基于 FPGA 的卷积神经网络加速器研究
随着深度学习的快速发展,卷积神经网络(Convolutional Neural Network,CNN)
在图像分类、目标检测等任务中取得了显著成果。然而,传统硬件实现 CNN 时面临
计算能力不足、能耗高和延迟大等问题。现场可编程门阵列(Field-Programmable
Gate Array,FPGA)具有高度的可编程性和并行处理能力,能够针对特定应用优化
硬件架构,可显著提升 CNN 的推理速度和能效。现有 FPGA 加速器存在资源利用率
低、设计复杂性高、数据传输延迟瓶颈等问题,限制了 CNN 的进一步实际应用。因
此,本文从 CNN 架构、IP 设计等方面展开研究,目的是设计高效率、低功耗的实用
化 FPGA 卷积神经网络加速器。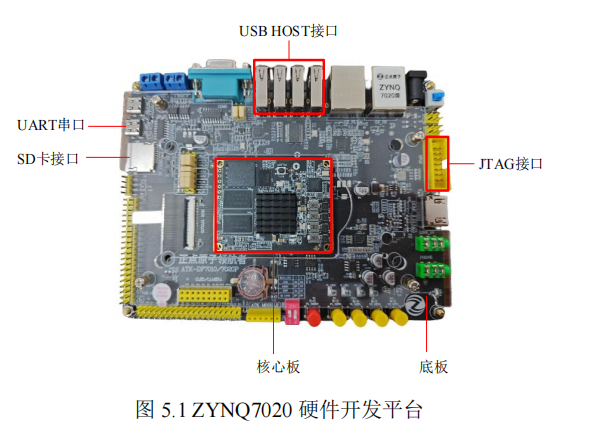
FPGA****卷积神经网络加速器架构设计
本章将重点研究基于 FPGA 的卷积神经网络加速器架构的设计。首先,对将要
在硬件上部署的卷积神经网络的硬件实现进行分析,包括网络计算量和参数量的分
析以及访存和计算并行性分析;其次,为了更好地在硬件上部署卷积神经网络,采
用双缓冲机制来提高设计吞吐量,将卷积层同 BN 层进行融合,并对网络参数做了
定点量化处理;最后,设计基于 Overlap 架构的卷积加速器。
3.1****硬件实现分析
3.1.1****网络计算量和参数量分析
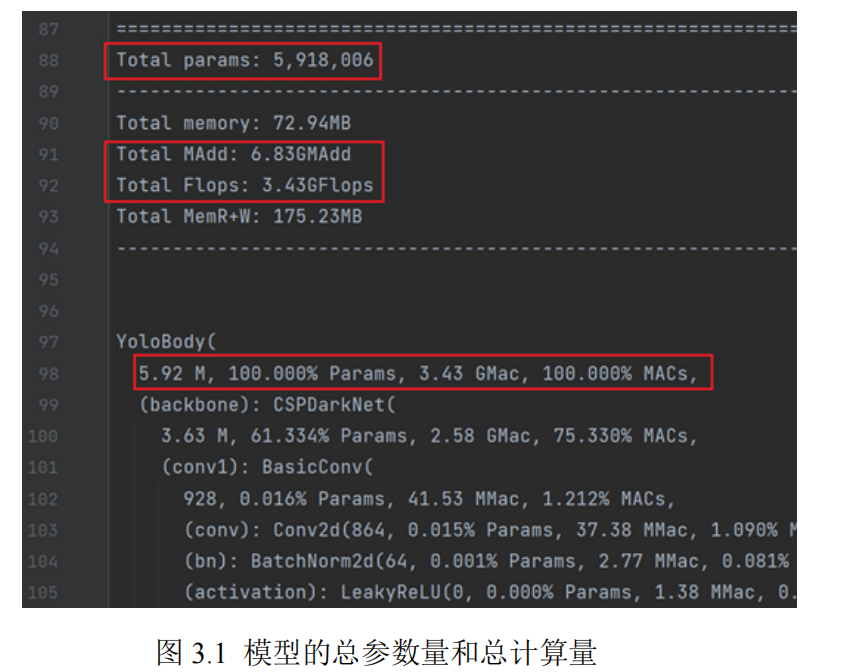
在硬件实现之前,需要对 CNN 的计算量和参数量进行分析,以便确定具体的硬
件加速器架构和目标板卡。在进行网络硬件实现分析时,需要关注该模型的总参数
量和总计算量,本文使用 Python 的 torchstat 和 ptflops 这两个工具统计该模型的总计
算量和总参数量,如图 3.1 所示为 CNN 的总参数量和总计算量,其中总参数量为
5.92M,总计算量为 3.43GFlops。
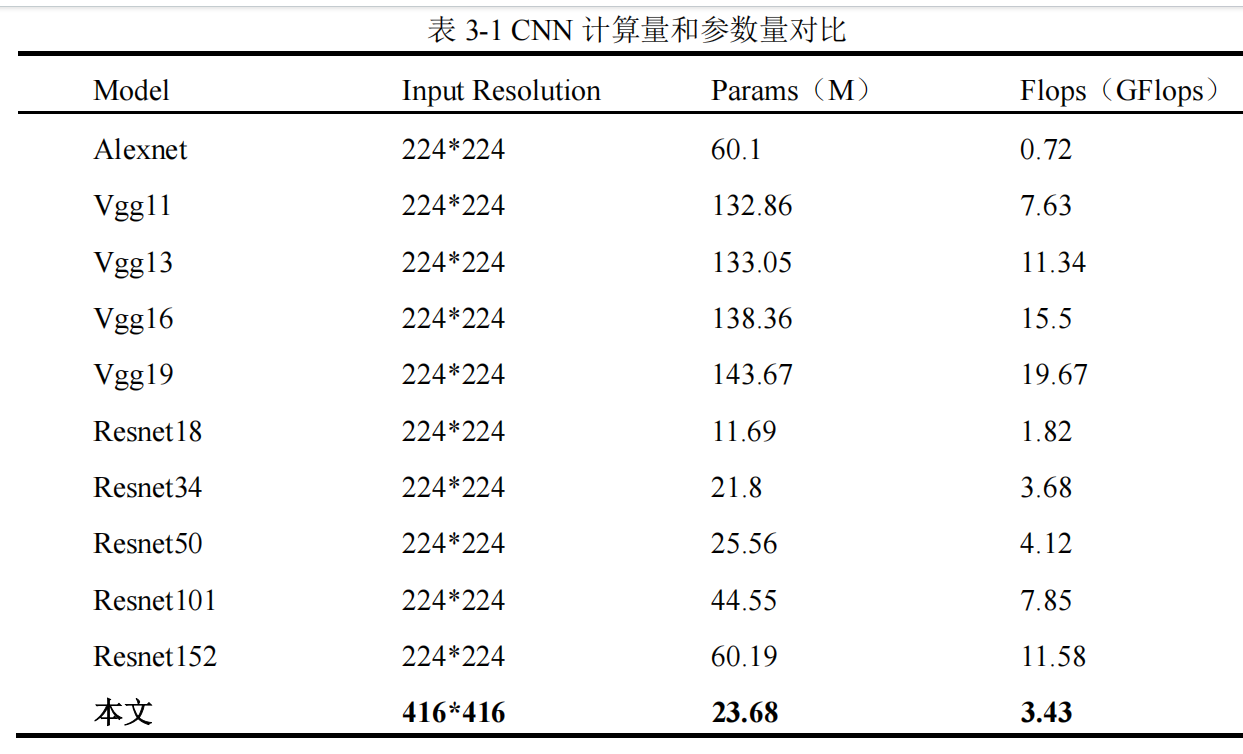
如表 3-1 所示为本文选用的轻量化 CNN 与其他 CNN 的总计算量和总参数量对
比,本文所选用的 CNN 的总参数量和总计算量相较于其他的 CNN 都比较小,更有
