误差损失函数比较
L1 损失函数
L1 损失函数又称为绝对误差损失,其形式为 loss(x) = |x|,即预测值与真实值之间差值的绝对值。该函数对异常值具有鲁棒性,梯度恒定不易爆炸,但由于不可导点和不连续导数,可能导致优化过程中收敛速度变慢。
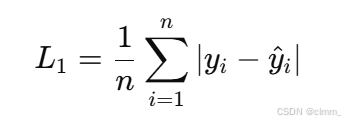
L2 损失函数
L2 损失函数也被称为均方误差损失,其形式为 loss(x) = x²。L2 损失对小误差敏感,能有效惩罚较大的偏差,是神经网络中常用的回归损失函数。然而,L2 损失对异常值非常敏感,可能使得模型偏向这些异常样本。
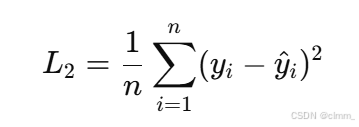
Huber 损失函数
Huber 损失结合了 L1 和 L2 的优点。其形式为:
- 当
|x| ≤ δ时,loss(x) = 0.5 * x²; - 当
|x| > δ时,loss(x) = δ * (|x| - 0.5 * δ)。
Huber 损失在误差小的情况下与 L2 相同,对结果平滑;在误差大的情况下表现为 L1,提升了对异常值的鲁棒性。
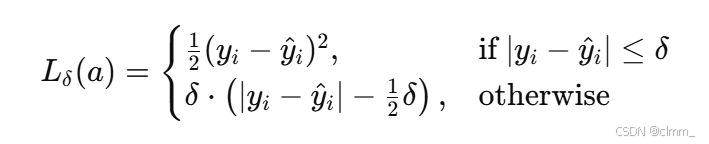
可视化对比
下图展示了 L1 损失、L2 损失以及 Huber 损失三者在误差不同取值下的对比情况:
L1 损失(绝对误差):对异常值鲁棒,梯度恒定,可能导致模型收敛较慢。
L2 损失(平方误差):对小误差敏感,有助于平滑优化,但容易受异常值影响。
Huber 损失:结合了 L1 和 L2 的优点,小误差时像 L2,大误差时像 L1,更平稳且对异常值鲁棒。
