3D-Mem 是用于具体探索和推理的3D场景记忆,来自CVPR 2025.
使用信息丰富的多视角图像,来表示场景并捕捉已探索区域的丰富视觉信息,
整合了基于前沿的探索,使智能体能够通过考虑已知和潜在的新信息,做出明智的决策。
本文分享3D-Mem复现和模型推理的过程~
下面是一个运行示例结果:

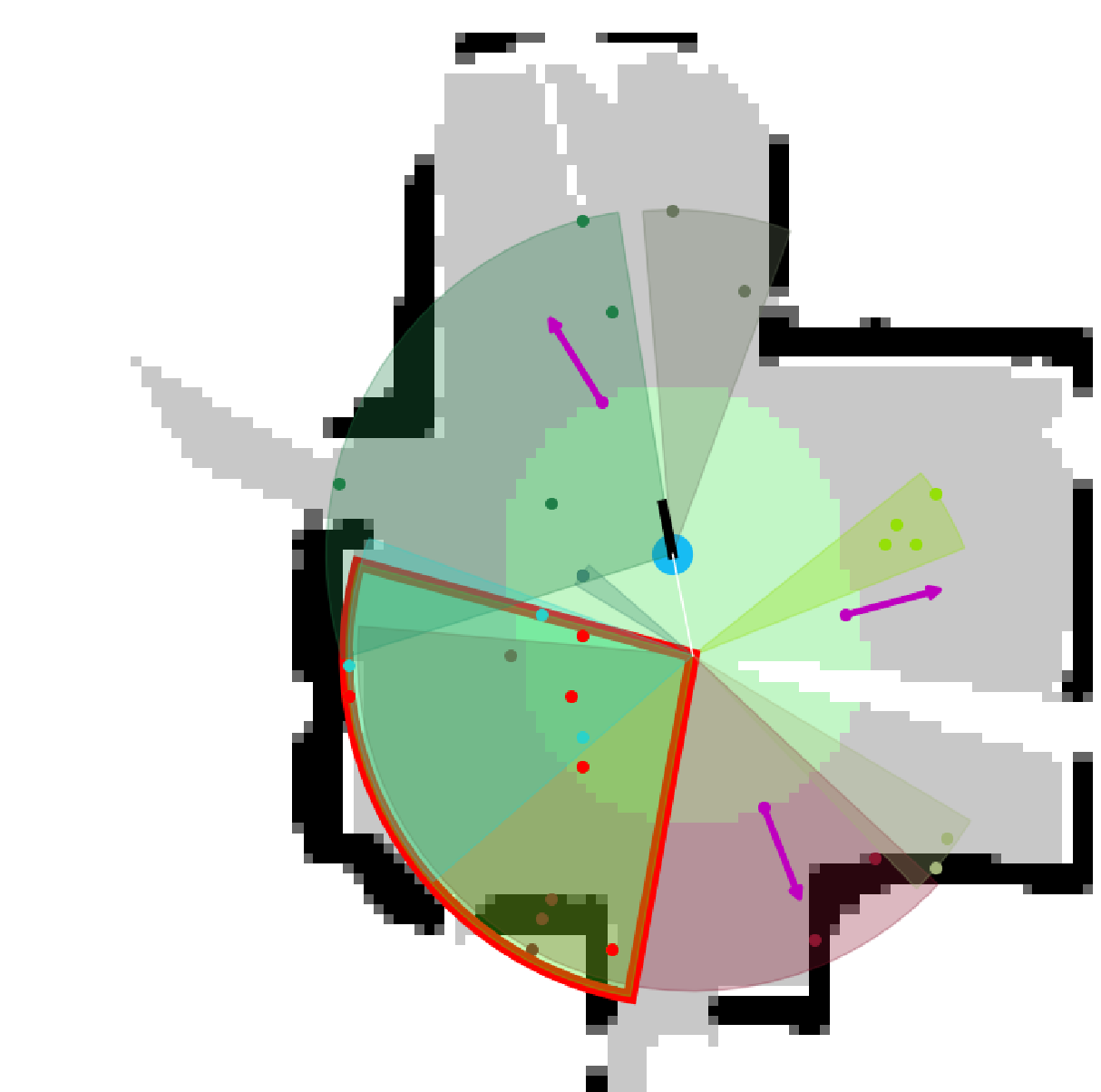
看一下占用地图的航向
下面是真实环境下,官方跑的demo,3D-Mem无需训练的设计,可以无缝适应真实的机器人,从而实现在现实世界中的部署

项目地址:https://umass-embodied-agi.github.io/3D-Mem/
1、创建Conda环境
首先创建一个Conda环境,名字为3dmem,python版本为3.9
进入3dmem环境
bash
conda create -n 3dmem python=3.9 -y
conda activate 3dmem然后下载代码,进入代码工程:https://github.com/UMass-Embodied-AGI/3D-Mem
git clone https://github.com/UMass-Embodied-AGI/3D-Mem.git
cd 3D-Mem2、安装habitat模拟器
我需要安装habitat-sim==0.2.5、headless 和 faiss-cpu
bash
conda install -c conda-forge -c aihabitat habitat-sim=0.2.5 headless faiss-cpu=1.7.4 -y等待安装完成~
3、安装 torch 和 pytorch3d
执行下面命令,进行安装torch:
bash
pip install torch==2.0.1 torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu118再安装pytorch3d:
bash
conda install https://anaconda.org/pytorch3d/pytorch3d/0.7.4/download/linux-64/pytorch3d-0.7.4-py39_cu118_pyt201.tar.bz2 -y4、安装依赖库
执行下面命令进行安装:
bash
pip install omegaconf==2.3.0 open-clip-torch==2.26.1 ultralytics==8.2.31 supervision==0.21.0 opencv-python-headless==4.10.* \
