一、基本框架
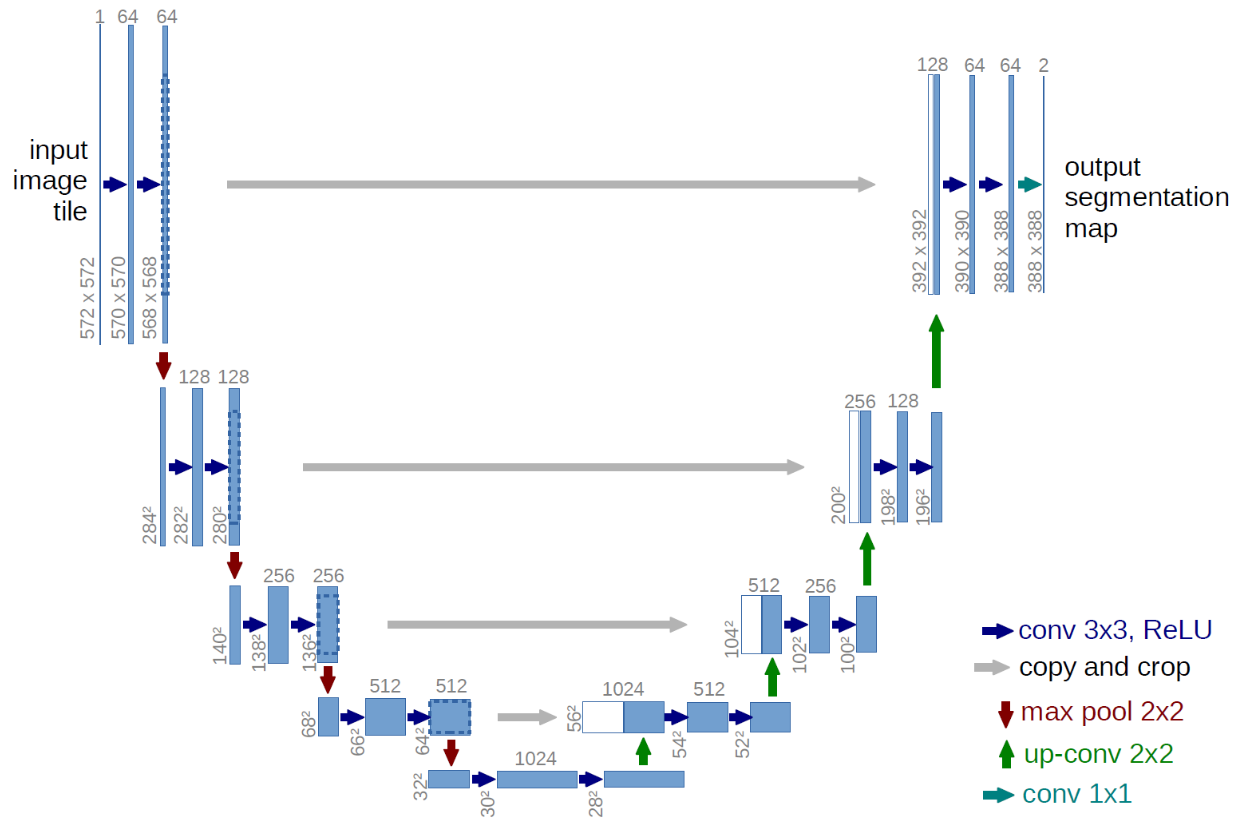
整体是一个U型的结构,左边是特征提取层,第一个是做了一个两层的卷积,蓝色箭头就是做了一个3*3的卷积,图中的图像大小会变小,但是本文代码会加入padding,避免图像大小的变化;两层卷积之后进行一个下采样,这里使用最大值池化,每次大小减小一倍;到了最下面,通过卷积变成1024的通道数;到右边进行上采样,注意,这里只取1024通道里面的一半,然后和上一层中的512进行拼接,图中灰色的箭头是裁剪,但是经过padding之后就不需要此步骤。然后一直到右上方,图中通道数是2,实际实践中可以是3,4,5,根据任务来具体判断需要几个。
二、代码部分
U-Net部分:
python
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
import sys
sys.path.append(r"C:\Users\25571\Desktop\u-net")
from module.ECA import ECA_layer
from module.EMA import EMA
from module.LSK import LSKNet
from module.ELA import ELA
from module.Biformer import BiLevelRoutingAttention as BRA
class DoubleConv(nn.Module): # 定义一个名为 DoubleConv 的类,继承自 nn.Sequential
def __init__(self, in_channels, out_channels, mid_channels=None):
super(DoubleConv, self).__init__() # 调用父类的构造函数
if mid_channels is None: # 如果未指定中间通道数,则默认为输出通道数
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False), # 第一个卷积层:输入通道数到中间通道数的卷积操作
nn.BatchNorm2d(mid_channels), # 对中间通道数进行批量归一化操作
nn.ReLU(inplace=True), # 使用 ReLU 激活函数进行非线性变换
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
# self.eca = ECA_layer(out_channels)
# self.ema = EMA(channels=out_channels)
# self.ela = ELA(out_channels,phi="T")
# self.bra = BRA(out_channels)
def forward(self, x):
x = self.double_conv(x)
# x = self.eca(x)
# x = self.ema(x)
# x = self.ela(x)
# x = self.bra(x)
return x
class Down(nn.Sequential): # 定义一个名为 Down 的类,继承自 nn.Sequential
def __init__(self, in_channels, out_channels):
# 调用父类的构造函数
super(Down, self).__init__(
# 最大池化层,用于下采样,将特征图尺寸缩小一半
nn.MaxPool2d(2, stride=2),
# 使用定义的 DoubleConv 类来构建一个特征提取块
DoubleConv(in_channels, out_channels)
)
class Up(nn.Module): # 定义一个名为 Up 的类,继承自 nn.Module
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
# 根据输入的参数决定使用双线性插值还是转置卷积
if bilinear:
# 使用双线性插值进行上采样
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# 使用定义的 DoubleConv 类构建一个特征提取块,其中中间通道数为输入通道数的一半
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
# 使用转置卷积进行上采样
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
# 使用定义的 DoubleConv 类构建一个特征提取块
self.conv = DoubleConv(in_channels, out_channels)
# self.ema = EMA(out_channels)
# 定义前向传播函数,实现特征图的上采样和连接
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# 计算两个特征图的尺寸差异
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
# 使用 F.pad 对 x1 进行填充,使其与 x2 的尺寸相同
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
# 将两个特征图按通道连接
x = torch.cat([x2, x1], dim=1)
# x = self.ema(x)
# 经过特征提取块进行特征提取和处理
x = self.conv(x)
return x
class OutConv(nn.Sequential): # 定义一个名为 OutConv 的类,继承自 nn.Sequential
