有五种通用技术用于限制数据的扫描量,正如图3 - 4所示。第一种技术是扫描那些被打上时戳的数据。当一个应用对记录的最近一次变化或更改打上时戳时,数据仓库扫描就能够很有效地进行,因为日期不相符的数据就接触不到了。然而,目前的数据被打上时戳的很少。
数据仓库抽取中限制数据扫描量的第二种技术是扫描增量文件。增量文件由应用程序生成,仅仅记录应用中所发生的改变。有了增量文件,扫描的过程就会变得高效,因为不在候选扫描集中的数据永远不会涉及到。但是,许多应用程序并没有创建增量文件。
第三种技术是扫描审计文件或日志文件。审计文件或日志文件记录的内容,本质上同增量文件一样。不过,这里还是有一些重要的区别。由于恢复过程需要日志文件,所以各种操作都要保护日志文件。把日志文件用于其他目的,对计算机的操作也无大碍。利用日志文件的另一个困难是它内部格式是针对系统的用途而构造的,而不是针对应用程序的。这就需要一种技术手段作为日志文件内容的接口。日志文件的另一个缺点是其中所包含的内容超出了据仓库开发人员所需要的。审计文件有许多与日志文件相同的缺点。
当数据仓库抽取数据时,控制扫描数据量的第四种技术是修改应用程序代码。这并不常用,因为很多应用程序的代码陈旧而且不易修改。
