背景
写这个文章的作用主要是做一些总结和梳理,特别是正对大数据场景下的实时写入更新策略 COW 和 MOR 以及 Delete+Insert 的技术策略的演进,
这也适用于其他大数据的计算存储系统。该文章主要参考了Primary Key table.
分析总结
Starrocks 的主键表主要是用来加速实时更新的效率,以及在做Adhoc查询的时候能够加速查询速度。在paimon等数据表格式中,一开始都是采用的MOR的策略来达到实时写入的目的,但是在读取的时候,就得进行合并的操作才能获取真正的数据,这种方式虽然能加速数据的写入速度,但是在读取的时候就会比较慢,采用Delete+Insert的方式,只会在写入的时候在DelVector增加一个标志位,读取的时候,只读最新的数据即可。大大的缩短了,数据读取的时间。
Starrocks的Unique表和Aggreate表采用的是 MOR 的策略,这个会存在读放大的问题。除此之外,由于存在Merge操作,谓词和索引也不能下推到底层的数据源中,即使下推了,也不能起到过滤的作用,这个严重的影响到了查询的效率。
对于Starrocks的主键索引,读写主键表的路程如下(参考Starrocks的官方文档):
-
对于写: Starrocks 先把对应的tablets的主键索引加载到内存,对于删除操作,Starrocks首先使用主键索引找到每行对应的数据位置,并在
DelVector中把数据行标记为删除。对于更新操作,会转换为Delete + insert操作,除了在DelVector增加删除标志外,还会写入最新的数据,同时主键索引也会被更新。
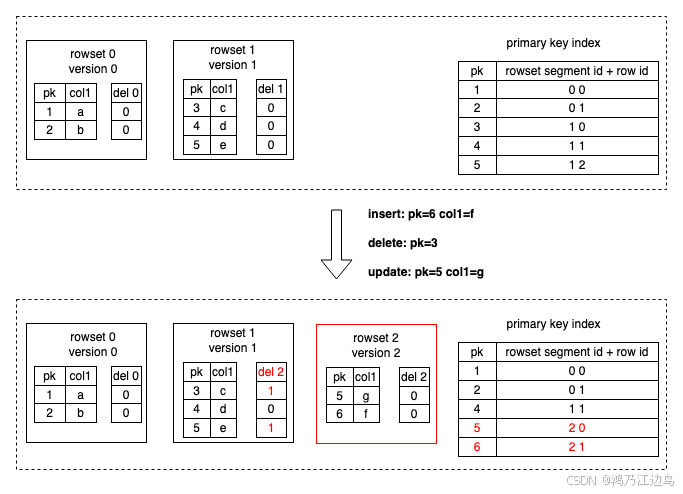
-
对于读: 由于历史的数据在写入的时候,已经被标志为了删除,所以只需要读取主键索引对应的信息就可以了,历史数据不需要再进行合并了。并且当底层的数据扫描的时候,可以利用谓词以及各种索引去减少扫描的数据量。因此查询性能得到大大的提升。
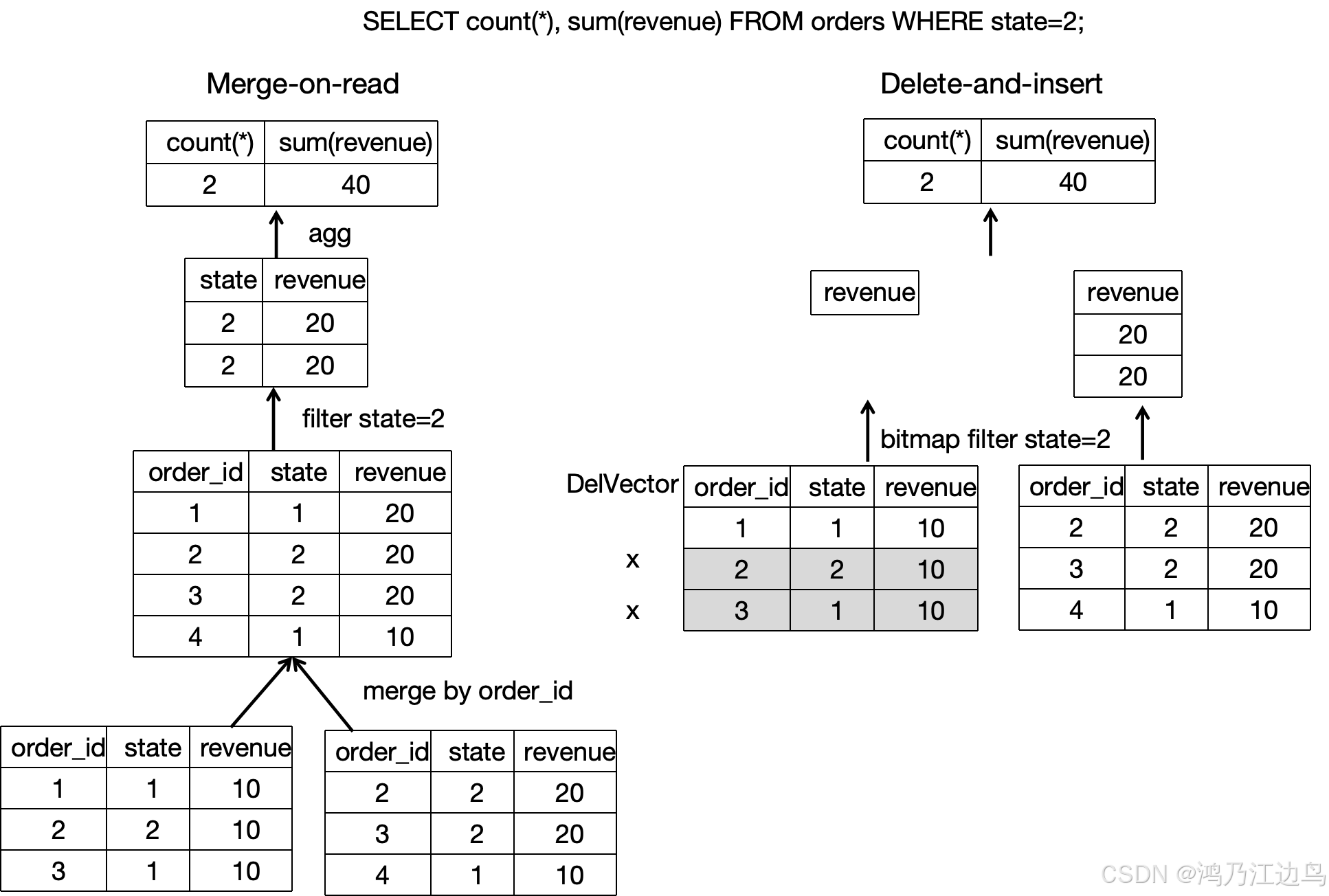
注意:
- DelVector 是 Rowset 级别的
- 主键索引会记录pk到rowsetId + segementId + rowId的映射关系