图像标注是构建高质量训练数据集的关键步骤,在目标检测、图像分割、姿态估计、
OCR等任务中具有决定性作用。然而,传统标注工具存在功能单一、自动化程度低、不支持复杂任务等问题,限制了其在实际应用中的效能。为此,X-AnyLabeling应运而生,结合最新研究成果与工程实践经验,打造了一个具备高度灵活性与智能化的标注平台。
1. 核心功能与技术架构
代码地址:https://github.com/CVHub520/X-AnyLabeling/tree/main
1.1 多样化标注样式支持
X-AnyLabeling 支持包括矩形框(HBB )、旋转框(OBB)、多边形、点、线段、折线段、圆形等七种标注形式,全面适配目标检测、实例分割、关键点定位等多种视觉任务。此外,软件还提供视频自动解析功能,实现对时序数据的高效标注。
| 标注样式 | 描述 | 适用场景 |
|---|---|---|
| 矩形框 | 快速框选目标对象,简单高效 | 目标检测、物体跟踪等基础任务 |
| 多边形 | 绘制不规则形状,实现精确标注 | 图像分割、显著性检测等复杂任务 |
| 旋转框 | 描述物体的方向和姿态,更加灵活 | 旋转目标检测 |
| 点 | 标记图像中的特定关键点 | 姿态估计、关键点检测等任务 |
| 线段 | 用于直线关系的标注需求 | 道路标线、简单图形边界等 |
| 折线段 | 绘制连续折线,适配弯曲线条标注 | 车道线检测等任务 |
| 圆形 | 提供便捷的圆形目标标注方式 | 车辆轮胎、瞳孔等圆形目标标注场景 |
此外,X-AnyLabeling 还提供其他支持,广泛适用于以下子任务:
- 图像级与对象级标签分类和描述: 图像分类;图像描述;图像标签
