1.机器学习概述(全部流程)
获取数据:from sklearn.datasets import load_wine
数据处理(数据集划分、标准化):from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
特征工程:from sklearn.featrue_extraction import DictVectorizer(字典列表特征提取)
from sklearn.featrue_extraction import CountVectorizer(文本特征提取)
from sklearn.featrue_extraction import TfidfVectorizer(TF-IDF文本特征词的重要程度特征提取)
这上面是特征提取,可以任选其一。
from sklearn.decomposition imoprt PCA(特征降维)
实例化预估器(生成模型):from sklearn.neighbors import KNeighborsClassifier
训练模型:model.fit(x_train_pca,y_train)
模型评估:model.score(x_test_pca,y_test)
预测数据:model.predict(x_new)
2.knn算法介绍
KNN(K - Nearest Neighbor)即 k 近邻算法 ,是一种基本的监督学习方法,既能用于分类,也能用于回归。
简单来说就是 "物以类聚,人以群分" 。算法假定给定一个训练数据集,其中实例的类别是已知的。在进行分类(或回归)时 ,对于一个新的实例,通过寻找其 k 个最近邻的训练实例 ,依据这些近邻的类别(或数值 )情况,通过多数表决(分类任务 )来预测新实例的类别(或数值 ) 。例如,在判断一个水果是苹果还是梨时,计算该水果与已知苹果和梨在颜色、大小等特征上的距离,选取距离最近的 k 个水果,根据它们中苹果或梨占比多的类别来判断新水果的类别。
简单来说计算步骤就是:
(1)计算实例与训练集中的每一个样本的距离;
(2)确定k的值;
(3)统计这k个值的分类结果,最多的就是实例的分类结果。
3.样本距离判断
3.1欧氏距离--L2距离

3.2曼哈顿距离-L1距离

4.原理
根据K个邻居样本的类别来判断当前样本的类别;
如果一个样本在特征空间中的k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别
比如: 有10000个样本,选出7个到样本A的距离最近的,然后这7个样本中假设:类别1有2个,类别2有3个,类别3有2个.那么就认为A样本属于类别2,因为它的7个邻居中 类别2最多(近朱者赤近墨者黑)
k为邻居数---哪个类型的邻居多,那这个就是什么类型。
5.API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
algorithm参数是 KNN 等算法的性能优化工具 ,与模型的预测逻辑无关。在实际开发中,建议使用默认值'auto',系统会根据数据特性自动选择最优方案。只有在对特定场景有深入了解(如高维数据、大规模数据)时,才需手动调整该参数。
6.模型保存与加载
导入库:import joblib
保存模型:joblib.dump(model,'my_ridge.pk1')
加载模型:joblib.load('my_ridge.pk1')
预测数据:y_pred = model.predict(data)
如果想保存在其他路径:
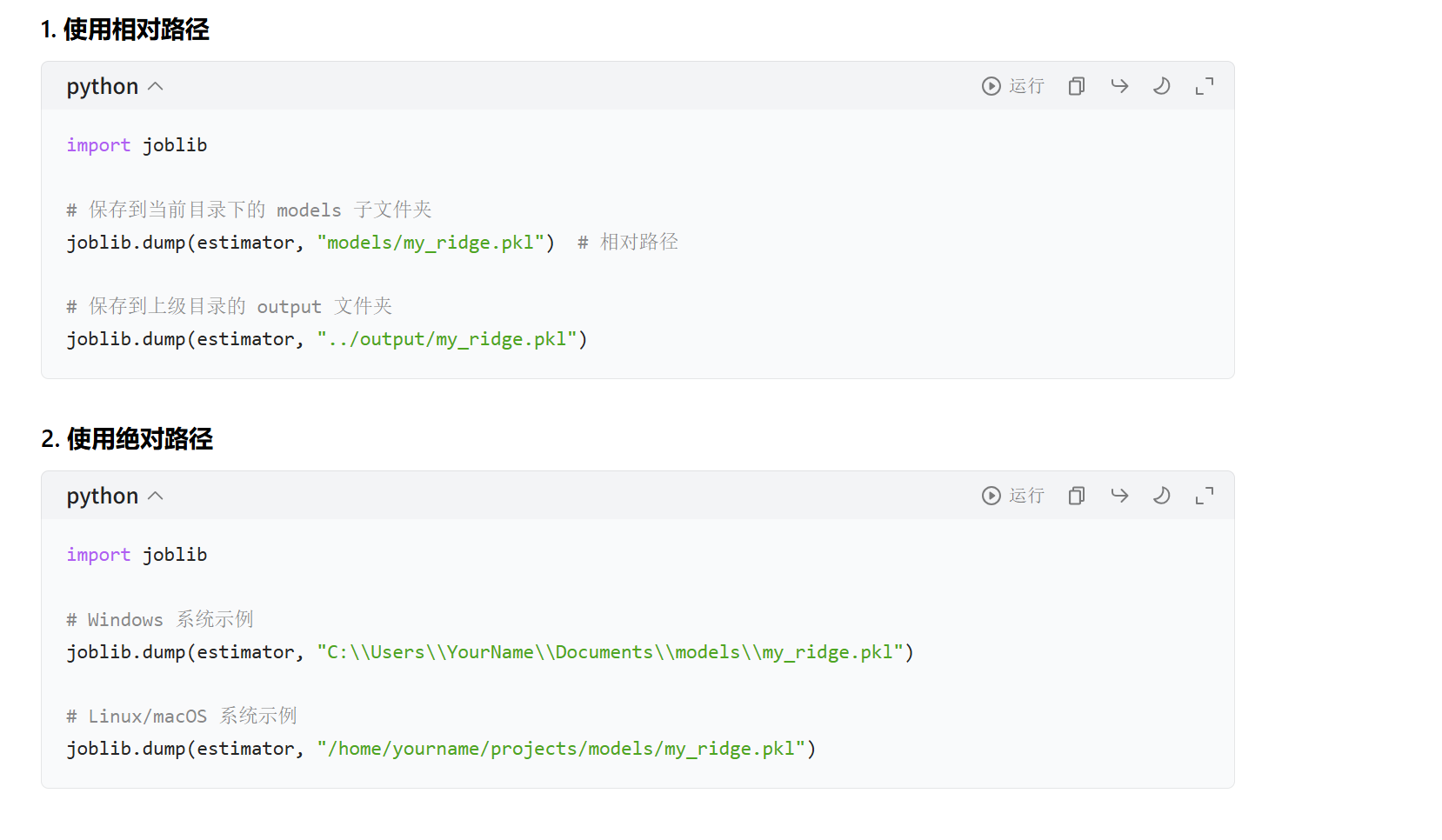
7.KNN葡萄酒案例
根据本文章的第一条内容来写:

也可以再结合模型保存,进行预测数据。这样的好处就是之后不用全部再训练一次,可以直接拿出来用。
python
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
import joblib
# 第一步加载数据
wine = load_wine()
print(wine.data.shape) #查看数据集形状
# 第二步划分数据集
x_train,x_test,y_train,y_test = train_test_split(wine.data,wine.target,test_size=0.3,random_state=44)
# 将模型划分为训练集和测试集,x为数据内容,y为标签(结果)内容
# 第三步标准化--标准化x
scaler = StandardScaler()
x_train_scaler = scaler.fit_transform(x_train)
x_test_scaler = scaler.transform(x_test)
# print('我是标准化后的x训练集:',x_train_scaler)
# print('我是标准化后的x测试集:',x_test_scaler)
# 第四步特征降维--也是对x进行特征工程处理
pca = PCA(n_components=8) #将原本13个列标签的数据全部降维为8个标签的数据
x_train_pca = pca.fit_transform(x_train_scaler)
x_test_pca = pca.transform(x_test_scaler)
# print('我是降维后的x训练集:',x_train_pca)
# print('我是降维后的x测试集:',x_test_pca)
# 第五步生成模型
estimator = KNeighborsClassifier(n_neighbors=7)
# 紧接着训练模型
estimator.fit(x_train_pca,y_train)
# 第六步预测测试集
y_pred = estimator.predict(x_test_pca)
print('预测x测试集:\n',y_pred)
#对比真实值、预测值:布尔
print('x_test的预测值与真实值y_test直接对比:\n',y_test == y_pred)
# 第七步评估模型准确率
score = estimator.score(x_test_pca,y_test)
print('评分为(准确率为):\n',score)
# 第八步保存模型
joblib.dump(estimator,'机器学习sklearn/srcc/save_model/knn_estimator.pkl')
# 第九步加载模型预测新数据
estimator = joblib.load('机器学习sklearn/srcc/save_model/knn_estimator.pkl')
new_pred = estimator.predict([[12,3,0,6,7,1,9,3]])
print('我是模型加载预测的值:\n',new_pred)结果:
(178, 13)
预测x测试集:
[0 1 0 2 2 0 1 1 0 1 0 0 1 0 1 1 1 0 0 0 0 2 0 0 0 0 2 2 2 1 1 2 1 1 1 0 0
2 2 0 1 1 0 0 1 2 2 1 2 0 1 1 0 1]
x_test的预测值与真实值y_test直接对比:
[ True True True True True True True True True True True False
True True True True True True True True True True False True
True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True]
评分为(准确率为):
0.9629629629629629
我是模型加载预测的值:
0