益于在嵌入式设备上进行部署。
进行硬件实现时,为更好适应有限的资源环境和提高 CNN 的运行效率,需要考
虑以下两个问题:
(1)参数保存在片上存储还是片外存储
虽然保存在片上存储的读取速度更快,计算更高效,但是片上存储的容量有限,
当网络参数大小大于片上存储的存储极限时,只能把参数存储到片外存储器中,本
文选用 DDR 作为片外存储器,由此可存储的参数大小理论是可以达到 GB 级别。
(2)如何提高加速器的吞吐量,使推理速度更快
若在 FPGA 上对训练好的模型达到更高的推理速度,那么就需要提高设计的吞
吐量,一般是针对计算量大的算子进行特定优化,比如提高并行度、加流水线等操
作。
由第2.2节中的CNN网络结构可知,本文所使用的卷积模型的算子一共有8种,
包括具有 3 种配置的 Conv2D、LeakyReLU、Concat、Maxpool2d、Upsample 和 BN。
其中,BN 层将与卷积层进行融合,在硬件实现时不需要单独设计算子 IP;另外,存
在训练参数的算子只有 Conv2D 和 BN,其余算子都是固定的计算,不存在需要进行
训练的参数。
由于 LeakyReLU,Maxpool2d,Upsample 都是只有计算量,而没有参数量的层。
Concat 是调用的 torch 的 API,相当于一个已被定义的函数,所以在统计信息里没有
Concat。在常用的网络层中,全连接层具有大量需要训练的参数,所以 CNN 加速器
的重点是对卷积层和全连接层进行加速。
3.1.2****访存并行性分析
由于 FPGA 的片上存储资源相对有限,而卷积神经网络的权重和中间计算结果
的特征图通常占用较大的存储空间,将整幅特征图缓存在片上存储 BRAM 中不切实
际。因此,采取循环分块策略将大循环中的数据划分为较小的块,以增强数据局部
性,从而提高缓存利用率和减少内存访问延迟。
3.3****加速器架构设计
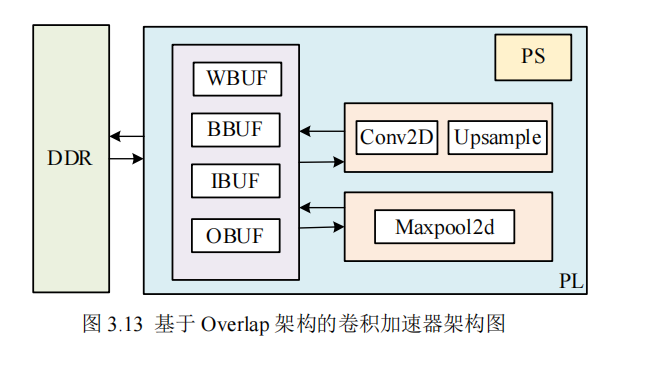
如图 3.13 所示为本文设计的一种基于 Overlap 架构的卷积加速器架构图。与传
统冯∙诺依曼架构相比,Overlap架构能够有效缓解数据搬运带来的瓶颈问题。传统架
构下,数据在存储器与处理器之间频繁传输,造成大量时间开销与功耗浪费。而