- KIE 场景的 SER 和 RE 标注功能:为结构化信息抽取任务提供高效解决方案
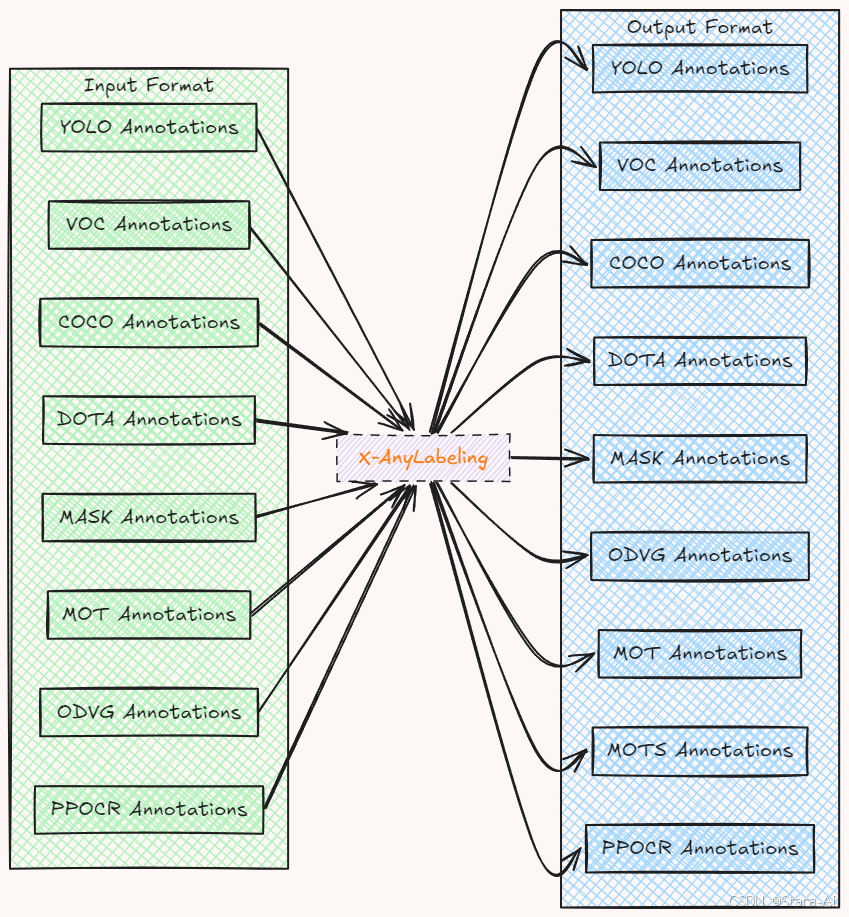
1.2 多格式数据转换与互操作性
平台内置 YOLO 、OpenMMLab 、PaddlePaddle 等主流框架的数据格式转换模块,用户可轻松导入/导出 COCO 、VOC 、YOLOv5/v8 格式等标准数据集,提升数据处理流程的兼容性与效率。
1.3 高性能跨平台推理引擎与多模态交互标注系统
引入基于 Open Vision 和 Florence 2 的交互式视觉-文本提示机制,实现了自然语言引导的目标检测与分割。该机制打破了传统闭集模型的类别限制,支持开集识别与细粒度语义理解,极大增强了人机交互体验。
后端采用 OnnxRuntime 为核心推理引擎,同时支持 PyTorch 、TensorRT 、OpenVINO 等多种加速方案,兼顾推理速度与精度。软件可在 Windows 、Linux 、macOS 系统上运行,并提供一键编译脚本,便于定制化部署。
1.4 小目标筛查功能
X-AnyLabeling 针对小目标场景提供了循环遍历子图的筛查功能,可以帮助用户在完成初始标注后,更加高效地复核和修正小目标标注。用户在标注完成后,可以通过快捷键快速调用该功能,系统会循环切换到每一个已标注目标所在的区域,并自动局部放大该目标对象所处的子图。GUI 界面也提供了统计总览和保存子图功能,帮助用户快速了解当前标注目标数量等信息和根据目标框将对应子图截取并保存下来,方便用户后续的分析和复盘,进一步提升了标注工作的可追溯性。
