文章目录
- 摘要
- Method
-
- 动机(问题1):
- 怎么解决:
- 解决方法的进一步解释和证明(3.3节):
-
- 1、clean loss的必要性
- 2、clean 模块作用于单张image而不是循环结构
- 3、动态调整的必要性(Dynamic Refinement)
- 动机 (问题2)
- 怎么解决:
-
- 1、速度性能的权衡(Training Speed vs. Performance)
- 2、bs和sl的权衡(Batch Size vs. Sequence Length)
- 实验设置
-
- 数据
- 训练设置
- 模型结构
-
- 生成器
- 鉴别器
- 总结贡献
摘要
现实世界视频超分辨率 (VSR) 中退化的多样性和复杂性在推理和训练中存在重大挑战。
首先,虽然长期传播可以在轻度退化的情况下提高性能,但严重的野外退化可以通过传播夸大,损害输出质量。为了平衡细节合成与伪影抑制,我们发现图像预清理阶段是不可或缺的,它可以减少在传播之前的噪声和伪影。配备经过精心设计的清理模块,我们的RealBasicVSR在质量和效率上均优于现有方法(见图1)。
其次,实际应用中的超分辨率(VSR)模型通常使用多样化的退化进行训练,以提高其泛化能力,这需要增加批量大小以产生稳定的梯度。额外的计算负担不可避免的会产生很多问题,包括1) 速度-性能权衡(speed-performance tradeoff)和 2) 批处理/长度权衡( batch-length tradeoff.) 为了减轻第一个权衡,我们提出了一种随机降级方案,该方案在不牺牲性能的情况下,可以减少多达40%的训练时间。我们接着分析了不同的训练设置,并建议在训练过程中采用更长的序列而不是更大的批次,这样可以更有效地利用时间信息,从而在推断期间实现更稳定的性能。