scikit-learn==1.4 scikit-image==0.22 open3d==0.18.0 hipart==1.0.4 openai==1.35.3 httpx==0.27.2等待安装完成~
5、安装clip
执行下面命令进行安装:
bash
pip install git+https://github.com/openai/CLIP.git打印信息
bash
Looking in indexes: https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
Collecting git+https://github.com/openai/CLIP.git
Cloning https://github.com/openai/CLIP.git to /tmp/pip-req-build-imrsh3kf
Running command git clone --filter=blob:none --quiet https://github.com/openai/CLIP.git /tmp/pip-req-build-imrsh3kf
Resolved https://github.com/openai/CLIP.git to commit dcba3cb2e2827b402d2701e7e1c7d9fed8a20ef1
Preparing metadata (setup.py) ... done
.....
Successfully built clip
Installing collected packages: clip
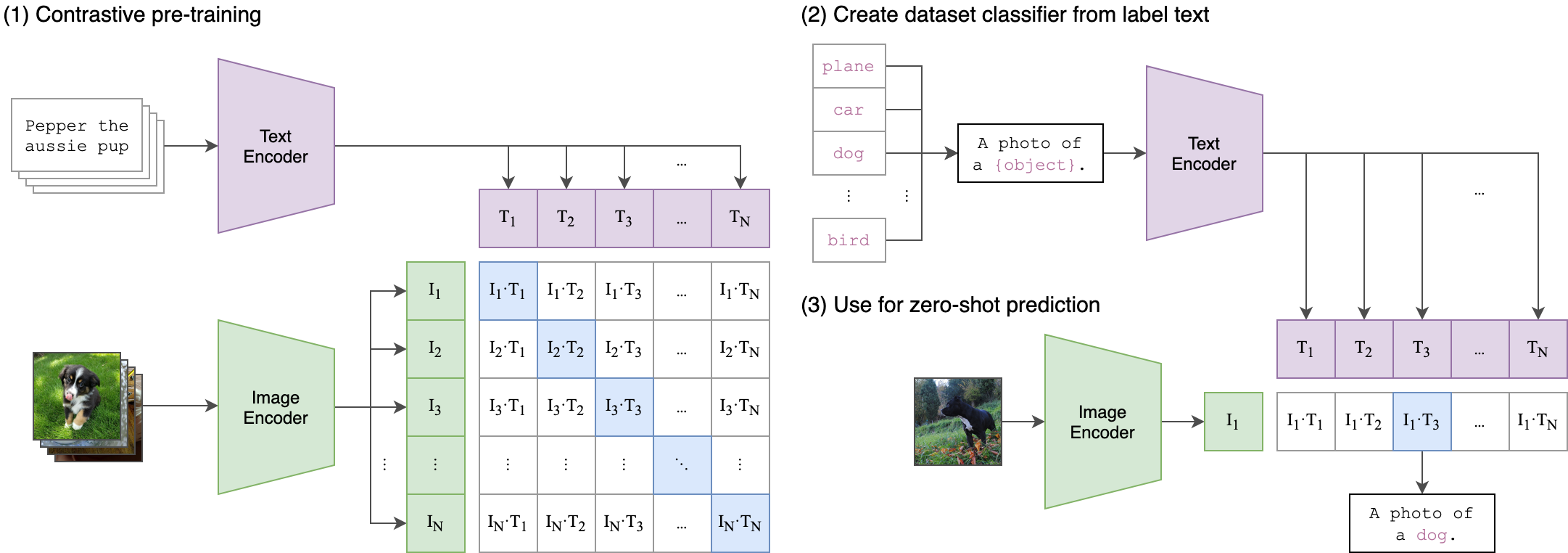
Successfully installed clip-1.0clip的主要思路流程:
6、修改Hugging Face 镜像源
代码会自动从Hugging Face下载模型权重,需要先配置为国内的镜像源
编辑用户配置文件 ~/.bashrc,设置为 export HF_ENDPOINT=https://hf-mirror.com
执行下面命令:
bash
echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
source ~/.bashrc # 立即生效验证环境变量,是否修改成功:
bash
echo $HF_ENDPOINT正常会输出:https://hf-mirror.com,说明设置成功啦~
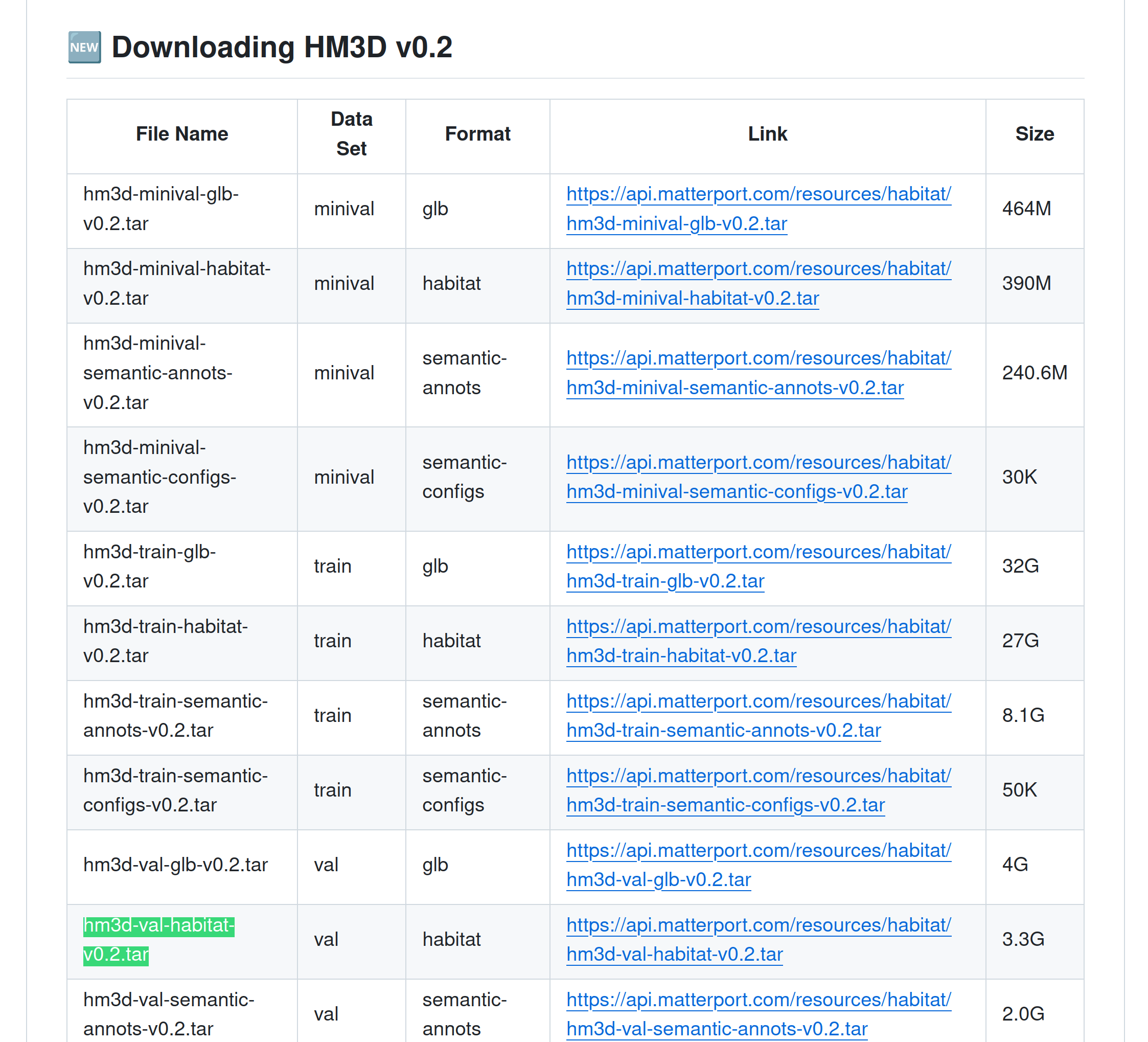
7、准备HM3D数据集
我们需要下载 hm3d_v0.2
下载地址:GitHub - matterport/habitat-matterport-3dresearch
选择的下载文件:hm3d-val-habitat-v0.2.tar