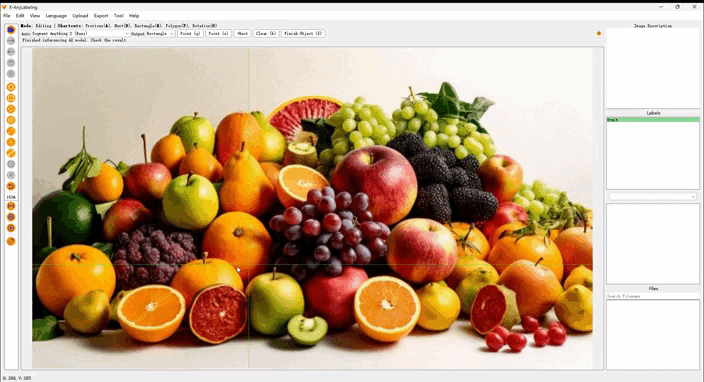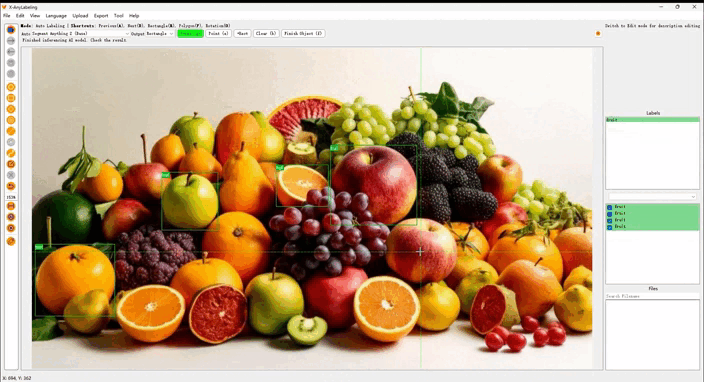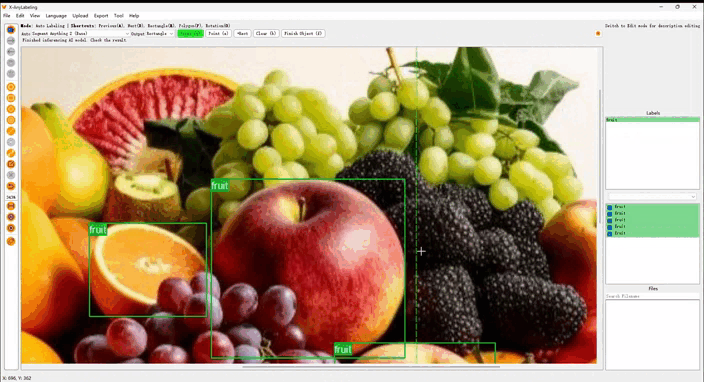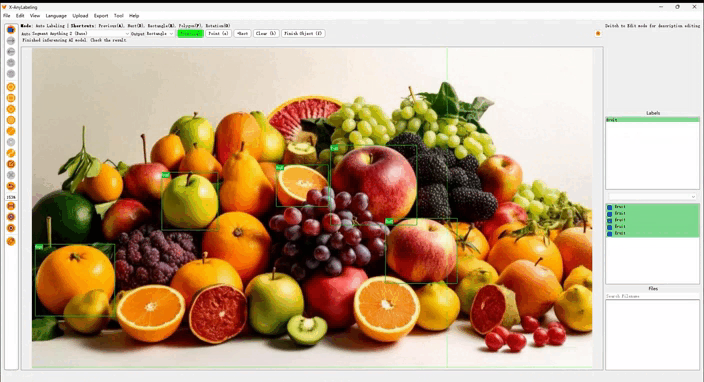
2. 先进算法与模型支持
2.1 基于文本/视觉提示或免提示的检测和分割统一模型
在 X-AnyLabeling 版本中,我们隆重推出全新算法 Open Vision ,它巧妙融合了 Visual-Text Grounding 和 Segment-Anything 的优势,实现了基于多提示融合的交互式检测与分割。 Open Vision 有效地克服了 YOLO 等主流传统闭集检测模型类别受限的缺点,也解决了 GroundingDINO 在处理复杂、模糊或具有歧义的文本提示时的局限性,为您带来前所未有的标注体验!
-
核心优势:
- 文本-视觉提示融合: 该功能将自然语言提示与视觉输入无缝结合,实现更智能、更直观的任务处理,显著提升交互性和效率。
- 通用视觉任务支持: 从目标检测到实例分割,该功能展现出卓越的多功能性和鲁棒性,可广泛应用于多种视觉任务。
-
潜在局限:
- 训练数据依赖: 该模型基于 FSC-147 数据集训练,在分布外的对象上可能表现不佳,需注意其泛化能力。
- 资源密集型推理: 为确保识别精度,采用了两阶段推理管道,导致模型推理需要较多的计算资源和时间,更适用于密集场景标注。
- 相似物体区分挑战: 当前模型在区分相似物体方面仍存在一定挑战,可能会导致个别误检情况。
