目录
[1.1 分类指标](#1.1 分类指标)
[1.2 回归指标](#1.2 回归指标)
[1.2.1 均方误差](#1.2.1 均方误差)
[1.2.2 均方根误差](#1.2.2 均方根误差)
[1.2.3 平均绝对误差](#1.2.3 平均绝对误差)
[1.2.4 R平方](#1.2.4 R平方)
[1.3 聚类指标](#1.3 聚类指标)
[1.3.1 内部指标](#1.3.1 内部指标)
[1.3.1.1 轮廓系数](#1.3.1.1 轮廓系数)
[1.3.1.2 戴维森堡丁指数](#1.3.1.2 戴维森堡丁指数)
[1.3.1.3 卡林斯基-哈拉巴斯指数](#1.3.1.3 卡林斯基-哈拉巴斯指数)
[1.3.2 外部指标](#1.3.2 外部指标)
[1.3.2.1 调整兰德指数](#1.3.2.1 调整兰德指数)
[1.3.2.2 标准化互信息](#1.3.2.2 标准化互信息)
[1.3.2.3 同质性、完整性和V度量](#1.3.2.3 同质性、完整性和V度量)
[2.1 超参数优化](#2.1 超参数优化)
[2.1.1 网格搜索](#2.1.1 网格搜索)
[2.1.2 随机搜索](#2.1.2 随机搜索)
[2.1.3 贝叶斯优化](#2.1.3 贝叶斯优化)
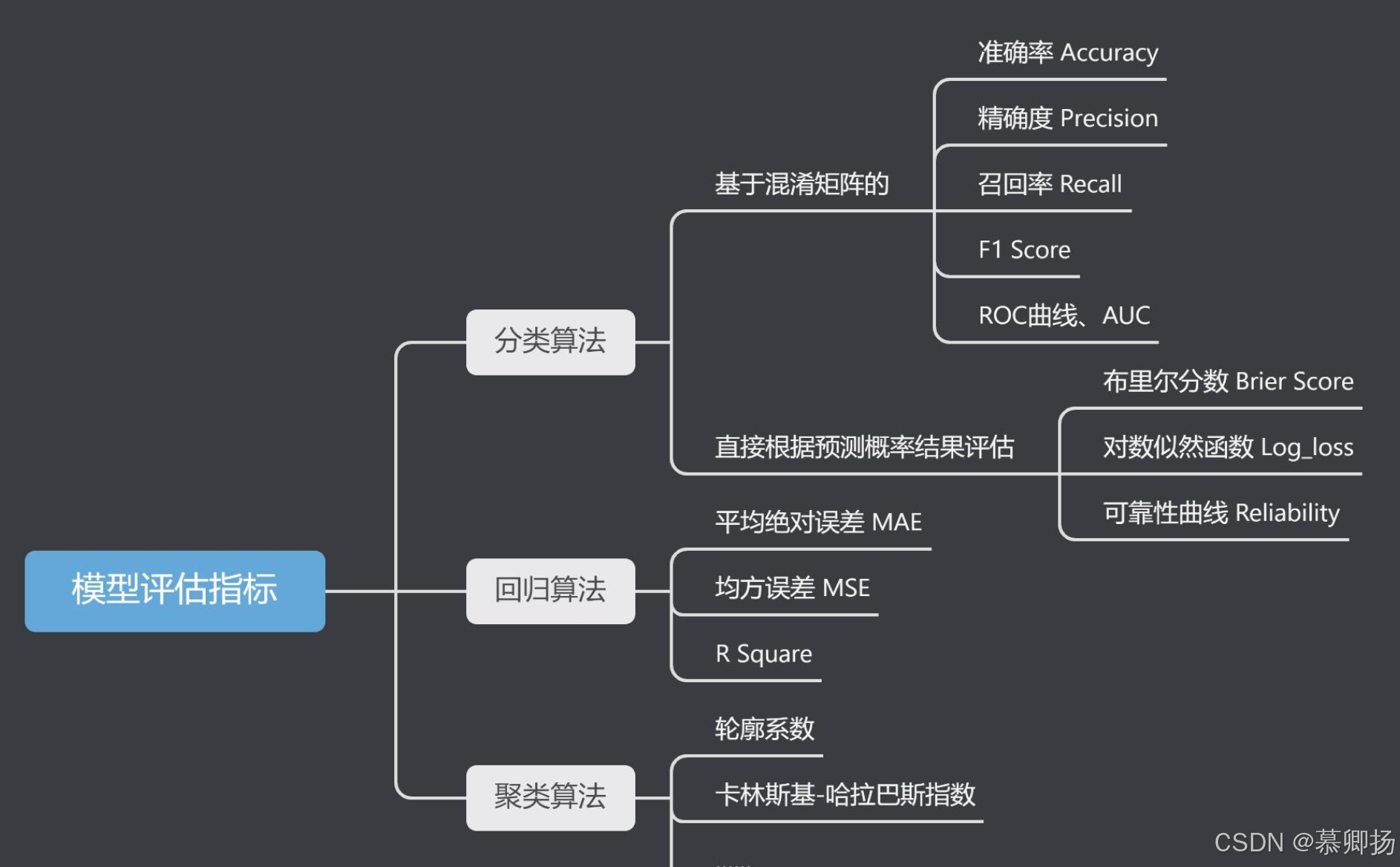
一、常用评估指标详解
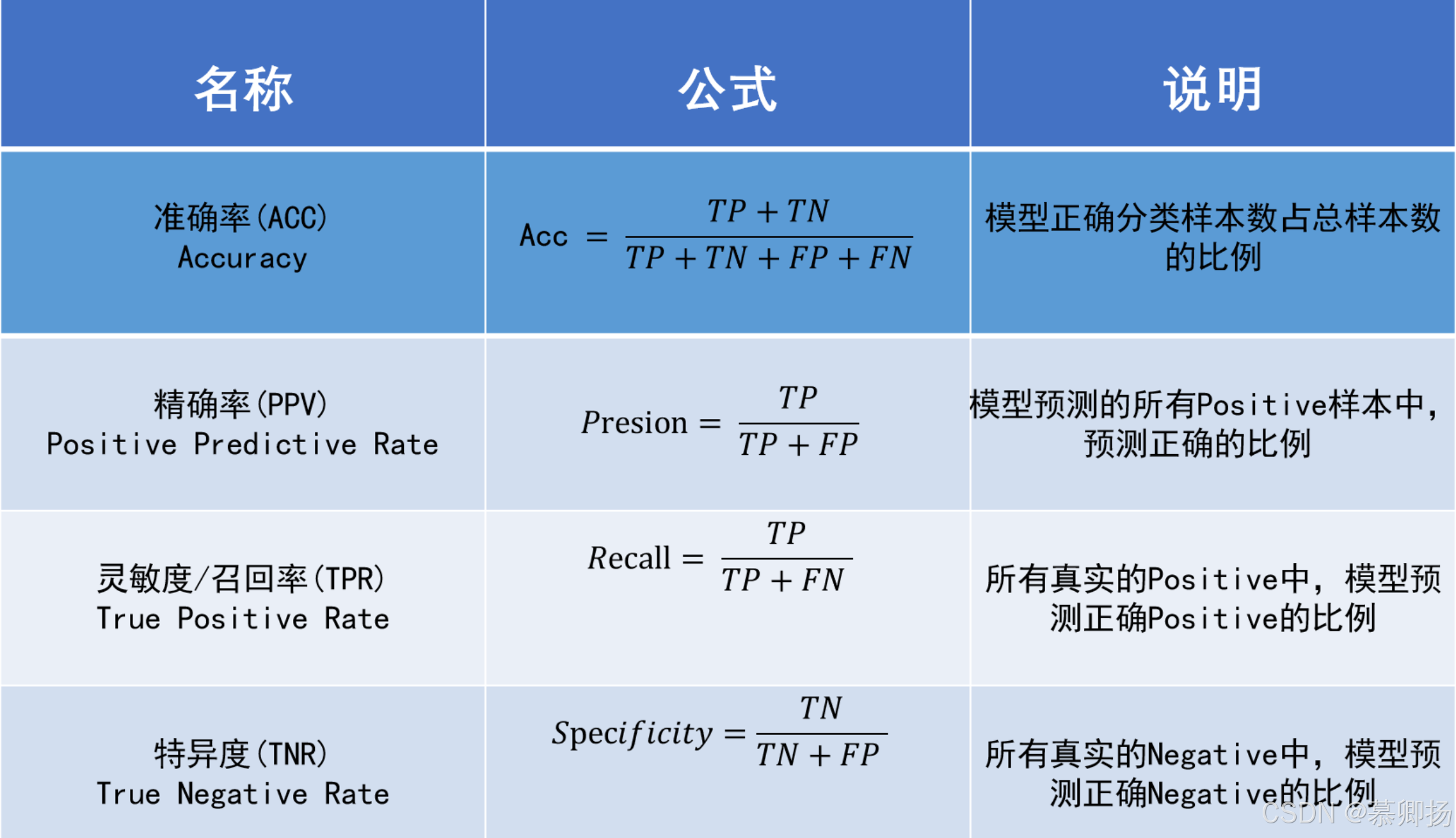
1.1 分类指标
分类指标的选择取决于具体任务需求。准确率适用于均衡数据,精确率和召回率分别关注假正例和假负例,F1分数平衡两者,ROC曲线和AUC值适用于阈值可调的场景。
在前面文章中已经进行详细介绍了,可以点击下面的链接直接跳转:
1.2 回归指标
评估回归模型性能的指标包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、R²分数等。这些指标从不同角度衡量预测值与真实值的偏差。
1.2.1 均方误差
均方误差(MSE)计算预测值与真实值之差的平方的平均值,对异常值敏感,值越小表示模型越好。
python
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mse = mean_squared_error(y_true, y_pred)
print(f"MSE: {mse}")1.2.2 均方根误差
均方根误差(RMSE)是MSE的平方根,与目标变量单位一致,更易解释。
python
import numpy as np
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
print(f"RMSE: {rmse}")1.2.3 平均绝对误差
平均绝对误差(MAE)计算预测值与真实值之差的绝对值的平均值,对异常值不敏感。
python
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mae = mean_absolute_error(y_true, y_pred)