为了促进公平比较,我们提出了新的VideoLQ数据集,该数据集包含大量真实世界中的低质量视频序列,具有丰富的纹理和图案。我们的数据集可以作为基准来测试。
代码、模型和数据集将会在 https://github.com/ckkelvinchan/RealBasicVSR 上公开发布。
更多RealWolrd VSR整理在https://github.com/qianx77/Video_Super_Resolution_Ref
Method
动机(问题1):
发现了basicvsr直接用于realworld dataset存在一定问题,具体为噪声累加,帧数越多,降质累加越严重。
这个时候其实就有保真和细节balance的想法了,作者原文描述是a tradeoff between enhancing details and suppressing artifacts

怎么解决:
在每一帧之前设置clean模块,提前清理掉一部分的降质信息,这样会降低这种累加误差的影响
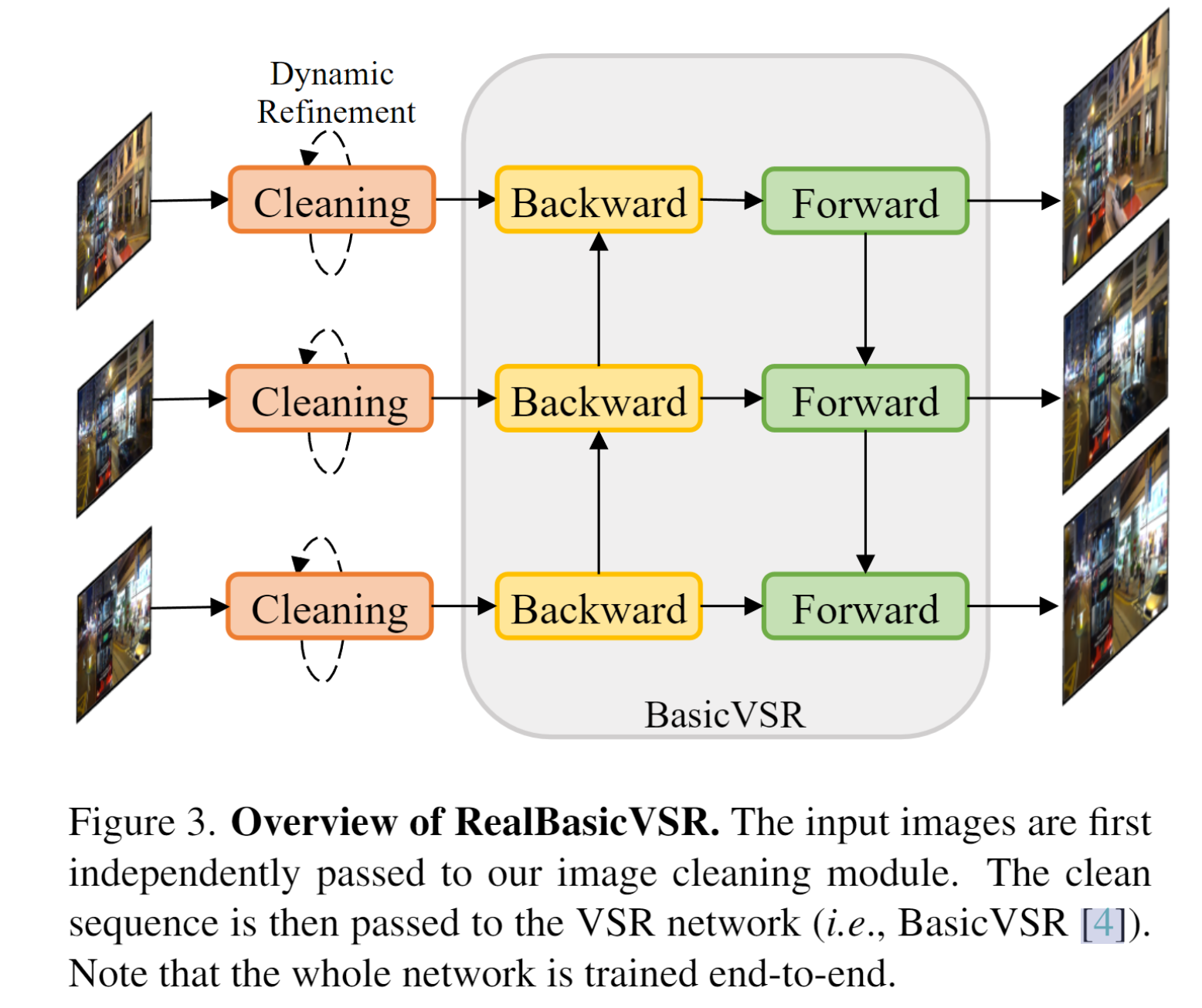
用来约束的损失函数是两个,一个是针对这个模块的clean loss(小分辨率) 一个是放在最后的output loss (原始分辨率),都是Charbonnier loss (可以理解为平滑的L1损失)
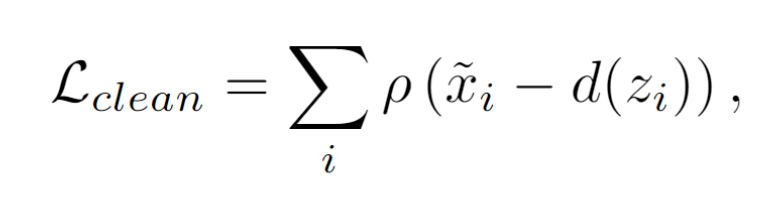
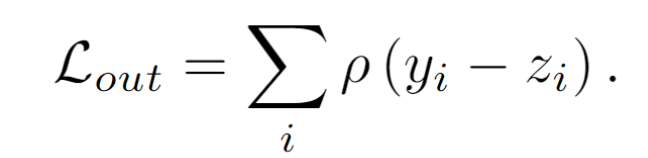