📚教程:https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/detection/hbb/README.md
2.2 基于 Florence 2 算法的多模态智能标注
Florence 2 是微软研究院推出的多模态基础模型,旨在实现更强大的视觉和语言理解能力,并为各种多模态任务提供统一的解决方案。Florence 2 采用统一的架构来处理多种多模态任务,例如图像分类、图像描述、视觉问答、文本到图像生成、视觉文本推理等。这种统一的架构简化了模型训练和部署过程。
📚 教程:https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/vision_language/florence2/README.md
-
目标检测
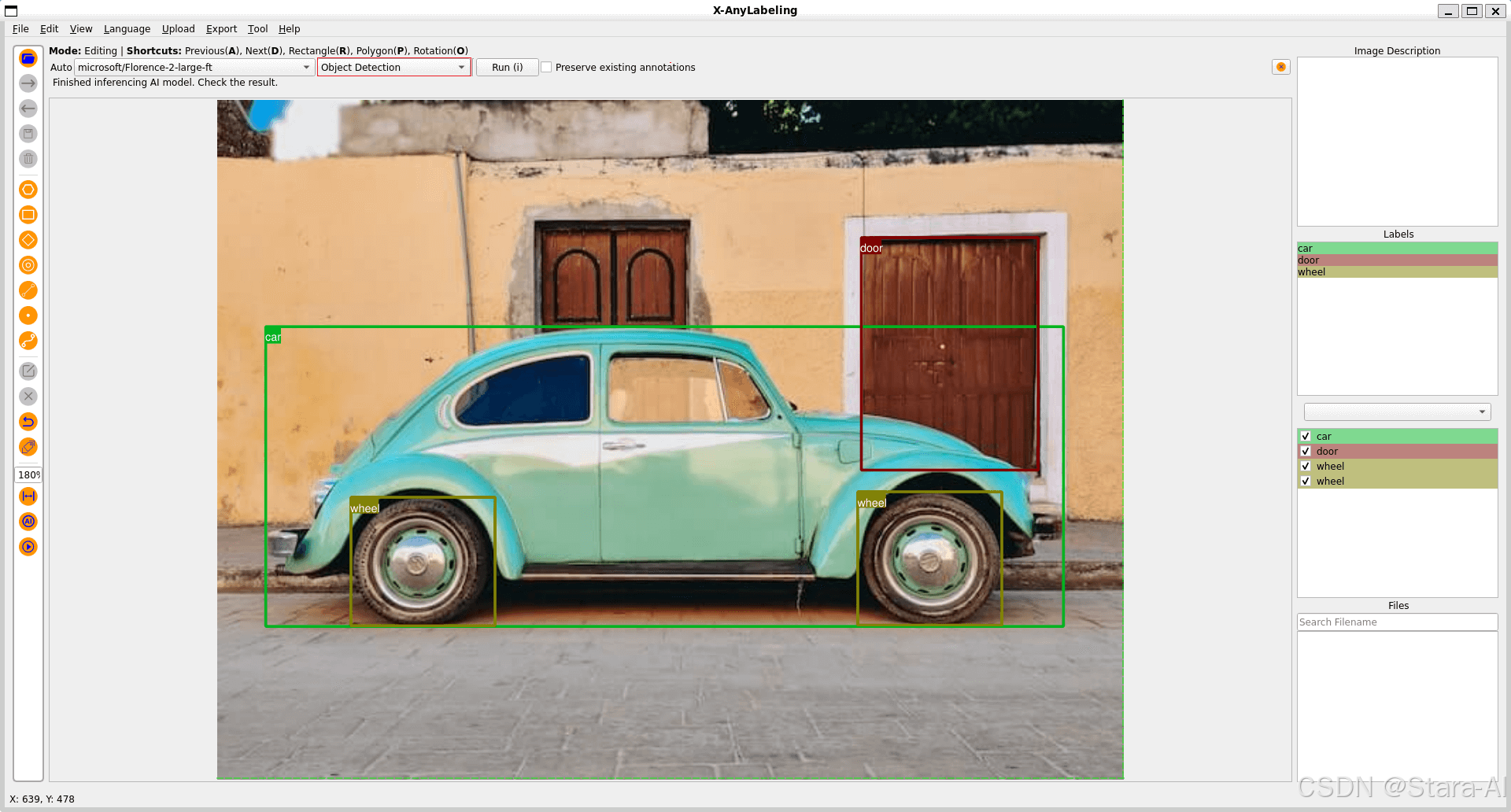
-
候选区域
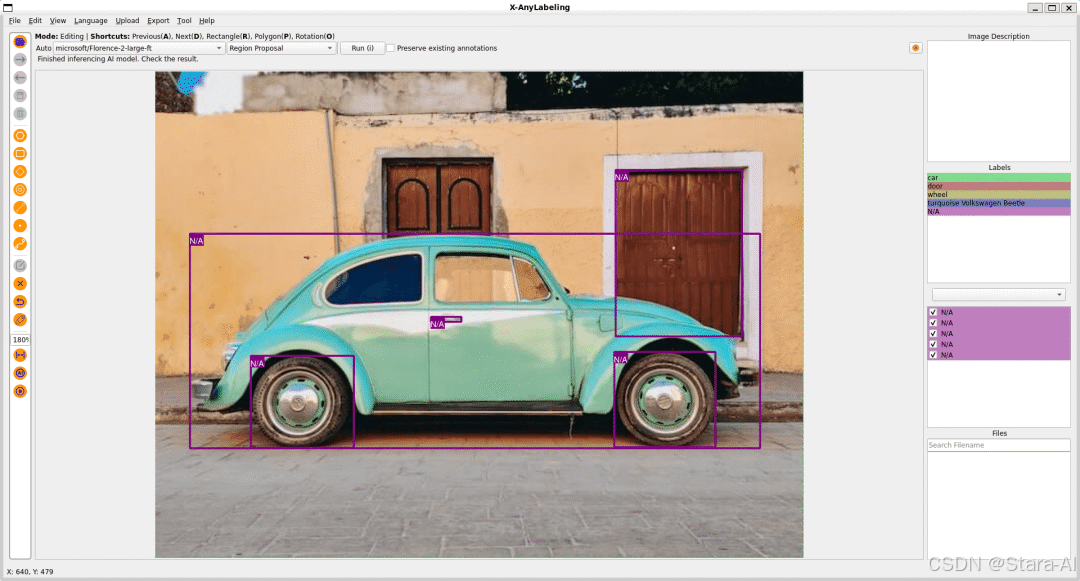
-
密集区域说明
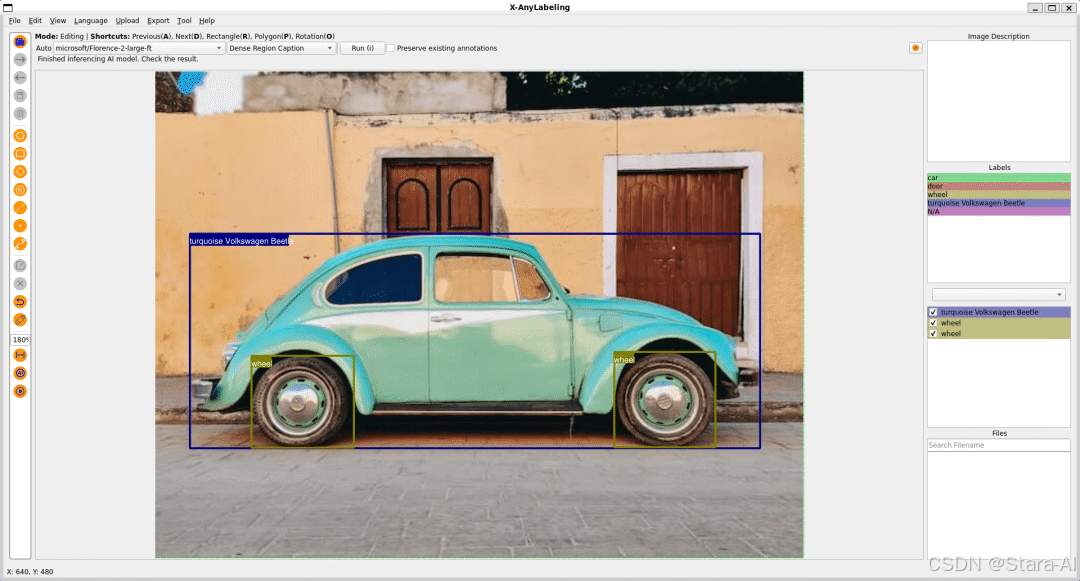
-
视觉提示
基于视觉提示的任务包含以下三个子任务:
- 区域分类(Region to category): 为指定区域分配一个类别标签。
- 区域描述(Region to description): 为指定区域生成一段描述性文本。
- 区域分割(Region to segmentation): 为指定区域生成一个分割掩码。
