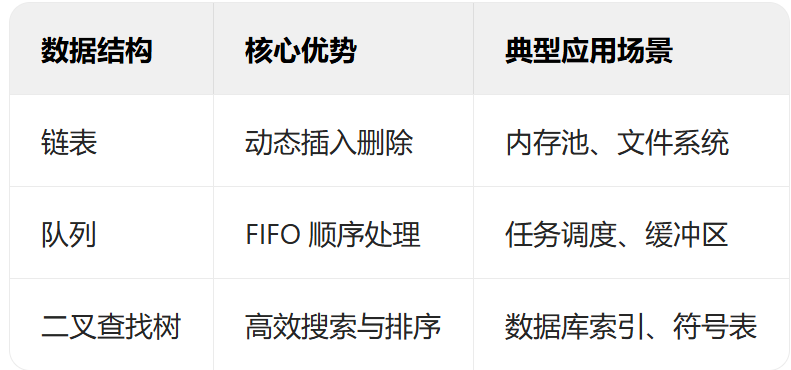
目录
[1.链表(Linked List)](#1.链表(Linked List))
[2.抽象数据类型(Abstract Data Type, ADT)](#2.抽象数据类型(Abstract Data Type, ADT))
[3.队列 ADT(Queue Abstract Data Type)](#3.队列 ADT(Queue Abstract Data Type))
[5.二叉查找树(Binary Search Tree, BST)](#5.二叉查找树(Binary Search Tree, BST))
1.链表(Linked List)
①含义
链表是一种动态数据结构,由一系列节点(Node)组成,每个节点包含数据域和指向下一个节点的指针。节点在内存中不必连续存储,通过指针连接形成逻辑上的序列。
②作用
- 动态内存分配,无需预先指定大小
- 高效的插入和删除操作(O (1))
- 适合数据量不确定或频繁变动的场景
③表达方式
struct Node {
int data; // 数据域
struct Node* next; // 指向下一个节点的指针
};④注意事项
- 内存管理:手动分配和释放内存(
malloc/free) - 指针操作:避免悬空指针和内存泄漏
- 遍历链表时需检查空指针(
NULL)
⑤例题
实现链表的基本操作:插入、删除、遍历
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
};
// 在链表头部插入节点
void insertAtHead(struct Node** head_ref, int new_data) {
struct Node* new_node = (struct Node*)malloc(sizeof(struct Node));
new_node->data = new_data;
new_node->next = (*head_ref);
(*head_ref) = new_node;
}
// 遍历链表并打印元素
void printList(struct Node* node) {
while (node != NULL) {
printf("%d ", node->data);
node = node->next;
}
}
int main() {
struct Node* head = NULL;
insertAtHead(&head, 3);
insertAtHead(&head, 2);
insertAtHead(&head, 1);
printList(head); // 输出: 1 2 3
return 0;
}2.抽象数据类型(Abstract Data Type, ADT)
①建立抽象
将数据结构的逻辑特性与其实现细节分离,定义数据类型的行为(操作)而不涉及具体实现。
②建立接口
声明一组操作(函数原型),定义外部可见的行为规范。
// 接口示例:栈ADT
void push(int item); // 入栈
int pop(); // 出栈
int isEmpty(); // 判断栈空③使用接口
通过调用接口函数操作数据,无需关心内部实现。
push(10);
int top = pop();④实现接口
具体实现接口中声明的操作。
// 栈的数组实现
#define MAX_SIZE 100
int stack[MAX_SIZE];
int top = -1;
void push(int item) {
stack[++top] = item;
}
int pop() {
return stack[top--];
}⑤注意事项
- 接口与实现分离,便于维护和修改
- 避免直接访问内部数据,确保数据封装性
3.队列 ADT(Queue Abstract Data Type)
①定义队列抽象数据类型
队列是遵循 FIFO(先进先出)原则的线性数据结构,支持入队(enqueue)和出队(dequeue)操作。
②定义接口
void enqueue(int item); // 入队
int dequeue(); // 出队
int isEmpty(); // 判断队空③实现接口数据表示
