📝前言:
这篇文章我们来讲讲Linux------动静态库链接原理
🎬个人简介:努力学习ing
📋个人专栏:Linux
🎀CSDN主页 愚润求学
🌄其他专栏:C++学习笔记,C语言入门基础,python入门基础,C++刷题专栏
目录
- 一,目标文件
- 二,ELF文件
-
- ELF文件格式的特点
- [1. ELF形成可执行](#1. ELF形成可执行)
- [2. ELF可执行加载](#2. ELF可执行加载)
- 三,理解链接与加载
一,目标文件
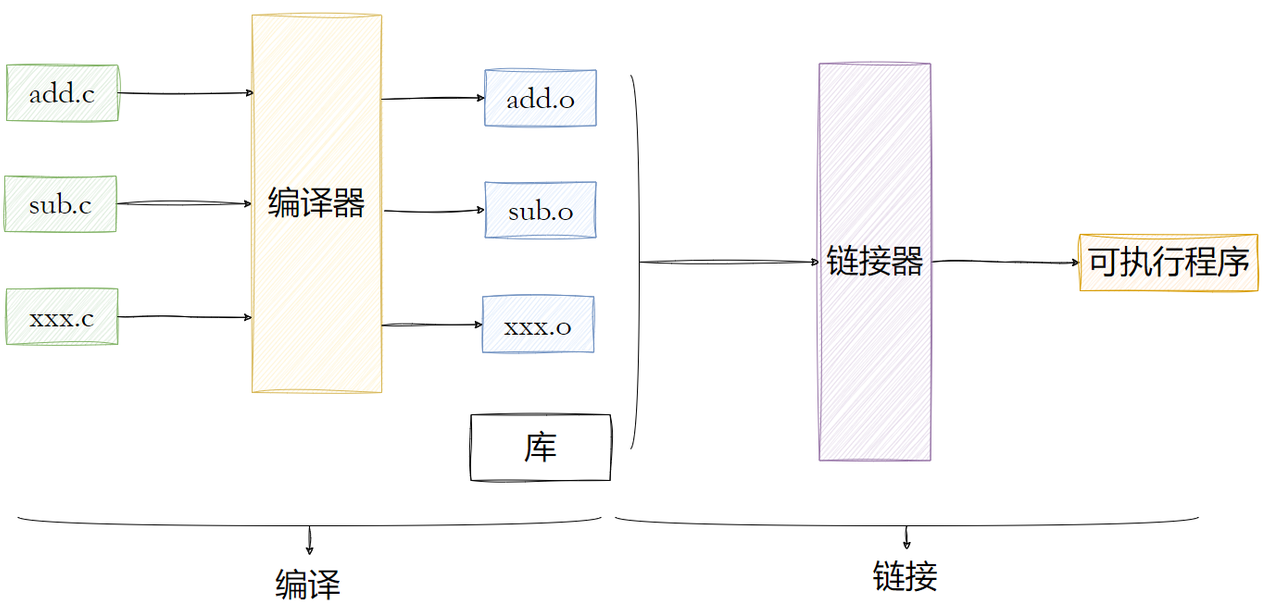
我们都知道,形成可执行需要经过 编译 + 链接两个步骤。当.c文件经过编译后形成的.o文件就叫做可重定位/可重定向目标文件。
当我们只有一个.c文件被修改时,我们只需要对修改的文件进行重新编译就行了,其他文件不需要。
二,ELF文件
.o文件,动静态库,可执行文件,内核转储(core dumps)都是ELF格式的二进制文件。
ELF文件格式的特点
ELF文件被划分成很多个节
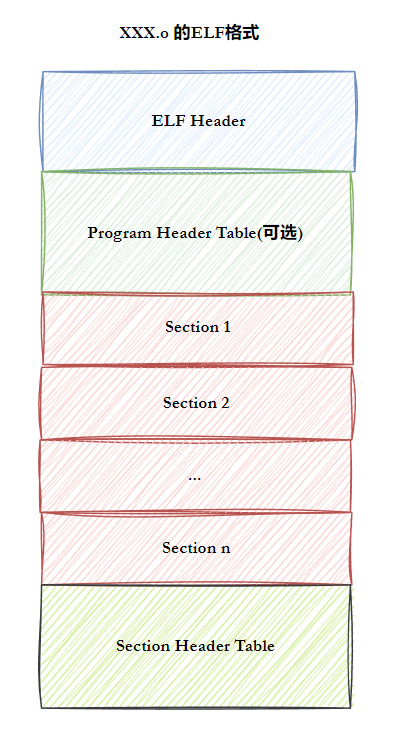