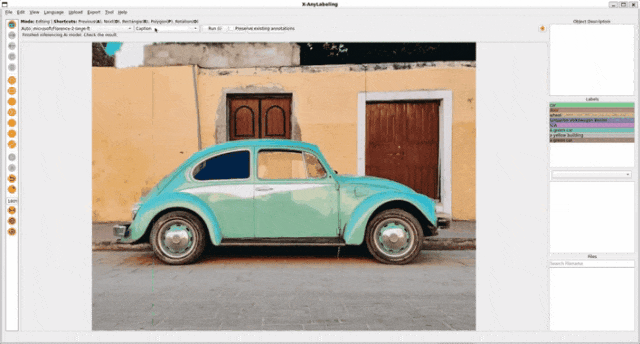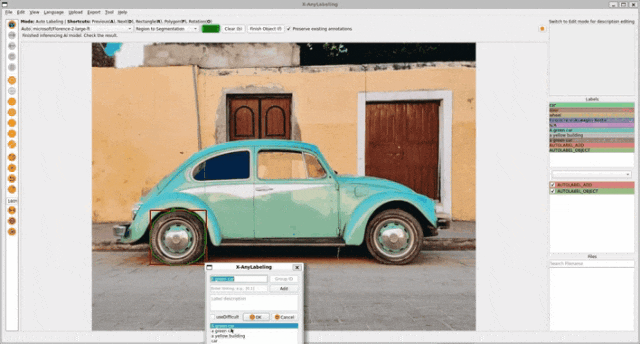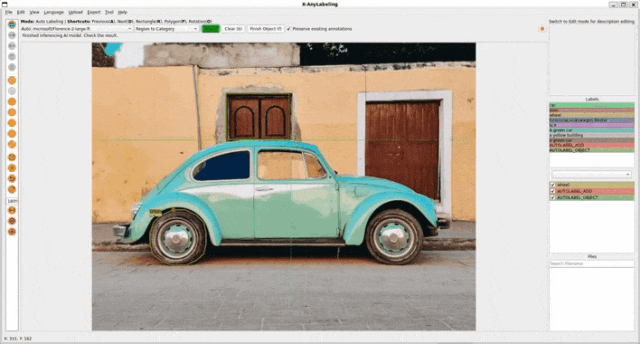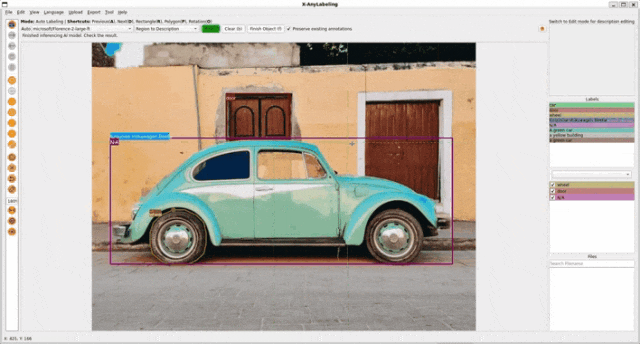
-
文本提示
基于文本提示的任务包含以下三个子任务:
- Caption to Parse Grounding
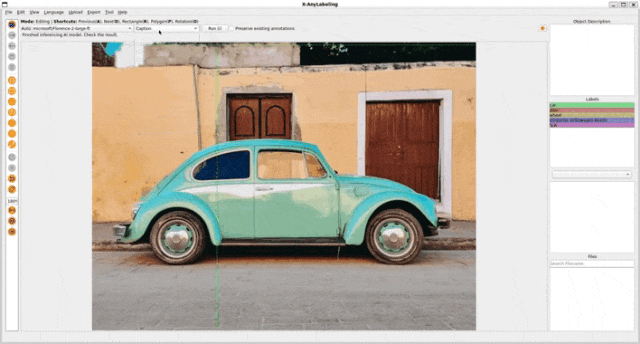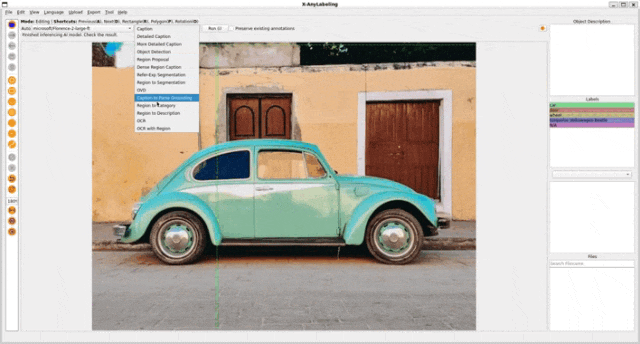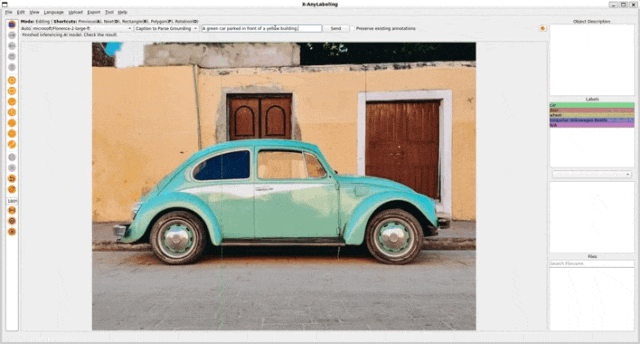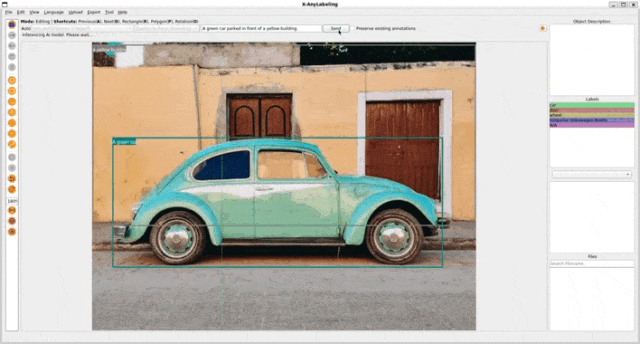
2. Referring Expression Segmentation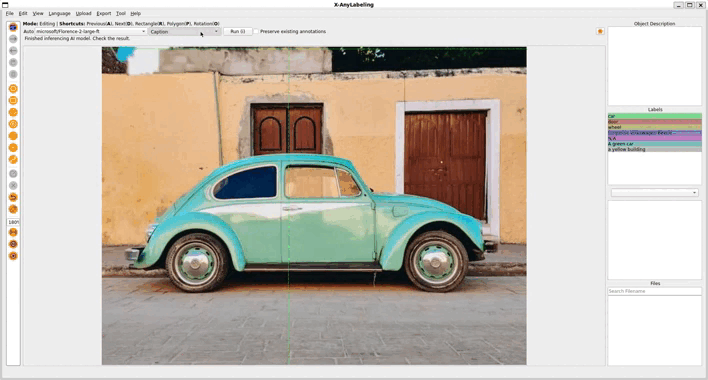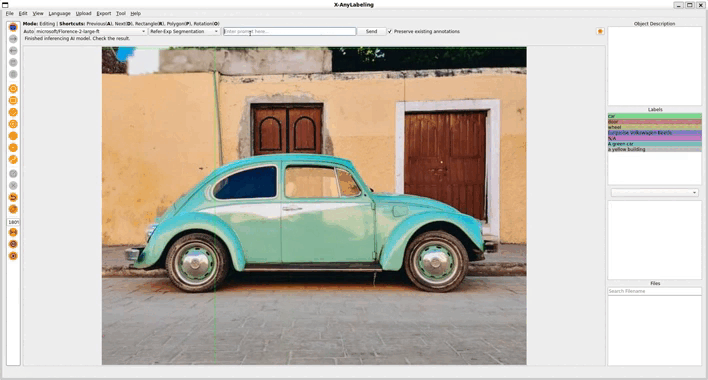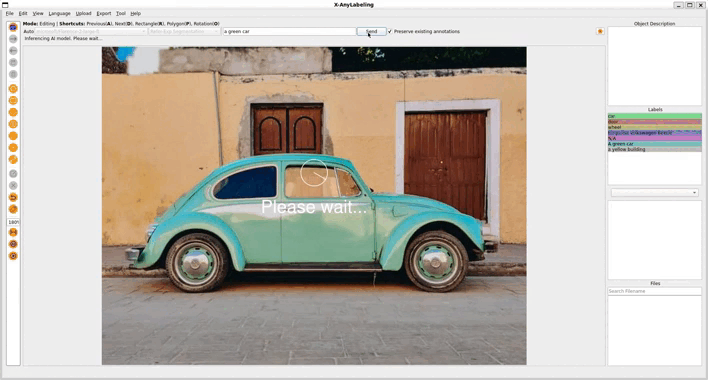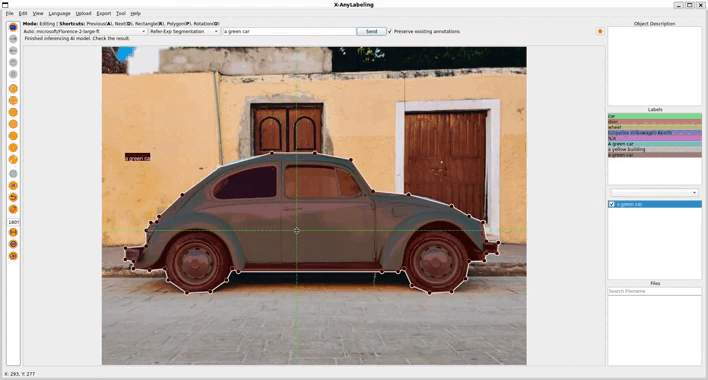
3. Open Vocabulary Detection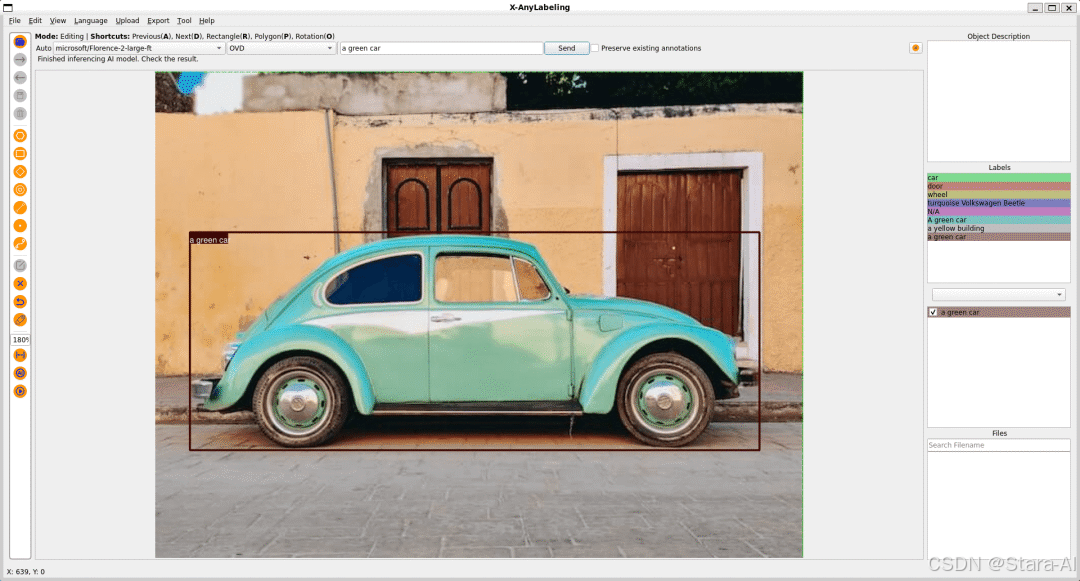
-
光学字符识别
基于光学字符识别的任务包含以下两个子任务:
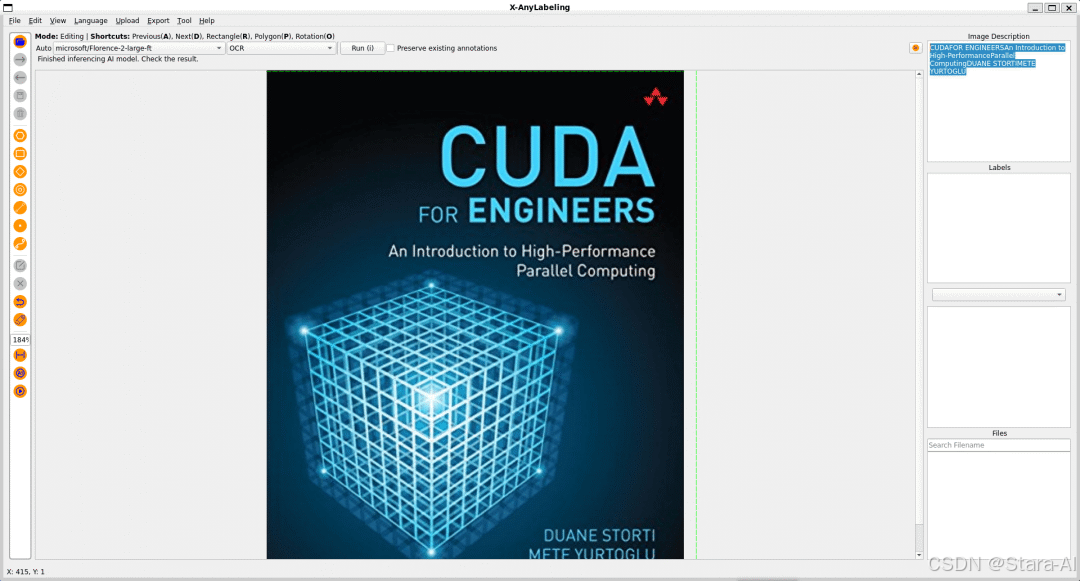
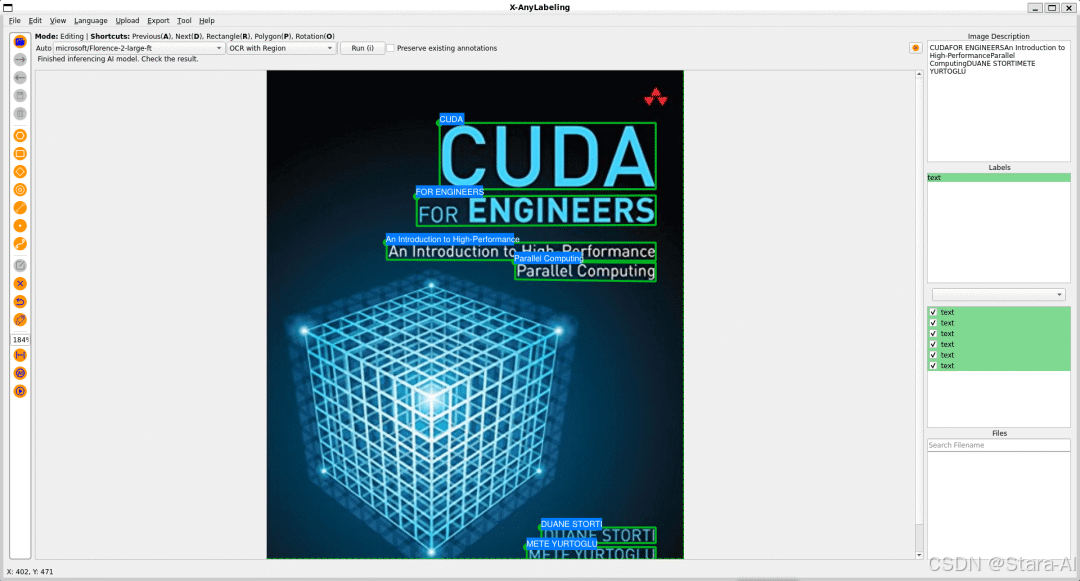
2.3 基于 Segment Anything 2 的交互式视频检测与分割标注
