一,题目描述:
https://leetcode.cn/problems/longest-common-prefix/description/

给出一组字符串的列表(字符串数组),寻找这个列表/数组中每个数组元素的最长公共前缀
二,我的解法:
python
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
# 公共序列前缀必然存在于所有序列中,不妨以序列1为基础
substring=[] # 用于存储子串0的所有前缀,注意包括""
dict={} # 用于存储子串0每个前缀(在其他子串)的hit数
# 需要判断是否是空列表,如果是空列表,那么strs[0]就下标越界了,也就是index越界
if len(strs) == 0 :
return ""
for j in range(len(strs[0])):
substring.append(strs[0][0:j+1])
# 如果这个substring出现在所有字符中,则为公共子串
for sub in substring:
dict[sub] = 0 # 用0初始化字典,如果这里键ker不存在,直接对其进行操作,也就是下面的dict[sub]+=1,会导致keyError,所以需要在对键key进行访问操作前,确保所有的sub的已经存在字典中,才能够访问
# 或者 dict = {sub:0 for sub in substring}
for i in strs:
# 这里不能够使用in,因为in仅仅只是判断字符在不在,但不能确保是否是前缀字符,即s in asa,必须以前缀开始
if i.startswith(sub):
dict[sub] += 1
# 因为我们要获取最大的公共子串前缀,所以最好是取出该dict的key,然后最好是逆序取出,这样逆序的第1个满足的hit,其实就是最大的公共子串前缀
# dict.keys()是<class 'dict_keys'>格式数据,不能够迭代,所以最好是外面套一层list,再取逆序数
for key,value in dict.items():
print(f"{key}:{value}")
for i in list(dict.keys())[::-1]:
if dict[i] == len(strs):
return i