最后一个选择(很多情况下,是一个可怕的选择,其目的是使人们相信一定有更好的办法)是将一个"前"映象文件和一个"后"映象文件进行比较。使用这种方法,一开始抽取就对数据库进行快照( s n a p s h o t )。进行另一个抽取时,就进行另一个快照。这两个快照逐次比较,以确定哪个活动发生了。这种方法很麻烦、复杂,还需要各种各样的资源。这只不过是最后的手段。但是,集成和性能并不是仅有的两个使得简单的抽取过程无法用于构造数据仓库的主要问题。
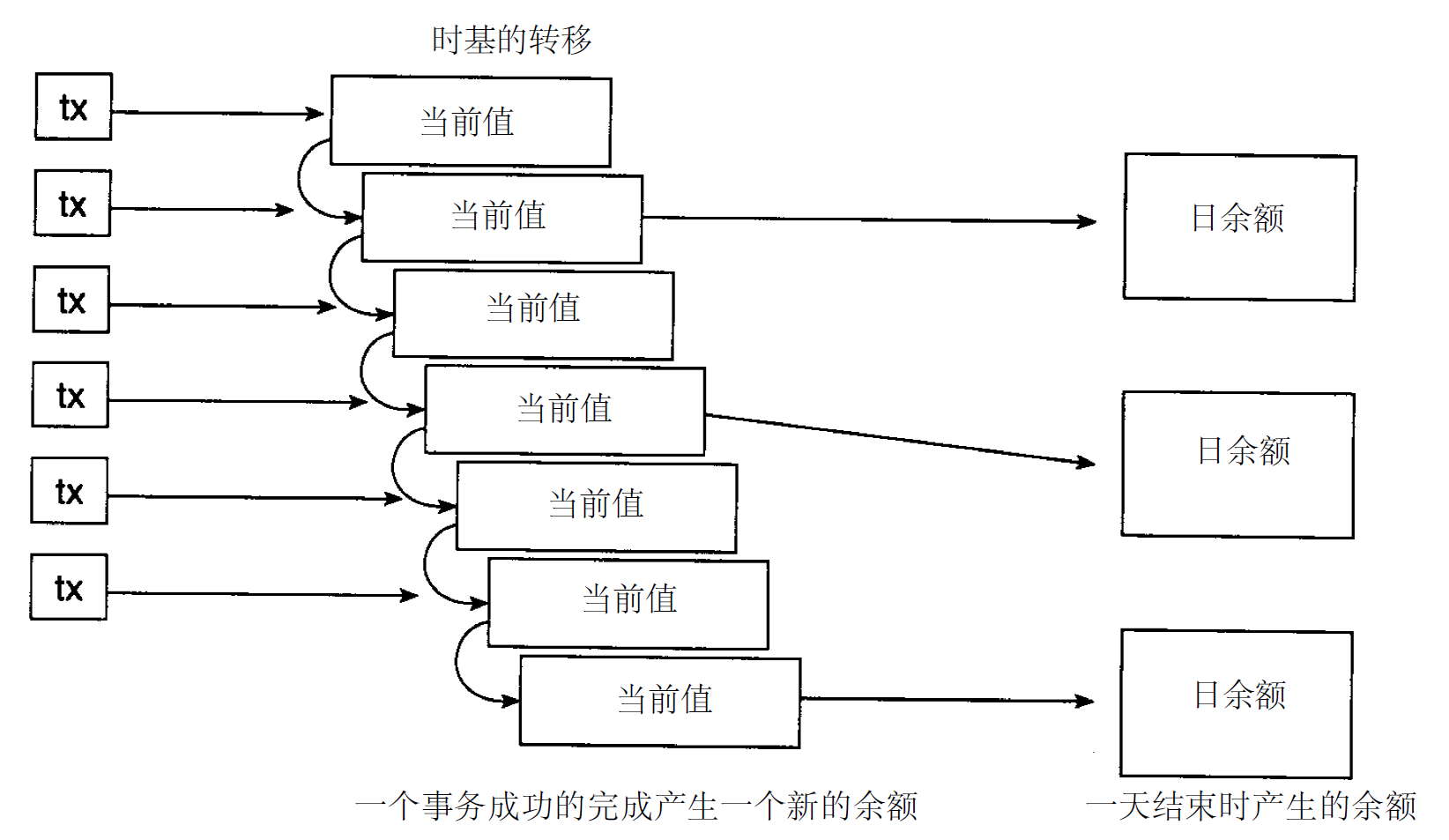
第三个主要困难是时基变化,如图3 - 5所示。现存的操作型数据通常是当值数据。当前值数据在被访问的时刻其精度是有效的,而且是可更新的。但是数据仓库中的数据是不能更新的。这些数据必须附有时间元素。当数据从操作型系统传送到数据仓库时,必需在数据中进行较大范围的改变。
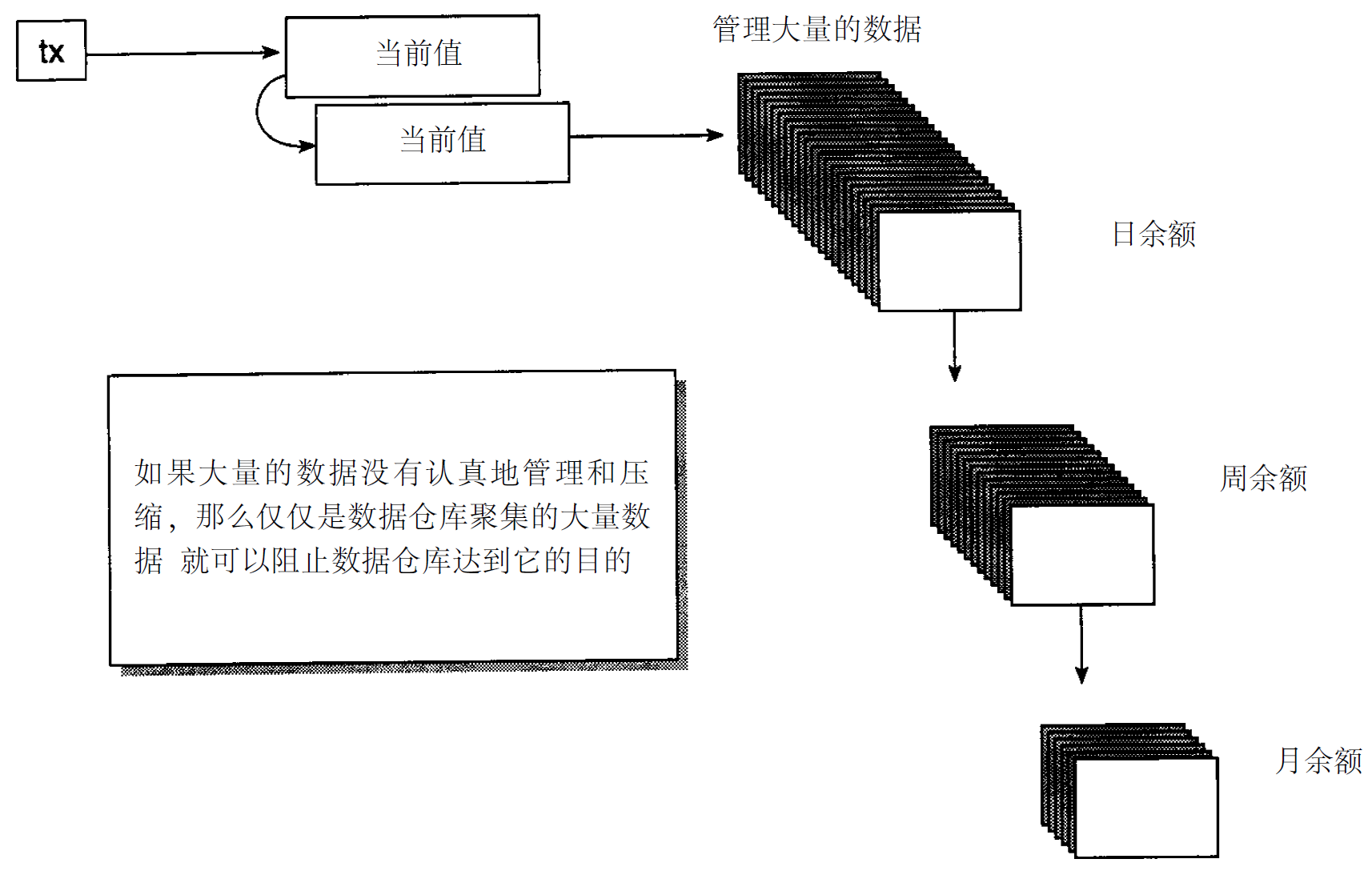
当数据从现存操作型环境传送到数据仓库时,要考虑的另一个问题是需要对数据的量进行管理。数据要浓缩,否则数据仓库的数据量很快就会失控。在数据抽取一开始就要进行数据浓缩。图3 - 6表示数据仓库数据浓缩的一个简单形式。