然后放到data目录下:
8、准备gpt-4o的Api
推荐使用国内的供应商,比较稳定:https://ai.nengyongai.cn/register?aff=RQt3
首先"添加令牌",设置额度(比如5块钱),点击查看就能看到Key啦

然后填写到 src/const.py中
python
# about habitat scene
INVALID_SCENE_ID = []
# about chatgpt api
END_POINT = "https://ai.nengyongai.cn/v1"
OPENAI_KEY = "xxxxxxxxxxxxxxxxxxxxx"点击模型列表,能查看支持的模型:
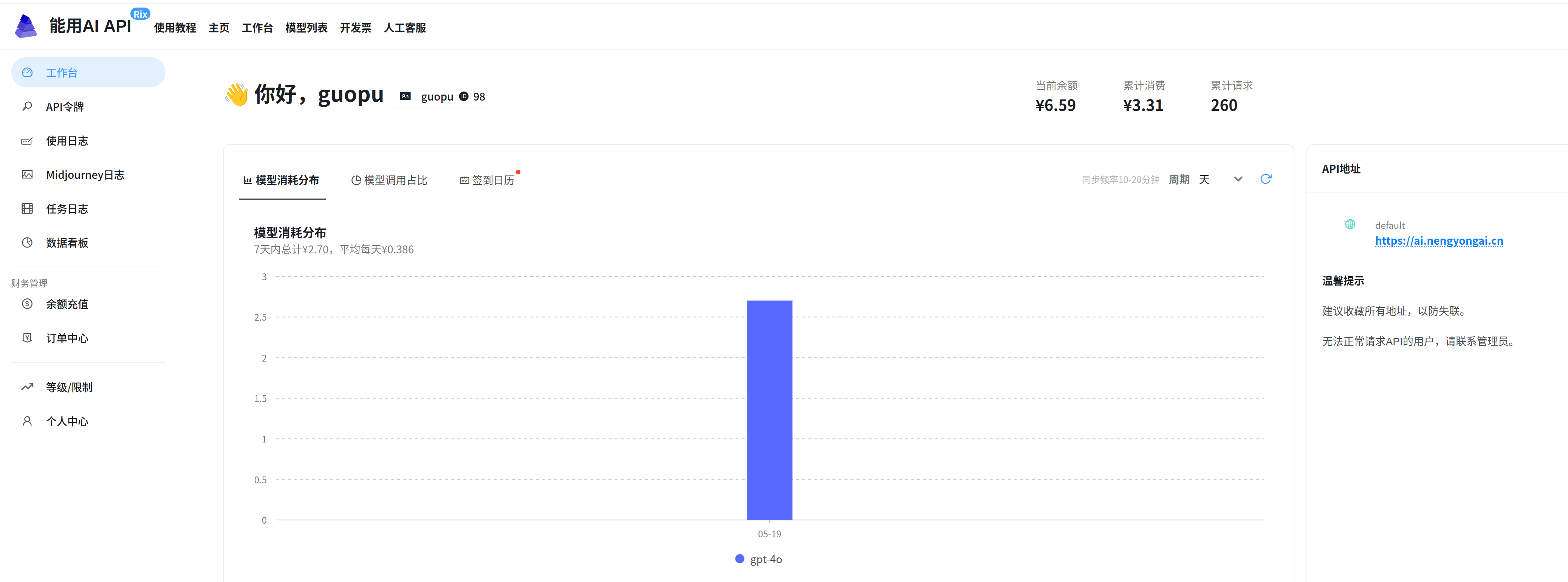
看一下使用情况:
9、运行模型推理
查看配置文件 cfg/eval_aeqa.yaml
bash
# 通用设置
seed: 77 # 随机种子
exp_name: "exp_eval_aeqa" # 实验名称
output_parent_dir: "results" # 输出文件夹的父目录
scene_dataset_config_path: "data/hm3d_annotated_basis.scene_dataset_config.json" # 场景数据集配置文件路径
scene_data_path: "data/hm3d_v0.2/" # 场景数据路径
questions_list_path: 'data/aeqa_questions-41.json' # 问题列表文件路径
concept_graph_config_path: "cfg/concept_graph_default.yaml" # 概念图配置文件路径
# 主要设置
choose_every_step: true # 是否在每一步都查询视觉语言模型(VLM),还是仅在到达导航目标后查询
egocentric_views: true # 是否在提示视觉语言模型时添加自我中心视角
prefiltering: true # 是否使用预筛选(实际上不能关闭,否则会超出上下文长度限制)
top_k_categories: 10 # 在预筛选过程中保留与目标最相关的前 k 个类别
# 关于检测模型
yolo_model_name: yolov8x-world.pt # YOLO 模型名称
sam_model_name: sam_l.pt # SAM 模型名称
class_set: scannet200 # 使用 200 类别的数据集用于 YOLO-world 检测器
# 关于快照聚类
min_detection: 1 # 最小检测数量
