内容提要
- 函数
- 函数的调用
- 函数的声明
- 函数的嵌套关系
- 函数的递归调用
- 数组做函数参数
函数
函数的调用
调用方式
①函数语句:
c
test (); //对于无返回值的函数,直接调用
int res = max(2,4); //对于有返回值的函数,一般需要在主调函数中接受被调函数的返回值②函数表达式:
c
4 + max(2,4);
scanf("%d", &num) != 1
(c = getchar()) != '\0'③函数参数:
c
printf("%d",(int)fabs(num)); //函数作为实参注意:函数可以作为函数的实参,如果要作为形参,必须使用函数指针。
在一个函数中调用另一个函数具备以下条件:
- 被调用的函数必须是已定义的函数。
- 若是用库函数,应在本文件开头用
#include包含其对应的头文件。 - 若使用自定义函数,自定义函数又在主调函数的后面,则应在主调函数中对被调函数进行声明。声明的作用是把函数名、函数参数的个数和类型等信息通知编译系统,以便于在遇到函数时,编译系统能正确识别函数,并检查函数调用的合法性。
函数的声明
函数调用时,往往要遵循先定义后使用,但如果我们对函数的调用操作出现在函数定义之前,则需要对函数进行声明。
定义
完整的函数使用分三部分:
-
**函数声明**
cint max(int x, int y, double z); //函数声明只保留函数头 int max(int, int, double); //s省略参数名称函数声明如果是在同一个文件,一定要定义在文件中所有的函数定义的最前面。如果有对应的
.h文件,可以将函数的声明抽取的.h中。 -
函数定义
cint max(int x, int y, double z) //函数定义时不能省略参数的名称 { return x > y ? x : y > z ? y : (int)z; }函数定义的时候,不能省略参数的数据类型,参数个数,参数名称,位置要和函数声明完全一 致。
-
函数调用
cint main() { printf("%d\n",max(4,5,6)); }
作用
C语言的函数声明是为了提前告诉编译器函数的名称、返回类型和参数,这样在函数实际定义之前就能安全调用它,避免编译错误,同时检査参数和返回值是否正确。相当于给编译器一个"预告",确保代码正确编译和运行。
使用
错误实例:被调函数写在主调函数之后
c
//主调函数
int main()
{
printf("%d\n", add(12, 13)); //此时编译会报错,因为函数没有经过声明,编译系统无法检查函数调用的合法性
}
//被调函数
int add(int x, int y)
{
return x + y;
}正确演示:被调函数写在了主调函数之前
c
//被调函数
int add(int x, int y)
{
return x + y;
}
//主调函数
int main()
{
printf("%d\n", add(12, 13));
}注意:如果函数的调用比较简单,如果a函数调用b函数,b函数定义在a函数之前,此时是可以省略函数声明的。
正确演示:被调函数和主调函数无法区分前后,需要增加被调函数的函数声明
c
//函数声明
int add(int, int);
//主调函数
int main()
{
printf("%d\n", add(12, 13));
}
//被调函数
int add(int x, int y)
{
return x + y;
}注意:如果设计函数的复杂调用,如果a函数调用b函数,b函数调用a函数,无法区分前后,此时需添加函数声明。
声明的方式:
- 函数头加上分号
cint add(int a, int b);
- 函数头加上分号,可省略形参名称,但不能省略参数类型
cint add(int, int);
函数的嵌套调用
函数不允许嵌套定义,但允许嵌套调用
-
正确示例:函数嵌套调用
cvoid a() {..} void b() { a(); } int main() { printf(..) } -
错误示例:函数嵌套定义
cvoid a() { void b() { ... } }
**嵌套调用:**在被调用函数内又主动去调用其他函数,这样的函数调用形式,称之为嵌套调用。
案例
案例1
-
需求:编写一个函数,判断给定的3~100的正整数是否是素数,若是返回1,否则返回0
-
分析:
- 素数:素数是大于1的自然数,除了1和它本身外,不能被其他整除。
-
代码:
c/** * 定义一个函数,求素数 * @param n:需要校验素数的整数 *@return 返回flag 1-素数,0-非素数 */ int is_prime(int n) { //默认是素数 int flag = 1; //循环变量 int i; // 生成2 ~ n/2 for (i = 2; i <= n / 2; i++) { // 判断是否出现整除的情况 if (n % i == 0) { flag = 0; //非素数 break; } } return flag; } int main() { for (int i = 3; i <= 100; i++) { if(is_prime(i)) printf("%-4d",i); } printf("\n"); return 0; }
案例2
-
需求:输入四个整数,找到其中最大的数,用函数嵌套来实现,要求每次只能两个数比较。
-
代码:
c//函数声明 int max_2(int, int); int max_4(int, int, int, int); /** * 2个整数求最大值 */ int max_2(int a, int b) { return a > b ? a : b; } /** * 4个整数求最大值 */ int max_4(int a, int b, int c, int d) { // 写法1 // int max; // max = max_2(a,b); // max = max_2(max,c); // max = max_2(max,d); // 写法2 return max_2(a,b) > max_2(c,d) ? max_2(a,b) : max_2(c,d); } int main(int argc,char *argv[]) { int a,b,c,d; printf("从控制台录入4个整数:\n"); scanf("%d%d%d%d",&a,&b,&c,&d); // 接收最大值 int max = max_4(a,b,c,d); printf("%d,%d,%d,%d中的最大值是%d\n",a,b,c,d,max) return 0; }
函数的递归调用
定义
**递归调用的含义:**在一个函数中,直接或间接调用了函数本身,就称之为函数的递归调用
c
//直接调用 推荐
a() → a();
//间接调用
a() → b() → a();
a() → b() →.. → a();递归调用的本质
递归调用是一种循环结构,它不同于我们之前学的while、for、do.while这样的循环结构,这些循环结构是借助于循环变量;而递归调用时利用函数自身实现虚幻结构,如果不加以控制,很容易产生死循环。
注意事项
①递归调用必须要有出口,一定要想办法终止递归(否则产生死循环)
②对终止条件的判断一定要放在函数递归之前。(先判断,再执行)
③进行函数的递归调用。
④函数递归的同时一定要将函数调用像出口逼近。
案例
案例1
-
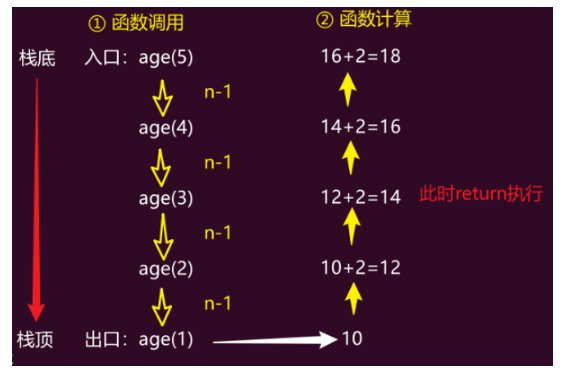
需求:
递归案例-
有5个人坐在一起,
问第5个人多少岁?他说比第4个人大2岁。
问第4个人岁数,他说比第3个人大2岁。
问第3个人,又说比第2个人大2岁。
问第2个人,说比第1个人大2岁。
最后问第1个人,他说是10岁。
请问第5个人多大。
-
分析:

-
代码:
c/** * 定义一个函数,求年龄 * @param n:第n个人 * @return 第n个人的年龄 */ int get_age(int n) { //创建一个变量,存储函数返回值,返回的是地n个人的年龄 int age; //出口设置 if (n == 1) //第一个人 { age = 10; } else if (n > 1) //第2,3,4,5个人 { age = age(n-1) + 2; //当前第n个人的年龄 = 第n - 1个人的年龄 + 2 } int main() { printf("%d\n",get_age(5)); return 0; }
案例2
-
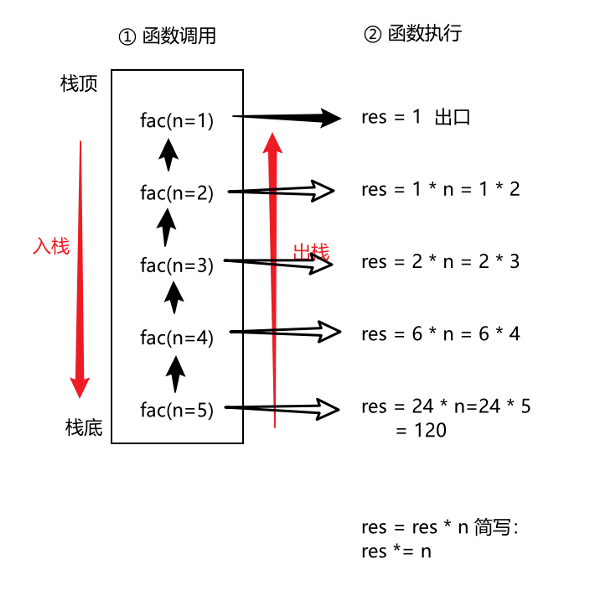
需求:求n的阶乘
-
分析:
-
代码
c/** * 定义一个函数,求n的阶乘值 * @param n 上限 * @return 阶乘运算结果 */ size_t fac(int n) // size_t 就是unsigned long int的别名,这个是等价的 { // 定义一个变量,用作阶乘结果的接收 size_t res; // 出口校验 if(n < 0) { printf("n的范围不能是0以下的数字\n"); return -1; } else if(n == 0 || n == 1) { res = 1; // 出口设置 } else // n > 1 { res = fac(n - 1) * n; } return res; } int main() { size_t n; printf("请输入一个整数:\n"); scanf("%lu", &n); printf("%lu的阶乘结果是%lu\n", n, fac(n)); return 0; }
排序算法:快速排序
