火山引擎的实时对话 AI 应用示例(rtc_conversational_ai)展示了如何利用 WebRTC、大模型、语音识别(ASR)、语音合成(TTS)等技术实现低延迟的实时对话功能。以下是其前端代码实现的逻辑介绍,帮助你理解其核心机制和实现思路。
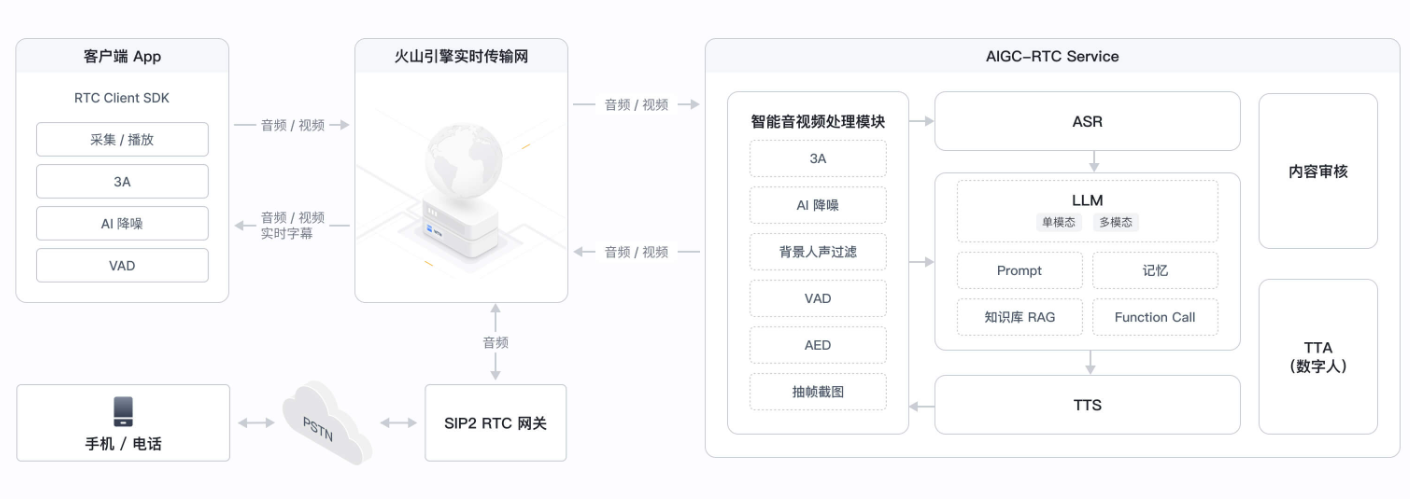
1. 项目结构与核心模块
前端代码通常包含以下关键模块:
- 音视频采集与传输:通过 WebRTC 实现音视频流的实时传输。
- 语音识别(ASR):将用户语音转换为文本,传递给大模型。
- 大模型交互:调用火山引擎的 API,获取 AI 生成的回复文本。
- 语音合成(TTS):将 AI 回复的文本转换为语音,播放给用户。
- UI 交互:展示对话历史、控制通话状态(开始/结束通话)等。
2. 核心逻辑实现
(1) 音视频采集与 WebRTC 连接
-
功能:采集用户的麦克风和摄像头输入,通过 WebRTC 建立点对点连接。
-
关键代码:
// 初始化 WebRTC const peerConnection = new RTCPeerConnection(config); // 采集本地音视频流 navigator.mediaDevices.getUserMedia({ audio: true, video: true }) .then(stream => { localStream = stream; localVideo.srcObject = stream; stream.getTracks().forEach(track => peerConnection.addTrack(track, stream)); }); // 处理远端音视频流 peerConnection.ontrack = (event) => { remoteVideo.srcObject = event.streams[0]; };
(2) 语音识别(ASR)
- 功能:将用户语音实时转换为文本,发送给大模型。
- 实现方式:
-
使用 Web Audio API 捕获音频数据。
-
调用火山引擎的 ASR API(如 Speech-to-Text)进行实时识别。
const audioContext = new AudioContext();
const mediaStreamSource = audioContext.createMediaStreamSource(localStream);
const recognizer = new SpeechRecognizer(apiKey, apiSecret);mediaStreamSource.connect(audioContext.destination);
mediaStreamSource.connect(recognizer.audioProcessor);recognizer.onResult = (text) => {
sendToAIModel(text); // 发送文本给大模型
};
-
(3) 大模型交互
- 功能:将用户语音转换的文本发送给大模型,获取 AI 回复。
- 实现方式:
-
调用火山引擎的大模型 API(如 Chatbot API)。
-
处理异步响应,将回复文本传递给 TTS 模块。
async function sendToAIModel(text) {
const response = await fetch('https://api.volcengine.com/ai/chat', {
method: 'POST',
headers: { 'Authorization':Bearer ${apiKey}},
