一、激活函数
激活函数的作用
激活函数在神经网络中起着至关重要的作用,主要用于引入非线性因素,使得神经网络能够学习和模拟复杂的非线性关系。如果没有激活函数,无论神经网络有多少层,最终都只能表示线性变换,无法处理复杂的任务。
激活函数的主要作用包括:
- 引入非线性,使神经网络能够学习和表示复杂的模式。
- 决定神经元是否应该被激活,即是否将信息传递到下一层。
- 帮助控制神经网络的输出范围,使其适合特定的任务。
五种常见的激活函数及其Python实现
1.Sigmoid 激活函数
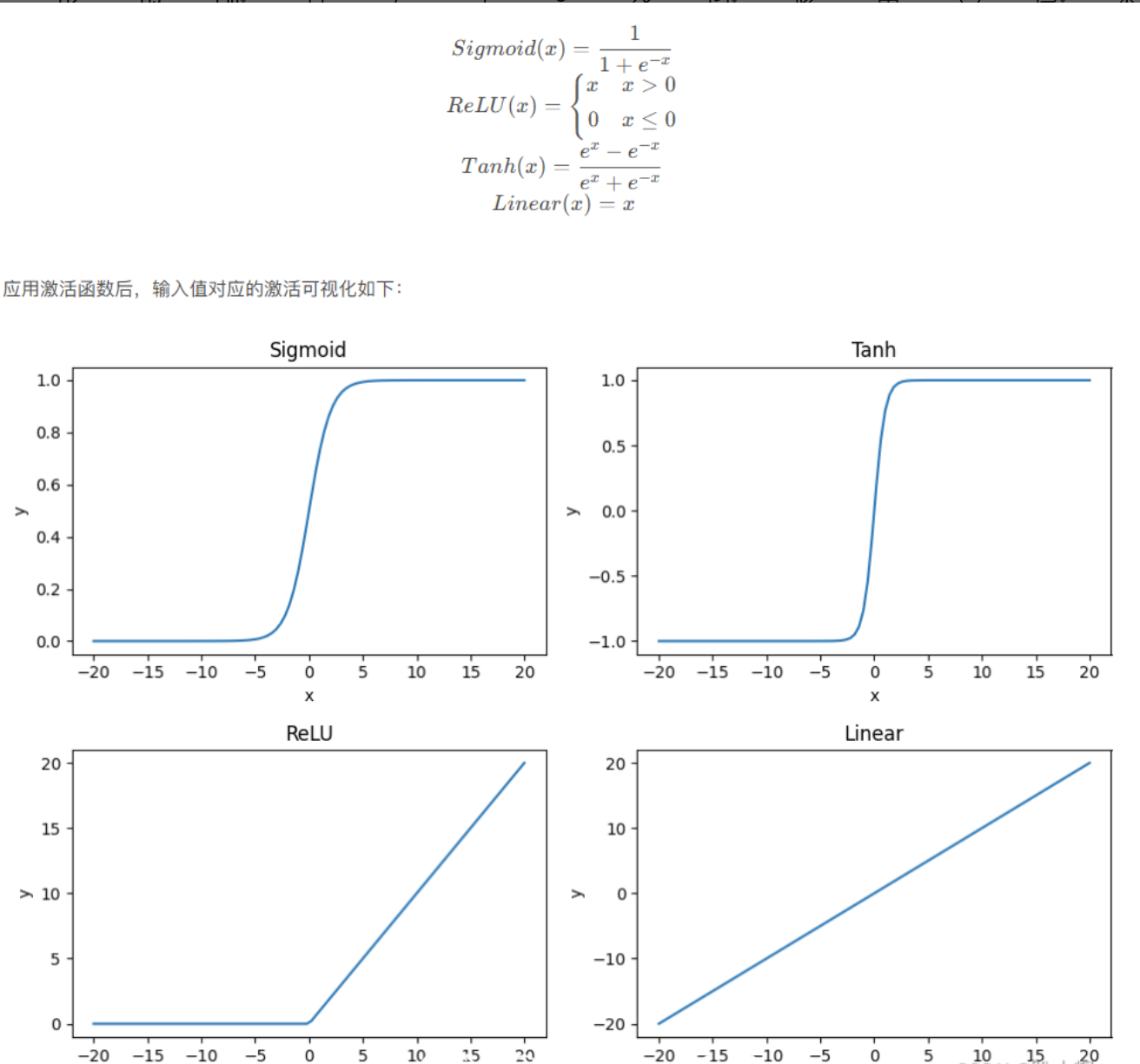
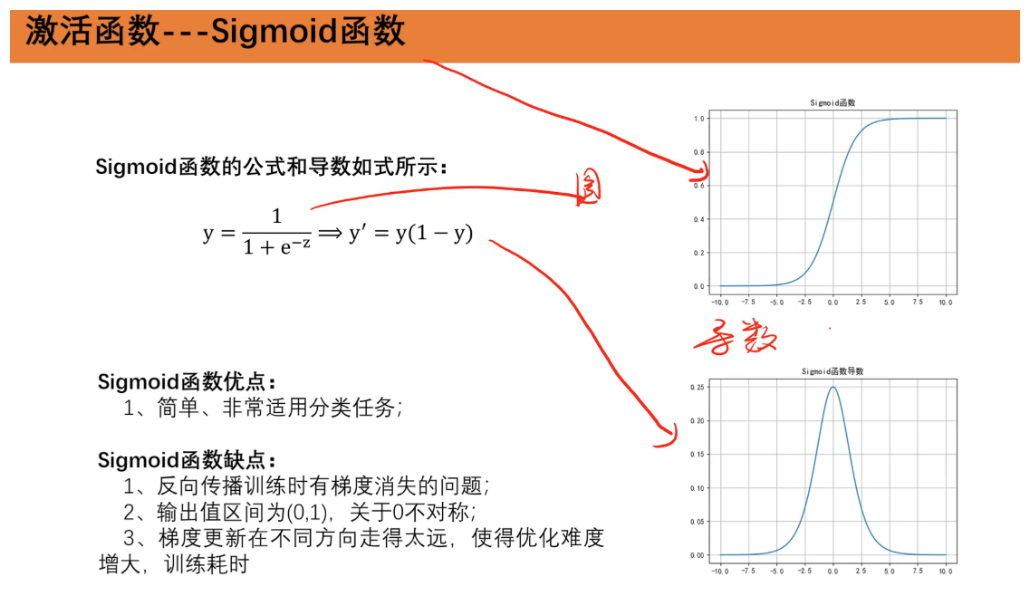
Sigmoid 函数将输入映射到 (0, 1) 之间,常用于二分类问题。
python
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))2.Tanh 激活函数
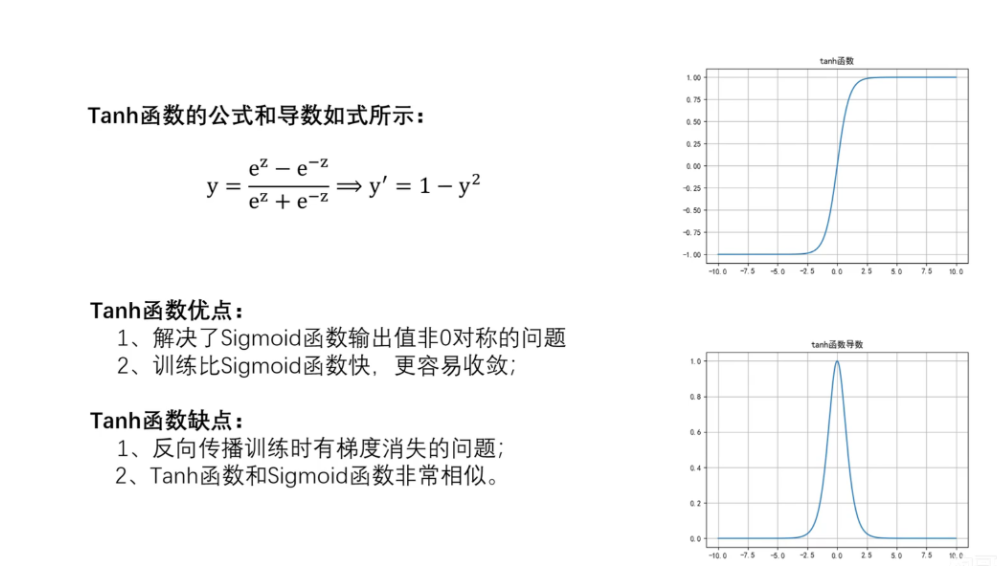
Tanh 函数将输入映射到 (-1, 1) 之间,通常比 Sigmoid 函数表现更好,因为它的输出以零为中心。
python
def tanh(x):
return np.tanh(x)3.ReLU 激活函数
ReLU(Rectified Linear Unit)函数在输入大于零时返回输入值,否则返回零。ReLU 是目前最常用的激活函数之一,因为它计算简单且能有效缓解梯度消失问题。
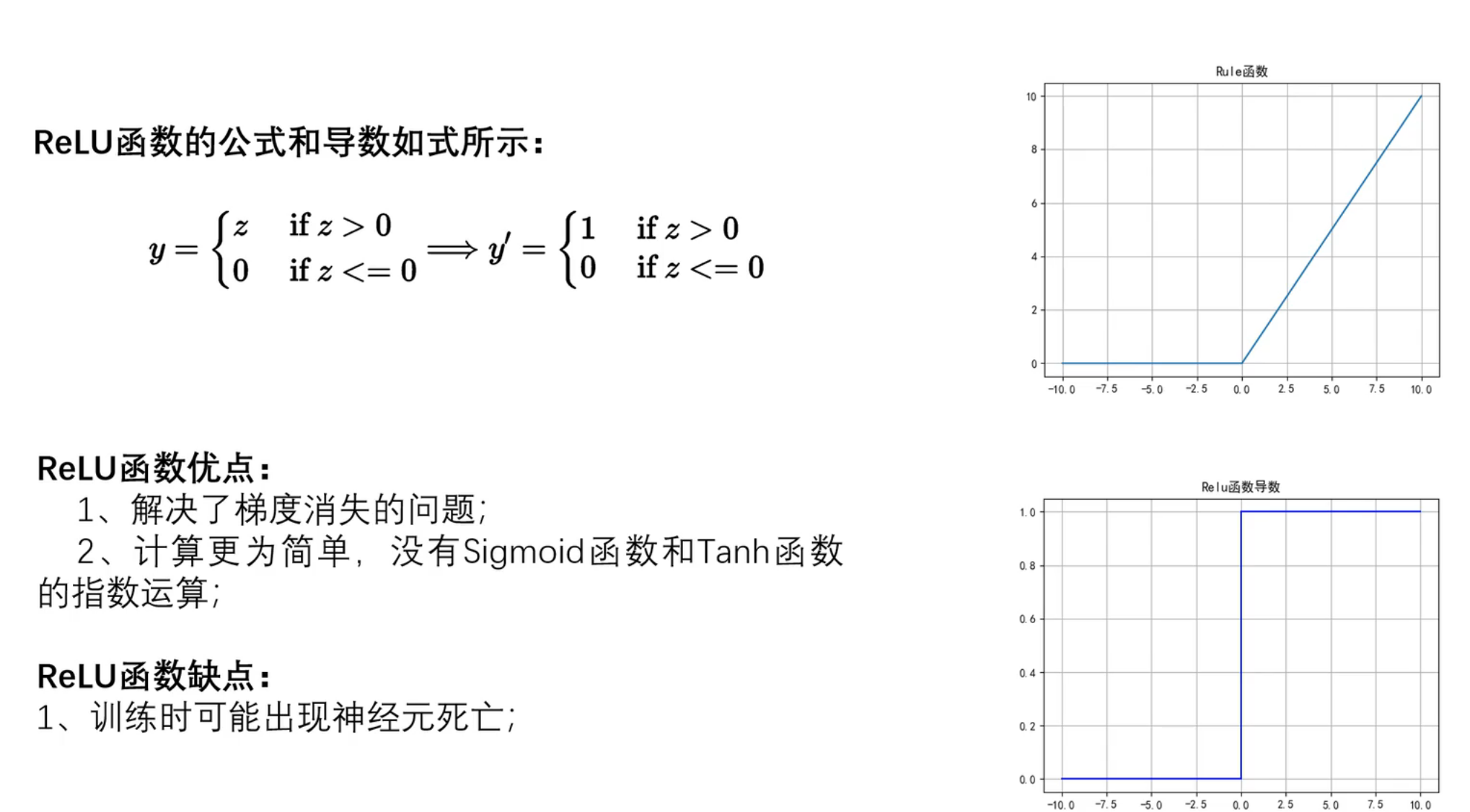
python
def relu(x):
return np.maximum(0, x)4.Leaky ReLU 激活函数