# 当所有前缀都没有匹配上,就是没有公共前缀
return ""想法其实很简单:公共子前缀必然出现在所有子字符串中,也就是数组中的所有元素都有,所以化一般为特殊,不妨取出第1个数组元素,获取其完备前缀子字符串数组,然后对于数组中的所有元素,一一比对这些前缀子字符串,找到大家都有的那个最长的子字符串前缀,就是答案。
我的想法是对于所有的前缀,构建1个计数count的hash表,如果count=数组的元素个数,那就说明这个前缀所有的元素中都有,所以得有1个字典:
python
substring_0 = [] # 先初始化存储子串0的所有前缀
substring_0_hit = {} # 我的想法是对于所有的前缀,构建1个计数count的hash表,如果count=数组的元素个数,那就说明这个前缀所有的元素中都有因为我后面for循环中要对数组索引下标index进行操作访问,所以得先判断是否是空列表:
判断空列表有很多方法,我此处选择判断列表的长度是否为0,也就是是否有元素,其余方法可以参考https://www.runoob.com/python3/python-empty-list.html
python
if len(strs) == 0:
return ""
# or
if not strs:
return ""然后紧接着,我想将strs0也就是第1个子串的所有前缀都取出来,依序存储在数组sub_string_0中,
按照数字下标获取切片,所以切片的索引要数字化,就range(len())经典搭配,然后1个1个appned进去:
注意range和切片都是左闭右开的,右边取不到,所以j是从0开始,第1个子前缀要0:1切片,所以是0:j+1(用特殊值的例子带入看一看,穷举形象化的逻辑);
注意这个时候在substring_0中的子串前缀,其实就是增序/升序的1个列表,比如说flower对应"f","fl","flo","flow","flowe","flower"
python
for j in range(len(strs[0]):
substring_0.append(strs[0][0:j+1])然后我们这里就要开始使用字典了,就是构建每一个前缀子串的count计数,我称之为hit:
首先要对这个字典初始化,如果没有初始化就直接count+=1的话,会出现kervalueerror,因为还没有定义键key,此处因为都是int计数,所以我初始化为0;
然后对于每一个子串前缀sub,都要遍历1遍所有的数组元素,也就是strs,看所有的strs中该前缀子串的hit数目总的是多少,但凡有1个数组元素和这个前缀匹配上,我们就在hash表中这个前缀key的值加1;
