: 指示分配的内存应该被清零
return mallocgc(mem, et, true)
}2.2扩容
核心源码 growslice-》nextslicecap&&roundupsize
首先通过nextslicecap计算出一个初步的扩容值,通过roundupsize内存对齐得出最终的扩容值,并不是网上的简单公式。
在1.18版本之前,slice源码中nextslicecap扩容主要逻辑为:
当原 slice 容量小于
1024的时候,新 slice 容量变成原来的2倍;原 slice 容量超过1024,新 slice 容量变成原来的1.25倍。
在1.18版本更新之后,slice源码中nextslicecap的扩容主要逻辑变为了:
当原slice容量(oldcap)小于256的时候,新slice(newcap)容量为原来的2倍;原slice容量超过256,新slice容量newcap = oldcap+(oldcap+3*256)/4
下述为go1.23源码逻辑src/runtime/slice.go :
go
// growslice 为一个切片分配新的底层存储。
//
// 参数:
// oldPtr = 指向切片底层数组的指针
// newLen = 新的长度(= oldLen + num)
// oldCap = 原始切片的容量
// num = 正在添加的元素数量
// et = 元素类型
// 返回值:
// newPtr = 指向新底层存储的指针
// newLen = 新的长度与传参相同
// newCap = 新底层存储的容量
//
// 要求 uint(newLen) > uint(oldCap)。
// 假设原始切片的长度为 newLen - num
//
// 分配一个至少能容纳 newLen 个元素的新底层存储。
// 已存在的条目 [0, oldLen) 被复制到新的底层存储中。
// 添加的条目 [oldLen, newLen) 不会被 growslice 初始化
// (虽然对于包含指针的元素类型,它们会被清零)。调用者必须初始化这些条目。
// 尾随条目 [newLen, newCap) 被清零。
//
// growslice 的特殊调用约定使得调用此函数的生成代码更简单。特别是,它接受并返回
// 新的长度,这样旧的长度不需要被保留/恢复,而新的长度返回时也不需要被保留/恢复。
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
oldLen := newLen - num
// ... 函数非核心部分省略
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
// append不应该创建一个指针为nil但长度非零的切片。
// 我们假设在这种情况下,append不需要保留oldPtr。
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
// 1.计算新容量
newcap := nextslicecap(newLen, oldCap)
var overflow bool
var lenmem, newlenmem, capmem uintptr
// 针对常见的 et.Size 进行优化
// 对于1我们不需要任何除法/乘法。
// 对于 goarch.PtrSize, 编译器会优化除法/乘法为一个常量移位。
// 对于2的幂,使用变量移位。
noscan := !et.Pointers()
// 2.内存对齐
switch {
case et.Size_ == 1:
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap), noscan)
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.Size_ == goarch.PtrSize:
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap)*goarch.PtrSize, noscan)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.Size_):
var shift uintptr
if goarch.PtrSize == 8 {
shift = uintptr(sys.TrailingZeros64(uint64(et.Size_))) & 63
} else {
shift = uintptr(sys.TrailingZeros32(uint32(et.Size_))) & 31
}
lenmem = uintptr(oldLen) << shift
newlenmem = uintptr(newLen) << shift
capmem = roundupsize(uintptr(newcap)<<shift, noscan)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
capmem = uintptr(newcap) << shift
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem, noscan)
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
// ... 函数非核心部分省略
}
核心代码:
// nextslicecap 计算下一个合适的切片容量。
// 该函数用于在切片需要扩容时,确定新的容量大小。
// newLen: 切片的新长度(所需容量)。
// oldCap: 切片的旧容量。
// 返回值: 新的切片容量。
func nextslicecap(newLen, oldCap int) int {
newcap := oldCap // 将新的容量初始化为旧的容量
doublecap := newcap + newcap // 计算旧容量的两倍
