锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

pd.merge():数据库风格合并
**核心功能 **:基于列值(类似 SQL JOIN)合并数据,支持多种连接方式。 适用场景:关联不同数据表的公共字段(如用户 ID、订单号)。
语法:
pd.merge(
left, # 左侧 DataFrame
right, # 右侧 DataFrame
how='inner', # 合并方式:'inner', 'outer', 'left', 'right'
on=None, # 用于合并的列名(需在两个 DataFrame 中存在)
left_on=None, # 左侧 DataFrame 中作为键的列
right_on=None, # 右侧 DataFrame 中作为键的列
left_index=False, # 是否用左侧索引作为合并键
right_index=False, # 是否用右侧索引作为合并键
suffixes=('_x', '_y') # 列名冲突时的后缀
)参数详解
-
left/right: 左表和右表(必填)。
-
on: 连接的列名(若未指定,自动查找同名列)。
-
how : 连接方式,可选
inner(默认)、left、right、outer。 -
suffixes : 列名冲突时的后缀(默认
('_x', '_y'))。 -
validate : 验证合并关系,如
'one_to_one'、'one_to_many'。
常用场景示例
1,基本合并(基于共同列)
import pandas as pd
df1 = pd.DataFrame({
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie']
})
df2 = pd.DataFrame({
'id': [2, 3, 4],
'age': [25, 30, 28]
})
# 按 'id' 列合并(默认 inner join)
result = pd.merge(df1, df2, on='id')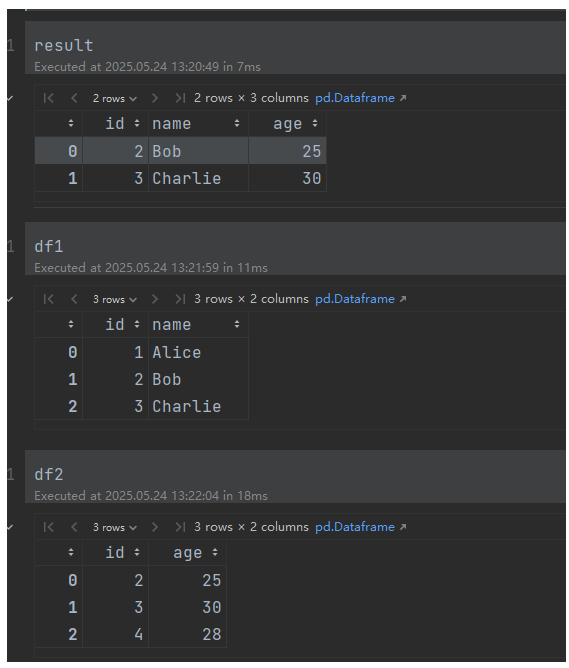
2,指定合并方式(how 参数)
左连接(保留左侧所有行):
result = pd.merge(df1, df2, on='id', how='left')输出(左侧 id=1 的 age 为 NaN):

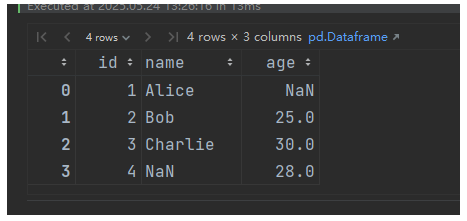
外连接(保留所有行):
result = pd.merge(df1, df2, on='id', how='outer')输出(id=1 和 id=4 的缺失值填充 NaN):
3,合并键列名不同(left_on 和 right_on)
df3 = pd.DataFrame({
'user_id': [2, 3, 4],
'score': [90, 85, 88]
})
# 合并 df1 的 'id' 和 df3 的 'user_id'
result = pd.merge(df1, df3, left_on='id', right_on='user_id')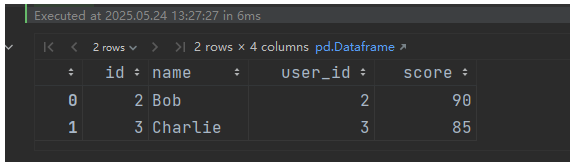
4,处理列名冲突(suffixes 参数)
当两个 DataFrame 有相同列名(非合并键)时,自动添加后缀:
df4 = pd.DataFrame({
'id': [2, 3],
'name': ['Bob', 'Charlie'],
'department': ['HR', 'Tech']
})
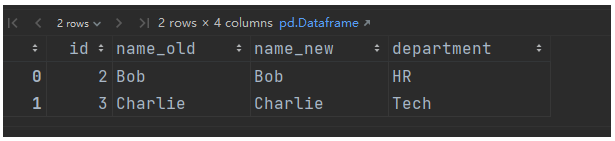
result = pd.merge(df1, df4, on='id', suffixes=('_old', '_new'))输出(name 列被区分为 name_old 和 name_new):
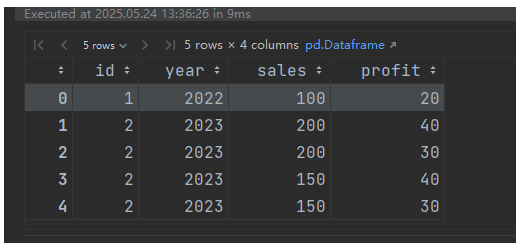
5,多键合并
指定多个列作为合并键:
df5 = pd.DataFrame({
'id': [1, 2, 2],
'year': [2022, 2023, 2023],
'sales': [100, 200, 150]
})
df6 = pd.DataFrame({
'id': [1, 2, 2],
'year': [2022, 2023, 2023],
'profit': [20, 40, 30]
})
result = pd.merge(df5, df6, on=['id', 'year'])输出(按 id 和 year 共同匹配):