# 相机和图像设置
camera_height: 1.5 # 相机高度(单位:米)
camera_tilt_deg: -30 # 相机倾斜角度(单位:度)
img_width: 1280 # 图像宽度(单位:像素)
img_height: 1280 # 图像高度(单位:像素)
hfov: 120 # 水平视场角(单位:度)
# 是否保存可视化结果(这会比较慢)
save_visualization: true
# 用于提示 GPT-4O 的图像大小
prompt_h: 360 # 提示图像高度(单位:像素)
prompt_w: 360 # 提示图像宽度(单位:像素)
# 导航设置
num_step: 50 # 最大导航步数
init_clearance: 0.3 # 初始避碰距离(单位:米)
extra_view_phase_1: 2 # 第一阶段额外视角的数量
extra_view_angle_deg_phase_1: 60 # 第一阶段每个额外视角之间的角度(单位:度)
extra_view_phase_2: 6 # 第二阶段额外视角的数量
extra_view_angle_deg_phase_2: 40 # 第二阶段每个额外视角之间的角度(单位:度)
# 关于 TSDF、深度图和边界更新
explored_depth: 1.7 # 已探索深度(单位:米)
tsdf_grid_size: 0.1 # TSDF 网格大小(单位:米)
margin_w_ratio: 0.25 # 宽度方向的边界比例
margin_h_ratio: 0.6 # 高度方向的边界比例
planner: # 规划器设置
eps: 1 # 规划器的精度
max_dist_from_cur_phase_1: 1 # 第一阶段未找到目标时,探索边界的步长(单位:米)
max_dist_from_cur_phase_2: 1 # 第二阶段找到目标后,接近目标的步长(单位:米)
final_observe_distance: 0.75 # 第二阶段找到一个距离目标对象此距离的地方进行观察(单位:米)
surrounding_explored_radius: 0.7 # 周围已探索区域的半径(单位:米)
# 关于边界选择
frontier_edge_area_min: 4 # 边界边缘最小面积
frontier_edge_area_max: 6 # 边界边缘最大面积
frontier_area_min: 8 # 边界最小面积
frontier_area_max: 9 # 边界最大面积
min_frontier_area: 20 # 边界至少需要的像素数量
max_frontier_angle_range_deg: 150 # 边界中像素所张角度的最大值(单位:度)