由于单次clean可能不能满足清除降质的目的,因此作者提出动态调整的策略(Dynamic Refinement),具体为如果均值差异大于阈值就持续clean,然后还根据经验设置了这个阈值:

解决方法的进一步解释和证明(3.3节):
然后作者在第3.3节又进一步分析了pre-cleanin模块的一些细节设置。
1、clean loss的必要性
如果没有这个辅助loss,整个网络变成个单级网络(single-stage network),网络会放大噪声和伪影
2、clean 模块作用于单张image而不是循环结构
作者想证明自己的观点,时序会放大噪声和伪影,并通过实验证明了

3、动态调整的必要性(Dynamic Refinement)
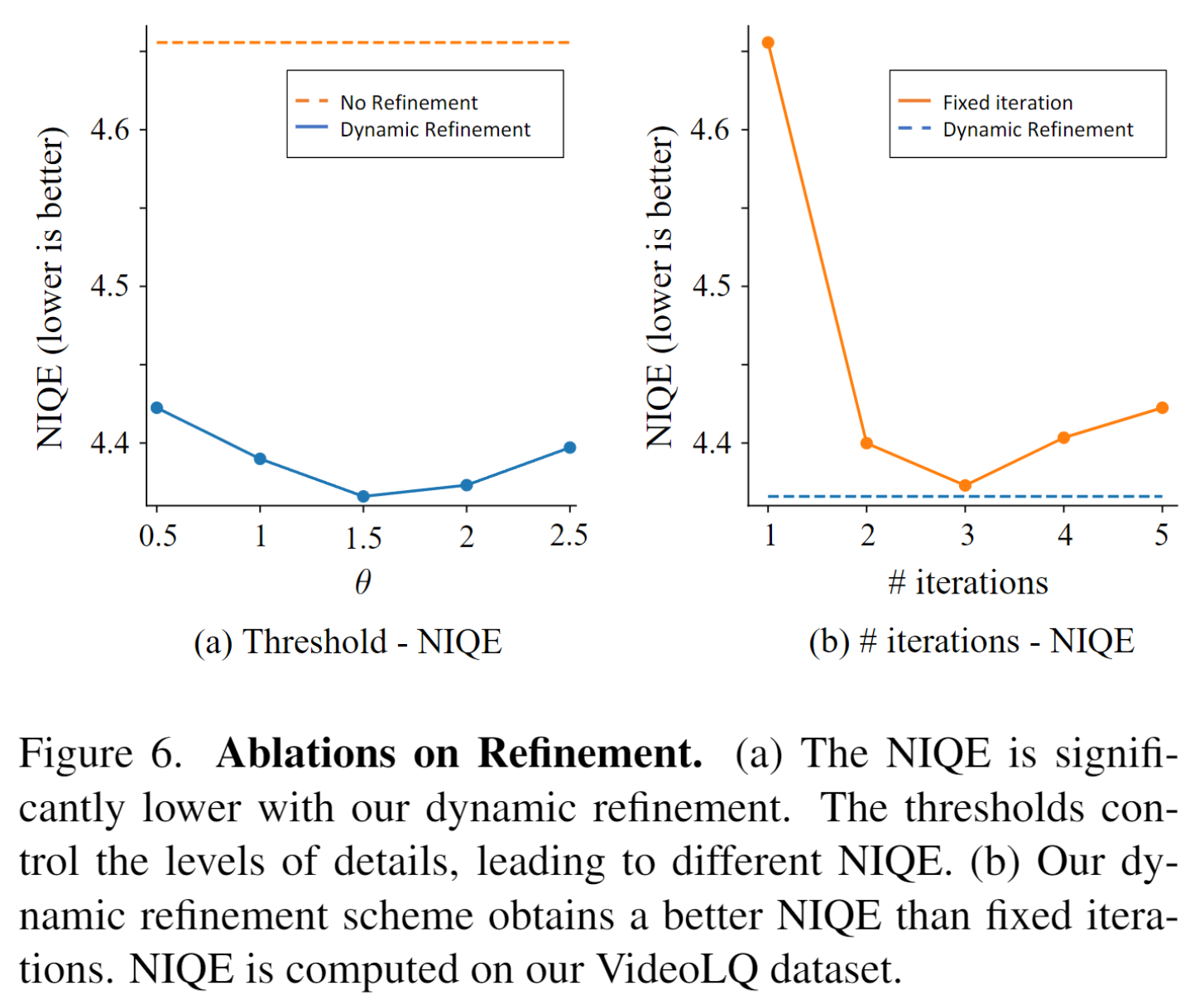
(1)、作者通过实验证明不同的clean次数得到的结果是不一样的,单次可能存留噪声,多次又太平滑,需要折中,有一定的策略还选择clean次数。
(2)、作者通过实验分析了选择自己设计的基于图像的Dynamic Refinement是比固定clean次数要好的,通过NIQE指标来证明这一点。

动机 (问题2)
real-world VSR相较于VSR需要应对更多挑战,更多样的退化,因此为了稳定梯度,需要更多的batch size稳定训练,但是这会造成更大的计算预算(computational budgets),资源有限的情况下,需要想办法解决这个问题,做出一定的平衡。
问题细化1:每次CPU需要加载BL张图像,增加batch size会增加非常大的I/O口压力,但是降低bs又会性能下降
问题细化2:计算资源固定(BL),什么样的BL比例才是最合适的?
