2025年5月6日,智源研究院在法国巴黎举行的GOSIM全球开源创新论坛上发布Chinese-LIPS中文多模态语音识别数据集,该数据为智源研究院联合南开大学共同构建。
在语音识别技术飞速发展的背景下,多模态语音识别正逐步成为学术界和工业界的研究热点。相较于传统依赖音频的识别方法,多模态语音识别通过引入视觉信息(如唇动特征、语义图像、幻灯片等),显著提升了系统在嘈杂环境、多说话人场景以及术语密集内容下的鲁棒性与识别准确率。

数据集获取方式
Github地址:
https://github.com/flageval-baai/Chinese-LiPS
HuggingFace地址:
https://huggingface.co/datasets/BAAI/Chinese-LiPS
魔搭社区地址:
https://www.modelscope.cn/datasets/BAAI/Chinese-LiPS
Datahun地址:
https://data.baai.ac.cn/datadetail/Chinese-LiPS
当前,已有若干较为成熟的英语多模态语音识别数据集,如LRS系列、How2、SlideSpeech等,在推动视觉辅助语音识别技术发展方面发挥了重要作用。然而,这些数据集在视觉模态的构建上仍存在明显局限:
-
信息类型不全面:部分数据集仅包含唇读信息,缺乏有效的语义上下文支持;而另一些则仅提供语义线索,如幻灯片或语境图像,但无法保证唇部区域的清晰可见与音频同步性。能够同时提供高质量唇读特征与语义视觉信息的多模态数据集仍极为稀缺。
-
数据发展尚处初期:在中文领域,此类数据资源处于空白状态,尚无公开数据集能够全面覆盖真实教学、讲解、科普等复杂场景下的多模态表达需求。
智源研究院联合南开大学共同打造并开源了Chinese-LiPS数据集。作为首个"唇读信息+幻灯片语义信息"结合的中文多模态语音识别数据集,Chinese-LiPS数据集面向中文讲解、科普、教学、知识传播等复杂语境,致力于推动中文多模态语音识别技术的发展。
研究团队以 Chinese-LiPS 数据集为依托,针对语音识别性能提升,开展了一系列严谨的评测实验。