ELF Header:描述文件的全局属性,主要作用是定位⽂件的其他部分Program Header Table列举了所有有效的段(segments)和他们的属性。表里记着每个段的开始的位置和位移(offset)、长度。(链接阶段,有合并以后才会生成Program Headers)【segments是什么后面讲】- 用来描述整个ELF文件
Section就是节,不同的数据会被存储到不同的节中。如代码节存储了可执行代码,数据节存储了全局变量和静态数据等Section Header Table用来描述每个节的信息
1. ELF形成可执行
- 将多份 C/C++ 源代码,翻译成为⽬标
.o⽂件 - 将多份
.o⽂件section进行合并(合并是:链接的过程之一)
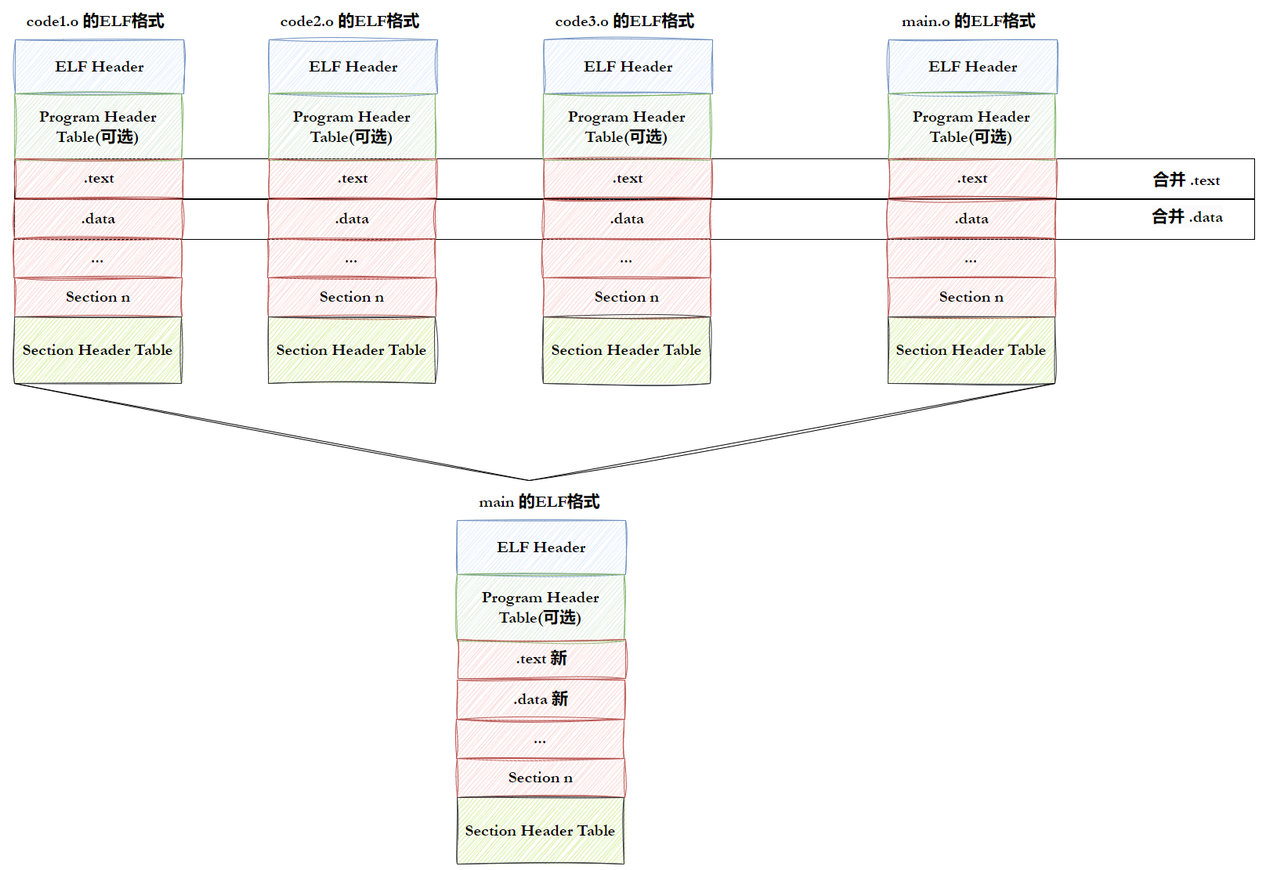
简单来说,就是把多个.o文件 中具有相同特性的Section合并成一个大的Segment
2. ELF可执行加载
- 一个ELF文件在加载到内存 的时候,也会把这个文件中具有相同特性(比如:把只读的代码段和只读数据合并)的
Section合并,形成segment - 这个合并⼯作也已经在形成ELF的时候,合并⽅式已经确定了,具体合并原则被记录在了ELF的 程序头表(Program header table) 中
为什么要将Section合并?