怎么解决:
作者通过实验提出两个折中方案
1、速度性能的权衡(Training Speed vs. Performance)
作者提出了stochastic degradation scheme(随机退化方案)来解决训练时候巨大的io口压力
具体做法:
1、假设输入的帧数为L,这个新的方法仅输入L/2帧,然后序列反转扩充为L帧,这样CPU的i/o压力就少了一半了,
2、但是会引发新问题,对称的帧噪声一样,模型鲁棒性不行,因此增加一个ri随机参数,增加退化的随机性。
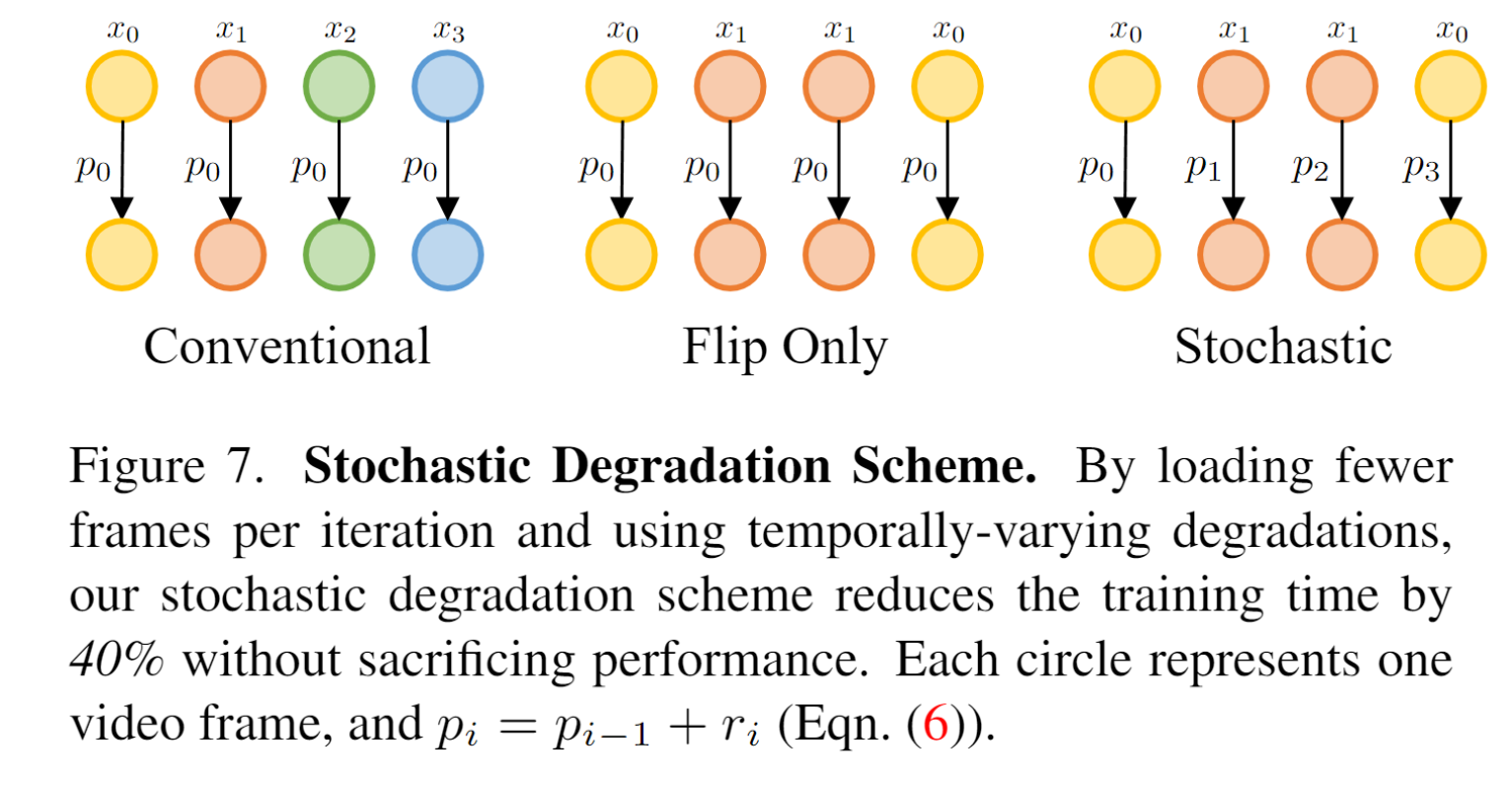
通过上面两个操作,在提升训练速度(减少40%)的前提下性能表现没有怎么下降。

2、bs和sl的权衡(Batch Size vs. Sequence Length)
通过实验证明什么样子B、L设置是比较合理的。
1、实验1,固定BL总数=480,比较不同的L,发现Sequence Length更重要