region_equal_threshold: 0.95 # 区域相等的阈值
# 关于场景图构建
scene_graph:
confidence: 0.003 # 置信度阈值
nms_threshold: 0.1 # 非极大值抑制阈值
iou_threshold: 0.5 # 交并比阈值
obj_include_dist: 3.5 # 包含目标对象的距离(单位:米)
target_obj_iou_threshold: 0.6 # 目标对象的交并比阈值运行下面代码,生成 A-EQA 数据集的预测结果:
bash
python run_aeqa_evaluation.py -cf cfg/eval_aeqa.yaml运行程序后,会联网下载一些模型权重,
包括:yolov8x-world.pt、sam_l.pt、open_clip_pytorch_model.bin、ViT-B-32.pt等
下面是运行信息:
bash
00:00:00 - ***** Running exp_eval_aeqa *****
00:00:00 - Total number of questions: 41
00:00:00 - number of questions after splitting: 41
00:00:00 - question path: data/aeqa_questions-41.json
Downloading https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-world.pt to 'yolov8x-world.pt'...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 141M/141M [04:04<00:00, 605kB/s]
00:04:09 - Load YOLO model yolov8x-world.pt successful!
Downloading https://github.com/ultralytics/assets/releases/download/v8.2.0/sam_l.pt to 'sam_l.pt'...
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.16G/1.16G [11:56<00:00, 1.74MB/s]
00:16:12 - Load SAM model sam_l.pt successful!
00:16:12 - Loaded ViT-B-32 model config.