- 为了减少页面碎片,提高内存使用效率。如果不进行合并,假设页面大小为 4096 字节(内存块基本大小,加载,管理的基本单位),如果
.text部分为4097字节,.init部分为 512 字节,那么它们将占用 3 个页面(.text两个 +.init一个),而合并后,它们只需 2 个页面。- 将具有相同属性的
section合并成⼀个大的segment,可以实现不同的访问权限,从而优化内存管理和权限访问控制
具体查看
Section查看
查看可执行程序的Section(我的可执行名称叫test):
cpp
readelf -S test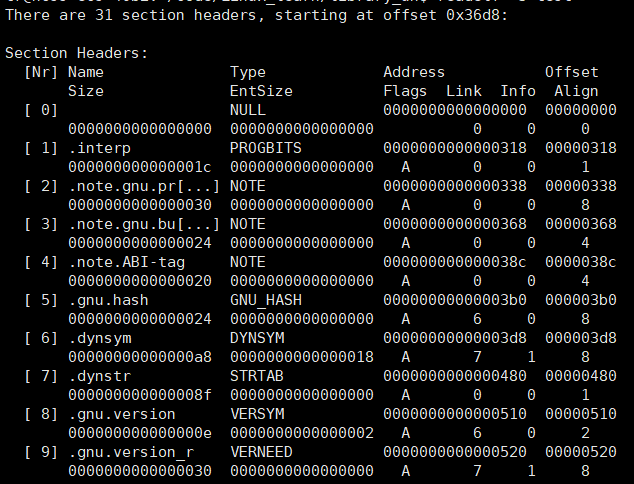
我们可以看到Section header table对每个Section的描述
查看可执行程序的Segment:
cpp
readelf -l test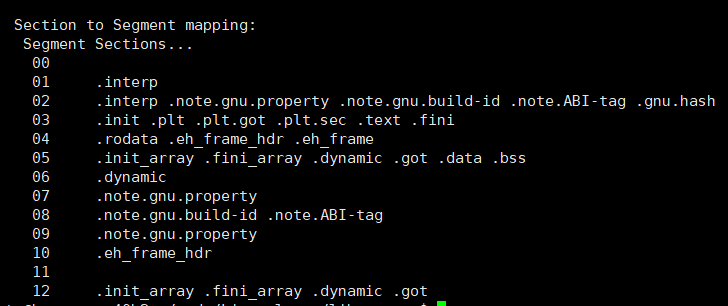
在图片中,我们就可以看到有哪些Section被合并成了一个Segment
提几个重要的Section:
text节 :保存了程序代码指令的代码节。data节 :保存了初始化的全局变量和局部静态变量等数据。.rodata节 :保存了只读的数据,如一行C语⾔代码中的字符串。.bss节 :为未初始化的全局变量和局部静态变量预留位置(对于未初始化的全局变量,我们没必要真正开辟空间,只需要在.bss里面描述出有多少未初始化的就行).symtab节 : Symbol Table 符号表,就是源码里面那些函数名、变量名和代码的对应关系。.got.plt节 (全局偏移表 - 过程链接表):.got节保存了全局偏移表。.got节和.plt节⼀起提供了对导⼊的共享库函数的访问⼊⼝,由动态链接器在运行时进行修改。
Segment查看
我们还可以看到其他信息:
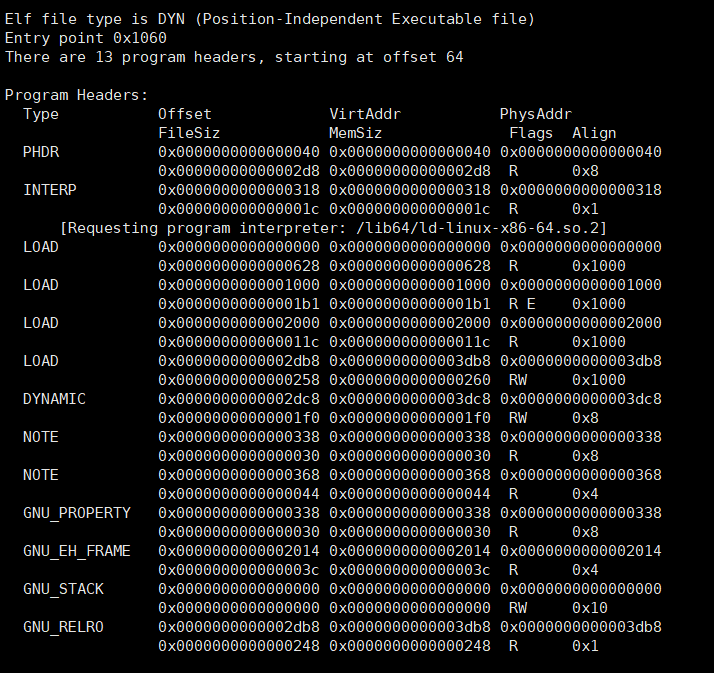
我们可以看到Program Header table对每个段的描述
你会不会很好奇,为什么可执行程序既有Section又有Segment?
