SgLang代码细读-1.从req到batch
代码入口 & 初始化
sglang/python/sglang/srt/entrypoints/http_server.py launch_server 主要分4个步骤:
- 启动下列进程 (_launch_subprocesses):
- TokenizerManager: 把输入的query进行tokenize
- DP=1: run_scheduler_process: 创建scheduler & 开始event_loop
- DP>1: run_data_parallel_controller_process: 初始化带负载均衡的DataParallelController, 开始event_loop
- Detokenizer: 重新将输出转为可阅读的文字输出, 返回http结果
- launch_dummy_health_check_server: 心跳保活接口
- api鉴权 & warmup请求
- 进程启动完成后启动http服务.
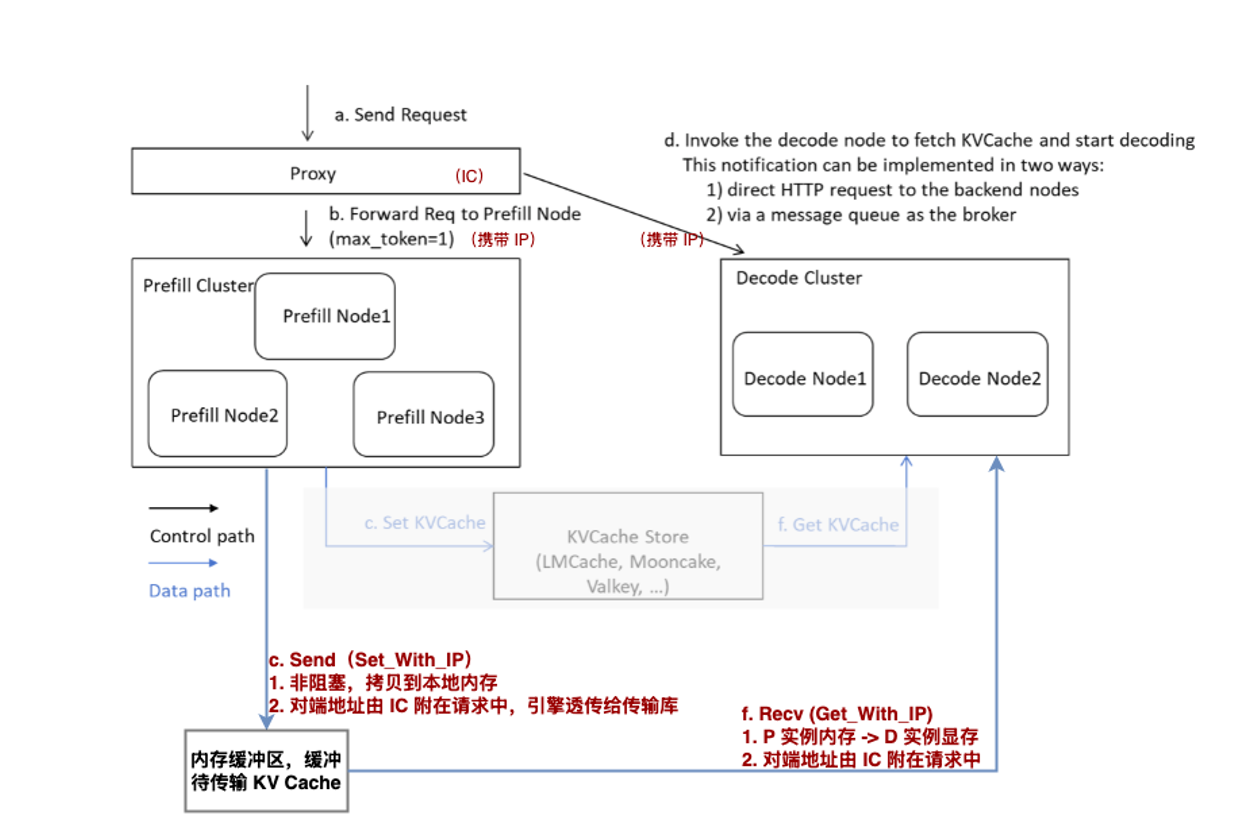
Tokenizer / Detokenizer
sglang/python/sglang/srt/managers/tokenizer_manager.py
1. 词表加载
get_tokenizer->AutoTokenizer.from_pretrained 从huggingface.io下载预训练好的tokenizer
词表的生成方式一般是通过统计方式取top词, 比较常见的有BPE, WordPiece, 例如BPE的训练步骤:
- 初始化词汇表: 基础单元为所有单字符
- 迭代合并高频字符对 :
- 统计所有相邻字符对的频率
- 合并频率最高的字符对,将其加入词表, 一直重复这个步骤直到达到目标词汇量
- 另外还有一部分特殊标记:
[UNK](未知词)、[PAD](填充)、[CLS](分类)、[SEP](分隔符)、MASK(掩码)、语言标记(,`)等。
- 保留合并操作: 记下所有的合并操作,用于后续对新文本的分词
2. 请求构造
每个节点都有一个http_server接受请求. sglang/python/sglang/srt/entrypoints/http_server.py generate_request()->_handle_batch_request()->send_to_scheduler.send_pyobj() 把请求发给rank0的scheduler
scheduler
只看了DP>1的情况.