Overlap 架构强调数据的局部性原理,通过合理组织数据存储与计算流程,提高数据
复用率,减少不必要的数据传输。在卷积运算中,相邻卷积核运算时会重复使用部
分输入数据,Overlap 架构可将这部分数据暂存于片上缓存,避免重复从外部存储器
读取,从而显著提升计算效率。
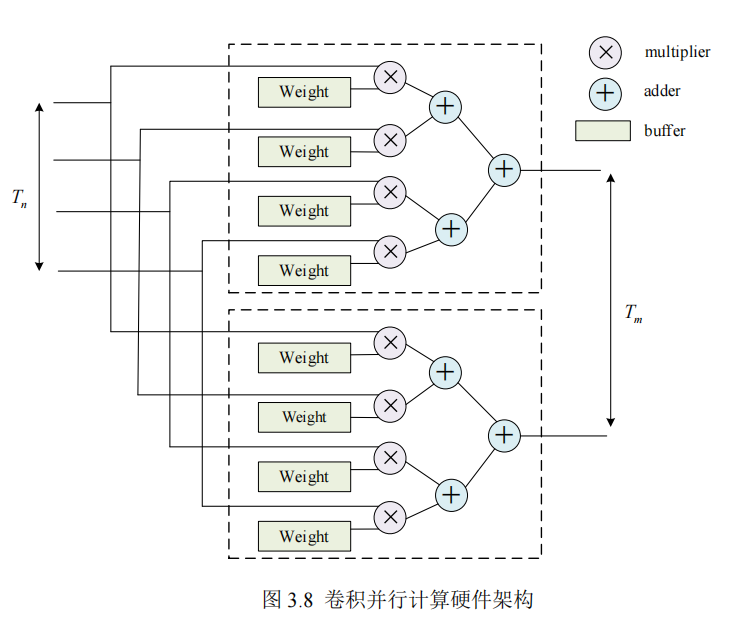
卷积计算在 CNN 计算量中占据主导地位,其计算性能的提升依赖于对多个参数。
卷积核大小直接影响感受野与计算复杂度,
的卷积核在处理高分辨率图像时,
既能有效提取局部特征,又能减少计算量;步长的设置则决定了特征图的下采样速
率,合理调整步长可在保证特征提取质量的同时,降低计算开销;通道数的确定需
综合考虑模型的表达能力与计算资源,过多通道数虽能提升特征表达能力,但会大
幅增加计算量。通过实验与理论分析相结合的方法,精确选取这些参数,可显著提
高卷积计算单元的性能。
外部存储器 DDR 与片上存储器(WBUF、BBUF、IBUF、OBUF)存在显著的
性能差异。DDR 虽具有大容量存储优势,但访问延迟较高。为缓解这一问题,跟据
数据访问模式设计合理的缓存机制。权重参数在模型训练与推理过程中为只读,且
复用率极高,因此将其存储于权重缓冲区 WBUF,可有效减少对 DDR 的重复访问;
输入数据按批次参与计算,输入缓冲区 IBUF 根据计算需求预取并缓存当前批次数
据,提高数据复用率;偏置参数与计算结果分别存储于 BBUF 和 OBUF,确保数据
的高效存储与读取。通过实验测试不同缓存容量配置下的数据访问时间,验证了缓
存机制对降低 DDR 访问延迟的有效性。
片上存储与计算单元之间采用双缓冲机制,通过设置两组缓冲区,一组用于数
据加载与计算,另一组用于数据更新与准备,实现数据加载与计算的并行处理,从
而隐藏数据传输延迟。本架构采用模块化设计理念,将不同计算单元如 Conv2D、
Maxpool2d 和 Upsample 设计成可复用的独立模块,便于在模型规模扩大时,通过增
加相同模块或替换为性能更优的模块,提升架构的计算能力。
如图 3.13 所示,外部存储器 DDR 用于存储大规模的模型权重、输入数据及中间
计算结果,由于 DDR 的访问延迟较高,直接从 DDR 读取数据会影响系统性能,因
