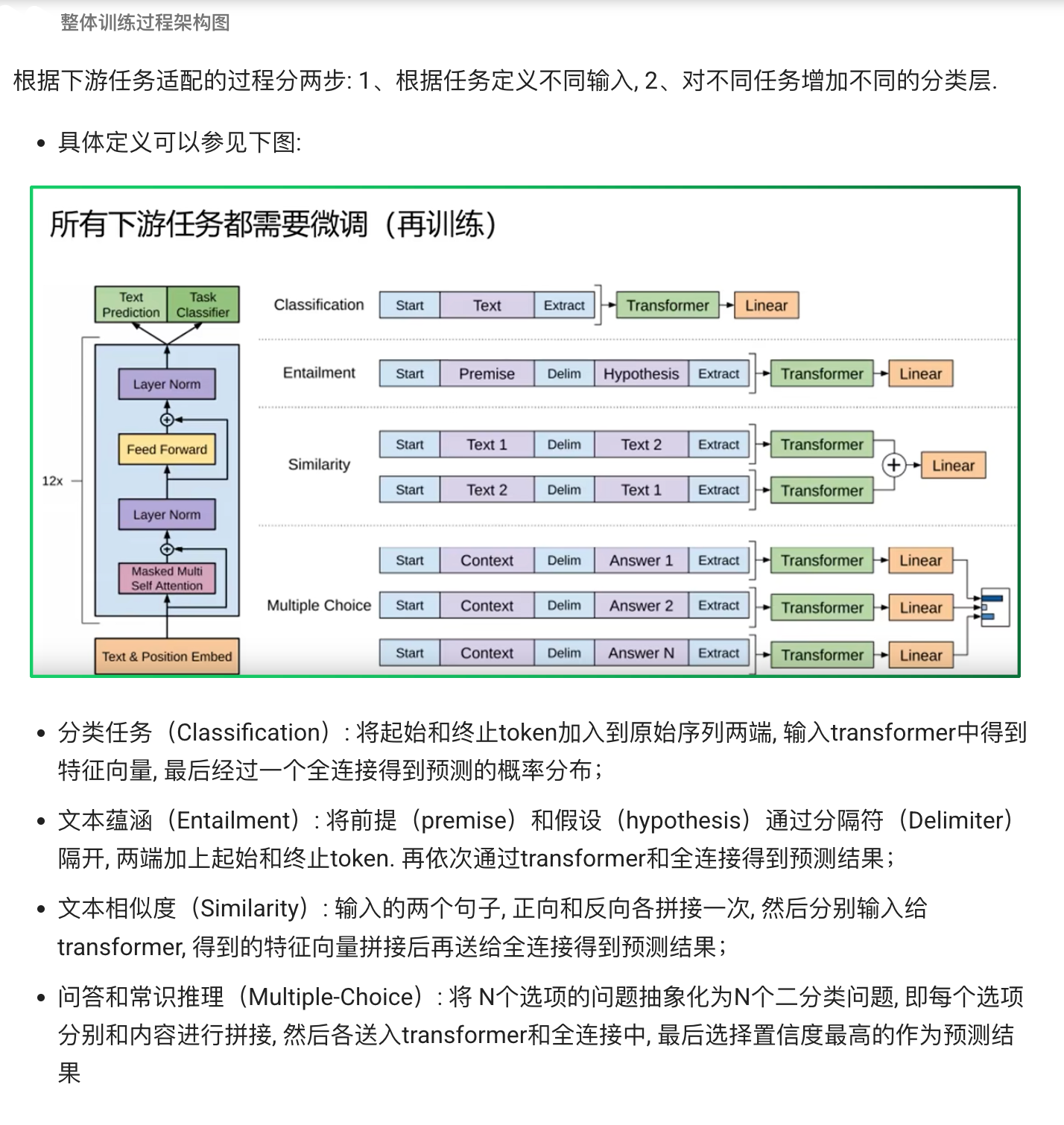
下面用一句话+四个例子,把上面那张"所有下游任务都要微调"架构图说清楚:
核心思路 :不管你要做什么任务,都用同一个 Transformer(这里是 GPT/Decoder-Only 模型)当"特征抽取器",只需在输入端"拼"出不同格式的 token 序列(加上 Start/Delim/Extract),在输出端接上不同的 小头(task‐specific head),微调时只训练这部分新加层(当然也可以微调部分 Transformer 层)。
1. 文本分类(Classification)
-
输入拼法:Start 文本内容 Extract
-
流程:
-
在句子最前加一个 Start token(如 <s> 或 CLS),末尾加一个 Extract token(可不显式标出,直接用最后一个位置)。
-
全序列送入 Transformer,取最后一个位置的隐藏向量(或取 Start 位置的隐藏向量,视实现而定)。
-
接一个全连接+Softmax,就能输出各分类概率(正例 vs. 反例,或多分类)。
-
2. 文本蕴涵(Entailment)
-
输入拼法:Start 前提(Premise) Delim 假设(Hypothesis) Extract
-
流程:
-
用一个 Delimiter(如 SEP)把两个句子切开。
-
Transformer 编码后,取最后一个隐藏向量(Extract)或 Start 位置向量,接线性层预测"蕴涵 / 不蕴涵 / 中立"等标签。
-
3. 文本相似度(Similarity)
-
输入拼法:
-
正向:Start 文本A Delim 文本B Extract
-
反向:Start 文本B Delim 文本A Extract
-
-
流程:
-
分别把两种拼法的序列喂入同一个 Transformer,得到两个 Extract 向量;
-
将这两个向量拼接(或做点积、余弦相似度),再接一个小线性层,输出相似度分数。
-
4. 多选/常识推理(Multiple Choice)
-
输入拼法(针对每个选项):
[Start] 问题 (Context) [Delim] 选项1 (Answer1) [Extract]
[Start] 问题 [Delim] 选项2 (Answer2) [Extract]
......
[Start] 问题 [Delim] 选项N (AnswerN) [Extract] -
流程:
-
每条"问题+一个选项"单独过 Transformer,取 Extract 向量;
-
每个 Extract 向量接一层线性层算分;
-
N 个分数中选最大的那个选项为模型答案。
-
为什么这样做?
-
统一:所有任务共用同一个预训练好的 Transformer 这里是decoder,节省研发和算力;
-
灵活:只要在"输入拼法"和"输出头"上下功夫,就能适配分类、蕴涵、相似度、问答、多选等几乎所有 NLP 任务;
-
高效:微调时只需在新加的那层(task head)上动点小学习率,或者连同少量 Transformer 层一起更新,就能快速收敛到 SOTA 水平。
总的来说,都是通过在序列前后添加 Start 和 Extract 特殊标识符来表示开始和结束,序列之间添加必要的 Delim 标识符来表示分隔,当然实际使用时不会直接用 "Start/Extract/Delim" 这几个词,而是使用某些特殊符号。基于不同下游任务构造的输入序列,使用预训练的 GPT 模型进行特征编码,然后使用序列最后一个 token 的特征向量进行预测。
可以看到,不论下游任务的输入序列怎么变,最后的预测层怎么变,中间的特征抽取模块都是不变的,具有很好的迁移能力。