def __init__(self, in_channels, num_classes):
# 调用父类的构造函数
super(OutConv, self).__init__(
# 1x1 卷积层,用于生成最终的输出特征图
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module): # 定义一个名为 UNet 的类,继承自 nn.Module
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
# 调用父类的构造函数
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
# 定义 U-Net 的各个组件
self.in_conv = DoubleConv(in_channels, base_c) # 输入通道数: in_channels -> base_c (64)
self.down1 = Down(base_c, base_c * 2) # base_c (64) -> base_c * 2 (128)
self.down2 = Down(base_c * 2, base_c * 4) # base_c * 2 (128) -> base_c * 4 (256)
self.down3 = Down(base_c * 4, base_c * 8) # base_c * 4 (256) -> base_c * 8 (512)
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor) # base_c * 8 (512) -> base_c * 16 // factor (512 or 1024)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear) # base_c * 16 (512 or 1024) -> base_c * 8 // factor (512 or 1024)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear) # base_c * 8 (512 or 1024) -> base_c * 4 // factor (256 or 512)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear) # base_c * 4 (256 or 512) -> base_c * 2 // factor (128 or 256)
self.up4 = Up(base_c * 2, base_c, bilinear) # base_c * 2 (128 or 256) -> base_c (64)
self.out_conv = OutConv(base_c, num_classes) # base_c (64) -> num_classes (2)
# 定义前向传播函数
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
# U-Net 的前向传播过程
# 编码器路径
x1 = self.in_conv(x) # 输入尺寸: (N, in_channels, H, W),输出尺寸: (N, base_c, H, W)
x2 = self.down1(x1) # 输入尺寸: (N, base_c, H/2, W/2),输出尺寸: (N, base_c*2, H/2, W/2)
x3 = self.down2(x2) # 输入尺寸: (N, base_c*2, H/4, W/4),输出尺寸: (N, base_c*4, H/4, W/4)
x4 = self.down3(x3) # 输入尺寸: (N, base_c*4, H/8, W/8),输出尺寸: (N, base_c*8, H/8, W/8)
x5 = self.down4(x4) # 输入尺寸: (N, base_c*8, H/16, W/16),输出尺寸: (N, base_c*16//factor, H/16, W/16)
# 解码器路径
x = self.up1(x5, x4) # 输入尺寸: (N, base_c*16//factor, H/8, W/8),输出尺寸: (N, base_c*8//factor, H/8, W/8)
x = self.up2(x, x3) # 输入尺寸: (N, base_c*8//factor, H/4, W/4),输出尺寸: (N, base_c*4//factor, H/4, W/4)
x = self.up3(x, x2) # 输入尺寸: (N, base_c*4//factor, H/2, W/2),输出尺寸: (N, base_c*2//factor, H/2, W/2)
x = self.up4(x, x1) # 输入尺寸: (N, base_c*2//factor, H, W),输出尺寸: (N, base_c, H, W)
# 输出通道数变换
logits = self.out_conv(x) # 输入尺寸: (N, base_c, H, W),输出尺寸: (N, num_classes, H, W)
# 返回输出的字典,包含了最终的预测结果
return {"out": logits}
if __name__ == "__main__":
model = UNet(in_channels=3, num_classes=2)
input_tensor = torch.randn(1, 3, 256, 256) # 输入大小
output = model(input_tensor)