3. 多样化的任务支持
除了上述新算法功能,X-AnyLabeling 还支持多样化的算法模型,以满足各项任务需求并扩展应用场景。
📚 教程:https://github.com/CVHub520/X-AnyLabeling/tree/main/examples/classification
3.1 图像分类
图像分类是计算机视觉领域的基础任务之一,X-AnyLabeling 内置了主流分类模型,其核心目标是将整幅图像准确地归类至预定义的标签或类别。此任务通常细分为以下两个关键子类别:
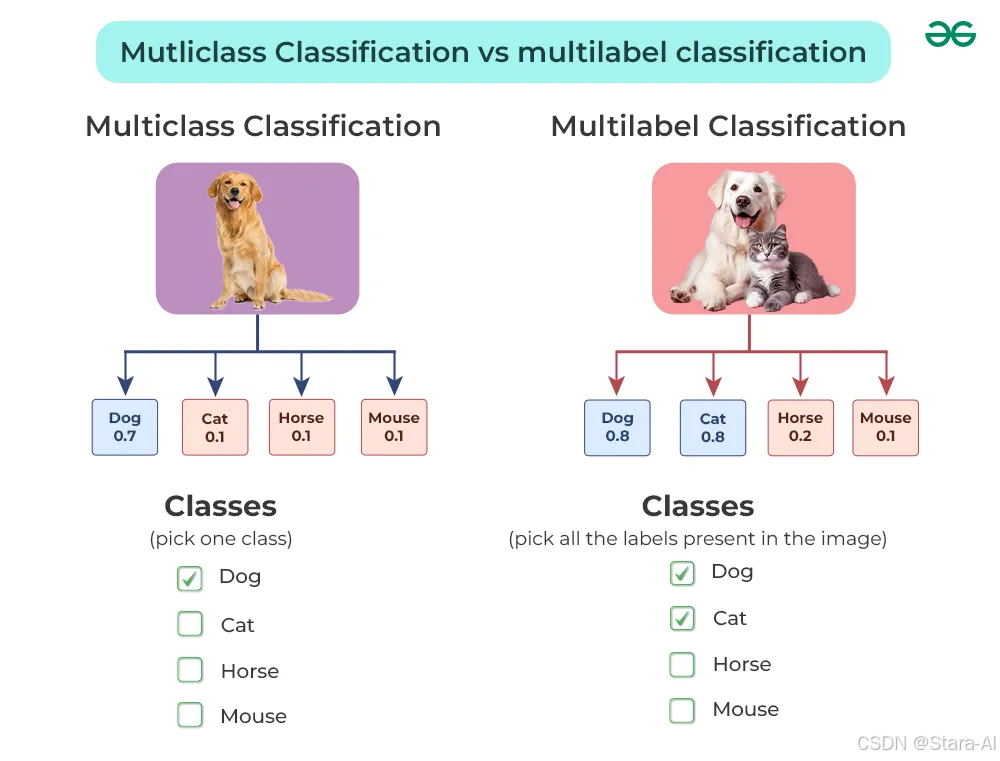
多类别分类 (Multiclass Classification):此任务中,每张图像被严格限定归属于一个且仅一个预先设定的类别。这些类别之间彼此互斥,例如,图像的内容可能被限定为"猫"、"狗"、"汽车"等互不重叠的选项。模型在此类任务中的目标是找出图像最可能对应的单一类别。举例来说,在动物识别任务中,一张图片仅能被分类为"猫"、"狗"或"鸟"中的一种。
多标签分类(Multilabel Classification):与多类别分类不同,多标签分类允许一张图像同时关联多个类别。这意味着图像内容可能涉及多种元素,而这些元素之间并不相互排斥。例如,一张图片中同时出现猫和狗,那么这张图片就应该同时被标记为"猫"和"狗"。多标签分类模型需要辨识图像中所有相关的元素,并为每个元素分配其对应的标签。
在 X-AnyLabeling 中内置了以下图像分类模型用于预打标:
- ResNet
- InternImage
- YOLOv5-cls
- YOLOv8-cls