print(f"MAE: {mae}")1.2.4 R平方
R平方(R²)分数衡量模型对目标变量的解释能力,范围在0到1之间,越接近1表示模型越好。
python
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
r2 = r2_score(y_true, y_pred)
print(f"R²: {r2}")1.3 聚类指标
评估聚类效果需依赖指标,主要分为内部指标(基于数据本身)和外部指标(基于真实标签)。
内部指标又分为轮廓系数、戴维森堡丁指数和卡林斯基-哈拉巴斯指数;外部指标又分为调整兰德指数、标准化互信息、同质性、完整性和V度量。
1.3.1 内部指标
1.3.1.1 轮廓系数
轮廓系数(Silhouette Coefficient)是一种用于评估聚类效果的指标,结合了簇内紧密性和簇间分离性,取值范围为-1, 1,值越大表示聚类效果越好。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, silhouette_samples
# 生成示例数据
X, y = make_blobs(n_samples=500, centers=4, cluster_std=0.8, random_state=42)
# 使用KMeans聚类
kmeans = KMeans(n_init=10, n_clusters=4, random_state=42)
labels = kmeans.fit_predict(X)
# 计算轮廓系数
score = silhouette_score(X, labels)
print(f"整体轮廓系数: {score:.3f}")
# 可视化轮廓分析
sample_silhouette_values = silhouette_samples(X, labels)
y_lower = 10 # 用于填充区域的起始y坐标
plt.figure(figsize=(10, 6))
for i in range(4):
ith_cluster_silhouette_values = sample_silhouette_values[labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
plt.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
alpha=0.7)
plt.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
plt.title("轮廓分析图")
plt.xlabel("轮廓系数值")
plt.ylabel("簇标签")
plt.axvline(x=score, color="red", linestyle="--") # 整体平均值
plt.show()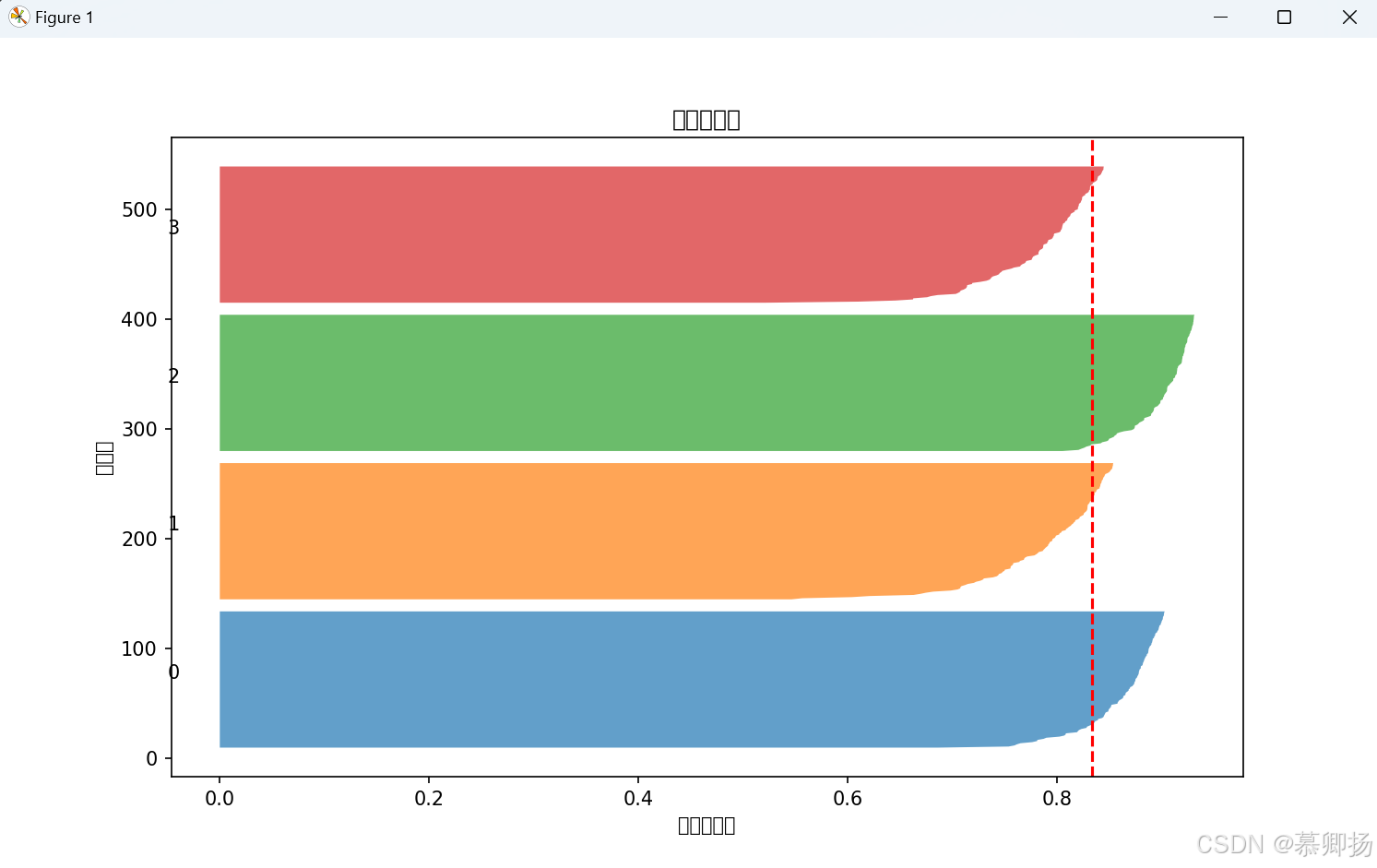
1.3.1.2 戴维森堡丁指数
戴维森堡丁指数(Davies-Bouldin Index, DBI)是一种聚类评估指标,用于衡量聚类结果的优劣。该指数越小,表示聚类效果越好。