2、实验2,固定B=16,比较不同的L,发现还是Sequence Length更重要

实验设置
数据
GT使用REDS数据集,LQ 尺寸裁剪为64*64 ,使用Real-ESRGAN退化模型+video compression(编解码噪声)
训练设置
第一步训练output loss and image cleaning loss训练300K
第二步增加perceptual loss and adversarial loss 训练150k
模型结构
生成器
同basicvsr
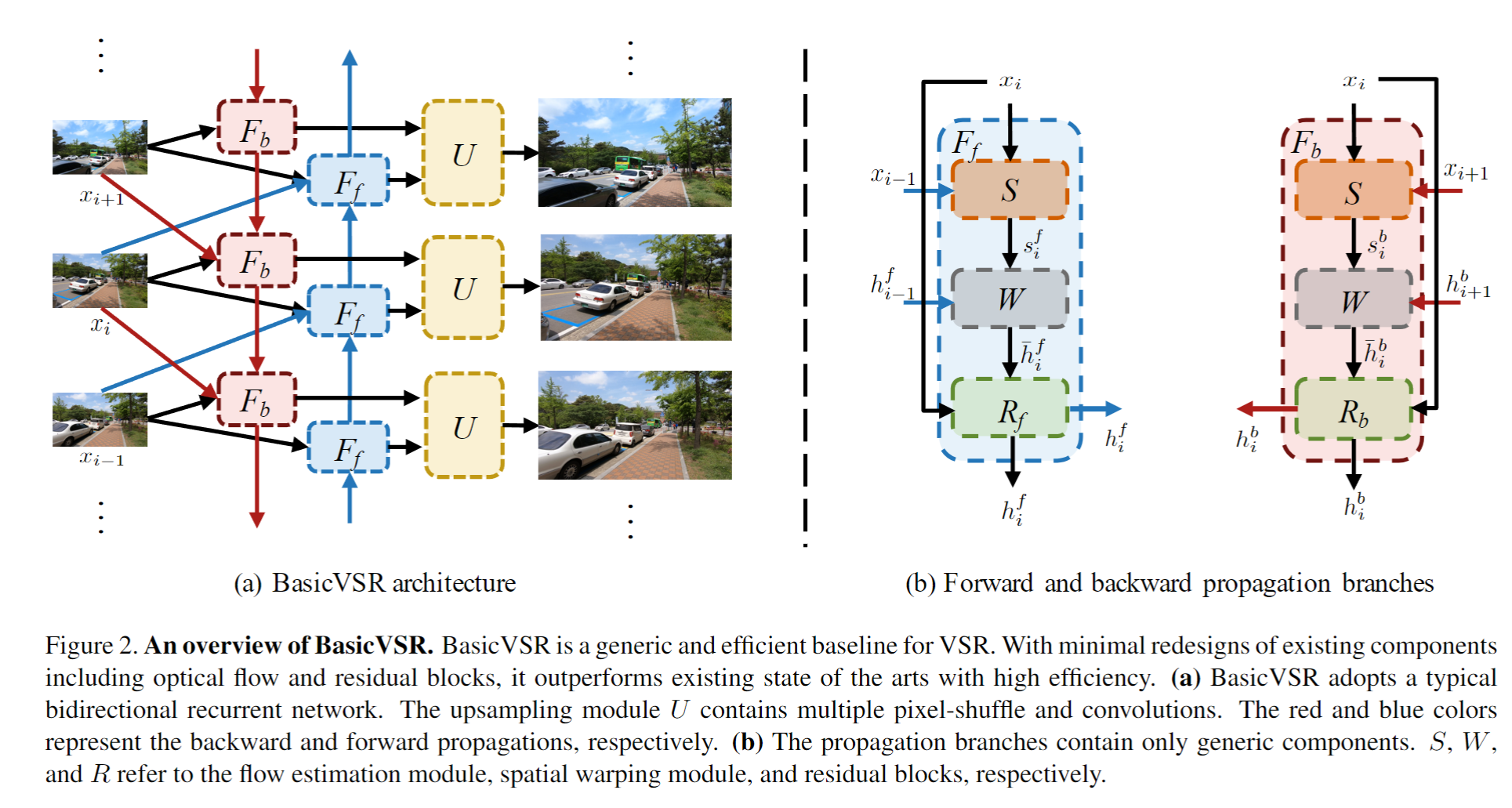
鉴别器
同Real-ESRGAN,谱归一化的UNet

总结贡献
1、clean结构
2、提出Stochastic Degradation Scheme快速训练方案
3、探索Batch Size vs. Sequence Length的最佳方案
4、VideoLQ数据集