除了图像级的分类任务外,也支持实例级的分类任务
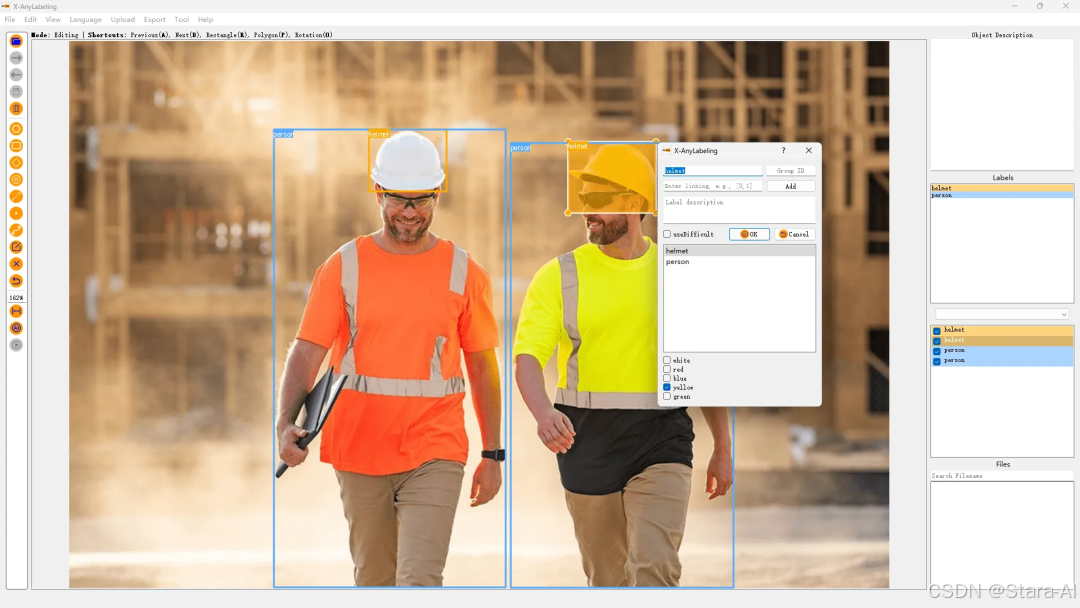
此外,X-AnyLabeling 还支持更为复杂的 多任务分类(Multitask classification ),这意味着你可以基于 X-AnyLabeling 为不同的对象轻松构建多种属性
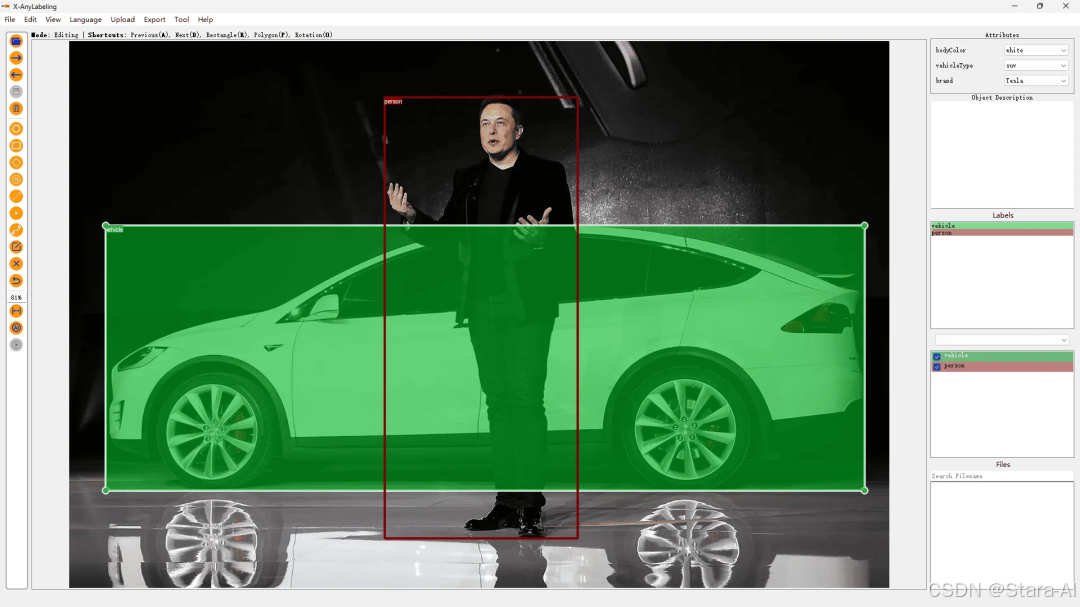
目前,X-AnyLabeling 中适配了 PaddlePaddle 开源的 PULC 车辆属性(Vehicle Attribute)和行人属性(Person Attribute)模型。整体的用户界面(UI)设计也参照 CVAT 的标注范式,为用户提供更加一致和友好的体验。
3.2 目标检测
📚 教程:
水平目标检测:https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/detection/hbb/README.md
旋转目标检测:https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/detection/obb/README.md
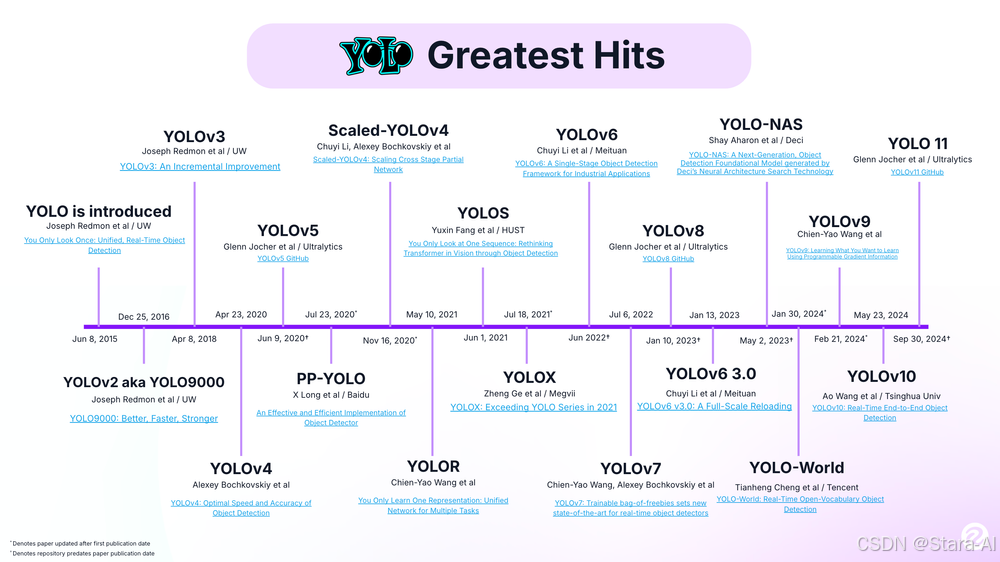
目标检测是计算机视觉领域的核心技术之一,其目标是在图像或视频中识别并精确定位各种物体,同时为每个被检测到的物体绘制边界框并给出其所属的类别。

目前,X-AnyLabeling 集成了多种主流的目标检测器,包括:
- RT-DETR 系列:RTDETR、RTDETRv2、DEIM
