Buffer Pool 实例
我们上边说过,Buffer Pool 本质是 InnoDB 向操作系统申请的一块连续的内存空间,在多线程环境下,访问 Buffer Pool 中的各种链表都需要加锁处理,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的 Buffer Pool 可能会影响请求的处理速度。所以在 Buffer Pool 特别大的时候,我们可以把它们拆分成若干个小的 Buffer Pool ,每个 Buffer Pool 都称为一个实例,它们都是独立的,独立地去申请内存空间,独立的管理各种链表,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。
我们可以在服务器启动的时候,通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,那每个Buffer Pool实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是每个 Buffer Pool 实例占用的大小等于 buffer pool 缓冲池总共的大小除以实例的个数。
innodb_buffer_pool_chunk_size
在MySQL 5.7.5之前,Buffer Pool 的大小只能在服务器启动时通过配置innodb_buffer_pool_size启动参数来调整大小,在服务器运行过程中是不允许调整该值的。不过 MySQL 在5.7.5以及之后的版本中支持了在服务器运行过程中调整 Buffer Pool 大小的功能,但是有一个问题,就是每次当我们要重新调整 Buffer Pool 大小时,都需要重新向操作系统申请一块连续的内存空间,然后将旧的 Buffer Pool 中的内容复制到这一块新空间,这是极其耗时的。所以 MySQL 决定不再一次性为某 Buffer Pool 实例向操作系统申请一大片连续的内存空间,而是以一个所谓的 chunk 为单位向操作系统申请空间。也就是说一个 Buffer Pool 实例其实是由若干个 chunk 组成的,一个 chunk 就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块:
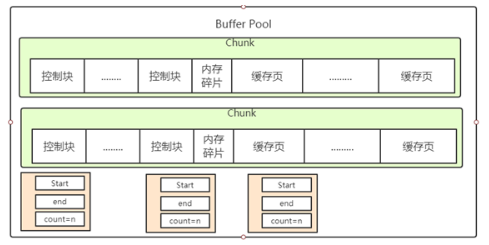
正是因为发明了这个 chunk 的概念,我们在服务器运行期间调整 Buffer Pool 的大小时就是以chunk为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的 chunk 的大小是我们在启动操作MySQL服务器时通过innodb_buffer_pool_chunk_size启动参数指定的,它的默认值是134217728,也就是128M。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指定,在服务器运行过程中是不可以修改的。
mysql
show variables like 'innodb_buffer_pool_chunk_size';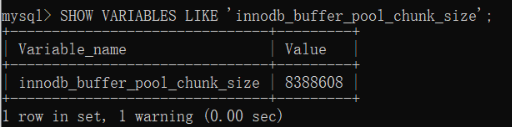
Buffer Pool 的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息。
查看Buffer Pool的状态信息
MySQL 给我们提供了 SHOW ENGINE INNODB STATUS 语句来查看关于 InnoDB 存储引擎运行过程中的一些状态信息,其中就包括 Buffer Pool 的一些信息,我们看一下(为了突出重点,我们只把输出中关于 Buffer Pool 的部分提取了出来):
mysql
show engine innodb status\G这里边的每个值都代表什么意思如下,知道即可:
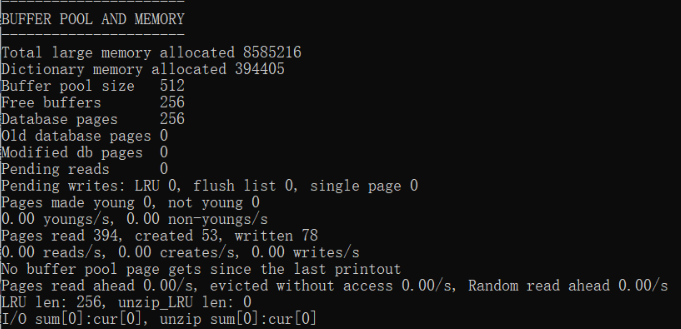
- Total large memory allocated: 代表 Buffer Pool 向操作系统申请的连续内存空间大小,包括全部控制块、缓存页、以及碎片的大小。
- Dictionary memory allocated: 为数据字典信息分配的内存空间大小,注意这个内存空间和Buffer Pool没啥关系,不包括在Total memory allocated中。
- Buffer pool size : 代表该Buffer Pool可以容纳多少缓存页,注意,单位是页!
- Free buffers: 代表当前Buffer Pool还有多少空闲缓存页,也就是free链表中还有多少个节点。
- Database pages: 代表LRU链表中的页的数量,包含young和old两个区域的节点数量。
- Old database pages: 代表LRU链表old区域的节点数量。
- Modified db pages:代表脏页数量,也就是flush链表中节点的数量。
- Pending reads:正在等待从磁盘上加载到Buffer Pool中的页面数量。
- Pending writes
- LRU:即将从LRU链表中刷新到磁盘中的页面数量。
- flush list:即将从flush链表中刷新到磁盘中的页面数量。
- single page:即将以单个页面的形式刷新到磁盘中的页面数量。
- Pages made young:代表LRU链表中曾经从old区域移动到young区域头部的节点数量
- Page made not young :在将innodb_old_blocks_time设置的值大于0时,首次访问或者后续访问某个处在old区域的节点时由于不符合时间间隔的限制而不能将其移动到young区域头部时,Page made not young的值会加1。
- **youngs/s:**代表每秒从old区域被移动到young区域头部的节点数量。
- **non-youngs/s:**代表每秒由于不满足时间限制而不能从old区域移动到young区域头部的节点数量。
- Pages read、created、written:代表读取,创建,写入了多少页。后边跟着读取、创建、写入的速率。
- **Buffer pool hit rate:**表示在过去某段时间,平均访问1000次页面,有多少次该页面已经被缓存到Buffer Pool了。
- young-making rate:表示在过去某段时间,平均访问1000次页面,有多少次访问使页面移动到young区域的头部了。
- not(young-making rate):表示在过去某段时间,平均访问1000次页面,有多少次访问没有使页面移动到young区域的头部。
- LRU len:代表LRU链表中节点的数量。
- unzip_LRU:代表unzip_LRU链表中节点的数量。
- I/O sum:最近50s读取磁盘页的总数。
- I/O cur:现在正在读取的磁盘页数量。
- I/O unzip sum:最近50s解压的页面数量。
- I/O unzip cur:正在解压的页面数量。
InnoDB的内存结构总结
InnoDB的内存结构和磁盘存储结构图总结如下:
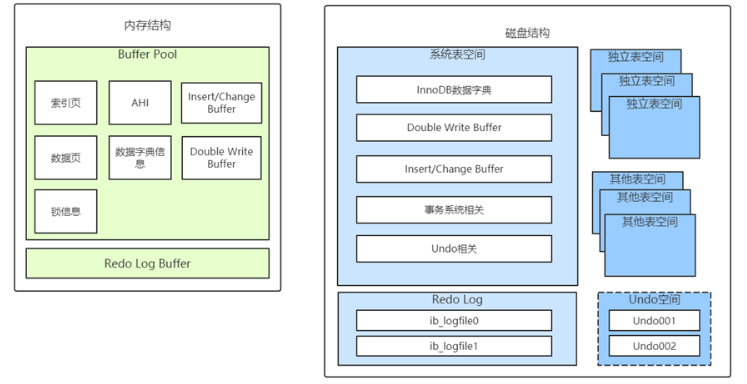
其中的 Insert/Change Buffer 主要是用于对二级索引的写入优化,Undo空间则是undo日志一般放在系统表空间,但是通过参数配置后,也可以用独立表空间存放,所以用虚线表示。