// 如果新长度大于旧容量的两倍,则直接使用新长度作为新容量
// 这是为了避免频繁的扩容操作,当所需长度远大于当前容量时,直接分配所需的空间
if newLen > doublecap {
return newLen
}
// 设置一个阈值,用于区分小切片和大切片
const threshold = 256
// 对于容量小于阈值的小切片,新容量直接设置为旧容量的两倍
// 这是因为小切片的扩容成本相对较低
if oldCap < threshold {
return doublecap
}
// 对于容量大于等于阈值的大切片,采用更保守的扩容策略
for {
// 从2倍增长(小切片)过渡到1.25倍增长(大切片)。
// 该公式在两者之间提供平滑的过渡。
// (newcap + 3*threshold) >> 2 等价于 (newcap + 3*threshold) / 4
// 这使得新容量的增长比例在1.25到2之间,并随着切片容量的增大而逐渐接近1.25
newcap += (newcap + 3*threshold) >> 2
// 需要检查 `newcap >= newLen` 以及 `newcap` 是否溢出。
// newLen 保证大于零,因此当 newcap 溢出时,`uint(newcap) > uint(newLen)` 不成立。
// 这允许使用相同的比较来检查两者。
// 使用uint类型进行比较是为了处理溢出情况。如果newcap溢出变成负数,转换为uint类型后会变成一个很大的正数,从而使得比较仍然有效。
if uint(newcap) >= uint(newLen) {
break // 如果新容量足够大,则退出循环
}
}
// 当 newcap 计算溢出时,将 newcap 设置为请求的容量。
// 如果 newcap 小于等于 0,说明发生了溢出
if newcap <= 0 {
return newLen
}
return newcap // 返回计算出的新容量
}
// roundupsize 返回 mallocgc 为指定大小分配的内存块的大小,减去任何用于元数据的内联空间。
// size: 请求分配的内存大小。
// noscan: 如果为 true,则表示该内存块不需要垃圾回收扫描。
// 返回值: mallocgc 实际分配的内存块大小。
func roundupsize(size uintptr, noscan bool) (reqSize uintptr) {
reqSize = size // 初始化请求大小
// 处理小对象(小于等于 maxSmallSize-mallocHeaderSize)
if reqSize <= maxSmallSize-mallocHeaderSize {
// 小对象。
// 如果需要垃圾回收扫描 (noscan 为 false) 并且大小大于 minSizeForMallocHeader,则添加 mallocHeaderSize 用于存储元数据。
// heapBitsInSpan(reqSize) 用于检查对象是否足够小到可以存储在堆的位图中,如果可以,则不需要 mallocHeader。
if !noscan && reqSize > minSizeForMallocHeader { // !noscan && !heapBitsInSpan(reqSize)
reqSize += mallocHeaderSize
}
// (reqSize - size) 为 mallocHeaderSize 或 0。如果添加了 mallocHeaderSize,我们需要从结果中减去它,因为 mallocgc 会再次添加它。
// 这里是为了确保返回的大小是 mallocgc 实际分配的大小,而不是包含了头部之后的大小。
// 进一步区分更小的对象和中等大小的对象,使用不同的查找表进行向上取整
if reqSize <= smallSizeMax-8 {
// 对于非常小的对象,使用 size_to_class8 和 class_to_size 查找表进行向上取整,以 8 字节为粒度。
// divRoundUp(reqSize, smallSizeDiv) 计算 reqSize 在 smallSizeDiv 粒度下的向上取整值。
// class_to_size[...] 获取对应大小类的实际分配大小。
// 最后减去 (reqSize - size) 移除之前可能添加的 mallocHeaderSize。
return uintptr(class_to_size[size_to_class8[divRoundUp(reqSize, smallSizeDiv)]]) - (reqSize - size)
}
// 对于中等大小的对象,使用 size_to_class128 和 class_to_size 查找表进行向上取整,以 128 字节为粒度。
return uintptr(class_to_size[size_to_class128[divRoundUp(reqSize-smallSizeMax, largeSizeDiv)]]) - (reqSize - size)
}
// 处理大对象(大于 maxSmallSize-mallocHeaderSize)
// 大对象。将 reqSize 向上对齐到下一页。检查溢出。
reqSize += pageSize - 1 // 将 reqSize 增加到下一页边界之前
// 检查溢出。如果 reqSize 加上 pageSize - 1 后反而变小了,说明发生了溢出。
if reqSize < size {
return size // 返回原始大小,避免分配过大的内存
}
// 通过按位与运算将 reqSize 对齐到下一页边界。
return reqSize &^ (pageSize - 1)
}三、问题
【引申1】 3int 和 4int 是同一个类型吗?
不是。因为数组的长度是类型的一部分,这是与 slice 不同的一点。
【引申2】 下面的代码输出是什么?