open_clip_pytorch_model.bin: 70%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 440M/626M [03:17<01:11, 2.58MB/s]
....当下载和加载成功后,会显示:
bash
00:00:00 - ***** Running exp_eval_aeqa *****
00:00:00 - Total number of questions: 41
00:00:00 - number of questions after splitting: 41
00:00:00 - question path: data/aeqa_questions-41.json
00:00:00 - Load YOLO model yolov8x-world.pt successful!
00:00:02 - Load SAM model sam_l.pt successful!
00:00:02 - Loaded ViT-B-32 model config.
00:00:04 - Loading pretrained ViT-B-32 weights (laion2b_s34b_b79k).
00:00:05 - Load CLIP model successful!
00:00:05 - Question 00c2be2a-1377-4fae-a889-30936b7890c3 already processed
00:00:05 - Question 013bb857-f47d-4b50-add4-023cc4ff414c already processed
00:00:05 -
========
Index: 2 Scene: 00848-ziup5kvtCCR
00:00:05 - semantic_texture_path: data/hm3d_v0.2/val/00848-ziup5kvtCCR/ziup5kvtCCR.semantic.glb or scene_semantic_annotation_path: data/hm3d_v0.2/val/00848-ziup5kvtCCR/ziup5kvtCCR.semantic.txt does not exist
00:00:06 - Loaded 192 classes from scannet 200: data/scannet200_classes.txt!!!
00:00:06 - Load scene 00848-ziup5kvtCCR successfully without semantic texture
00:00:10 -
Question id 01fcc568-f51e-4e12-b976-5dc8d554135a initialization successful!