- YOLO 系列: DAMO-YOLO、Gold-YOLO、YOLOX、YOLO-NAS、YOLO-World、YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv9、YOLOv10、YOLO11、Hyper-YOLO
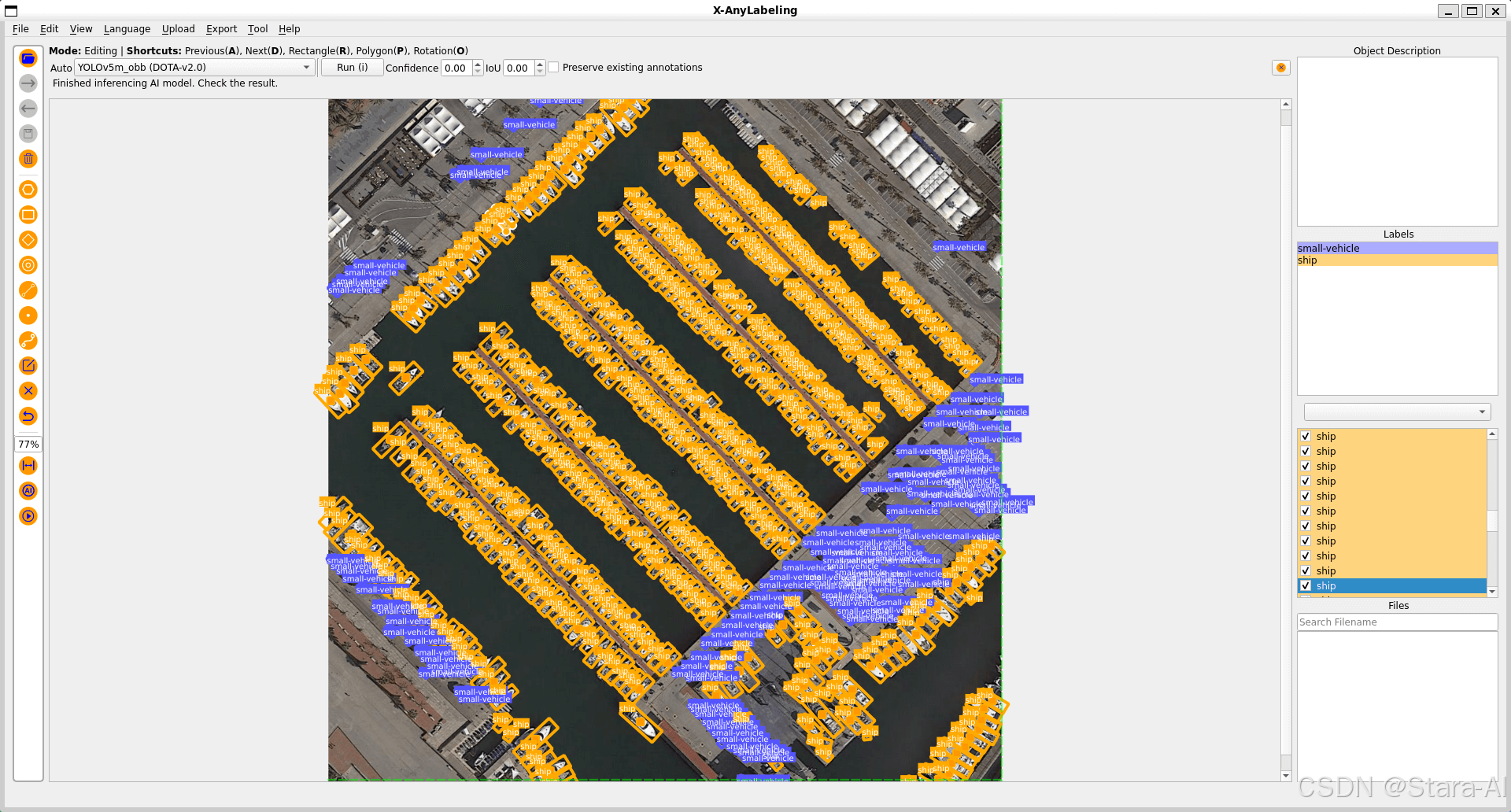
同时也支持旋转框的标定,并包括 YOLOv5-OBB 和 YOLOv8-OBB 等旋转目标检测模型,以更好的适配旋转目标检测任务。
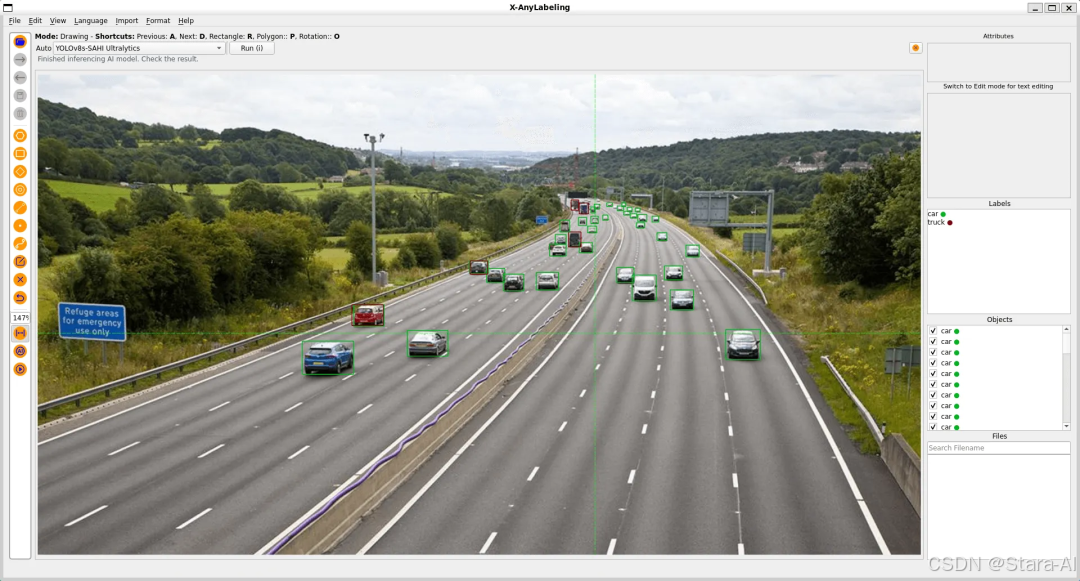
此外,针对小目标检测的挑战,X-AnyLabeling 整合了 SAHI 工具,提供了 YOLOv5-SAHI 和 YOLOv8-SAHI并支持切片推理,有效提升了小目标场景下的检测召回率。
除了闭集目标检测,X-AnyLabeling 中还适配了基于开集的目标检测算法 Grounding-DINO,该模型允许用户通过文本提示的方式进行交互,从而实现零样本检测能力。
值得一提的是,X-AnyLabeling v2.5.0+ 版本中还引入了全新的 UPN 算法,该模型采用双粒度提示调优策略,在实例和部件级别生成全面的对象提议。

具体而言,UPN模型包含两种提示模式:
- 细粒度提示(fine_grained_prompt):
用于检测详细的对象部件以及相似对象之间的细微差别。此模式擅长识别面部特征等特定细节,或区分相似物种。 - 粗粒度提示(coarse_grained_prompt): 用于检测广泛的对象类别和主要场景元素。此模式侧重于识别诸如人、车辆或建筑物等通用对象,而无需进行详细的子分类。