其实这只是ELF 文件提供 2 个不同的视图/视角来让我们理解这两个部分:
Section是链接视图(Linking View),面向开发者/工具链。用于编译和链接阶段,供编译器、链接器和调试工具使用Segment是执行视图(Execution View),面向操作系统。用于程序加载和运行时,指导操作系统如何将文件映射到内存
ELF Header查看
用命令:
cpp
readelf -h test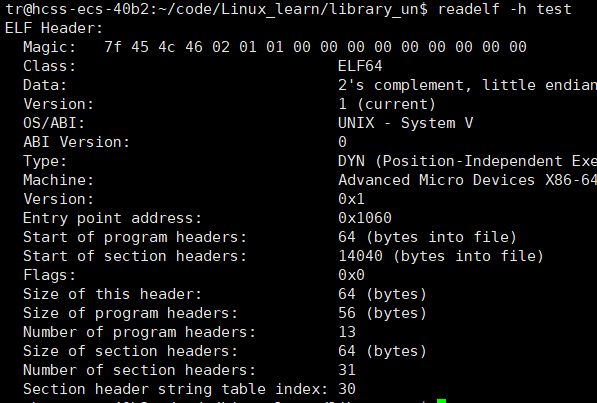
- 我们可以看到
ELF Header保存着一些大小 / 入口信息,用于定位⽂件的其他部分。 - 系统通过
Magic来判断文件是不是ELF的格式。Entry point(标识可执行程序的入口地址【虚拟地址】)
三,理解链接与加载
1. 静态链接与静态库加载
因为静态库就是都是.o文件打包的,并且静态库在形成可执行的时候,会把库中的函数实现直接拷贝一份到可执行里面。所以研究静态链接,本质上是在研究.o文件是如何链接的。
test.c文件内容
cpp
1 #include "mystring.h"
2
3 int main()
4 {
5 char* msg = (char*)"hello world\n";
6 print(msg); // 调用自定义的print
7 return 0;
8 }查看编译后的符号表
符号表
符号表用于记录了目标文件中定义和引用的符号相关信息,如:函数名、变量名、全局常量名等。
会用一个长字符串表来存储,像这样:

然后通过\0来划分他们,通过\0我们可以记录每个符号在串中的起始结束下标,就可以很快得到这个符号的名称。
cpp
readelf -s test.o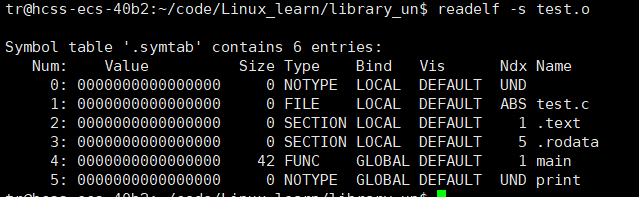
可以发现print是UND的,就是:没有定义
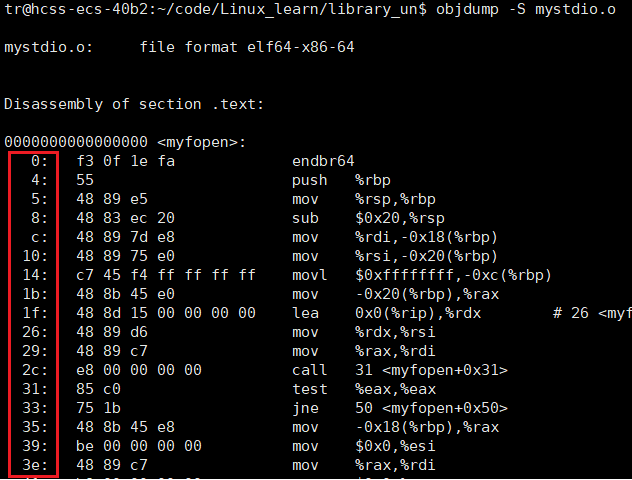
查看反汇编目标文件的内容
cpp
objdump -d test.o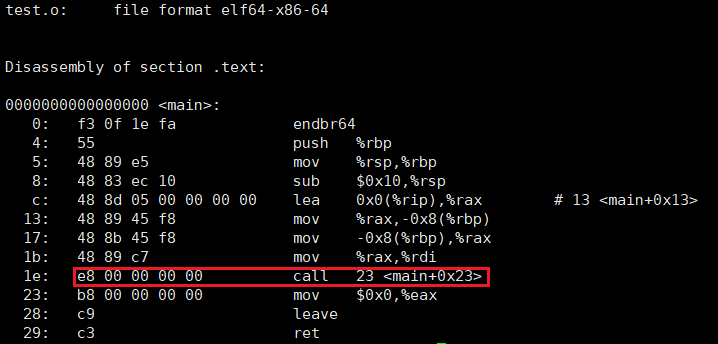
- 这里,调用
print函数,但是它的跳转地址被设置成了0。 - 这是因为:在编译 test.c 的时候,编译器知道有
print函数(因为有声明)但是不知道具体的实现(即:不知道print在内存的哪里)。因此,编译器只能将这两个函数的跳转地址先暂时设为0 - 链接的时候!
.o文件被合并,就会修改call中不确定的地址。(这就是静态链接,也是外部符号的地址重定位步骤)
2. ELF加载与进程地址空间
---个ELF程序,在没有被加载到内存的时候,有没有地址呢?
答案:有的,有虚拟地址!