使用链表实现队列:
struct Node {
int data;
struct Node* next;
};
struct Queue {
struct Node* front;
struct Node* rear;
};
void enqueue(struct Queue* q, int item) {
struct Node* new_node = (struct Node*)malloc(sizeof(struct Node));
new_node->data = item;
new_node->next = NULL;
if (q->rear == NULL) {
q->front = q->rear = new_node;
return;
}
q->rear->next = new_node;
q->rear = new_node;
}④测试队列
验证队列操作的正确性:
struct Queue q;
q.front = q.rear = NULL;
enqueue(&q, 1);
enqueue(&q, 2);
printf("%d ", dequeue(&q)); // 输出: 1⑤注意事项
- 循环队列可避免数组实现的假溢出问题
- 链表实现需处理空队列的特殊情况
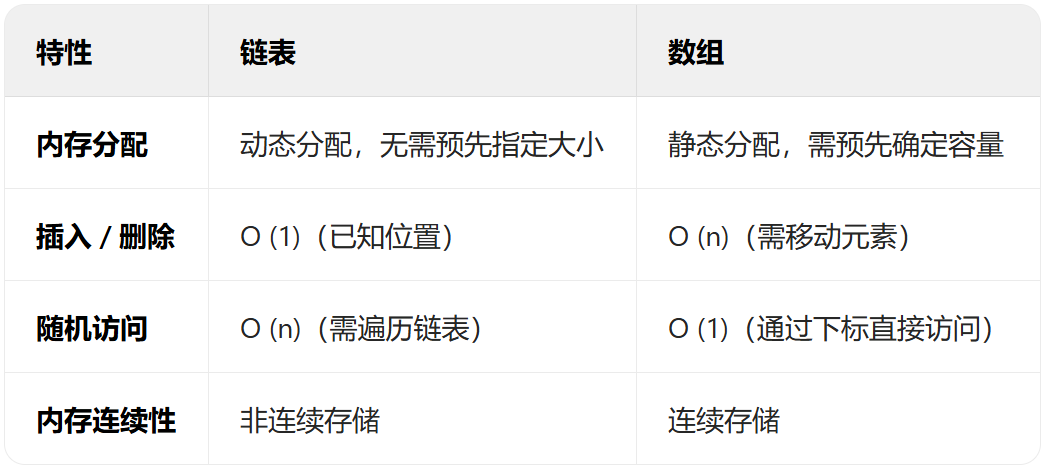
4.链表与数组的对比
**例题:**将链表逆置:
struct Node* reverseList(struct Node* head) {
struct Node* prev = NULL;
struct Node* curr = head;
struct Node* next = NULL;
while (curr != NULL) {
next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}5.二叉查找树(Binary Search Tree, BST)
(1)二叉树 ADT
每个节点最多有两个子节点(左子树和右子树)的树形结构。
(2)二叉查找树接口
struct TreeNode* insert(struct TreeNode* root, int key); // 插入节点
struct TreeNode* search(struct TreeNode* root, int key); // 查找节点
void inorderTraversal(struct TreeNode* root); // 中序遍历(3)二叉树的实现
struct TreeNode {
int key;
struct TreeNode* left;
struct TreeNode* right;
};
struct TreeNode* insert(struct TreeNode* root, int key) {
if (root == NULL) {
struct TreeNode* new_node = (struct TreeNode*)malloc(sizeof(struct TreeNode));
new_node->key = key;
new_node->left = new_node->right = NULL;
return new_node;
}
if (key < root->key)
root->left = insert(root->left, key);
else if (key > root->key)
root->right = insert(root->right, key);
return root;
}(4)使用二叉树
struct TreeNode* root = NULL;
root = insert(root, 50);
insert(root, 30);
insert(root, 70);
inorderTraversal(root); // 输出: 30 50 70(升序)(5)树的思想
利用分治策略高效解决问题(如排序、搜索),时间复杂度平均为 O (log n)。
(6)注意事项
- 保持树的平衡性可避免退化为链表(如 AVL 树、红黑树)
- 删除操作需处理三种情况:无子节点、一个子节点、两个子节点
6.总结