一、单机模式
步骤:
1、使用XFTP将Spark安装包spark-2.4.8-bin-hadoop2.7.tgz发送到master机器的主目录。
2、解压安装包:
tar -zxvf ~/spark-2.4.8-bin-hadoop2.7.tgz3、修改文件夹的名字,将其改为flume,或者创建软连接也可:
mv ~/spark-2.4.8-bin-hadoop2.7 ~/spark4、开箱即用;
二、Spark Standalone模式集群
步骤:
1、使用vim命令配置Spark的环境配置文件,原本应是不存在的:
cd ~/spark/conf
vim spark-env.sh配置内容如下(注意此处的所有路径、主机名):
# jdk安装目录
export JAVA_HOME=/home/hadoop/jdk1.8.0_311
# Hadoop配置文件目录
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.9.2/etc/hadoop
# Hadoop根目录
export HADOOP_HOME=/home/hadoop/hadoop-2.9.2
# Web UI端口号
SPARK_MASTER_WEBUI_PORT=8888
# 配置ZooKeeper
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/myspark"修改完后保存。
2、配置slaves:
vim slaves添加以下内容:
master
slave1
slave23、接着把配置好的Spark安装目录使用scp命令发送到其他节点:
scp -r ~/spark hadoop@slave1:~
scp -r ~/spark hadoop@slave2:~4、启动ZooKeeper,略;
5、在master节点上,带路径启动Spark集群:
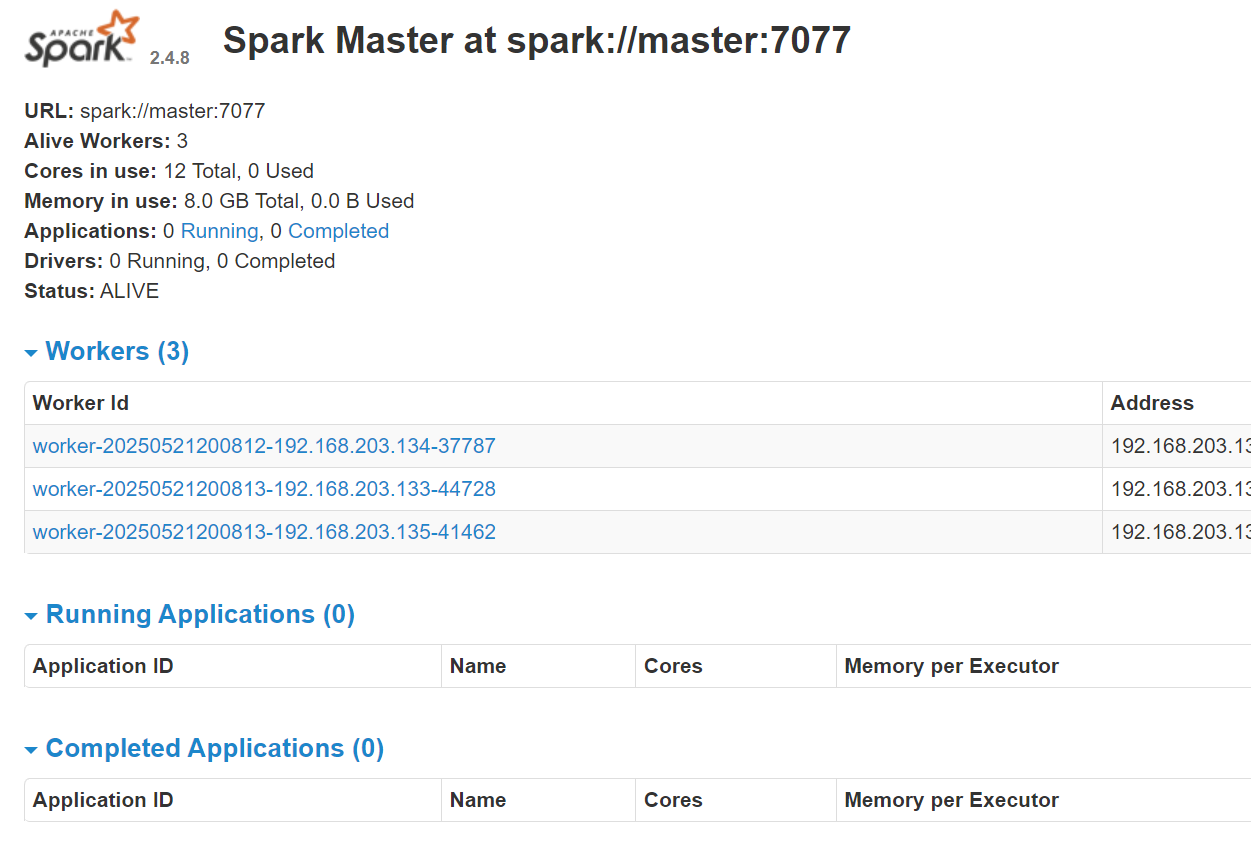
~/spark/sbin/start-all.sh测试
浏览器输入:master:8888,如下:
三、Spark on YARN模式
实际上,Spark on YARN模式,即把Spark应用程序跑在YARN集群之上,通过第二节配置好Spark Standalone模式后,已经可以在任意节点上,执行spark-submit脚本把任务提交至YARN实现Spark on YARN。而区别就是使用这种方式提交任务的话,就不需要启动Spark集群了。