注意这里的匹配是指数组元素都以这个前缀子串作为前缀,也就是以它开头,所以是使用字符串函数startswith,注意不是in(in只能判断有没有,但不一定是前缀):
python
for sub in substring_0:
substring_0_hit[sub] = 0
for i in strs:
if i.startswith(sub):
substring_0_hit[sub] += 1然后对于获得的substring_0_hit,我们可以查看一下键值对的分布:
python
for prefix,count in substring_0_hit.items():
print(f"{prefix}:{count}")现在既然我们已经获取了这个字典,而且是升序子串前缀的字典,那么实际上我们就可以对其中count计数=len(strs)的所有key中,取最大的那个就可以了;
这里的话,为了查找方便,我直接将key逆序了,因为我们要找的是最大的公共子前缀,而原始的字典又是升序存储的,所以我们只要反过来key找,找到的第一个肯定就是最大的了;
逆序的话就是切片::-1,但是注意substring_0_hit.keys()是是<class 'dict_keys'>格式数据,可以type看看,不能直接取切片,所以我们需要将其转换为list列表格式的数据,再取切片;
然后注意是每一个前缀i都要检查过的,只有每一个前缀都没有了,我们才判断为没有公共子字符串前缀。
python
for i in list(substring_0_hit.keys())[::-1]:
if substring_0_hit[i] == len(strs):
return i
return ""整体整合起来就是:
python
# 本质:先从任意1个字符串中初始化1个公共前缀数组,再循环比对
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
substring_0 = [] # 先初始化存储子串0的所有前缀
substring_0_hit = {} # 我的想法是对于所有的前缀,构建1个计数count的hash表
if len(strs) == 0: # 空列表判断,防止空列表index操作越界
return ""
for j in range(len(strs[0]): # 提取strs[0]的所有前缀子串
substring_0.append(strs[0][0:j+1])