Leaky ReLU 是一种常用的激活函数,它在输入为负时引入一个小的斜率,而不是像标准 ReLU 那样直接输出零。这有助于缓解神经元"死亡"问题。以下是 Leaky ReLU 的代码实现。
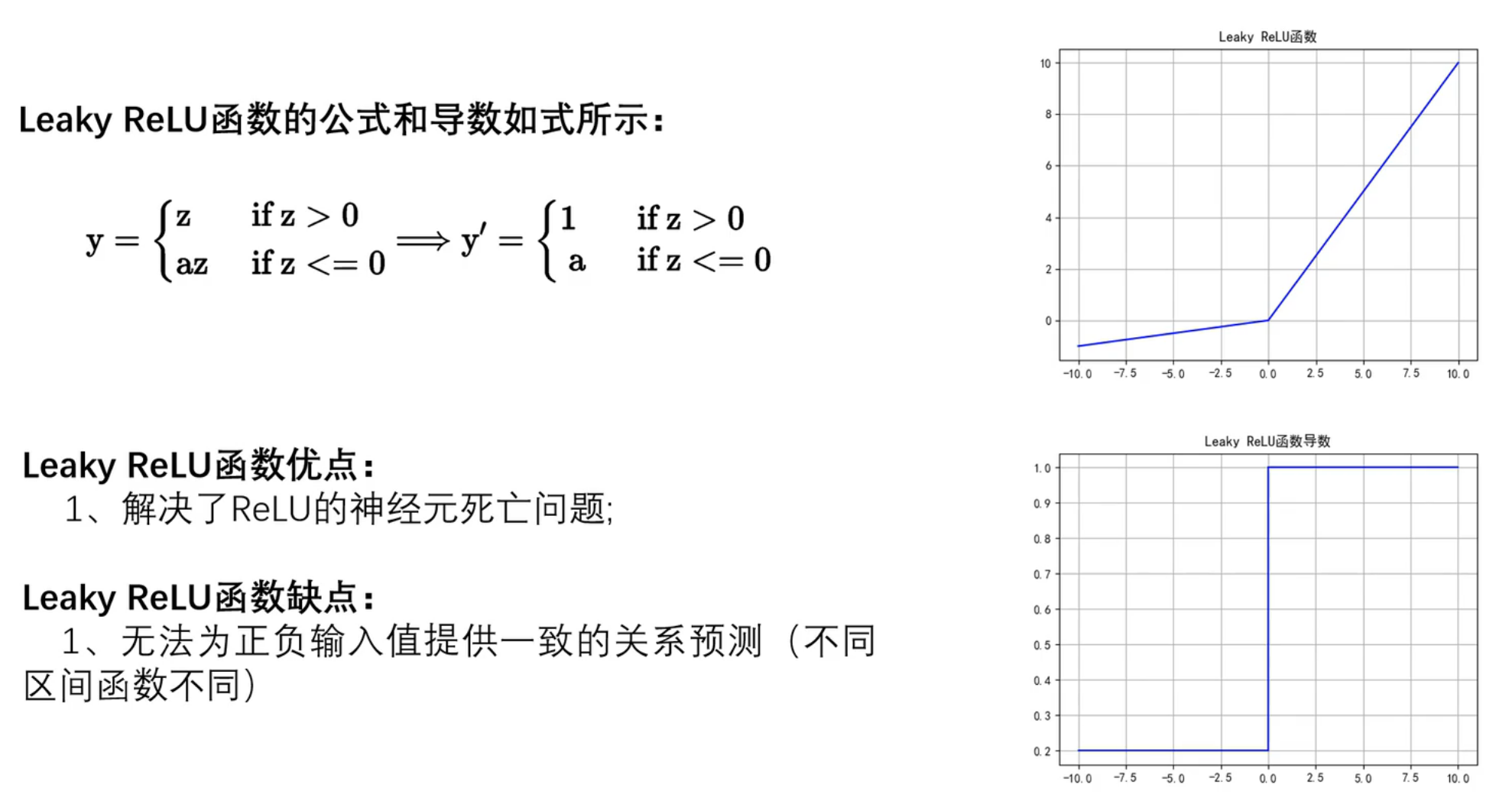
python
import numpy as np
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)5.Softmax 激活函数
Softmax 函数通常用于多分类问题的输出层,它将输入转换为概率分布,所有输出的和为1。
python
def softmax(x):
exp_x = np.exp(x - np.max(x)) # 防止数值溢出
return exp_x / np.sum(exp_x, axis=0)使用示例
python
x = np.array([1.0, 2.0, 3.0])
print("Sigmoid:", sigmoid(x))
print("Tanh:", tanh(x))
print("ReLU:", relu(x))
print("Leaky ReLU:", leaky_relu(x))
print("Softmax:", softmax(x))这些激活函数在不同的场景下有不同的应用,选择合适的激活函数可以显著提升神经网络的性能。
二、前向传播的实现
前面已经介绍了前向传播的过程
(Forward Propagation)
步骤:
输入图像通过卷积层提取特征得到张量数据
(卷积层:通过卷积核(Filter)提取局部特征(如边缘、纹理))
张量数据与权重相乘加上偏置值得到隐藏层数据
隐藏层通过激活函数引入非线性,作为下一层的输出数据
