 TIGER 是一种轻量级语音分离模型,通过频段分割、多尺度及全频帧建模有效提取关键声学特征。该项目由来自清华大学主导研发,通过频率带分割、多尺度以及全频率帧建模的方式,有效地提取关键声学特征,从而实现高效的语音分离。
TIGER 是一种轻量级语音分离模型,通过频段分割、多尺度及全频帧建模有效提取关键声学特征。该项目由来自清华大学主导研发,通过频率带分割、多尺度以及全频率帧建模的方式,有效地提取关键声学特征,从而实现高效的语音分离。
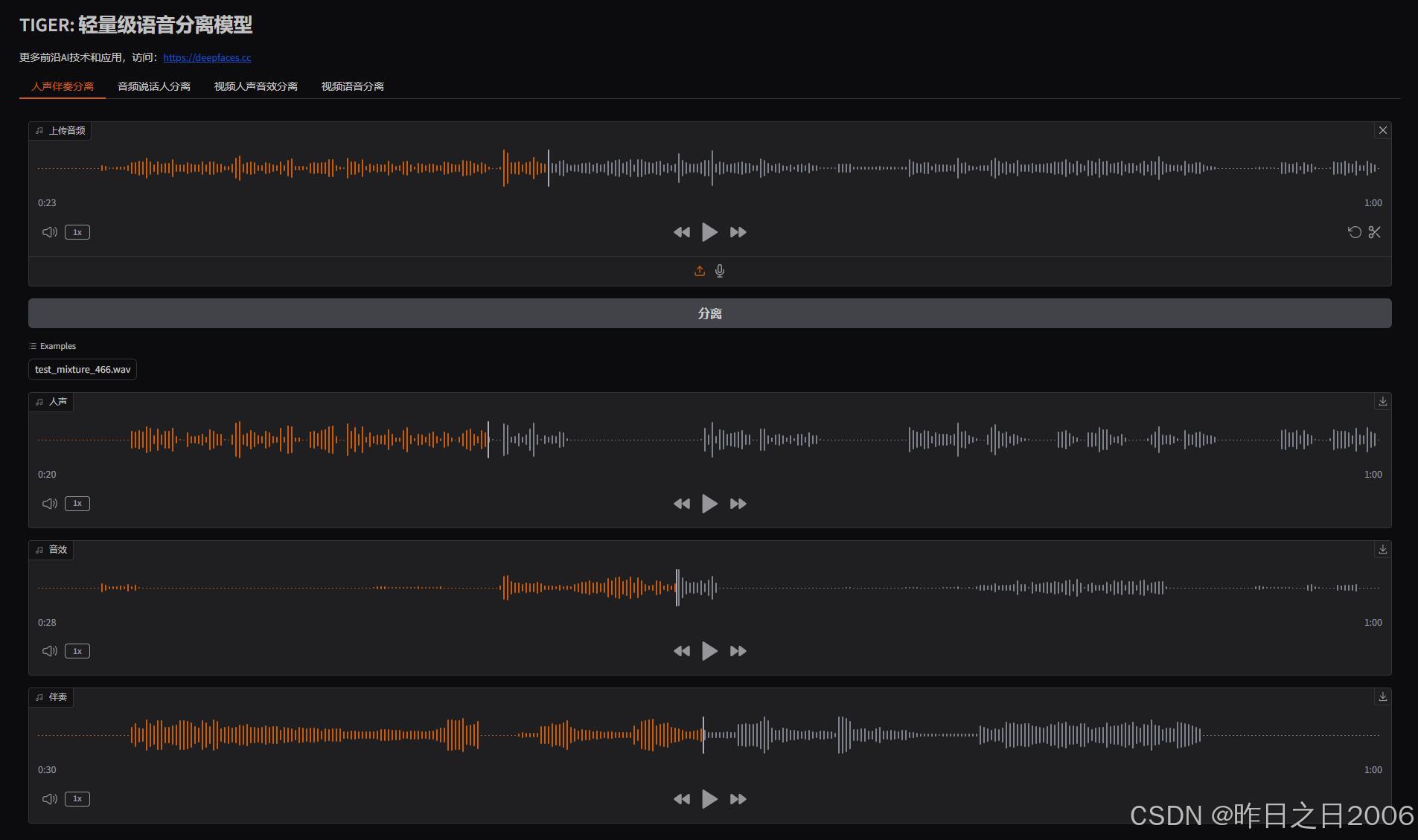
TIGER 模型大小不到20M,即使CPU也可以流畅运行,且支持人声伴奏分离(音频文件中分离人声和伴奏)、音频说话人分离(从多个说话人音频中分离出每个说话人的声音)、视频降噪以及视频语音分离等功能。
应用领域
语音通信:在多人语音通信场景中,TIGER可以有效分离出各个说话人的声音,提高通话质量和清晰度。
智能语音识别:在智能家居、车载系统等智能语音识别应用中,TIGER能够帮助系统更准确地识别用户的指令,提升用户体验。
音频处理软件:作为音频处理软件中的一个组件,TIGER可以用于音频编辑、混音等场景,实现音频信号的精细分离和处理。
远程教育和会议:在远程教育和在线会议中,TIGER能够分离出各个参与者的声音,减少背景噪音和干扰,提高沟通效率。
使用教程: (CPU可流畅运行。建议N卡,显存4G起。支持50系显卡,基于CUDA12.8)
上传需要分离的音视频素材,提交即可。
注. 适用大部分音视频素材分离,但不保证所有复杂的场景都有好的效果。支持自定义素材模型训练
下载地址:点此下载