for sub in substring_0: # 对strs[0]中的所有前缀子串,在strs中遍历获取hash表的计数
substring_0_hit[sub] = 0
for i in strs:
if i.startswith(sub):
substring_0_hit[sub] += 1
for i in list(substring_0_hit.keys())[::-1]: # 逆序查找第1个hit符合len(strs)的key
if substring_0_hit[i] == len(strs):
return i
return "" 三,大佬们的优质解法:
1,官方解法1:
横线扫描,有点像横向的递归;

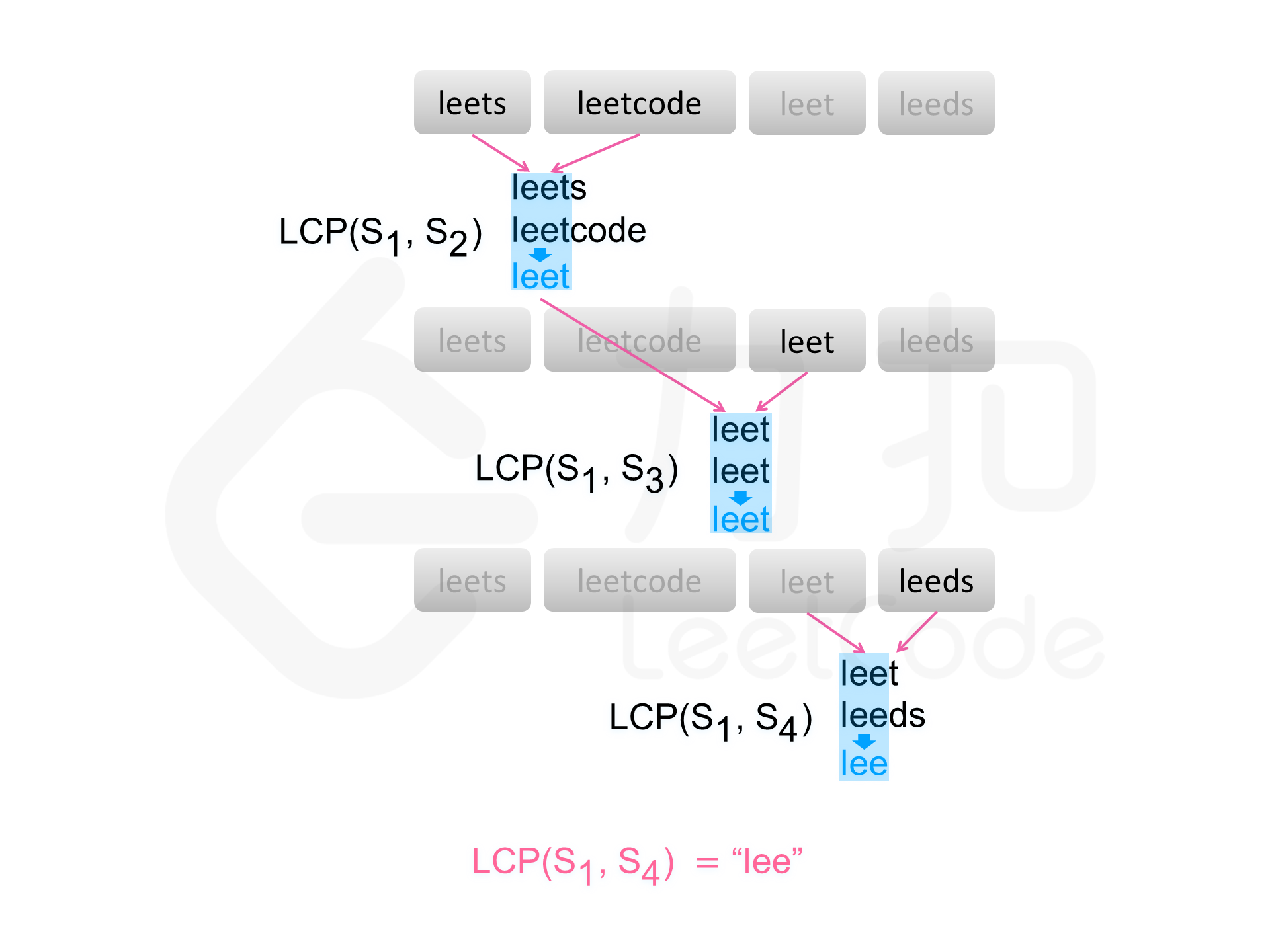
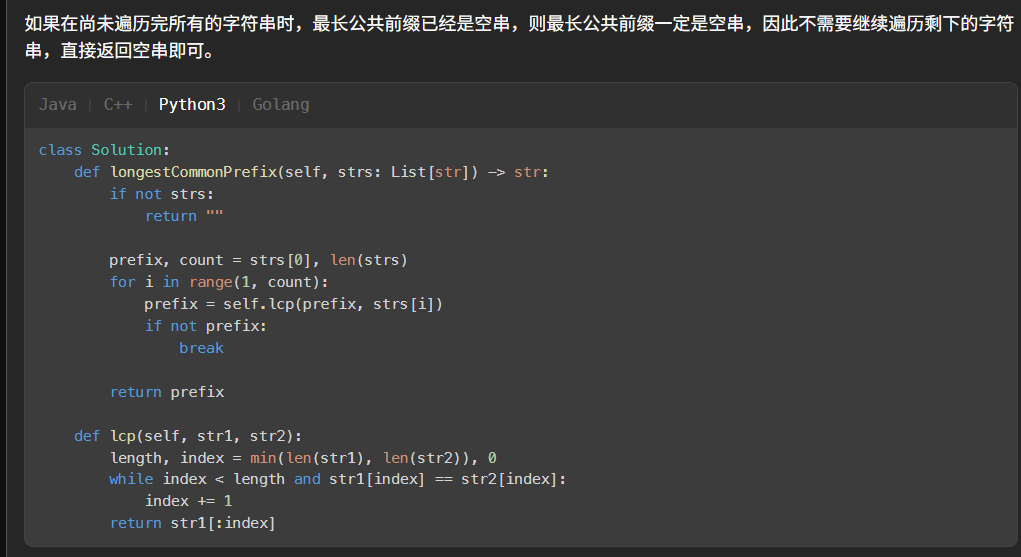
按顺依次合并或者说是对2个子串进行取最长公共前缀,然后更新为前缀,再和第3个进行归并,递归意味在里面;
重点在于
python
prefix = self.lcp(prefix, strs[i])因为多个取最长公共子前缀不好比,但是两个好取,然后多个的前缀取问题又可以化为两两递归的比较;
2个的话就从最短长度length开始比,index(0-indexed)比length(1-indexed)小,然后一次一次比值,逼到最大的即可;
python
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:
return ""
prefix, count = strs[0], len(strs)
for i in range(1, count):
prefix = self.lcp(prefix, strs[i])
if not prefix:
break
return prefix
def lcp(self, str1, str2):
length, index = min(len(str1), len(str2)), 0
while index < length and str1[index] == str2[index]:
index += 1
return str1[:index]时间复杂度的话,可以直接看第1个for循环(字符串数目n),然后里面其实调用lcp还有1个while循环(比价的是index和length,从length量级上考虑);

2,官方解法2:
纵向扫描,其实就是按照首字符对齐之后,然后对于每一列,先初始化,再按个冒泡下去,看看有没有不同的值出现
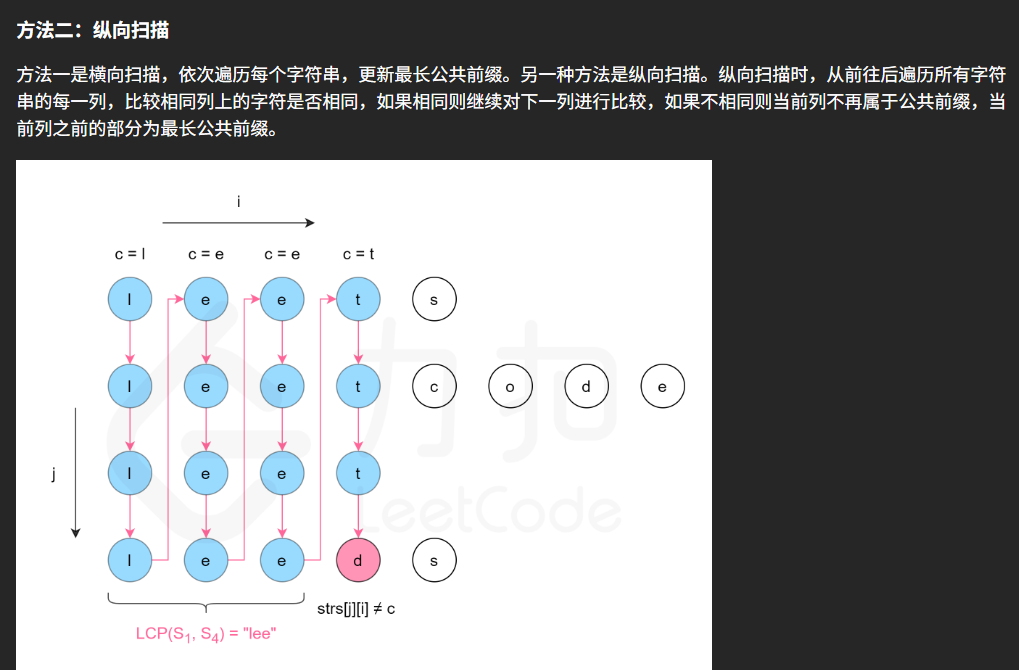
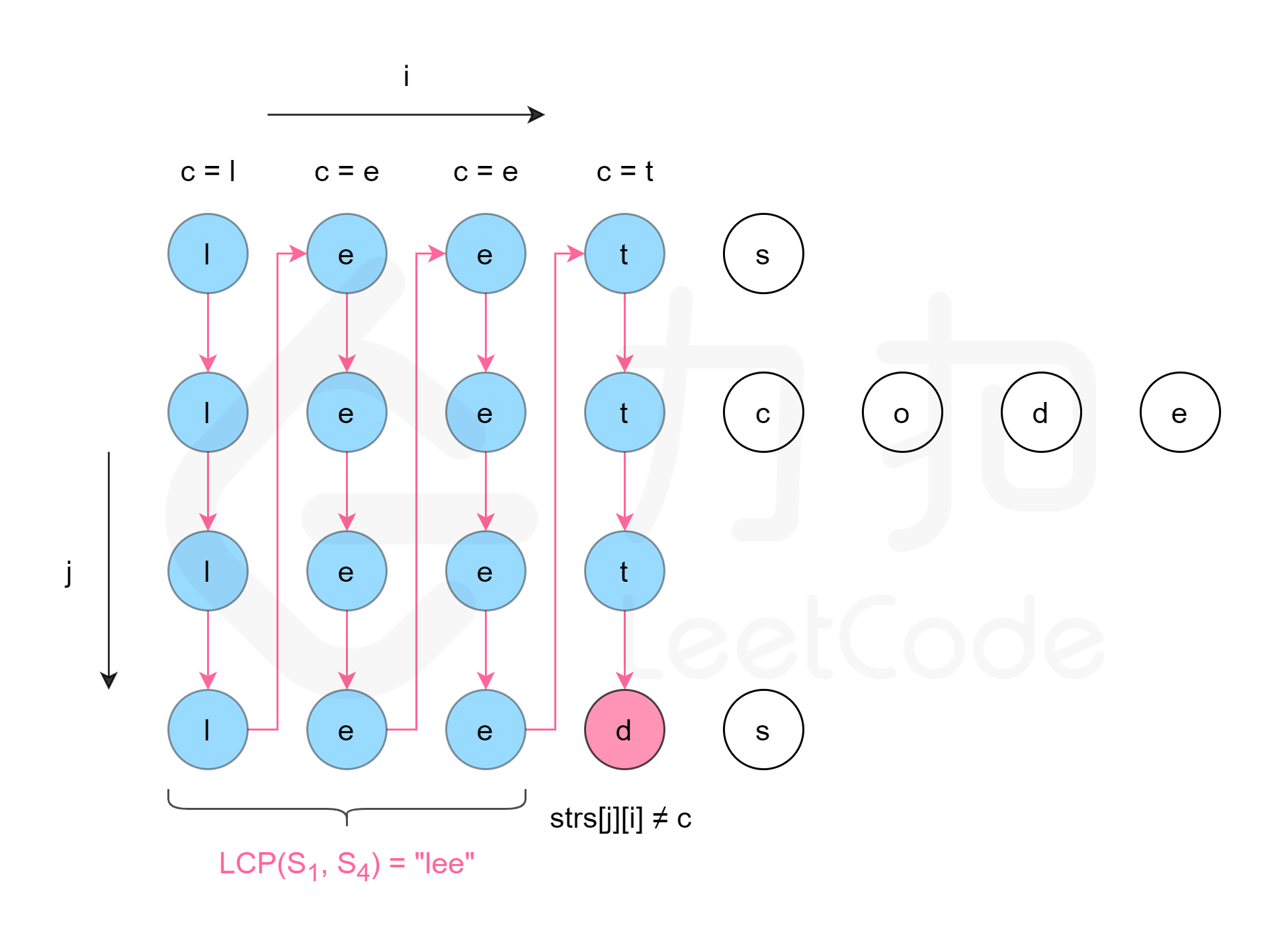
for i in range(length)按照第一个子串元素的列为基准进行对齐,获取其列数;
c = strs0i 每一列都要初始化1个用于比较的基准值;
for j in range(1, count)其实就是纵向冒泡每1列,
重点是前面这里的判断条件:
i是strs0为基准的列数,也就是第几列,j是range(1,count),实际上是遍历strs数组中的第几个字符串;
i == len(strsj)其实就是在比较其中第几个字符串是不是长度就这么长了,就到strs0的i列这里了;
如果是的话,说明i在i++迭代的话,那么这个第j个字符串长度就不够了;
所以这个条件其实是确保所有的字符串在目前的i列长度上起码能够对齐(在长度上对齐),只有长度对齐了(也就是长度达标了)才好在这一列上冒泡比较值,也就是这个值起码得存在,然后any的话,其实是判断这一列中起码有1行也就是起码有1个字符串是长度即将不行了;
至于or逻辑,有1个为真即为真,所以有1个长度对齐不了了也就是长度跟不上了,就要停止;
在长度跟得上的前提下,然后要在这一列位置上的所有字符串的的值,也就是第i列的值,要都等于基准参考值c。
我们终止的判断条件是:一旦出现(所谓一旦指的是第1次出现),
1️⃣一旦出现某列中有1个字符不匹配,也就是strsji != c;
2️⃣或者某个字符串的长度不足以包含当前索引的字符,即any(i == len(strsj);
如果i等于某个字符串的长度,注意我们比较的都是第i列的值,就相当于比如说某个字符串是长度为5,即len(strsj) 为5,然后i这里是5,实际上比的是第6列,那么因为我们比较的是strsji,如果字符串j长度为5,则第2个索引下标只能是range 0-4,所以strsj5实际上已经越界了;说明当前索引i已经超过了该字符串的范围,即该字符串比当前索引的字符更短。
那么,它就会返回当前已匹配的最长公共前缀,注意当前/已经,指的是strs0:i,这里的:i刚好没有渠道当前比较的字符i上,而是i-1。
any函数用于判断1个可迭代对象(主要是元组和列表)中是否有/存在1个为真,
https://www.runoob.com/python/python-func-any.html