实验结果显示,在仅采用语音单模态输入的情况下,模型的字符错误率(CER)为 3.99%。当将语音、唇读信息、通过 OCR 技术从幻灯片提取的文本以及从图像和图形内容中获取的语义信息进行融合时,模型的字符错误率显著下降至 2.58%。
进一步对错误类型进行深入分析发现,唇读信息在减少删除错误方面发挥了重要作用。由于唇读能够捕捉到与发音相关的细节,在实际应用场景中,诸如填充词、因犹豫而未完整表达的语音片段等容易在语音识别中缺失的部分,借助唇读信息可有效补充;而幻灯片信息对于降低替换错误成效显著,幻灯片中所包含的丰富的语义和上下文信息,在面对专业词汇、地名等具有特定领域属性的词汇识别时,能够为模型提供关键的识别线索,从而大幅提高识别的准确性。
评测结果显示,多模态信息融合能够显著提升语音识别系统的性能,为语音识别技术的发展提供了新的思路与方向。
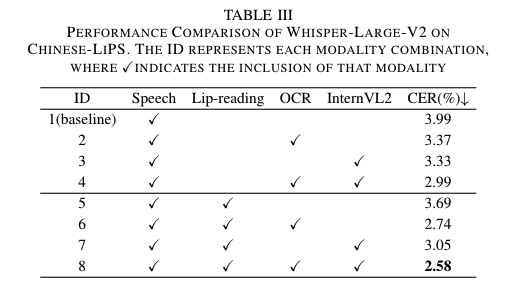
Chinese-LiPS评测实验结果
该数据集具备以下四大核心特点:
-
数据规模大:Chinese-LiPS总时长约为100小时,包含36,208条高质量语音片段,由207位专业讲者录制,具备良好的代表性与多样性。
-
覆盖主题丰富:内容涵盖科学技术、健康养生、文化历史、旅游探索、汽车工业、体育赛事等9大热门领域,主题分布均衡,充分体现了真实教学与讲解类语境下的表达特点与术语密度。
-
**高质量幻灯片制作:**由领域专家设计内容并参与标注,确保幻灯片图文信息的准确性与专业性。PPT内容结构清晰、设计精美,包含丰富的图像与视觉语义信息,而非单一文字堆砌。
-
**高质量视频录制:**视频由专业讲者在安静环境中录制,画面高清,涵盖唇读视频(720P)与幻灯片视频(1080P)两类模态,保障语音与唇动精准对齐,确保数据质量一致可靠。
-
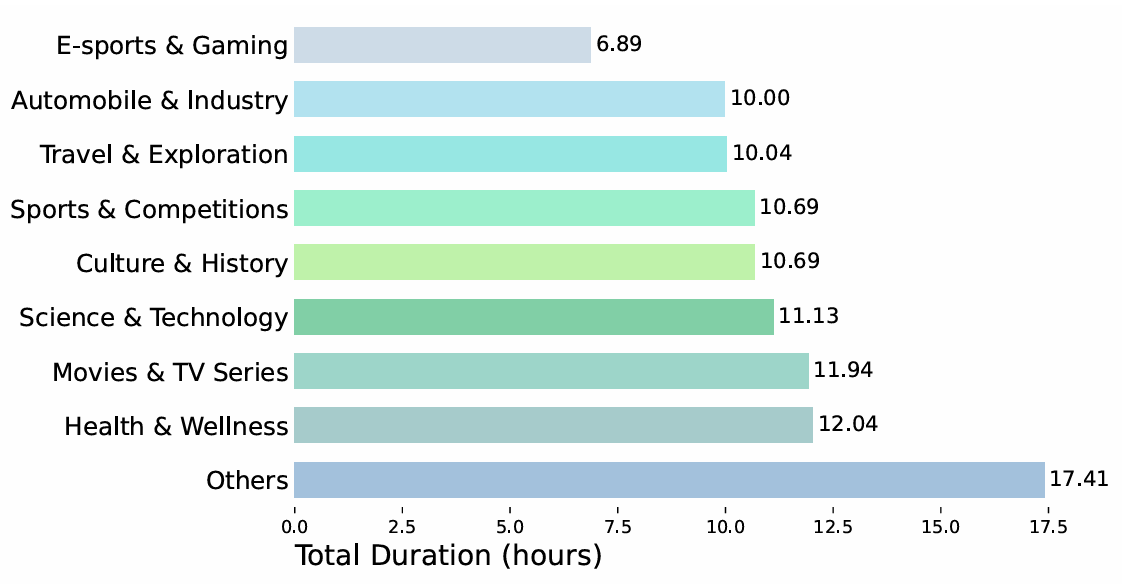
Chinese-LiPS数据集中每个主题的时长分布
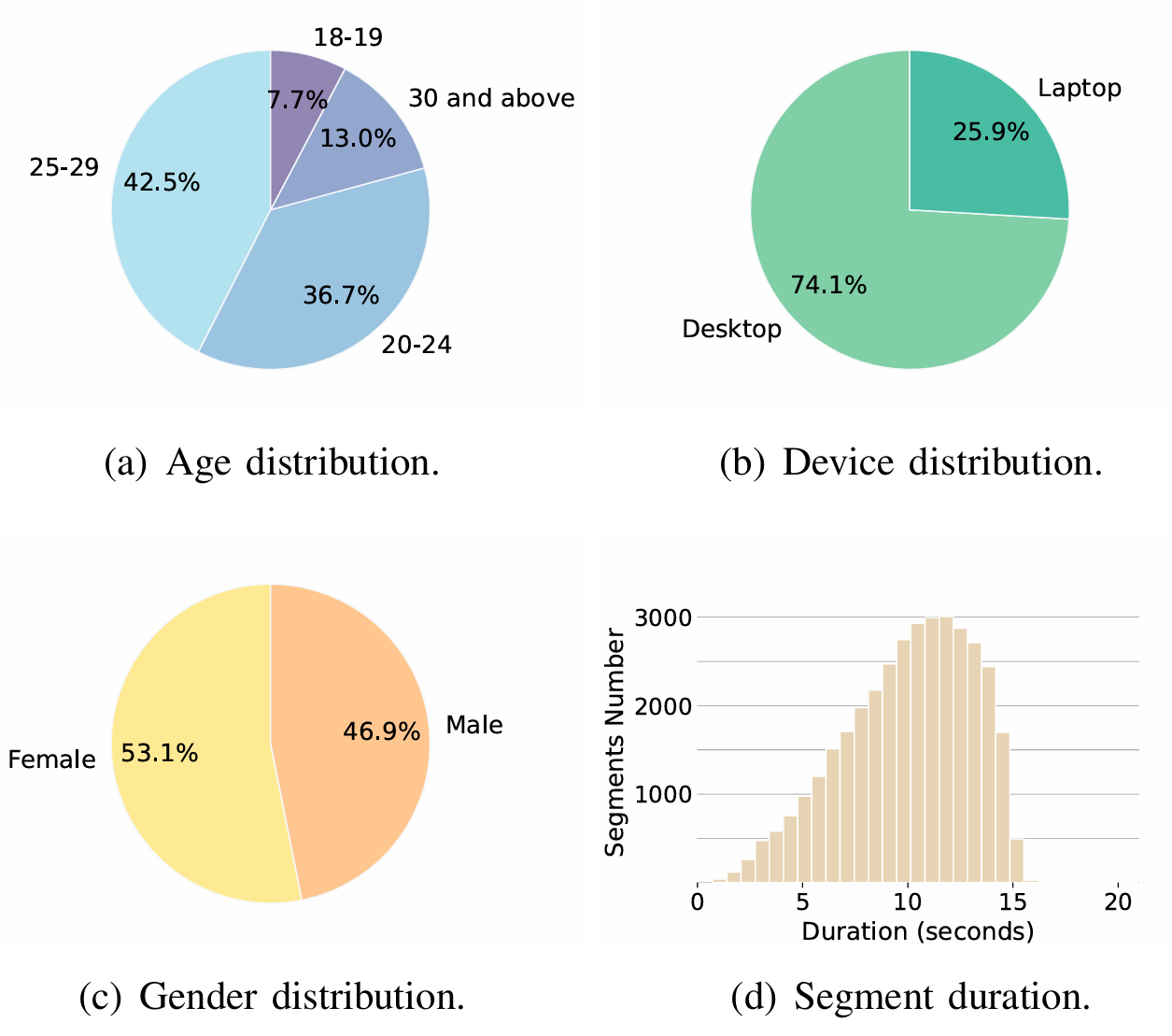
Chinese-LiPS数据集数据的分布情况
希望Chinese-LiPS数据集能够为从事语音识别、多模态融合、教育AI、虚拟讲解人等方向的研究者提供关键资源,共同推动中文智能语音技术的进步。