快速排序是一种高效的分治(Divide and Conquer )排序算法,它的核心思想是通过选取一个基准值(pivot),将数组分为两个子数值:一个子数组的所有元素比基准值小,另一个子数组的所有元素比基准值大,然后递归地对子数维进行排序。
快速排序的基本步骤
1.选择基准值 :
- 从数组中选择一个元素作为基准值(pivot)。常见的选择方式包括:
- 第一个获最后一个元素(简单但可能效率不高,尤其是在已排序接近排序的数组中)。
- 随机选择一个元素(减少最坏情况概率)。
- 三数取中法(如第一个、中间、最后一个元素的中位数,提高分区均衡性)。
2.分区( Partition ) :
- 数组重新排列,使得
- 比基准值小的元素都在其左侧。
- 比基准值大的元素都在其右侧。
- 分区完成后,基准值的位置即为最终排序后的位置。
- (注:分区是快速排序的关键步骤,常见的实现有Lomuto分区和Hoare分区方案。)
3.递归排序(Recursion) :
- 对基准值左侧的子数组和右侧的子数组递归地应用快速排序。
- 递归的终止条件是子数组的长度为0或1(已有序)。
4.合并结果(Combine):
- 由于每次分区后基准值已位于正确位置,且左右子数组通过递归排序完成,因此无需显式合并操作,整个数组自然有序。
总结
快速排序,实际上就是通过一个基准值不断的拆分数组,一直到拆无可拆为止(就是拆成一个个的 数据元素)
代码

c
/**
* 定义一个函数,实现快速排序
* @param arr:待排序数组
* @param n: 数组长度
*/
void QSort(int arr[], int n) //函数传参,如果传递的是数组,形式参数收到的不是数组,而是数组的首地址(数组降级为指针)
{
//出口限制:子数组长度小于等于1
if (n < = 1) return;
int i = 0, j = n - 1;// 定义的两个指针,i是从左往右,j是从右往左
int pivot = arr[(n-1)/2]; // 选择中间元素元素作为基准值(可优化为随机或三位取中)
//分区过程
while(i < j)
{
// 从右向左找第一个小于等于基准值的元素(比基准值小的数)
while(arr[j] > pivot && i < j) j--;
// 从左向右找第一个大于基准值的元素(比基准值大的数)
while(arr[i] <= pivot && i < j) i++;
// 交换找到的两个元素
if (i < j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// 将基准值放到正确位置 (i = = j)
arr[0] = arr[i];
arr[i] = pivot;
// 递归排序左半部分(<=基准)
QSort(arr,i);
// 递归排序右半部分 (>基准)
QSort(arr+i+1, n - 1 - i);
}
int main()
{
int arr[] = {23,45,56,24,14,78,22,19};
int n = sizeof(arr) / sizeof(arr[0]);
QSort(arr, n);
//打印排序结果
for (int i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
printf("%-4d",arr[i]);
}
printf("\n");
return 0;
}数组做函数参数
定义
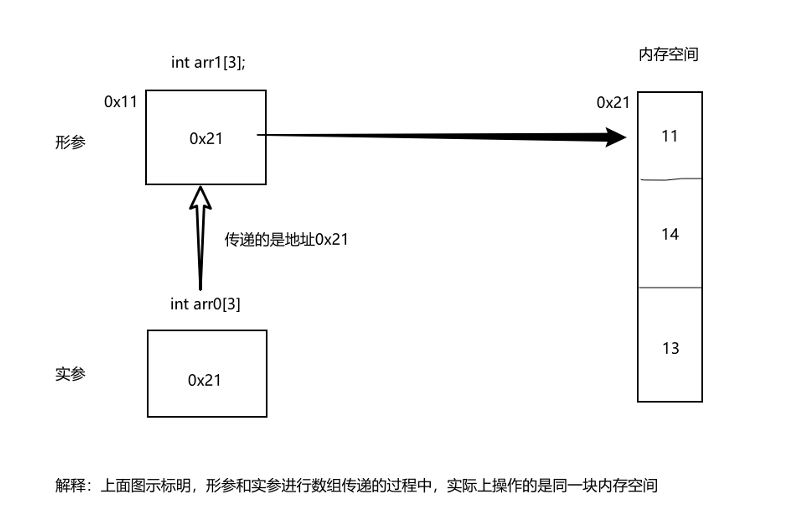
当使用数组作为函数的实参时,形参应该使用数组形式或者指针变量来接收。需要注意的是:
1.这种传递方式并不是传递数组中的所有元素数据,而是传递数组首地址,此时数组降级为指针。
2.形参接收到这个地址后,形参和实参指向同一块内存空间。
3.因此,通过形参对数组元素的修改会直接影响到实参。
这种传递方式称为"地址传递"(或"指针传递"),它与"值传递"的不同:
- 值传递:传递数据的副本,修改形参不影响实参
- 地址传递:
- 地址传递:传递数据的地址,通过形参可以修改实参。"地址传递"是逻辑上的说法,强调传递的是地址,而不是数据本身。数据本质上还是值传递。
当使用数组作为函数的形参时,通常需要额外传递一个参数表示数组的元素个数。这是因为:
1.数组形参退化为指针 在函数参数传递时,数组名会退化为指向其首元素的指针(即 int arr[]等价于 int *arr),因此函数内部无法直接获取数组的实际长度。
2.防止越界访问 由于形参仅知道数组的首地址,而不知道数组的实际大小,如果不传递元素个数,函数内部可能因错误计算或循环导致 数组下标越界(访问非法内存),引发未定义行为(如程序崩溃、数据损坏)。
3.通用性 即使实参数组的声明长度固定(如 int a[10]),函数仍应接收元素个数参数,因为函数可能需要处理不同长度的数组(例如动态数组或部分填充的数组)。