---个ELF程序,在没有被加载到内存的时候,采用"平坦模式"(就是地址下标从 0 开始连续编址),对自己的代码和数据进行统⼀编址
最左侧的就是ELF的虚拟地址!严格意义上应该叫做逻辑地址(起始地址 + 偏移量)
- 进程的
mm_struct、vm_area_struct在进程刚刚创建的时候,就是用ELF的统一编址的信息来初始化的。(每个segment有自己的起始地址和自己的长度,用来初始化内核结构中的[start, end]等范围数据) - 同时,记载到内存中的可执行文件也有对应的物理内存地址
- 这样
mm_struct的虚拟地址有了,程序的物理内存地址也有了,就可以填写页表了!!! - 所以:虚拟地址机制,不光OS要⽀持,编译器也要支持
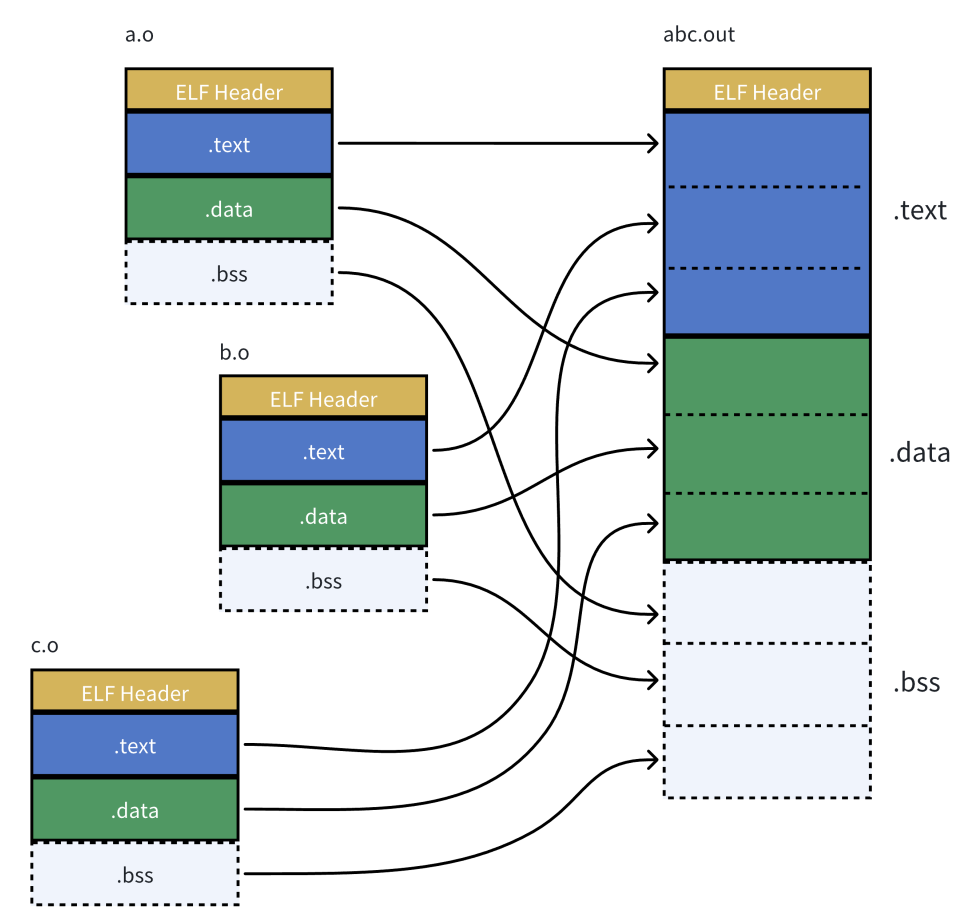
静态链接总结
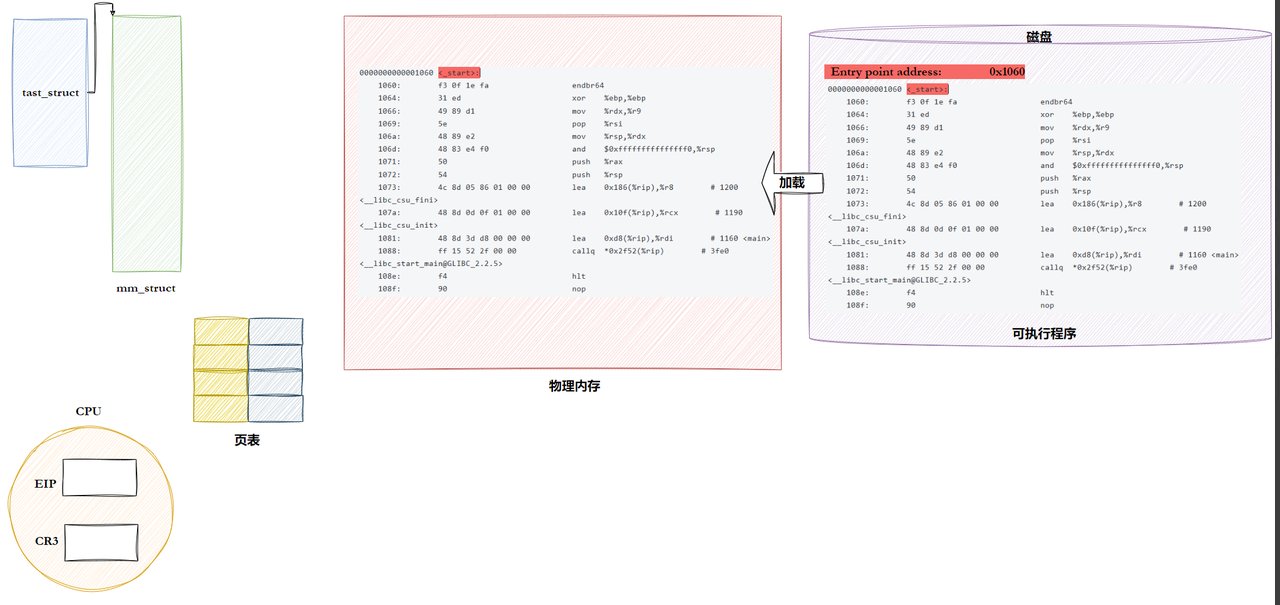
通过这张图梳理一遍静态链接:
- 首先,ELF文件在没有加载到内存时,已经有了统一编址
- 链接前,
.o文件彼此不知道对方,所以没有办法call函数调用的具体地址 - 在链接阶段,会把可执行程序中需要的静态库的库方法,拷贝一份给可执行程序。(这个时候,方法有了明确的地址,就可以进行地址重定位,把
call的内容修改成具体的方法地址) - 当程序加载到内存中时,用统一编址初始化
mm_struct,再结合实际物理内存地址,就可以构建好页表 - 并将程序的入口