DataParallelController
负载均衡 : node间请求是通过zmq的方式进行通信. 在node_rank=0接受原始请求(TokenizedGenerateReqInput), 也就是上面的send_to_scheduler的请求, 然后进行dispatch. 负载均衡采用round_robin/shortest_queue的方式, 其他节点接到请求后, 在handle_generate_request里把请求放到waiting_queue里面
Launch_schedulers
核心是launch_tensor_parallel_group这个函数, 这里根据一个开关 enable_dp_attention 进行逻辑的区分. 这个优化原理参考文档, 当模型结果中有MLA时, 如果我们在attention层使用了TP, 会导致KV结果被复制到多张卡上, 极大地浪费显存, 通过这个开关可以吧attn单独使用DP实现, 经过attn all_gather后在MOE层再进入TP逻辑. 这个函数中会计算各个device自己的PP/DP/TP rank并初始化到配置里.
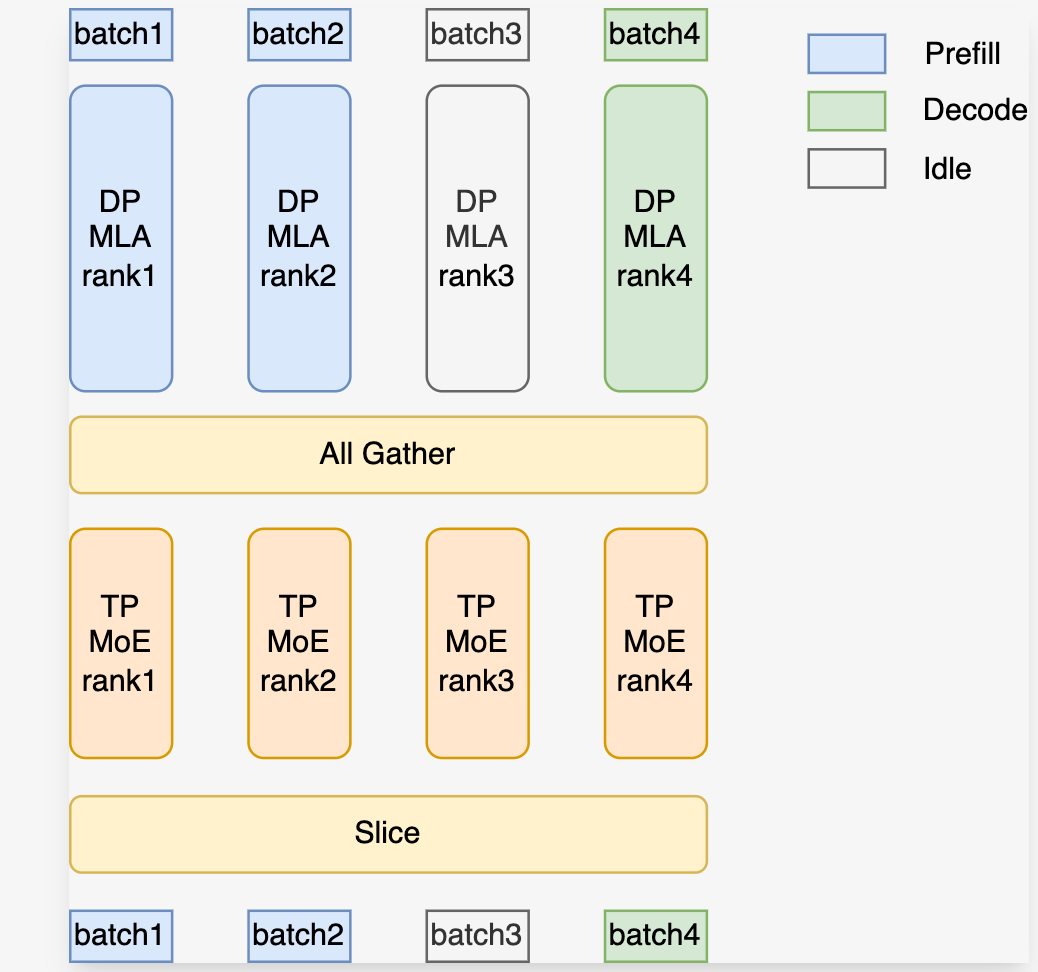
完成初始化后, 根据算好的rank启动run_scheduler_process进程, 这个函数做了下面几个事:
- 初始化logger
- 设置CPU亲和性:
SGLANG_SET_CPU_AFFINITY, 当启动scheduler进程的时候, 把GPU与对应范围的CPU核做黏合,也就是说,做了亲和性的线程或进程,只会在这一个CPU核上运行,只在这一个CPU核上被调度,且不会切换到其他的核上运行。开超线程(HT)的时候, bind范围需要根据逻辑核心数进行设置. - 根据prefill/decode启动不同的event_loop, 注意这里有个overlap配置, 参考设计文档, 如果不开这个优化, cpu和GPU逻辑完全串行, 比如batch1在GPU forward计算时, CPU空闲, 而实际上可以在这段时间跑batch2的前置batch逻辑(比如tokenizer)

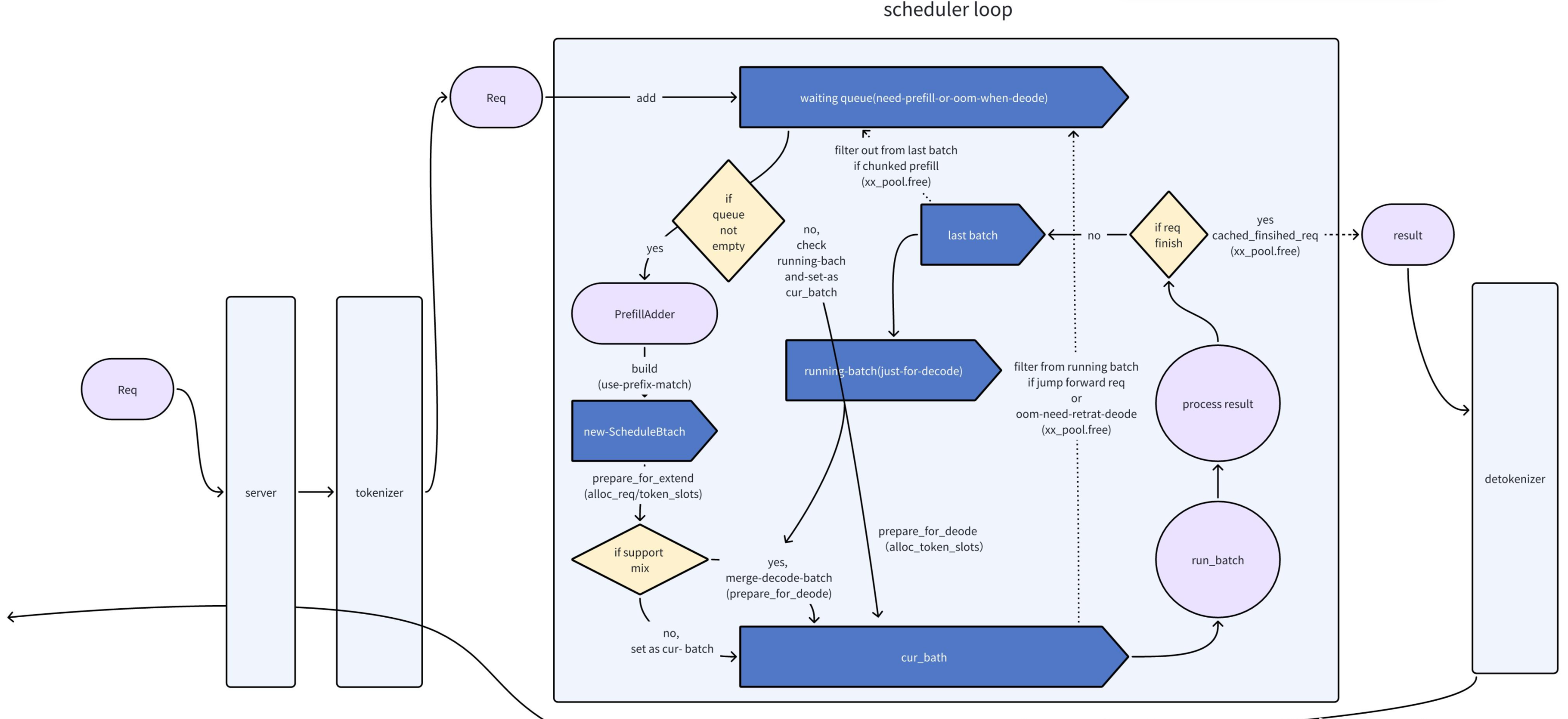
Event_loop
主要逻辑如图, 主要功能是把req处理成batch, 用于后续的计算backend开始forward
prefill (sglang/python/sglang/srt/disaggregation/prefill.py)
以event_loop_normal_disagg_prefill为基础看prefill中的逻辑. overlap省略
1. 接受处理请求(recv_requests & process_input_requests)
接受请求, 分几种并行方式来:
- PP: rank0 节点从tokenizer里接受请求list, 非rank0节点等待从上一个pp_rank节点的点对点请求.