说明:例子来自雨痕大佬《Go学习笔记》第四版,P43页。这里我会进行扩展,并会作图详细分析。
golang
package main
import "fmt"
func main() {
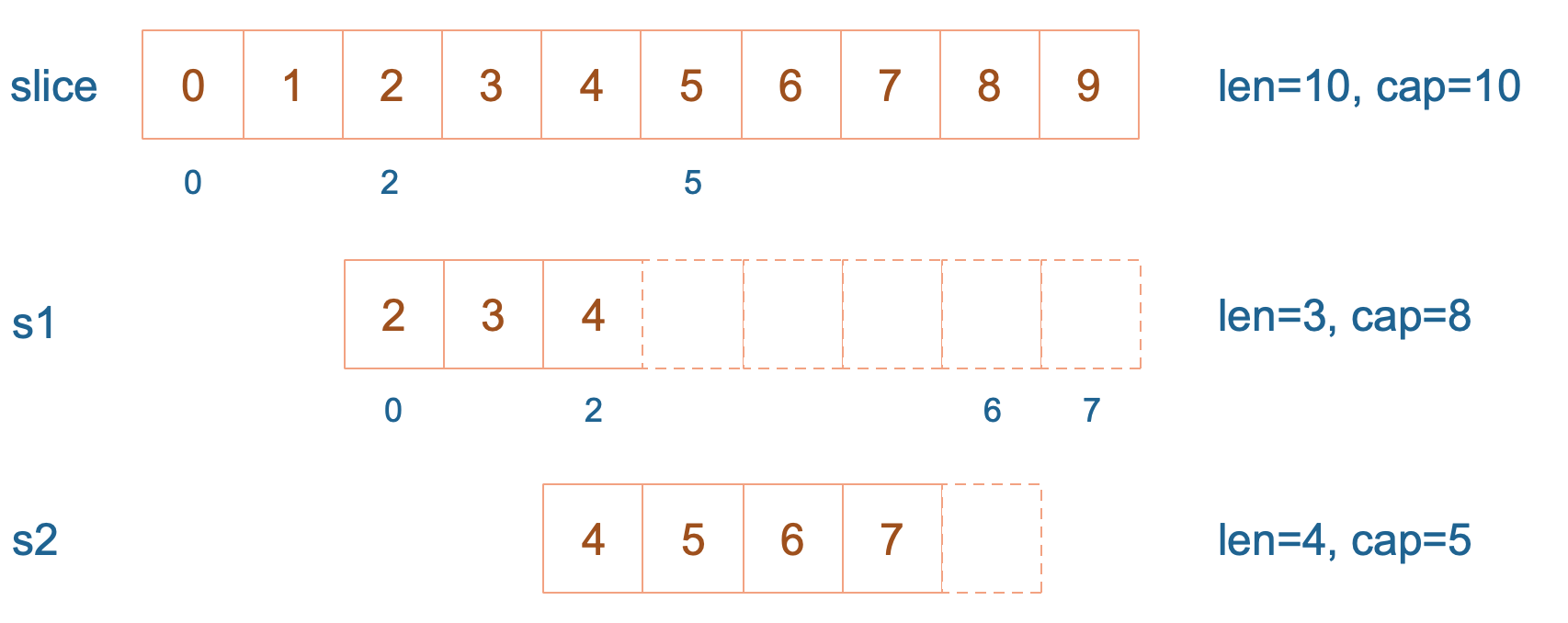
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:6:7]
s2 = append(s2, 100)
s2 = append(s2, 200)
s1[2] = 20
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(slice)
}结果:
golang
[2 3 20]
[4 5 6 7 100 200]
[0 1 2 3 20 5 6 7 100 9]s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。 s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。
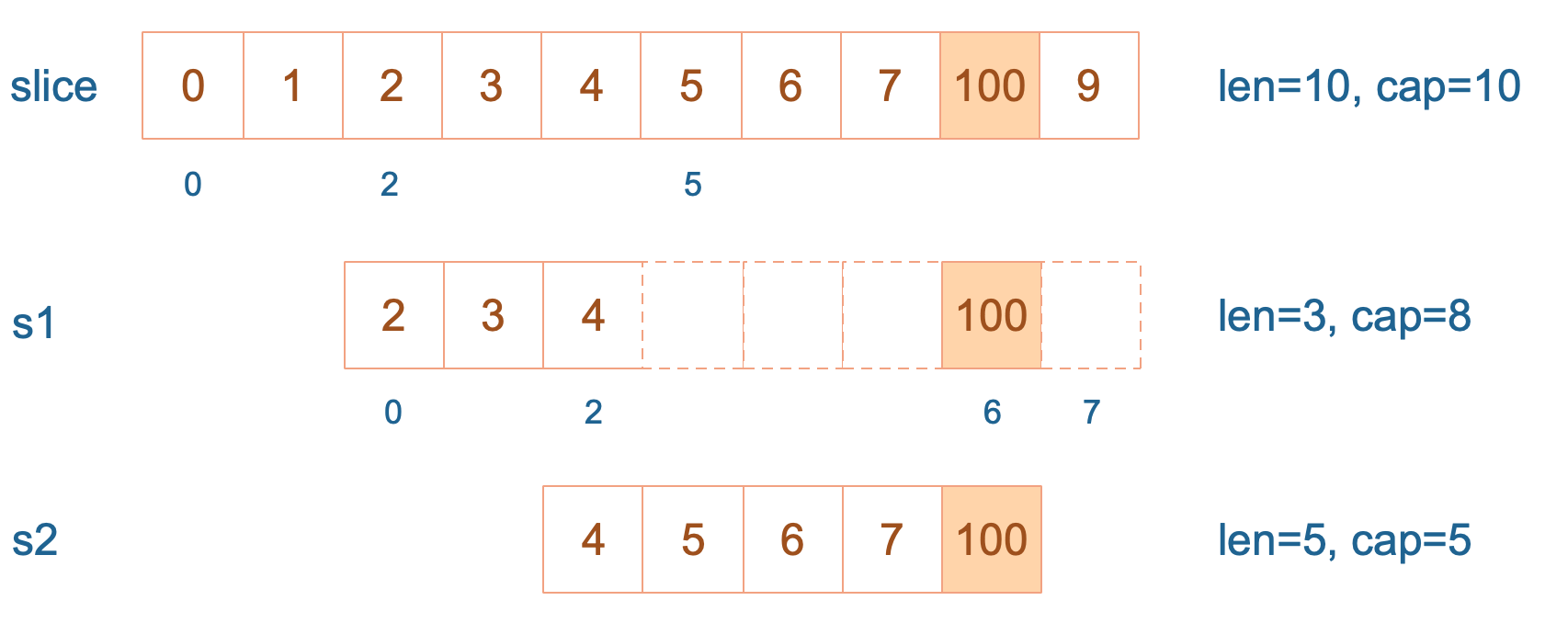
接着,向 s2 尾部追加一个元素 100:
go
s2 = append(s2, 100) s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。