python
import numpy as np
from sklearn.metrics import davies_bouldin_score
from sklearn.datasets import make_blobs
# 生成示例数据
X, y = make_blobs(n_samples=500, centers=3, random_state=42)
# 计算DBI(假设已通过聚类算法得到标签)
dbi_score = davies_bouldin_score(X, y)
print(f"Davies-Bouldin Index: {dbi_score:.4f}")1.3.1.3 卡林斯基-哈拉巴斯指数
卡林斯基-哈拉巴斯指数(Calinski-Harabasz Index)是一种用于评估聚类效果的指标,数值越高表示聚类效果越好。
python
import numpy as np
from sklearn.metrics import calinski_harabasz_score
# 示例数据:生成随机样本和聚类标签
X = np.random.rand(100, 2) # 100个2维数据点
labels = np.random.randint(0, 3, size=100) # 3个聚类标签
# 计算卡林斯基-哈拉巴斯指数
score = calinski_harabasz_score(X, labels)
print(f"Calinski-Harabasz Index: {score:.2f}")1.3.2 外部指标
1.3.2.1 调整兰德指数
调整兰德指数(Adjusted Rand Index, ARI)是一种用于评估聚类结果的指标,用于衡量聚类结果与真实标签之间的一致性,修正了随机因素的影响。
python
from sklearn import metrics
# 示例数据:真实标签和预测聚类结果
true_labels = [0, 0, 1, 1, 2, 2] # 真实类别标签
predicted_clusters = [0, 0, 1, 2, 2, 2] # 聚类算法输出的结果
# 计算调整兰德指数
ari_score = metrics.adjusted_rand_score(true_labels, predicted_clusters)
print(f"Adjusted Rand Index: {ari_score}")1.3.2.2 标准化互信息
标准化互信息(Normalized Mutual Information, NMI)是衡量两个聚类结果相似性的指标,常用于评估聚类或分类算法的性能。
python
from sklearn import metrics
import numpy as np
# 生成示例数据:真实标签和预测标签
true_labels = np.array([0, 0, 1, 1, 2, 2])
pred_labels = np.array([2, 2, 0, 0, 2, 2])
# 计算标准化互信息
nmi = metrics.normalized_mutual_info_score(true_labels, pred_labels)