python
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:
return ""
length, count = len(strs[0]), len(strs)
for i in range(length):
c = strs[0][i]
if any(i == len(strs[j]) or strs[j][i] != c for j in range(1, count)):
return strs[0][:i]
return strs[0]时间复杂度还是两个for循环之间

3,
因为操作对象是python中的字符串,所以可以先对字符串进行排序,简单理解为字符串的比大小,按照ASCII或者unicode;
在排序之后,可以原地排序sort,或者由可迭代对象构建新列表,也就是指向新的变量地址;
参考https://docs.python.org/zh-cn/3.12/howto/sorting.html
然后按照常理在排序之后,排在最前面的应该是最短的字符串,最后面的是最长的字符串,sort默认是升序,其余就是字符之间编码值大小的比较了;
然后实际上我们寻找最长公共前缀,本质上只要比较1个最短以及1个最长的极端字符串就可以了,
因为最短的最好提取前缀,最长的最稳定保留最短字符的前缀;
然后还是那个问题,两个字符串之间的比较其实是最简单的,所以本质上还是将多字符串前缀比较问题转换为了2字符串前缀比较问题,两个比较的话:
确保两个数a、b当前下标索引的值能够取到,值能够取到的前提下比较值是否相等,然后逐索引index相加字符,累计构建前缀。
一旦出现值不等,或index越界,就跳出循环,并返回当前累计的字符
python
class Solution:
def longestCommonPrefix(self, s: List[str]) -> str:
if not s:
return ""
s.sort()
n = len(s)
a = s[0]
b = s[n-1]
res = ""
for i in range(len(a)):
if i < len(b) and a[i] == b[i]:
res += a[i]
else:
break
return res其余解法可以参考:
https://leetcode.cn/problems/longest-common-prefix/solutions/