print(output["out"].shape)训练部分:
python
import os
import time
import datetime
import torch
# import sys
# sys.path.append(r"D:\Codes\Deep learning\unet\save_weights")
from src import UNet,ResNetUNet
from train_utils import train_one_epoch, evaluate, create_lr_scheduler
from my_dataset import DriveDataset
# from my_dataset import CustomDataset
import transforms as T
class SegmentationPresetTrain:
def __init__(self, base_size, crop_size, hflip_prob=0.5, vflip_prob=0.5,
mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
# 根据输入的基础尺寸计算随机调整图像大小的最小和最大尺寸
min_size = int(0.5 * base_size) # 最小尺寸为基础尺寸的50%
max_size = int(1.2 * base_size) # 最大尺寸为基础尺寸的120%
# 构建数据增强的变换序列,首先是随机调整图像大小
trans = [T.RandomResize(min_size, max_size)]
# 如果水平翻转概率大于0,则添加随机水平翻转的操作
if hflip_prob > 0:
trans.append(T.RandomHorizontalFlip(hflip_prob))
# 如果垂直翻转概率大于0,则添加随机垂直翻转的操作
if vflip_prob > 0:
trans.append(T.RandomVerticalFlip(vflip_prob))
# 在变换序列中添加随机裁剪、张量转换和归一化的操作
trans.extend([
T.RandomCrop(crop_size), # 随机裁剪图像到指定大小
T.ToTensor(), # 将图像从PIL格式转换为张量格式
T.Normalize(mean=mean, std=std), # 对图像进行归一化处理
])
# 将所有的数据增强操作组合成一个变换序列
self.transforms = T.Compose(trans)
def __call__(self, img, target):
# 调用时对输入的图像和目标(如标签)应用变换
return self.transforms(img, target)
class SegmentationPresetEval:
def __init__(self, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
# 定义评估(验证/测试)模式下的变换序列
self.transforms = T.Compose([
T.ToTensor(), # 将图像从PIL格式转换为张量格式
T.Normalize(mean=mean, std=std), # 对图像进行归一化处理
])
def __call__(self, img, target):
# 调用时对输入的图像和目标(如标签)应用变换
return self.transforms(img, target)
def get_transform(train, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
base_size = 565 # 定义基础图像尺寸
crop_size = 480 # 定义裁剪后的图像尺寸
if train:
# 如果是训练模式,返回训练模式下的数据增强配置
return SegmentationPresetTrain(base_size, crop_size, mean=mean, std=std)
else:
# 如果是评估模式,返回评估模式下的变换配置
return SegmentationPresetEval(mean=mean, std=std)
class SegmentationPresetTrain:
def __init__(self, base_size, crop_size, hflip_prob=0.5, vflip_prob=0.5,
mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
# 根据输入的基础尺寸计算随机调整图像大小的最小和最大尺寸
min_size = int(0.5 * base_size) # 最小尺寸为基础尺寸的50%
max_size = int(1.2 * base_size) # 最大尺寸为基础尺寸的120%
# 构建数据增强的变换序列,首先是随机调整图像大小
trans = [T.RandomResize(min_size, max_size)]
# 如果水平翻转概率大于0,则添加随机水平翻转的操作
if hflip_prob > 0:
trans.append(T.RandomHorizontalFlip(hflip_prob))
# 如果垂直翻转概率大于0,则添加随机垂直翻转的操作
if vflip_prob > 0:
trans.append(T.RandomVerticalFlip(vflip_prob))
# 在变换序列中添加随机裁剪、张量转换和归一化的操作
trans.extend([
T.RandomCrop(crop_size), # 随机裁剪图像到指定大小