00:00:10 -
== step: 0
00:00:11 - Done! Execution time of detections_to_obj_pcd_and_bbox function: 0.12 seconds
00:00:13 - Done! Execution time of detections_to_obj_pcd_and_bbox function: 0.09 seconds
00:00:15 - Done! Execution time of detections_to_obj_pcd_and_bbox function: 0.08 seconds
00:00:16 - Done! Execution time of detections_to_obj_pcd_and_bbox function: 0.05 seconds
00:00:17 - Done! Execution time of detections_to_obj_pcd_and_bbox function: 0.04 seconds
00:00:18 - Done! Execution time of detections_to_obj_pcd_and_bbox function: 0.05 seconds
00:00:19 - Done! Execution time of detections_to_obj_pcd_and_bbox function: 0.07 seconds
00:00:20 - Step 0, update snapshots, 25 objects, 6 snapshots
00:00:23 - HTTP Request: POST https://ai.nengyongai.cn/v1/chat/completions "HTTP/1.1 200 OK"
00:00:23 - Prefiltering selected classes: ['sofa chair', 'couch', 'pillow', 'coffee table', 'cabinet']
00:00:23 - Prefiltering snapshot: 6 -> 3
00:00:23 - Input prompt:
00:00:23 - Task: You are an agent in an indoor scene tasked with answering questions by observing the surroundings and exploring the environment. To answer the question, you are required to choose either a Snapshot as the answer or a Frontier to further explore.
Definitions:
Snapshot: A focused observation of several objects. Choosing a Snapshot means that this snapshot image contains enough information for you to answer the question. If you choose a Snapshot, you need to directly give an answer to the question. If you don't have enough information to give an answer, then don't choose a Snapshot.
Frontier: An observation of an unexplored region that could potentially lead to new information for answering the question. Selecting a frontier means that you will further explore that direction. If you choose a Frontier, you need to explain why you would like to choose that direction to explore.
Question: Where is the teddy bear?
Select the Frontier/Snapshot that would help find the answer of the question.
The following is the egocentric view of the agent in forward direction: [iVBORw0KGg...]
The followings are all the snapshots that you can choose (followed with contained object classes)
Please note that the contained classes may not be accurate (wrong classes/missing classes) due to the limitation of the object detection model. So you still need to utilize the images to make decisions.
Snapshot 0 [iVBORw0KGg...]coffee table, couch, pillow
Snapshot 1 [iVBORw0KGg...]coffee table, pillow, sofa chair
Snapshot 2 [iVBORw0KGg...]cabinet, couch
The followings are all the Frontiers that you can explore:
Frontier 0 [iVBORw0KGg...]
Frontier 1 [iVBORw0KGg...]
Please provide your answer in the following format: 'Snapshot i
[Answer]' or 'Frontier i
[Reason]', where i is the index of the snapshot or frontier you choose. For example, if you choose the first snapshot, you can return 'Snapshot 0
The fruit bowl is on the kitchen counter.'. If you choose the second frontier, you can return 'Frontier 1
I see a door that may lead to the living room.'.
Note that if you choose a snapshot to answer the question, (1) you should give a direct answer that can be understood by others. Don't mention words like 'snapshot', 'on the left of the image', etc; (2) you can also utilize other snapshots, frontiers and egocentric views to gather more information, but you should always choose one most relevant snapshot to answer the question.
00:00:32 - HTTP Request: POST https://ai.nengyongai.cn/v1/chat/completions "HTTP/1.1 200 OK"
00:00:32 - Response: [frontier 0]
Reason: [I would like to explore the hallway further as it may lead to other rooms where the teddy bear might be located.]
00:00:32 - Prediction: frontier, 0
00:00:32 - Next choice: Frontier at [79 33]
UserWarning: *c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2D array with a single row if you intend to specify the same RGB or RGBA value for all points.
00:00:33 - Current position: [ 0.11692 0.021223 6.1057], 1.005
00:00:34 -
== step: 1可视化的结果保存在:results/exp_eval_aeqa 中

看一下占用地图,规划航向(1)

规划航向(2)

规划航向(3)

模型推理示例2
对应的配置文件是:cfg/eval_goatbench.yaml
运行代码,生成 GOAT-Bench 数据集的预测结果:
bash
python run_goatbench_evaluation.py -cf cfg/eval_goatbench.yamlGOAT-Bench 为每个场景提供了 10 个探索情节,并且由于时间和资源的限制,默认只测试第一情节。
我们还可以通过设置来指定要评估每个场景的情节 --split。
分享完成~
相关文章推荐:
UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客
【机器人】复现 UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客