再次向 s2 追加元素200:
go
s2 = append(s2, 200) 这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。
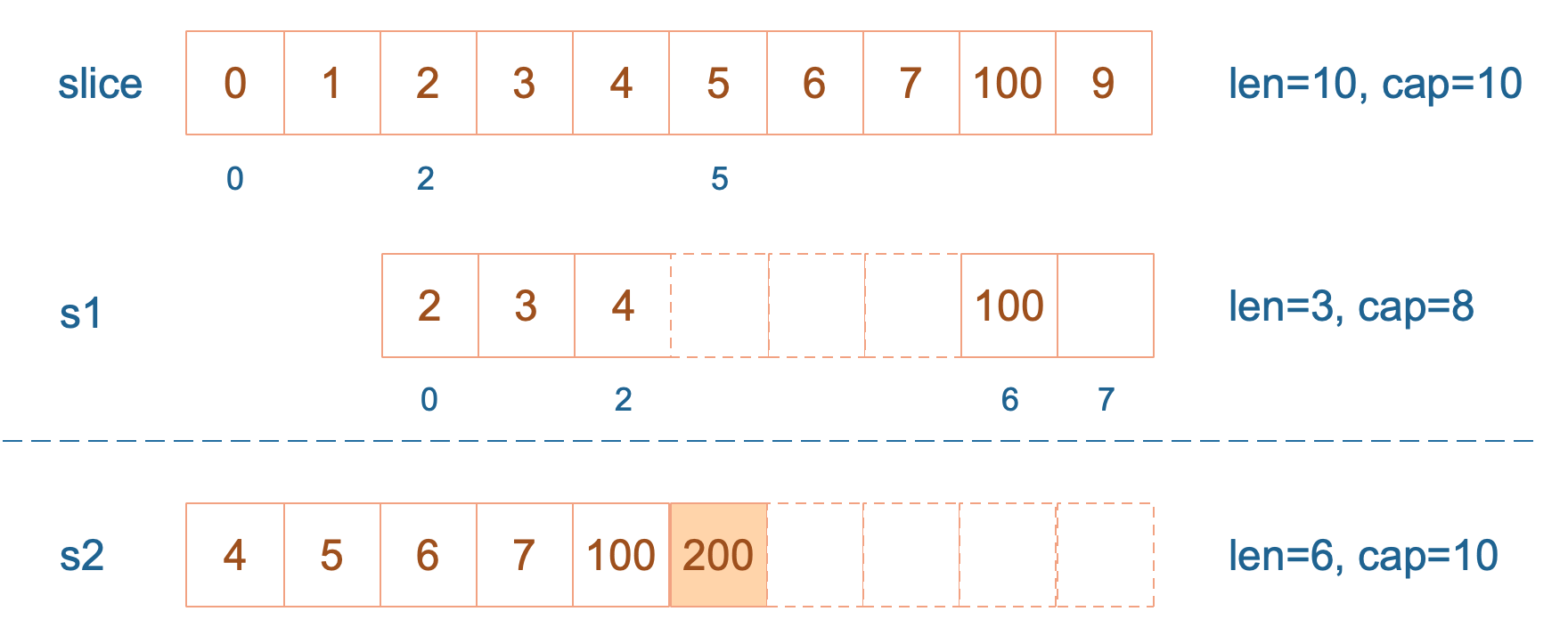
最后,修改 s1 索引为2位置的元素:
go
s1[2] = 20这次只会影响原始数组相应位置的元素。它影响不到 s2 了,人家已经远走高飞了。
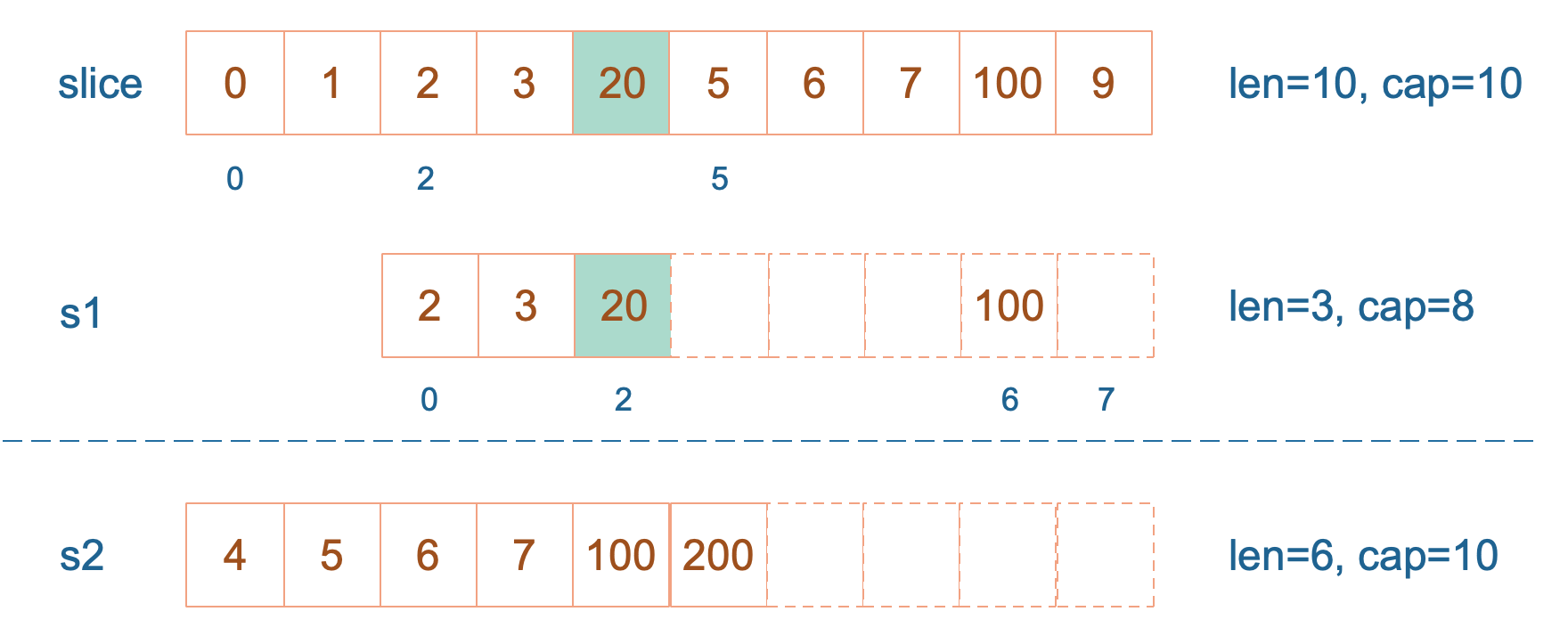
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
参考链接
2.《Go学习笔记》