- TP: 如果开启了enable_dp_attn, tp_rank0节点 把tokenizer相关的请求(TokenizedGenerateReqInput, TokenizedEmbeddingReqInput)视为work_req, 其他类型的视为control_req, 把这些请求都广播到同TP_group的其他节点
处理请求: TypeBasedDispatcher在这个Dispatcher内定义了每个请求类型和对应的处理方法, 心跳请求忽略
2. 从waiting_queue中pop请求
KVSender有这么几种状态: Bootstrapping(表示正在与远端节点建立连接和同步元数据), WaitingForInput(完成连接, 等待kvcache发送), Transferring(传输中)
核心函数: pop_bootstrapped, 步骤如下:
- poll_and_all_reduce: 调用每个请求里对应的kv_sender, 也就是mooncake/conn.py里的poll方法, 用来获取KVSender的当前状态, 通过all_reduce获取各个机器上的所有请求状态
- 把WaitingForInput状态的请求挑出来执行, 从内存池(ReqToMetadataIdxAllocator)中给这些请求分配首token的内存存储空间, 以及kv_sender初始化, TODO: 待弄清楚token_to_kv_pool分页的原因是否为保证访存连续性.
3.处理process_prefill_chunk:
把chunked请求从batch里过滤出来, 保留chunkCache
4.get_new_batch_prefill 从waitingQueue里根据优先级组合新batch (重要函数)
一.优先级计算(schedule_policy.py) calc_priority
policy策略主要分为两大类, 和tree_cache相关的和无关的. 涉及到cache命中的相关数据结构与逻辑在后文单独说.
无关的有:
- FCFS: first come first serve, 也是默认策略
- LOF: based on the longest output, 把waiting_queue按最长输出排序.
- RANDOM: 直接shuffle queue
有关的有:
- LPM: longest prefix, 根据最长前缀token匹配数排序
- DFS_WEIGHT: DFS方式计算req 最后一个node在treeCache中的权重再排序
二. 处理chunked_req
如果存在chunked请求, 之前把它从batch里过滤出来, 在init_next_round_input根据cache中已经处理完的前缀, 确定下一个batch中要处理的chunk长度和token.
在add_chunked_req中变更ids的偏移, 并且把chunked_req加到can_run_list里
三. 遍历waiting_queue
python
for req in self.waiting_queue:
#... 前面还有一些非核心逻辑,省略
if len(adder.can_run_list) >= self.get_num_allocatable_reqs(running_bs):
self.running_batch.batch_is_full = True
break
#对请求进行prefix_cache匹配, 确定在cache中的last_node, prefix_indices, 和input_len, 计算需要用多长的kvcache
req.init_next_round_input(
None if prefix_computed else self.tree_cache,
self.enable_hierarchical_cache)
#判断这个请求的token数和batch里已有的token总和是否打印max_tokens, 目标应该是防止显存超限
#对tree_cache.last_node加锁后操作, 增加last_node的引用计数, 防止被释放.
res = adder.add_one_req(
req, self.chunked_req, self.enable_hierarchical_cache)当batch满或是要处理的token数满后, 停止这个遍历循环, 然后把在can_run_list中的req从waiting_queue里剔除.