body: JSON.stringify({ query: text }),
});
const data = await response.json();
synthesizeSpeech(data.reply); // 调用 TTS 合成语音
}
-
(4) 语音合成(TTS)
- 功能:将 AI 回复的文本转换为语音,播放给用户。
- 实现方式:
-
调用火山引擎的 TTS API(如 Text-to-Speech)。
-
播放合成的音频。
const synthesizer = new TextToSpeech(apiKey, apiSecret);
synthesizer.onAudio = (audioBuffer) => {
const audio = new Audio(URL.createObjectURL(audioBuffer));
audio.play();
};
-
(5) UI 交互与状态管理
-
功能:展示对话历史、控制通话状态。
-
实现方式:
- 使用 Vue/React 管理状态(如通话中、已结束)。
- 渲染对话消息列表。
// React 示例 function App() { const [messages, setMessages] = useState([]); const [isCalling, setIsCalling] = useState(false); return ( <div> <div>{messages.map(msg => <Message key={msg.id} text={msg.text} />)}</div> <button onClick={startCall}>开始通话</button> <button onClick={endCall}>结束通话</button> </div> ); }
3. 低延迟优化
- WebRTC 数据通道:通过 RTCDataChannel 直接传输文本,减少服务器中转延迟。
- 音频编码优化:使用低延迟编码格式(如 Opus)。
- 分片处理:将音频流分片发送,避免阻塞。
4. 完整流程总结
- 用户点击"开始通话",触发音视频采集和 WebRTC 连接。
- 用户语音通过 ASR 转换为文本,发送给大模型。
- 大模型生成回复文本,通过 TTS 转换为语音。
- 语音通过 WebRTC 传输到对方,或直接播放给本地用户。
- UI 实时更新对话历史。
5. 参考与扩展
- 火山引擎文档:查阅火山引擎实时对话 AI 文档获取 API 细节。
- WebRTC 指南:参考 WebRTC 官方示例 深入理解音视频传输。
- 性能调优:结合 Chrome DevTools 分析网络延迟和音频处理性能。
6. 应用优势
智能打断
支持全双工通信及音频帧级别的人声检测(VAD),随时插话打断,交流更自然。
端上降噪
通过 RTC SDK 实现对复杂环境的音频降噪能力,有效降低背景噪音、背景音乐的干扰,提高用户语音打断的准确性。
超低时延
基于全链路流式处理,RTC+ASR+LLM+TTS 整体链路时延缩短至 1 秒。
抗弱网
通过智能接入、RTC 云端协同优化,在复杂和弱网环境下确保低延时和传输可靠性,避免因丢字引起大模型理解错误。
快速接入、易集成
一站式集成,企业只需调用标准的 OpenAPI 接口即可配置所需的语音识别(ASR)、 语音合成(TTS)和大模型(LLM)服务,快速实现 AI 实时交互应用。
多平台支持
支持 iOS、Android、Windows、Linux、macOS、Web、Flutter、Unity、Electron 和微信小程序多端,满足不同场景的应用需求。
以上内容纯个人理解,如写的不对,请原谅。