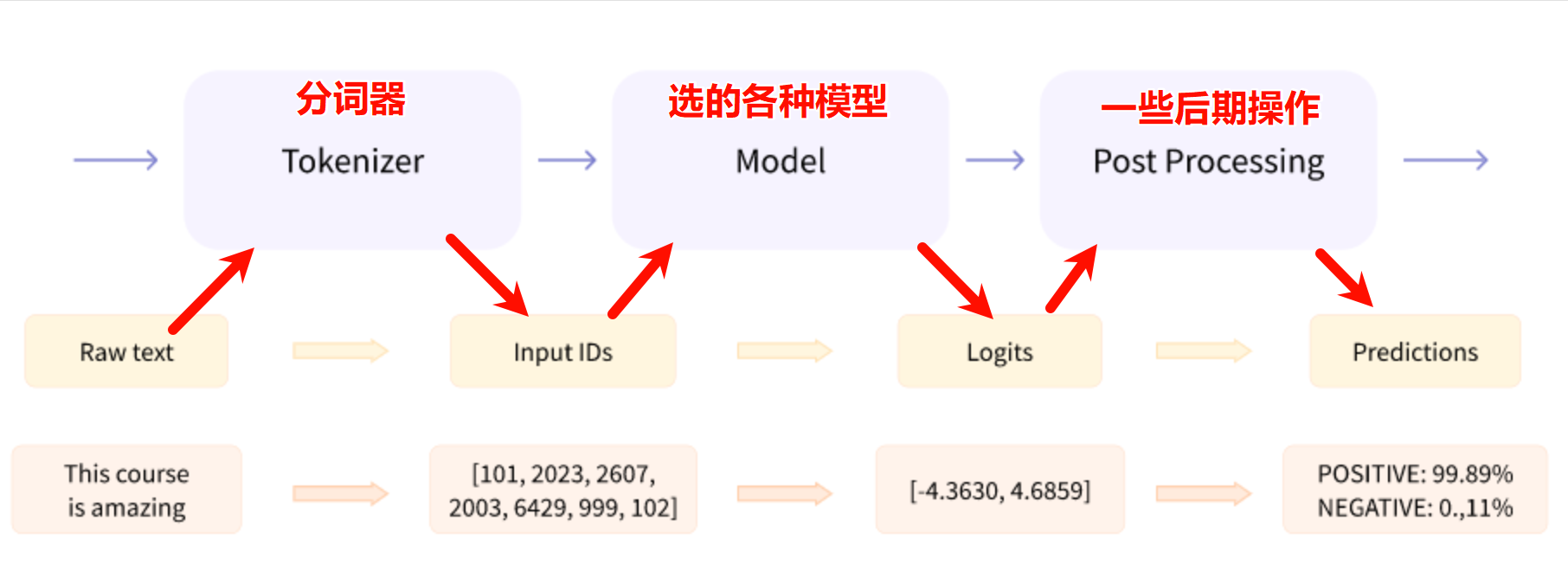
自然语言处理(Natural Language Processing, NLP)是计算机科学与人工智能领域中的一个重要分支,旨在使计算机能够理解、分析、生成和处理人类语言。NLP的基本流程通常包括以下几个关键步骤:
1. 文本预处理 (Text Preprocessing)
在处理原始文本数据时,通常需要进行一系列的预处理步骤,以便提高后续处理的效果。
- 分词 (Tokenization): 将一段文本切分成一个个单独的词或字符。对于英文,通常是按空格分词;对于中文,通常使用基于词典的分词算法。
- 去除停用词 (Stopword Removal): 停用词是指在分析中不提供实质意义的常见词,如"的"、"是"之类的词。去除这些词有助于减少计算负担。
- 词干提取 (Stemming) 或 词形还原 (Lemmatization): 这一步骤是将词语还原为其基础词根或标准形式。例如,"running"会被还原为"run"。
- 去除噪声 (Noise Removal): 移除文本中的无关信息,如HTML标签、特殊字符等。
2. 特征提取 (Feature Extraction)
从文本中提取出有用的特征,用于后续的模型训练。常见的特征提取方法包括:
- 词袋模型 (Bag-of-Words, BoW): 将每个词语作为一个特征,统计文本中各个词语的出现频率。
- TF-IDF (Term Frequency-Inverse Document Frequency): 该方法衡量词语在文档中的重要性。词频越高且在其他文档中出现频率越低的词语,通常对当前文档越重要。
- Word2Vec / GloVe: 这些是通过神经网络训练得到的词向量模型,可以捕捉词语的语义信息,解决传统词袋模型忽略语境和语义的问题。
3. 文本表示 (Text Representation)
将文本转换为机器可以理解的格式(通常是数值形式)。这一步骤可以通过以下方法完成:
- 词嵌入 (Word Embedding): 通过词向量模型(如Word2Vec、GloVe、FastText)将每个词映射到一个稠密的向量空间。
- 句子/文档嵌入 (Sentence/Document Embedding): 使用更高级的模型,如BERT、GPT等,获得整段文本的嵌入表示,这些表示捕捉了文本的深层语义。
4. 模型训练 (Model Training)
使用机器学习或深度学习模型对文本进行分析和预测。常见的任务包括分类、回归、序列标注等。
- 监督学习: 在标签已知的情况下,使用如逻辑回归、支持向量机(SVM)、随机森林等算法进行训练。
- 深度学习: 对于复杂的NLP任务,通常使用卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)、Transformer等深度学习模型。
5. 模型评估 (Model Evaluation)
训练好的模型需要进行评估,以判断其在任务上的表现。常见的评估指标包括:
- 精确率 (Precision): 测量模型正确预测为正例的样本占所有预测为正例样本的比例。
- 召回率 (Recall): 测量模型正确预测为正例的样本占所有真实为正例样本的比例。
- F1-score: 精确率和召回率的调和平均值,综合衡量模型的准确性和召回能力。
- 准确率 (Accuracy): 正确预测的样本占所有样本的比例。
6. 模型优化 (Model Optimization)
通过调整模型的超参数(如学习率、正则化系数等)以及选择合适的训练数据集和特征,进一步提升模型的性能。
7. 应用与部署 (Application & Deployment)
一旦模型训练和评估完成,可以将其应用到实际场景中,例如:
- 情感分析:分析文本的情感倾向,如正面、负面或中性。
- 命名实体识别 (NER):识别文本中的实体,如人名、地名、日期等。
- 机器翻译:将一种语言的文本翻译成另一种语言。
- 对话系统:开发智能客服、虚拟助手等应用。
- 文本生成:根据给定的输入生成相关的文本,如新闻生成、创作辅助等。
8. 后处理与反馈 (Post-processing & Feedback)
在实际应用中,可能还需要对模型的输出进行后处理,或者利用用户反馈对模型进行持续优化。
总之,NLP的基本流程涵盖了从文本数据的获取、处理、特征提取到模型训练和应用的全过程。