print(f"标准化互信息 (NMI): {nmi:.4f}")1.3.2.3 同质性、完整性和V度量
同质性、完整性和V度量:
- 同质性(Homogeneity):每个聚类仅包含单个类的成员,值范围0, 1,越高越好;
- 完整性(Completeness):给定类的所有成员分配到同一个聚类,值范围0, 1,越高越好;
- V度量(V-measure):同质性和完整性的调和平均数,值范围0, 1,越高越好。
python
from sklearn.metrics import homogeneity_score, completeness_score, v_measure_score
# 示例数据:真实标签和聚类结果
true_labels = [0, 0, 1, 1, 2, 2]
predicted_labels = [0, 0, 1, 2, 2, 2]
# 计算同质性
homogeneity = homogeneity_score(true_labels, predicted_labels)
print(f"Homogeneity: {homogeneity:.4f}")
# 计算完整性
completeness = completeness_score(true_labels, predicted_labels)
print(f"Completeness: {completeness:.4f}")
# 计算V度量(V-measure)
v_measure = v_measure_score(true_labels, predicted_labels)
print(f"V-measure: {v_measure:.4f}")二、模型选择与调优
2.1 超参数优化
超参数优化是机器学习模型调优的核心环节,直接影响模型性能。超参数是训练前预设的配置参数(如学习率、批量大小、网络层数等),与模型权重不同,无法通过训练自动更新。
2.1.1 网格搜索
网格搜索(Grid Search)通过穷举给定超参数组合寻找最优解。定义每个超参数的候选值范围,遍历所有排列组合,评估模型性能。
python
from sklearn import datasets
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# 加载示例数据集(鸢尾花数据集)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 定义模型(支持向量机)
model = SVC()
# 定义超参数网格
param_grid = {
'C': [0.1, 1, 10], # 正则化参数
'kernel': ['linear', 'rbf'], # 核函数类型
'gamma': ['scale', 'auto'] # 核函数系数
}
# 创建网格搜索对象
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=5, # 5折交叉验证
scoring='accuracy', # 评估指标
verbose=1 # 输出详细日志
)