Entry被传入到CPU的寄存器EIP中,就可以拿着EIP中的Entry进入程序并执行
也就是说:静态链接在链接阶段,已经完成了地址重定位操作,运行阶段已经不需要静态库了,所以是编译时(链接阶段)链接!
3. 动态链接与动态库加载
- 对于动态链接,动态库并不会直接拷贝到可执行程序的代码中。
- 所有程序是共用内存中的一份动态库代码的
那么,进程之间,又是如何共享库的呢?
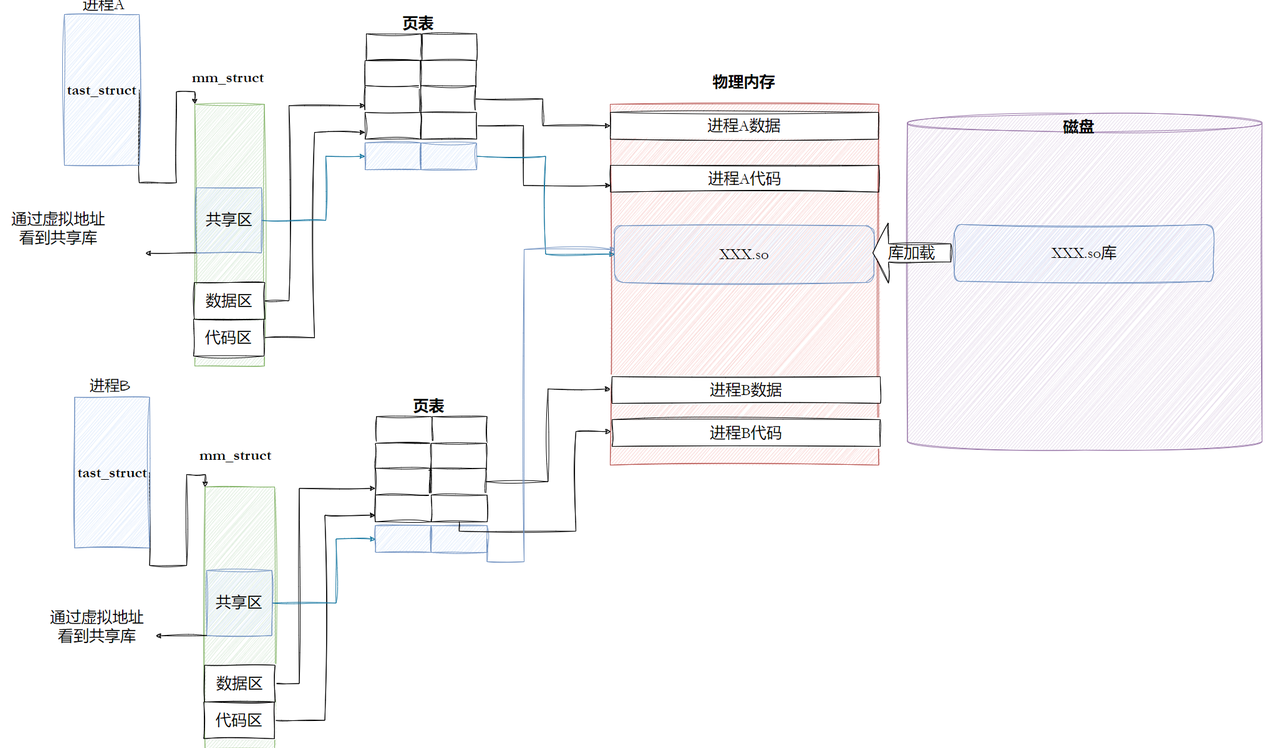
先不挖细节,先说整体轮廓:
- 动态库也是文件,需要独立加载到内存中,有自己的内存区域
- 当动态库加载到内存中时,动态库的ELF格式会用来初始化进程
mm_struct的共享区 - 当在运行代码区的代码时,遇到了动态库的方法,就会从代码区跳转到共享区,得到对应方法的虚拟地址,然后就可以用虚拟地址通过页表映射找到内存中的代码了
看似没啥问题,但是,我们把目标放在从代码区跳转到共享区这一步:
如果要跳转,则代码区应该知道对应方法的内存地址。可是,如果动态库是独立的文件,只有程序加载的时候,动态库才能真真被加载ELF的虚拟内存地址里。才能有对应方法的地址。所以动态链接,也就被推迟到了加载时。
所以:
- 因为动态库也是独立的文件,也要加载到进程的
mm_struct,但是在加载之前,动态库还没有映射到mm_struct上(即:动态库的同一编址还没有用来初始化对应的mm_struct里面对应的区域) - 所以在编译链接时:可执行程序里面的代码段,就不知道对应动态库方法
