文章目录
- 前言
- 1、出发点
- 2、方法
-
- 2.1.符号说明
- [2.2.Efficient Adaptive Decision Learning](#2.2.Efficient Adaptive Decision Learning)
- [2.3.Open-World Wildcard Learning](#2.3.Open-World Wildcard Learning)
- 3、实验结果
- 总结
前言
本文介绍一篇来自Tencent的开放词汇和世界检测结合的论文:Yolo-uniow,开源地址。
1、出发点
本篇论文相当于开辟了一个新任务,将开放词汇检测 和世界检测融合到一个任务:在给定一系列text prompt后,除了检测出对应单词的边界框,还要将其余未知的物体检测为"Unknown"。贴一张论文示例图:

2、方法
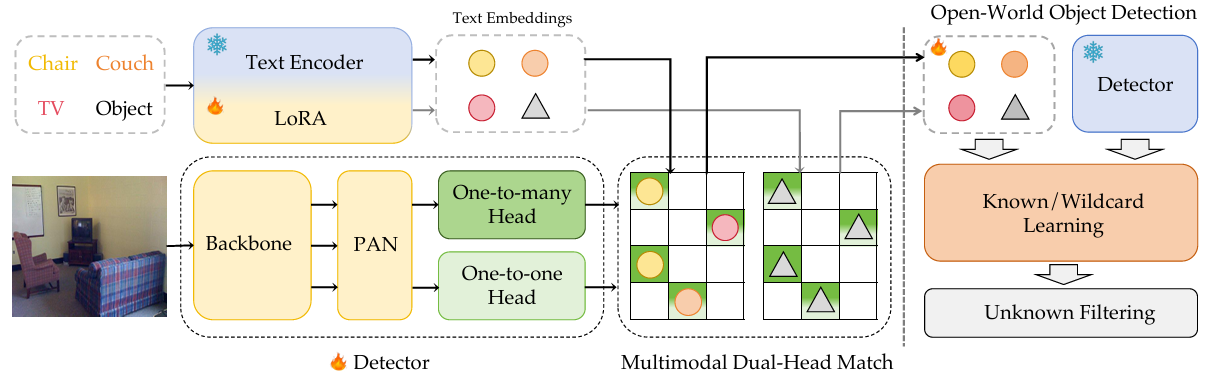
底下是论文总体结构图,在yolo-world基础上衍生出来的,总体来看结构比较简单,Detector用到的是yolov10,包含两个assign head: one2many和one2one;TextEncoder启用了LoRA微调,然后设计了一个通配符Wildcard Learning策略(其实就是object类别的嵌入向量),来挖掘Unknown物体。下面将逐一介绍。
2.1.符号说明

上述三个标黄的公式其实就是论文要实现功能。其中 c k c_k ck表示已知的文本类别; C u n k C_{unk} Cunk为未知的类别, T w T_w Tw就是通配符wildcard learning;当然,作为开放世界检测模型,需要能够不断从Unknown中迭代出新类别来更新 c k c_k ck,也就是第3个公式中表达意思。
2.2.Efficient Adaptive Decision Learning
论文创新点之一,但实际上就是 LoRA微调 TextEncoder。
2.3.Open-World Wildcard Learning
这里主要介绍下通配符学习策略,看模型是如何在train stage筛选Unknown物体的。先说两个子训练stage:
- 先训练open-vocabulary-detector,即完成类似yolo-world的训练;
- 设置可学习嵌入向量wildcard embedding,代表含义是 object,监督信息是所有box;
- 在完成上述训练后,需要将两个部分结合起来,将wildcard embedding发现所有物体的能力迁移到open-vocabulary部分:但结合时候会出现问题,因为通配符检测结果跟open-vocabulary的一部分检测框是重叠的,需要过滤掉。而将未过滤的则是 Unkonwn 物体,将其交给可学习嵌入向量Unkonwn Wildcard。
而具体筛选策略就是通过底下公式:

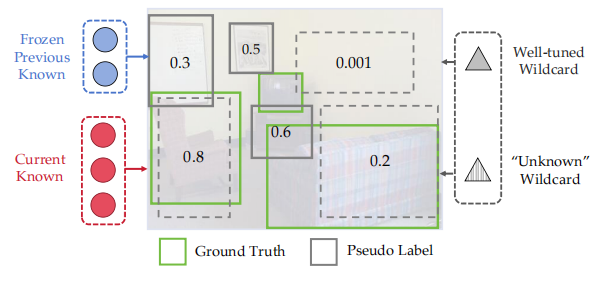
也可以按照下图示例说明:当迭代发现新的类别即CurrentKnown时,跟绿色的GTbox做监督训练。而Well-tuned Wildcard检测出 0.0001和0.2和0.8的虚线框,其中0.001因阈值太低过滤掉,而0.2去分配给Unkonwn Wildcard,而0.8因跟GTbox交并比过大也被过滤掉了 。
3、实验结果
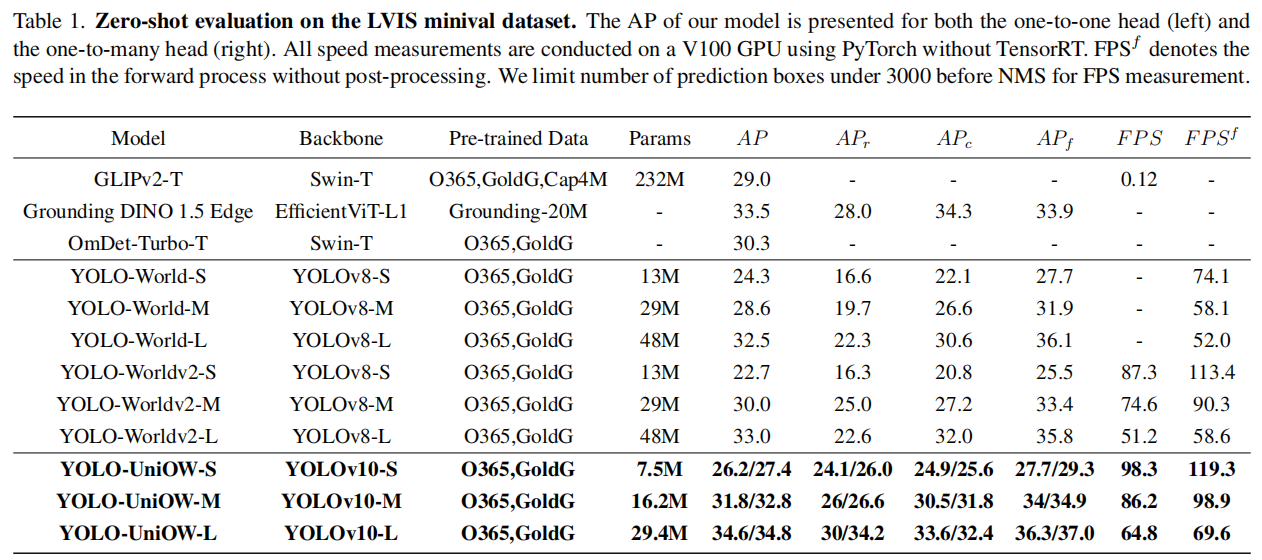
比yolo-world高。
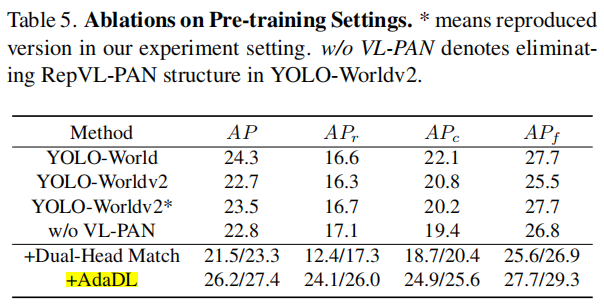
LoRA微调TextEncoder涨点儿明显。
总结
总体来说结合起来挺有意思,从另一个角度来解决open-world问题。