T.ToTensor(), # 将图像从PIL格式转换为张量格式
T.Normalize(mean=mean, std=std), # 对图像进行归一化处理
])
# 将所有的数据增强操作组合成一个变换序列
self.transforms = T.Compose(trans)
def __call__(self, img, target):
# 调用时对输入的图像和目标(如标签)应用变换
return self.transforms(img, target)
class SegmentationPresetEval:
def __init__(self, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
# 定义评估(验证/测试)模式下的变换序列
self.transforms = T.Compose([
T.ToTensor(), # 将图像从PIL格式转换为张量格式
T.Normalize(mean=mean, std=std), # 对图像进行归一化处理
])
def __call__(self, img, target):
# 调用时对输入的图像和目标(如标签)应用变换
return self.transforms(img, target)
def get_transform(train, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
base_size = 565 # 定义基础图像尺寸
crop_size = 480 # 定义裁剪后的图像尺寸
if train:
# 如果是训练模式,返回训练模式下的数据增强配置
return SegmentationPresetTrain(base_size, crop_size, mean=mean, std=std)
else:
# 如果是评估模式,返回评估模式下的变换配置
return SegmentationPresetEval(mean=mean, std=std)
def create_model(num_classes):
# 创建一个 UNet 模型实例,设置输入通道为 3(RGB图像),输出类别数为 num_classes,基础通道数为 32
model = UNet(in_channels=3, num_classes=num_classes)
# model = ResNetUNet(num_classes=num_classes)
return model
def main(args):
# 获取设备
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
# 批次大小
batch_size = args.batch_size
# 分割类别数(包括背景)
num_classes = args.num_classes + 1
# 图像均值和标准差
mean = (0.709, 0.381, 0.224)
std = (0.127, 0.079, 0.043)
# 用于保存训练和验证信息的文件
results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
# 创建训练和测试数据集
train_dataset = DriveDataset(args.data_path,
train=True,
transforms=get_transform(train=True, mean=mean, std=std))
val_dataset = DriveDataset(args.data_path,
train=False,
transforms=get_transform(train=False, mean=mean, std=std))
num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # 计算可用的 worker 数量,限制在最小的工作进程数和一些条件下的最小值
train_loader = torch.utils.data.DataLoader(train_dataset, # 创建训练数据加载器
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
pin_memory=True,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset, # 创建验证数据加载器
batch_size=1,
num_workers=num_workers,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
model = create_model(num_classes=num_classes) # 创建模型实例
model.to(device)
params_to_optimize = [p for p in model.parameters() if p.requires_grad] # 获取需要优化的参数
# 创建优化器
optimizer = torch.optim.SGD(
params_to_optimize,
lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay
)
# 创建混合精度训练的梯度缩放器(如果开启了混合精度训练)
scaler = torch.cuda.amp.GradScaler() if args.amp else None
# 创建学习率更新策略,这里是每个step更新一次(不是每个epoch)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True)
# 如果设置了恢复训练
if args.resume:
# 加载之前保存的模型状态
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
# 如果开启了混合精度训练,还需恢复梯度缩放器状态
if args.amp:
scaler.load_state_dict(checkpoint["scaler"])
# 初始化最佳 Dice 分数和开始时间
best_dice = 0.
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
# 训练一个 epoch
mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch, num_classes,
lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)
# 在验证集上评估模型性能
confmat, dice = evaluate(model, val_loader, device=device, num_classes=num_classes)
val_info = str(confmat)
print(val_info)
print(f"dice coefficient: {dice:.3f}")
# 将结果写入到文件中
with open(results_file, "a") as f:
# 记录每个epoch对应的train_loss、lr以及验证集各指标
train_info = f"[epoch: {epoch}]\n" \
f"train_loss: {mean_loss:.4f}\n" \
f"lr: {lr:.6f}\n" \
f"dice coefficient: {dice:.3f}\n"
f.write(train_info + val_info + "\n\n")
# 如果开启了保存最佳模型
if args.save_best is True:
# 如果当前 Dice 值优于历史最佳,则更新最佳 Dice 值
if best_dice < dice:
best_dice = dice
else:
continue
# 准备要保存的模型状态
save_file = {"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
"epoch": epoch,
"args": args}
# 如果开启了混合精度训练,还需保存梯度缩放器的状态
if args.amp:
save_file["scaler"] = scaler.state_dict()
# 根据条件选择保存最佳模型或每个 epoch 的模型
if args.save_best is True:
torch.save(save_file, "save_weights/CH_best_model.pth")
else:
torch.save(save_file, "save_weights/model_{}.pth".format(epoch))
# 计算总训练时间并打印
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print("training time {}".format(total_time_str))
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="pytorch unet training")
parser.add_argument("--data-path", default="./", help="DRIVE root")
parser.add_argument("--num-classes", default=1, type=int)
parser.add_argument("--device", default="cuda", help="training device")
parser.add_argument("-b", "--batch-size", default=2, type=int)
parser.add_argument("--epochs", default=200, type=int, metavar="N",
help="number of total epochs to train")
parser.add_argument('--lr', default=0.01, type=float, help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument('--print-freq', default=1, type=int, help='print frequency')
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
parser.add_argument('--save-best', default=True, type=bool, help='only save best dice weights')
# 混合精度训练参数
parser.add_argument("--amp", default=False, type=bool,
help="Use torch.cuda.amp for mixed precision training")
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
# 如果保存模型的文件夹不存在,则创建它
if not os.path.exists("./save_weights"):
os.mkdir("./save_weights")
# 执行主程序入口函数
main(args)