# 执行网格搜索
grid_search.fit(X, y)
# 输出最佳参数和最佳得分
print("最佳参数组合:", grid_search.best_params_)
print("最佳交叉验证得分:", grid_search.best_score_)2.1.2 随机搜索
随机搜索(Random Search)通过随机采样超参数组合进行优化,适用于高维超参数空间。
python
import numpy as np
# 定义目标函数(以二次函数为例)
def objective_function(x):
return x**2 + 2*x + 1
# 随机搜索函数
def random_search(objective_func, bounds, n_iterations):
best_x = None
best_score = float('inf')
for i in range(n_iterations):
# 在范围内随机生成参数
x = np.random.uniform(bounds[0], bounds[1])
# 计算目标函数值
score = objective_func(x)
# 更新最优解
if score < best_score:
best_score = score
best_x = x
return best_x, best_score
# 搜索范围和迭代次数
bounds = [-5, 5]
n_iterations = 100
# 执行随机搜索
best_x, best_score = random_search(objective_function, bounds, n_iterations)
print(f"最优解: x = {best_x:.4f}, 最小值: f(x) = {best_score:.4f}")2.1.3 贝叶斯优化
贝叶斯优化(Bayesian Optimization)通过概率模型(如高斯过程)建模超参数与性能的关系,逐步逼近最优解。
python
import numpy as np
from skopt import gp_minimize
from skopt.space import Real
# 定义目标函数(假设为需要最小化的函数)
def objective_function(x):
return (x[0] - 0.5)**2 + (x[1] - 0.3)**2 + 0.1 * np.sin(10 * x[0])
# 定义参数搜索空间(两个连续变量)
search_space = [
Real(0, 1, name='x0'), # 变量1范围[0, 1]
Real(0, 1, name='x1') # 变量2范围[0, 1]
]
# 执行贝叶斯优化(最小化目标函数)
result = gp_minimize(
objective_function,
search_space,
n_calls=20, # 迭代次数
random_state=42,
verbose=True
)
# 输出最优结果
print("最优参数:", result.x)
print("最优目标值:", result.fun)