call。(无法像静态链接一样,直接填上方法具体的地址) - 只能等到程序加载到内存里以后,再填上。(这就是加载时链接)
- 但是,因为当可执行程序加载到内存中以后,代码区具有只读性,无法修改。所以我们需要借助一个中间层,来修改
call的地址。 - 这个中间层就是GOT(全局偏移量表),我们让GOT表位于
.data区(可修改),每一个位置存放着:方法 + 对应方法的库名称【本质是:方法在库中的偏移量 + 库名称】 - 而,原来的代码中
call:GOT表的起始地址 + 要调用的方法在GOT表中的偏移量 - 当我们加载程序时,动态库被加载到了
mm_struct,就知道了动态库的虚拟起始地址。 - GOT表就会被修改,里面每个位置存储的(通过:方法在库中的偏移量 + 库名称)就变成了对应方法的绝对虚拟地址 【这样就相当于间接改了代码区的
call】,此时页表也会被填写 - 这就完成了重定位,完成了动态链接
和文件系统关联起来:
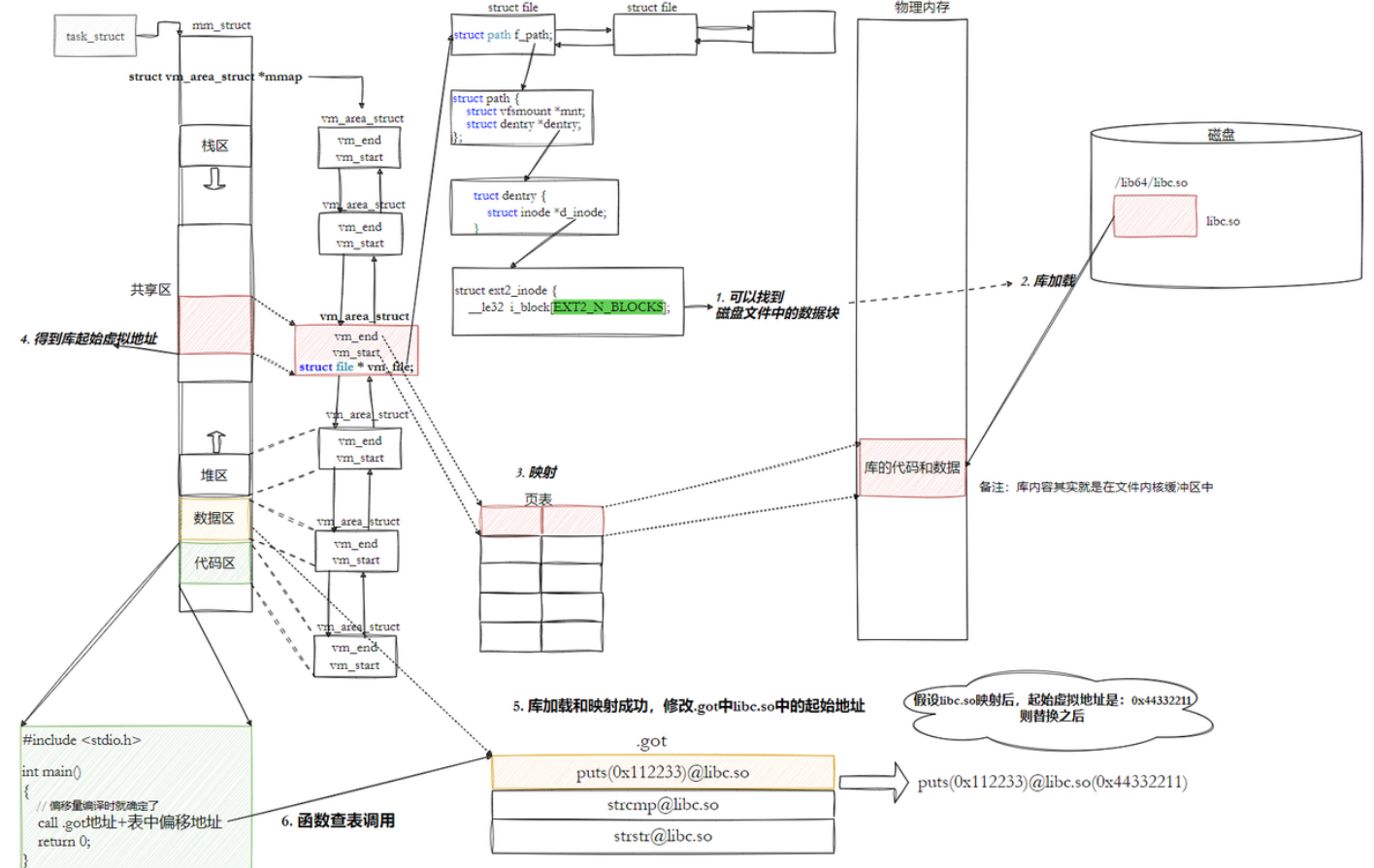
这种⽅式实现的动态链接就被叫做 PIC 地址⽆关代码 。换句话说,我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运⾏,并且能够被所有进程共享,这也是为什么之前我们给编译器指定-fPIC参数的原因,PIC=相对编址+GOT
下面在谈几个更细节的知识
动态链接器
【以下内容由AI生成】