重复这一步骤直到输出最后的结果
现在进行一个简单的代码实现
python
import numpy as np
# 定义激活函数(例如Sigmoid函数)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def Leaky_relu(x, negative_slope=0.01):
return np.where(x >= 0, x, negative_slope * x)
# 初始化参数
def initialize_parameters(n_x, n_h, n_y):
# 2,3,1
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1)) #n_h×1的全0数组
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
#print("初始化参数为:",W1,b1,W2,b2)
return {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
# 前向传播函数
def forward_propagation(X, parameters):
# 获取参数
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# 计算隐藏层的线性部分
Z1 = np.dot(W1, X) + b1
# 应用激活函数
A1 = sigmoid(Z1)
# 计算输出层的线性部分
Z2 = np.dot(W2, A1) + b2
# 应用激活函数
A2 = sigmoid(Z2)
# 存储中间变量
cache = {"Z1": Z1, "A1": A1, "Z2": Z2, "A2": A2}
return A2
if __name__ == "__main__":
# 示例输入
X = np.array([[1, 2], [3, 4]])
parameters = initialize_parameters(2, 3, 1)
# 执行前向传播
A2, cache = forward_propagation(X, parameters)
print("预测输出:", A2, cache)其实是非常简单的

三、反向传播的实现
反向传播就是根据前向传播的损失值反向修改参数w和b,再次带入模型中进行正向传播,然后计算判断两次传播之间的损失值变化
当损失值值上升时说明误差增大,此时应该按照之前修改趋势相反的方向调整参数
通过设置学习率来调整参数修改的速度,不断的循环重复这一步骤,直到找到最合适的参数
python
import Feed_forward as forward//前面前向传播的模块名
import numpy as np
from copy import deepcopy
#L2损失值 均分损失
def L2_loss(preputs,outputs):
return np.mean(np.square(preputs - outputs))
def backward_propagation(inputs,outputs,parameters,lr=0.1):
# 使用深拷贝创建对象
original_weights = deepcopy(parameters)
temp_weights = deepcopy(parameters)
updated_weights = deepcopy(parameters)
#原始损失值
original_loss=L2_loss(inputs,outputs)