范例:
c
#include <stdio.h>
// 定义一个函数,将数组作为参数
void fun(int arr[], int len) // 数组传参,形参只能接收到实参数组的首地址,并不是完整的数组
{
for(inti=0;i< len; i++)
{
printf("%-4d",arr[i]);
}
printf("\n");
}
void main()
{
int arr[]={11,22,33,44,55};
int len=sizeof(arr)/sizeof(arr[0]);
fun(arr, len);
}但有一个例外,如果是用字符数组做形参,且实参数组中存放的是字符串数据(形参是字符数组,实参是字符串常量)。则不用表示数组个数的形参,原因是字符串本身会添加自动结束标志\0,举例:
c
#include <sidio.h>
//定义一个函数,传递一个字符串
void fun(char arr[])
{
char c;
int i = 0;
while(c = arr[i] ! = '\0')
{
printf("%c",c);
i++;
}
}
void main()
{
fun("hello");
}为什么 sizeof 不能用于形参数组?在函数内部, sizeof(arr)返回的是指针大小(如4/8字节),而非数组总字节数。例如:
c
void printsize(int arr[]){
printf("%zu\n",sizeof(arr)); // 输出指针大小(如 8),而非数组大小!
}案例
案例1
-
需求
有两个数组a和b,各有5个元素,将它们对应元素逐个地相比(即a0与b0比,a1 与b1比......)。如果a数组中的元素大于b数组中的相应元素的数目多于b数组中元素大 于a数组中相应元素的数目(例如,ai>b]i]6次,bi>ai 3次,其中i每次为不同的值),则 认为a数组大于b数组,并分别统计出两个数组相应元素大于、等于、小于的个数。
cint a[10] = {12,12,10,18,5}; int b[10] = {111,112,110,8,5}; -
代码:
c#include <stdio.h> #define LEN 5 /** * 定义一个函数,实现两个数字的比较 * @param x,y 参与比较的两个数字 * @return x>y --> 1, x < y --> -1, x == y --> 0 */ int get_large(int x, int y) { int flag = 0; if(x > y) flag = 1; else if(x < y) flag = -1; return flag; } int main() { //定义啊a,b两个测试数组 int a[LEN] = {12,12,10,18,5}; int b[LEN] = {111,112,110,8,5}; int i, max = 0, min = 0, k = 0; // 遍历数组,进行比较 for (i = 0; i < LEN; i++) { //同一位置两个数比较 int res = get_large(a[i],b[i]); if(res == 1) max++; else if (res == -1) min++; else k++; } printf("max=%d,min=%d,k=%d\n",max,min,k); return 0; }
案例2:
-
需求:编写一个函数,用来分别求数组score-1(有5个元素)和数组score_2(有10个元素)各元素的平均值。
-
代码:
c/** * 定义一个函数,求数组中元素的平均值 * @param scores 成绩数组 * @param len 数组大小 * @return 平均值 */ float get_avg(float scores[],int len) { int i; float aver,sum = scores[0]; // 平均分,总分 // 遍历数组 for(i = 1; i < len; i++) { sum += scores[i]; } //求平均分 aver = sum / len; return aver; } int main() { //测试数组 float scores1[] = {66,78,86,56,46}; float scores2[] = {77,88,98,87,67,65,55,45,67,78}; printf("%6.2f,%6.2f\n",get_avg(scores1,sizeof(scores1)/sizeof(scores1[0])),get_avg(score s2,sizeof(scores2)/sizeof(scores2[0]))); return 0; }