/lib64/ld - linux - x86 - 64.so.2这就是动态连接器,加载动态库、符号解析与重定位、处理库依赖、初始化库函数...都是由它完成的。
在C/C++程序中,当程序开始执行时,并不会直接跳转到 main 函数。实际上,程序的入口是 _start ,这是⼀个由C运行时库(通常是glibc)或链接器(如ld)提供的特殊函数。在 _start 函数中,会执⾏⼀系列初始化操作,其中就包括动态链接:
_start 函数会调⽤动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调⽤和变量访问能够正确地映射到动态库中的实际地址。
库间的依赖
库也会调⽤其他库!!库之间是有依赖的,如何做到库和库之间互相调⽤也是与地址⽆关的呢?
答:库中也有.GOT,和可执行⼀样。
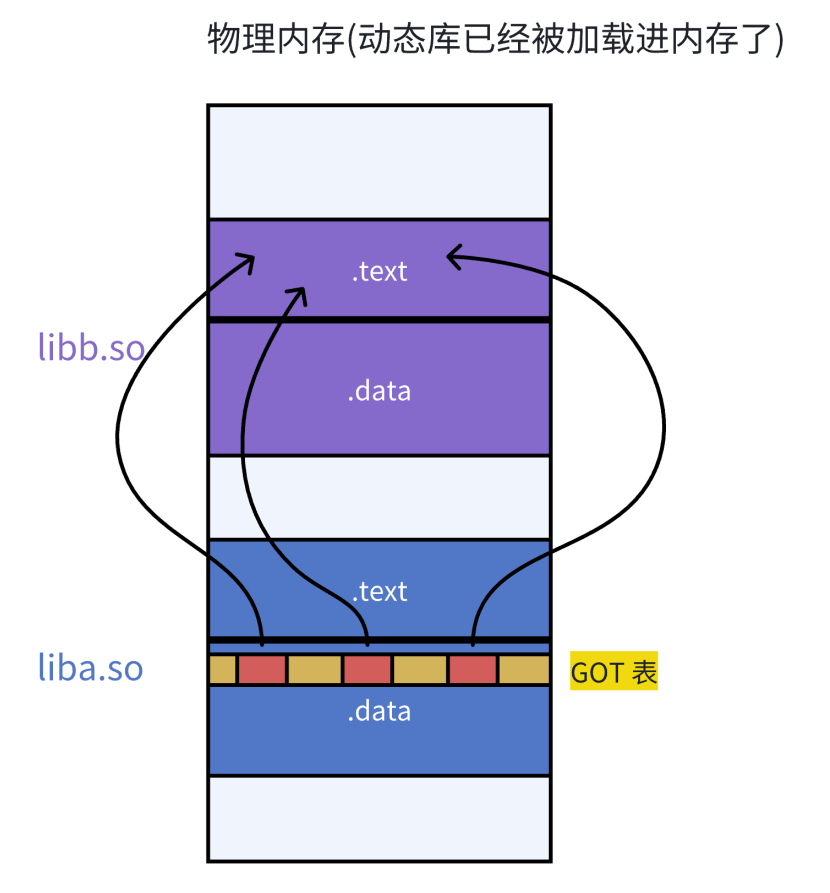
PLT
PLT:延迟绑定(Lazy Binding)
作用:
- 避免在程序启动时解析所有动态库函数(如果库函数很多的话,就很浪费时间,因为有些库函数可能没被使用)
- 而是在函数首次被调用时才进行地址解析
更具体的比较复杂,就不讲述了。
🌈我的分享也就到此结束啦🌈
要是我的分享也能对你的学习起到帮助,那简直是太酷啦!
若有不足,还请大家多多指正,我们一起学习交流!
📢公主,王子:点赞👍→收藏⭐→关注🔍
感谢大家的观看和支持!祝大家都能得偿所愿,天天开心!!!