for i, layer in enumerate(original_weights):
for index,_ in np.ndenumerate(temp_weights[layer]):
#修改权重
temp_weights[layer][index] += 0.01
#print("ori-temp",original_weights,temp_weights)
temp_outputs = forward.forward_propagation(inputs, temp_weights)
#print("第一次输出",outputs,"第二次输出",temp_outputs)
loss_puls=L2_loss(outputs,temp_outputs)
# 计算梯度变化引起的损失值
grad = (loss_puls - original_loss) / 0.01
# 通过损失变化来更新参数,grad为正代表损失值上升,说明参数上升损失上升,通过-=降低参数,反之亦然
updated_weights[layer][index] -= grad * lr
return updated_weights
if __name__ == "__main__":
# 示例输入
X = np.array([[1, 3], [2, 4]])
#参数
parameters = forward.initialize_parameters(2, 3, 1)
# 执行前向传播
A2 = forward.forward_propagation(X, parameters)
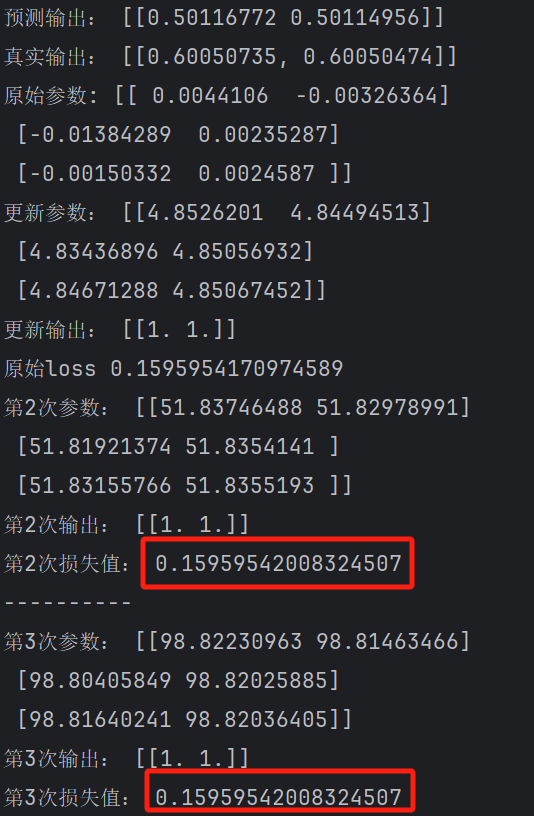
print("预测输出:", A2)
output= [[0.60050735,0.60050474]]
print("真实输出:",output)
print("原始参数:",parameters['W1'])
updated_weights=backward_propagation(X,output,parameters,lr=0.01)
print("更新参数:",updated_weights['W1'])
temput = forward.forward_propagation(X, updated_weights)
loss=L2_loss(output,temput)
print("更新输出:",temput)
print("原始loss",loss)
i=1
while(100*loss>3):
i+=1
updated_weights = backward_propagation(X, output, updated_weights, lr=0.1)
print(f"第{i:}次参数:", updated_weights['W1'])
temput = forward.forward_propagation(X, updated_weights)
print(f"第{i:}次输出:", temput)
loss = L2_loss(output, temput)
print(f"第{i:}次损失值:", loss)
print("-"*10)
if(i==1000):
break
print("最终参数:", updated_weights['W1'])
print("最终输出:", temput)这是代码的输出,很快就到达了上限,由于使用的sigmod激活函数,0,1之间,当然这只是一个简单的演示,希望你对前向传播和反向传播的概念和过程有所理解