四.构建ScheduleBatch
ScheduleBatch.init_new: 从can_run_list中构建ScheduleBatch类
prepare_for_extend: 为batch内的数据分配显存, 如input_ids/seq_lens 等
5.prepare_dp_attn_batch
这个函数主要作用是统计其他DP的batch状态, 首先统计local的batch信息, 比如num_tokens, can_cuda_graph等, 通过all_gather汇聚所有DP的状态, 只要有其中一个DP存在非空的batch, 就把当前如果是空的local_batch填充一个idle_batch, 这个idle_batch的作用就是使得所有DP的运行状态保持同步, 比如其他DP有AllToAll的需求, 就可以在idle_batch中能够把对应的集合通信状态给同步运行
6.run_batch
run_batch: forward核心逻辑, 在下一个文章中详细解读
process_batch_result_disagg_prefill: 把完成forward的prefill结果启动send_kv_cache, 并添加到disagg_prefill_inflight_queue里面
process_disagg_prefill_inflight_queue: 使用all_reduce检查所有处于kv sending状态的请求, 对已经完成发送的req交给detokenizer进行处理.
7.开始下一轮循环
decode (sglang/python/sglang/srt/disaggregation/decode.py)
以event_loop_normal_disagg_decode为基础. 重点看下和prefill有区别的地方
1.请求处理
recv_requests & process_input_requests, 和prefill逻辑一致
2.从decode_queue里拿取完成kvcache通信的请求(process_decode_queue)
disagg_decode_prealloc_queue.pop_preallocated: Decode阶段请求进来后首先进入这个队列, 在pop时, 根据req的token数判断当前已pop出去的token总和是否大于阈值, 如果大于就暂停, 如果小于则可以对这个请求对应的kvcache分配显存, 主要目的是防止显存超限.
disagg_decode_transfer_queue.extend & pop_transferred: 把prealloc_queue pop出来的请求再填入transfer_queue, 把其中已经完成kv通信的请求挑出来, 把这些请求, 最后把这些请求加到decode模块的waiting_queue里面
3.ScheduleBatch构建(get_next_disagg_decode_batch_to_run)
decode整体是通过continus-batching的方式进行batch组合, 从而提升GPU利用率

last_batch.filter_batch(): 把上个batch里已经处理完的请求剔除.self.running_batch.merge_batch(last_batch): 把上个batch中没处理完的请求merge到running_batch里get_new_prebuilt_batch, 从waiting_queue里取出请求, 把当前batch填满到(min(self.req_to_token_pool.size, self.max_running_requests))update_running_batch((self.running_batch)): 检查batch里的请求是否有超显存的可能性, 如果有将部分请求拿出来再放回queue里(retract_decode), 分配decode tensor相关显存占用.
4.run_batch & process_batch_result (同prefill)
参考:
MFU概念和计算方法(Deepseek):
-
理论最大 FLOPs 计算:
-
计算设备(如 GPU)的理论最大 FLOPs(Floating Point Operations per Second)通常由设备的硬件规格决定。对于一个 GPU,它可以通过以下公式计算:
Theoretical FLOPs=2×CUDA 核心数×时钟频率(GHz)×每周期 FLOPsTheoretical FLOPs=2×CUDA 核心数×时钟频率(GHz)×每周期 FLOPs
-
这个计算可能会因为不同的硬件架构而有所不同,比如 Tensor Cores 的使用会影响 FLOPs 的计算。
-
-
实际执行的 FLOPs 计算:
-
对于给定的深度学习模型,计算在一次前向和后向传播中执行的 FLOPs。通常,模型的 FLOPs 计算可以通过分析模型的每一层(如卷积层、全连接层等)来完成。
-
例如,对于一个卷积层,FLOPs 可以通过以下公式计算:
FLOPs=2×输入通道数×输出通道数×核大小×输出特征图大小FLOPs=2×输入通道数×输出通道数×核大小×输出特征图大小
-
这个计算应包括所有正向和反向传播中的运算。
-
-
计算时间测量:
- 测量实际训练过程中执行这些运算所花费的时间。可以使用高精度计时工具来获取准确的时间数据。
-
MFU 计算:
-
使用以下公式计算 MFU:
MFU=实际执行的 FLOPs理论最大 FLOPs×执行时间MFU=理论最大 FLOPs×执行时间实际执行的 FLOPs
-
这个比率提供了模型在硬件设备上利用计算能力的程度。
-
解释和优化:
- MFU 值 :
- MFU 的值介于 0 和 1 之间,接近 1 表示计算资源利用率高,接近 0 表示利用率低。
- 高 MFU 通常表示计算资源被有效利用,而低 MFU 则可能意味着存在潜在的瓶颈或非计算密集型操作。
- 优化 MFU :
- 可以通过优化算法、调整模型结构、使用更高效的算子(如利用 Tensor Cores),以及调整批量大小等方式来提高 MFU。
- 通过识别并优化内存带宽、数据传输和算子执行效率,可以有效提高 MFU。
sglang阅读笔记: https://www.zhihu.com/column/c_1710767953182674944