此设计了片上缓存机制。片上存储器 WBUF、BBUF、IBUF、OBUF 用于缓解 DDR
访问延迟,实现高效的数据管理。WBUF 为权重缓冲区,用于存储卷积层的权重参
数,以减少重复访问 DDR 的开销;BBUF 为偏置缓冲区,用于存储神经网络中的偏
置参数;IBUF 为输入缓冲区,用于存储当前计算所需的输入数据,提高数据复用率;
OBUF 输出缓冲区,存储计算后的中间或最终结果,供后续计算或数据回写到 DDR
使用。主要的计算单元有 Conv2D、Maxpool2d 和 Upsample,Conv2D 用于实现 CNN
中的卷积计算,负责特征提取;Maxpool2d 用于特征降采样,以减少计算量和存储
需求,同时增强特征的平移不变性;Upsample 用于恢复特征图尺寸。片上存储与计
算单元之间的数据交互采用双缓冲技术,数据从 DDR 加载至输入缓冲区 IBUF,计
算完成后将结果存入输出缓冲区 OBUF,最终回写至 DDR。PS 端负责任务调度、参
数配置及数据管理,实现核心计算单元,并通过高速总线与 PS 进行数据交互,实现
高效计算加速50。
基于ZYNQ FPGA+AI+ARM 的卷积神经网络加速器设计
ARM+FPGA+AI工业主板定制专家2025-10-09 18:34
相关推荐
GIR1237 小时前
官方出品 | 多通道土壤呼吸测量系统市场现状与十五五规划深度报告:行业分析+趋势预测全收录绿算技术7 小时前
绿算技术亮相第十八届HPC AI中国年会,擘画AI基础设施全栈协同新图景Litluecat7 小时前
2026年7月22日科技热点新闻To_OC8 小时前
别再傻傻分不清:Workflow 和 Agent 到底不是一回事触底反弹8 小时前
🔥 2026 大模型选择指南:别再只看 Benchmark 了,这些维度才是关键!神奇霸王龙8 小时前
GB/T 46886 闭环屠夫:5 旗舰多模态 LLM 工业质检实测南讯股份Nascent8 小时前
洽洽全域会员项目启动会圆满召开大郭鹏宇9 小时前
基于 LangGraph 构建智能分诊系统(一):项目概述与环境搭建小林ixn9 小时前
大模型的“高考成绩单”:读懂Benchmark,选对真·生产力模型冬奇Lab9 小时前
AI 评测系列(04):RAG 评测——RAGAS 四指标实战与一个反直觉发现